 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating trajectory optimization with Sobolev-trained diffusion policies
Apr 21, 2026Trajectory Optimization (TO) solvers exploit known system dynamics to compute locally optimal trajectories through iterative improvements. A downside is that each new problem instance is solved independently; therefore, convergence speed and quality of the solution found depend on the initial trajectory proposed. To improve efficiency, a natural approach is to warm-start TO with initial guesses produced by a learned policy trained on trajectories previously generated by the solver. Diffusion-based policies have recently emerged as expressive imitation learning models, making them promising candidates for this role. Yet, a counterintuitive challenge comes from the local optimality of TO demonstrations: when a policy is rolled out, small non-optimal deviations may push it into situations not represented in the training data, triggering compounding errors over long horizons. In this work, we focus on learning-based warm-starting for gradient-based TO solvers that also provide feedback gains. Exploiting this specificity, we derive a first-order loss for Sobolev learning of diffusion-based policies using both trajectories and feedback gains. Through comprehensive experiments, we demonstrate that the resulting policy avoids compounding errors, and so can learn from very few trajectories to provide initial guesses reducing solving time by $2\times$ to $20 \times$. Incorporating first-order information enables predictions with fewer diffusion steps, reducing inference latency.
SVL: Goal-Conditioned Reinforcement Learning as Survival Learning
Apr 19, 2026Standard approaches to goal-conditioned reinforcement learning (GCRL) that rely on temporal-difference learning can be unstable and sample-inefficient due to bootstrapping. While recent work has explored contrastive and supervised formulations to improve stability, we present a probabilistic alternative, called survival value learning (SVL), that reframes GCRL as a survival learning problem by modeling the time-to-goal from each state as a probability distribution. This structured distributional Monte Carlo perspective yields a closed-form identity that expresses the goal-conditioned value function as a discounted sum of survival probabilities, enabling value estimation via a hazard model trained via maximum likelihood on both event and right-censored trajectories. We introduce three practical value estimators, including finite-horizon truncation and two binned infinite-horizon approximations to capture long-horizon objectives. Experiments on offline GCRL benchmarks show that SVL combined with hierarchical actors matches or surpasses strong hierarchical TD and Monte Carlo baselines, excelling on complex, long-horizon tasks.
Rockmate: an Efficient, Fast, Automatic and Generic Tool for Re-materialization in PyTorch
Jul 03, 2023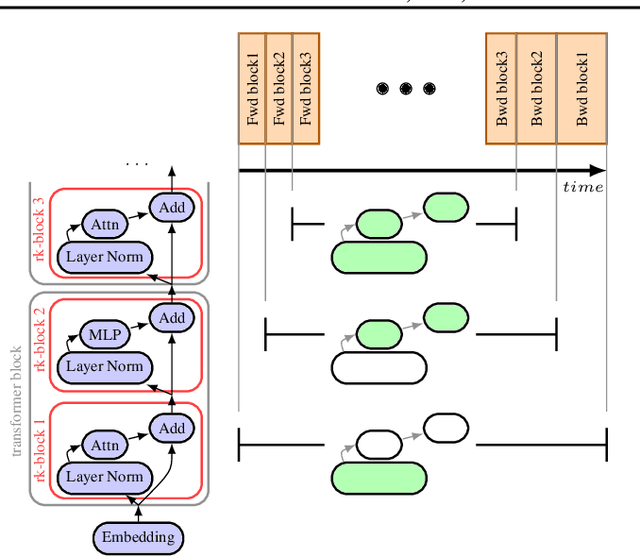
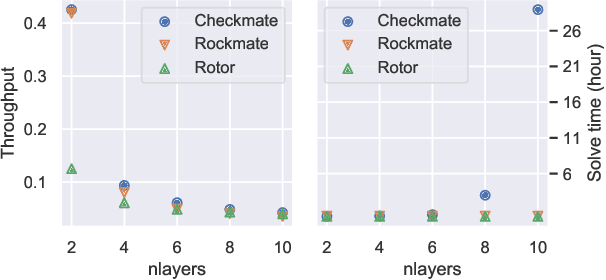
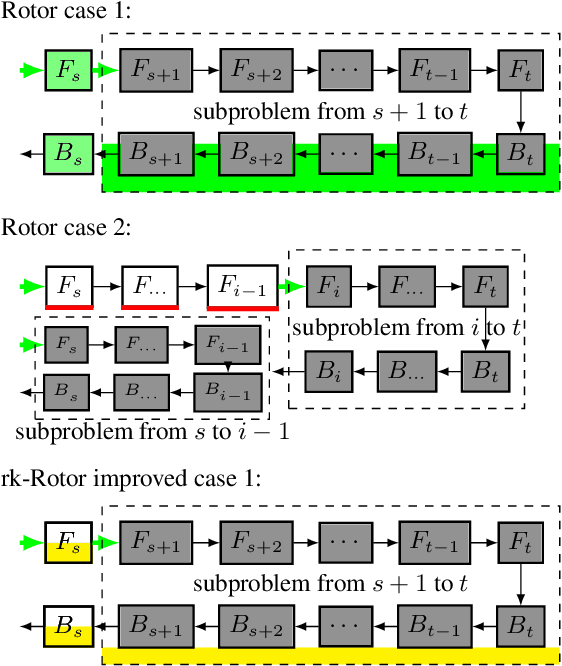
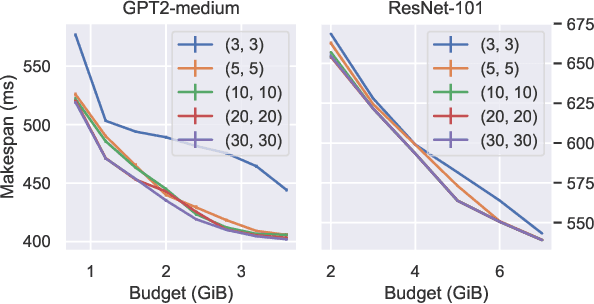
We propose Rockmate to control the memory requirements when training PyTorch DNN models. Rockmate is an automatic tool that starts from the model code and generates an equivalent model, using a predefined amount of memory for activations, at the cost of a few re-computations. Rockmate automatically detects the structure of computational and data dependencies and rewrites the initial model as a sequence of complex blocks. We show that such a structure is widespread and can be found in many models in the literature (Transformer based models, ResNet, RegNets,...). This structure allows us to solve the problem in a fast and efficient way, using an adaptation of Checkmate (too slow on the whole model but general) at the level of individual blocks and an adaptation of Rotor (fast but limited to sequential models) at the level of the sequence itself. We show through experiments on many models that Rockmate is as fast as Rotor and as efficient as Checkmate, and that it allows in many cases to obtain a significantly lower memory consumption for activations (by a factor of 2 to 5) for a rather negligible overhead (of the order of 10% to 20%). Rockmate is open source and available at https://github.com/topal-team/rockmate.