 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023



Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023



The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023



The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
Exploring Opinion-unaware Video Quality Assessment with Semantic Affinity Criterion
Feb 26, 2023



Recent learning-based video quality assessment (VQA) algorithms are expensive to implement due to the cost of data collection of human quality opinions, and are less robust across various scenarios due to the biases of these opinions. This motivates our exploration on opinion-unaware (a.k.a zero-shot) VQA approaches. Existing approaches only considers low-level naturalness in spatial or temporal domain, without considering impacts from high-level semantics. In this work, we introduce an explicit semantic affinity index for opinion-unaware VQA using text-prompts in the contrastive language-image pre-training (CLIP) model. We also aggregate it with different traditional low-level naturalness indexes through gaussian normalization and sigmoid rescaling strategies. Composed of aggregated semantic and technical metrics, the proposed Blind Unified Opinion-Unaware Video Quality Index via Semantic and Technical Metric Aggregation (BUONA-VISTA) outperforms existing opinion-unaware VQA methods by at least 20% improvements, and is more robust than opinion-aware approaches.
Disentangling Aesthetic and Technical Effects for Video Quality Assessment of User Generated Content
Nov 16, 2022User-generated-content (UGC) videos have dominated the Internet during recent years. While it is well-recognized that the perceptual quality of these videos can be affected by diverse factors, few existing methods explicitly explore the effects of different factors in video quality assessment (VQA) for UGC videos, i.e. the UGC-VQA problem. In this work, we make the first attempt to disentangle the effects of aesthetic quality issues and technical quality issues risen by the complicated video generation processes in the UGC-VQA problem. To overcome the absence of respective supervisions during disentanglement, we propose the Limited View Biased Supervisions (LVBS) scheme where two separate evaluators are trained with decomposed views specifically designed for each issue. Composed of an Aesthetic Quality Evaluator (AQE) and a Technical Quality Evaluator (TQE) under the LVBS scheme, the proposed Disentangled Objective Video Quality Evaluator (DOVER) reach excellent performance (0.91 SRCC for KoNViD-1k, 0.89 SRCC for LSVQ, 0.88 SRCC for YouTube-UGC) in the UGC-VQA problem. More importantly, our blind subjective studies prove that the separate evaluators in DOVER can effectively match human perception on respective disentangled quality issues. Codes and demos are released in https://github.com/teowu/dover.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
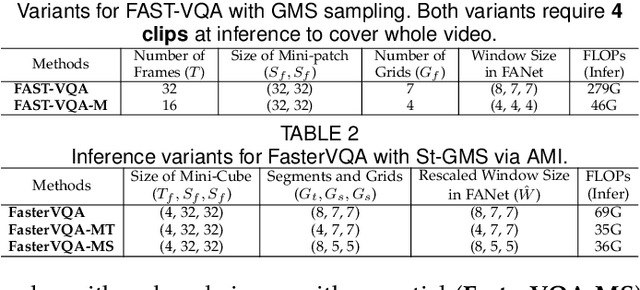
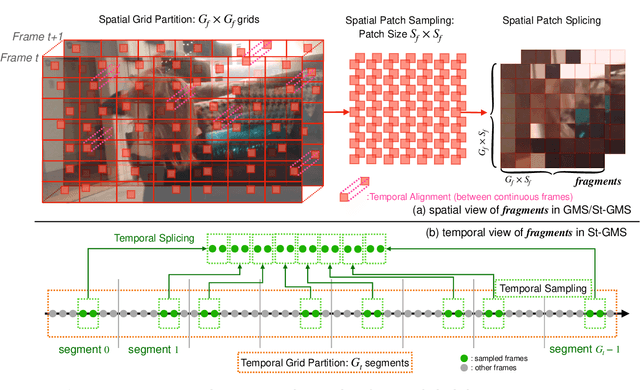
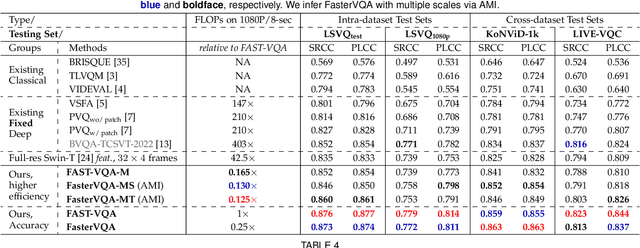
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022
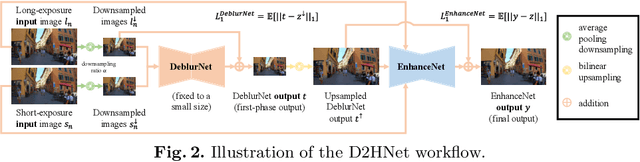
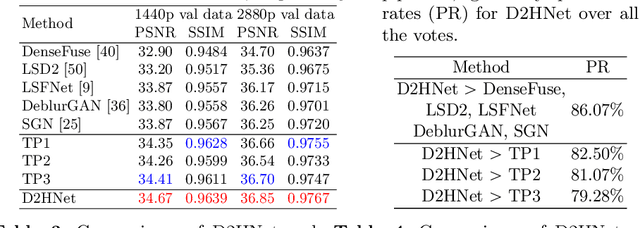
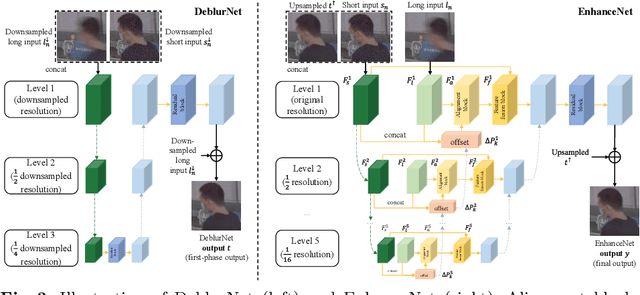
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
Exploring the Effectiveness of Video Perceptual Representation in Blind Video Quality Assessment
Jul 08, 2022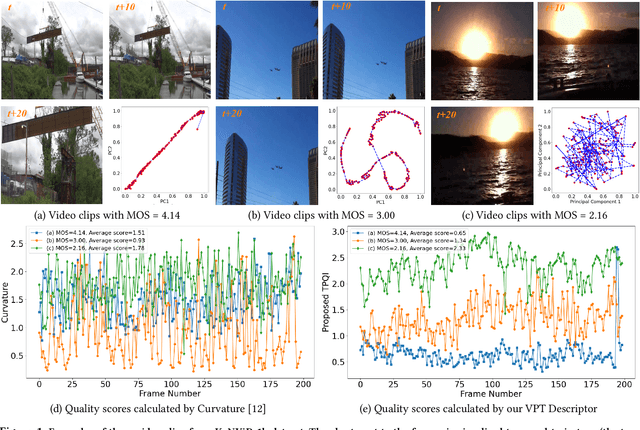
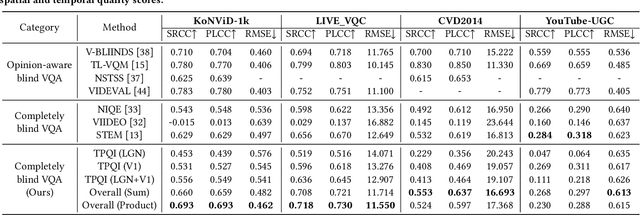
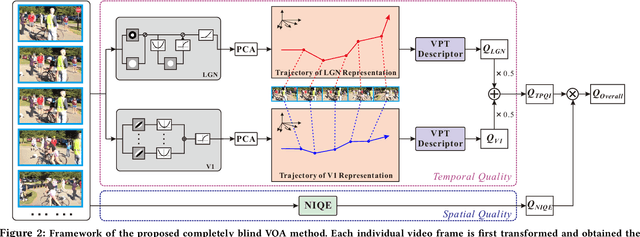
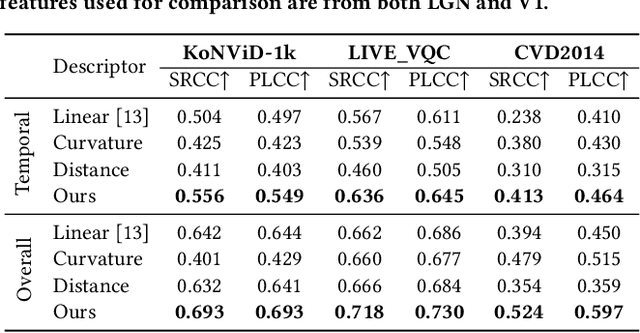
With the rapid growth of in-the-wild videos taken by non-specialists, blind video quality assessment (VQA) has become a challenging and demanding problem. Although lots of efforts have been made to solve this problem, it remains unclear how the human visual system (HVS) relates to the temporal quality of videos. Meanwhile, recent work has found that the frames of natural video transformed into the perceptual domain of the HVS tend to form a straight trajectory of the representations. With the obtained insight that distortion impairs the perceived video quality and results in a curved trajectory of the perceptual representation, we propose a temporal perceptual quality index (TPQI) to measure the temporal distortion by describing the graphic morphology of the representation. Specifically, we first extract the video perceptual representations from the lateral geniculate nucleus (LGN) and primary visual area (V1) of the HVS, and then measure the straightness and compactness of their trajectories to quantify the degradation in naturalness and content continuity of video. Experiments show that the perceptual representation in the HVS is an effective way of predicting subjective temporal quality, and thus TPQI can, for the first time, achieve comparable performance to the spatial quality metric and be even more effective in assessing videos with large temporal variations. We further demonstrate that by combining with NIQE, a spatial quality metric, TPQI can achieve top performance over popular in-the-wild video datasets. More importantly, TPQI does not require any additional information beyond the video being evaluated and thus can be applied to any datasets without parameter tuning. Source code is available at https://github.com/UoLMM/TPQI-VQA.
* Will appear on ACM MM 2022
FAST-VQA: Efficient End-to-end Video Quality Assessment with Fragment Sampling
Jul 06, 2022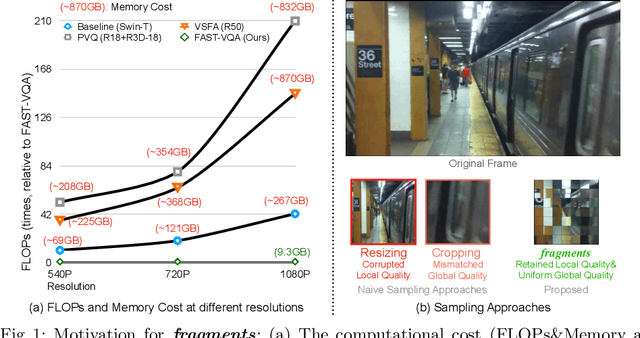
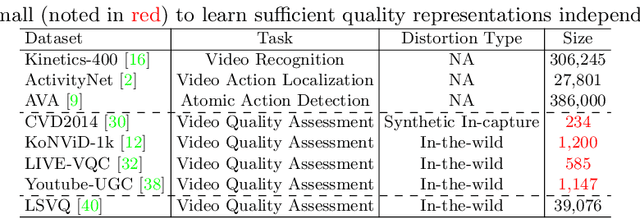


Current deep video quality assessment (VQA) methods are usually with high computational costs when evaluating high-resolution videos. This cost hinders them from learning better video-quality-related representations via end-to-end training. Existing approaches typically consider naive sampling to reduce the computational cost, such as resizing and cropping. However, they obviously corrupt quality-related information in videos and are thus not optimal for learning good representations for VQA. Therefore, there is an eager need to design a new quality-retained sampling scheme for VQA. In this paper, we propose Grid Mini-patch Sampling (GMS), which allows consideration of local quality by sampling patches at their raw resolution and covers global quality with contextual relations via mini-patches sampled in uniform grids. These mini-patches are spliced and aligned temporally, named as fragments. We further build the Fragment Attention Network (FANet) specially designed to accommodate fragments as inputs. Consisting of fragments and FANet, the proposed FrAgment Sample Transformer for VQA (FAST-VQA) enables efficient end-to-end deep VQA and learns effective video-quality-related representations. It improves state-of-the-art accuracy by around 10% while reducing 99.5% FLOPs on 1080P high-resolution videos. The newly learned video-quality-related representations can also be transferred into smaller VQA datasets, boosting performance in these scenarios. Extensive experiments show that FAST-VQA has good performance on inputs of various resolutions while retaining high efficiency. We publish our code at https://github.com/timothyhtimothy/FAST-VQA.
* Will appear on ECCV 2022. 14 Pages
DisCoVQA: Temporal Distortion-Content Transformers for Video Quality Assessment
Jun 20, 2022
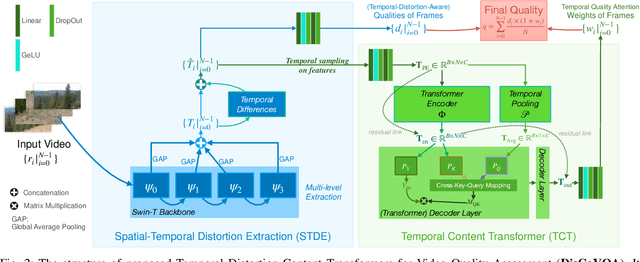
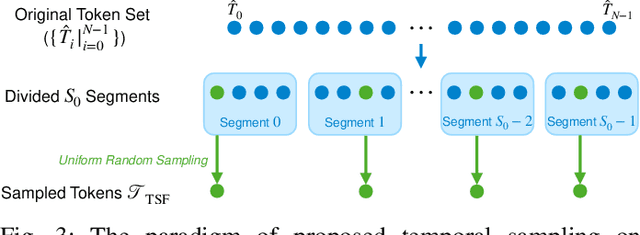
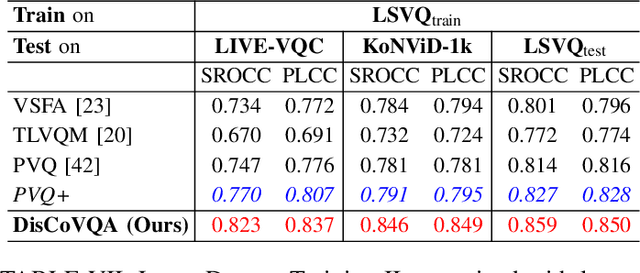
The temporal relationships between frames and their influences on video quality assessment (VQA) are still under-studied in existing works. These relationships lead to two important types of effects for video quality. Firstly, some temporal variations (such as shaking, flicker, and abrupt scene transitions) are causing temporal distortions and lead to extra quality degradations, while other variations (e.g. those related to meaningful happenings) do not. Secondly, the human visual system often has different attention to frames with different contents, resulting in their different importance to the overall video quality. Based on prominent time-series modeling ability of transformers, we propose a novel and effective transformer-based VQA method to tackle these two issues. To better differentiate temporal variations and thus capture the temporal distortions, we design a transformer-based Spatial-Temporal Distortion Extraction (STDE) module. To tackle with temporal quality attention, we propose the encoder-decoder-like temporal content transformer (TCT). We also introduce the temporal sampling on features to reduce the input length for the TCT, so as to improve the learning effectiveness and efficiency of this module. Consisting of the STDE and the TCT, the proposed Temporal Distortion-Content Transformers for Video Quality Assessment (DisCoVQA) reaches state-of-the-art performance on several VQA benchmarks without any extra pre-training datasets and up to 10% better generalization ability than existing methods. We also conduct extensive ablation experiments to prove the effectiveness of each part in our proposed model, and provide visualizations to prove that the proposed modules achieve our intention on modeling these temporal issues. We will publish our codes and pretrained weights later.