 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Motion Prediction with Stacked Transformers
Mar 24, 2021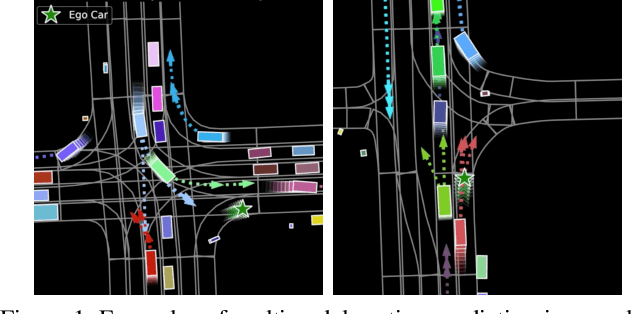
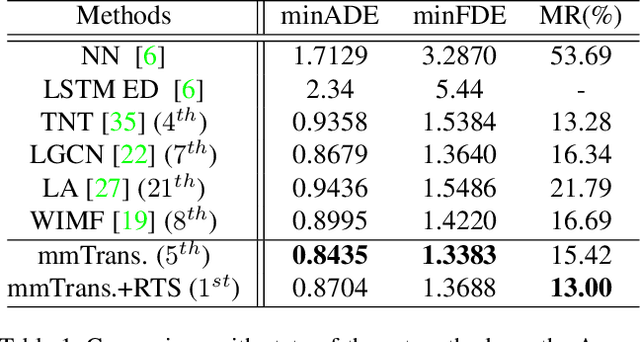
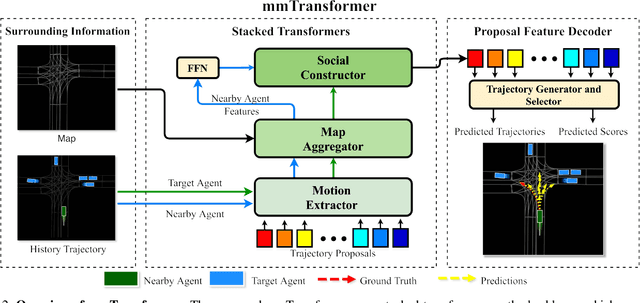
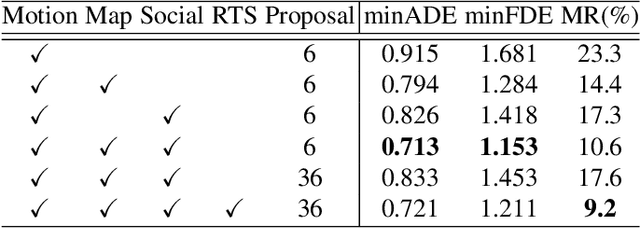
Predicting multiple plausible future trajectories of the nearby vehicles is crucial for the safety of autonomous driving. Recent motion prediction approaches attempt to achieve such multimodal motion prediction by implicitly regularizing the feature or explicitly generating multiple candidate proposals. However, it remains challenging since the latent features may concentrate on the most frequent mode of the data while the proposal-based methods depend largely on the prior knowledge to generate and select the proposals. In this work, we propose a novel transformer framework for multimodal motion prediction, termed as mmTransformer. A novel network architecture based on stacked transformers is designed to model the multimodality at feature level with a set of fixed independent proposals. A region-based training strategy is then developed to induce the multimodality of the generated proposals. Experiments on Argoverse dataset show that the proposed model achieves the state-of-the-art performance on motion prediction, substantially improving the diversity and the accuracy of the predicted trajectories. Demo video and code are available at https://decisionforce.github.io/mmTransformer.
Dynamic and Static Context-aware LSTM for Multi-agent Motion Prediction
Aug 03, 2020
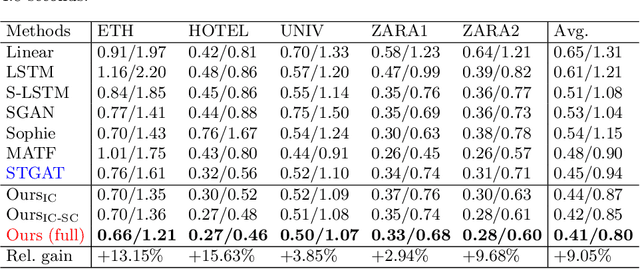
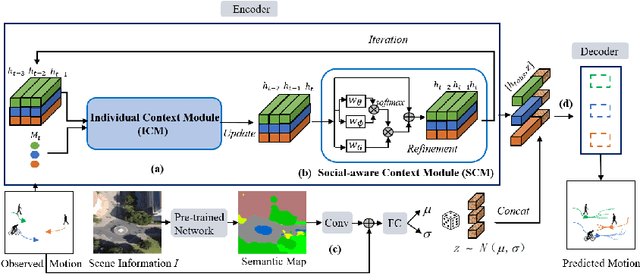
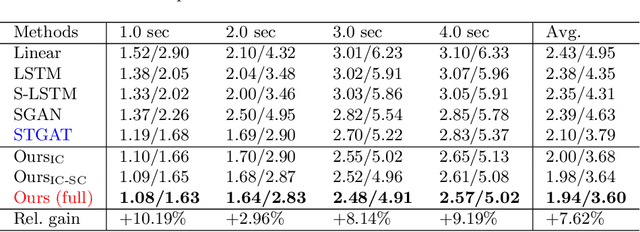
Multi-agent motion prediction is challenging because it aims to foresee the future trajectories of multiple agents (\textit{e.g.} pedestrians) simultaneously in a complicated scene. Existing work addressed this challenge by either learning social spatial interactions represented by the positions of a group of pedestrians, while ignoring their temporal coherence (\textit{i.e.} dependencies between different long trajectories), or by understanding the complicated scene layout (\textit{e.g.} scene segmentation) to ensure safe navigation. However, unlike previous work that isolated the spatial interaction, temporal coherence, and scene layout, this paper designs a new mechanism, \textit{i.e.}, Dynamic and Static Context-aware Motion Predictor (DSCMP), to integrates these rich information into the long-short-term-memory (LSTM). It has three appealing benefits. (1) DSCMP models the dynamic interactions between agents by learning both their spatial positions and temporal coherence, as well as understanding the contextual scene layout.(2) Different from previous LSTM models that predict motions by propagating hidden features frame by frame, limiting the capacity to learn correlations between long trajectories, we carefully design a differentiable queue mechanism in DSCMP, which is able to explicitly memorize and learn the correlations between long trajectories. (3) DSCMP captures the context of scene by inferring latent variable, which enables multimodal predictions with meaningful semantic scene layout. Extensive experiments show that DSCMP outperforms state-of-the-art methods by large margins, such as 9.05\% and 7.62\% relative improvements on the ETH-UCY and SDD datasets respectively.
* 17 pages, 6 figures
TPNet: Trajectory Proposal Network for Motion Prediction
Apr 26, 2020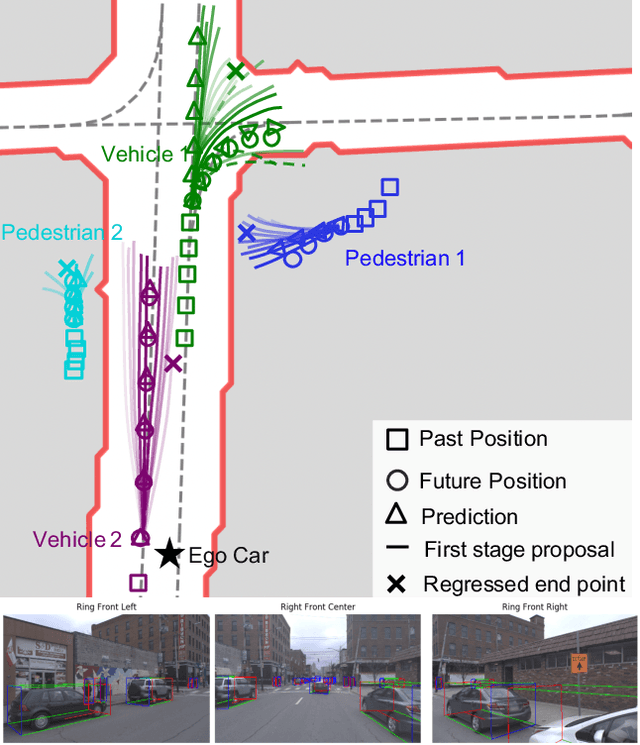
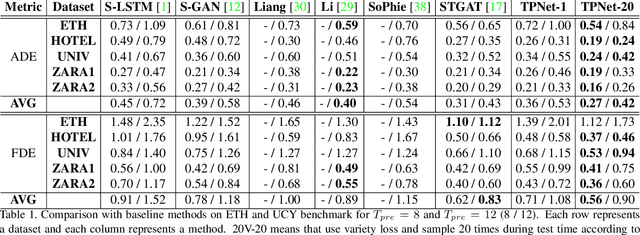
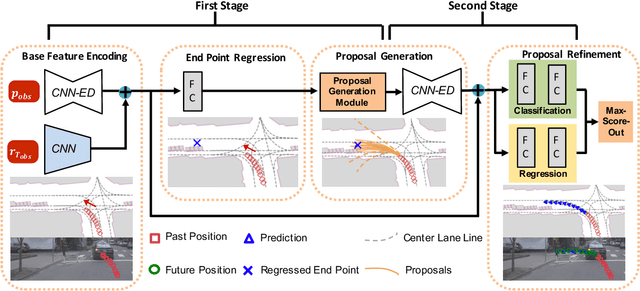
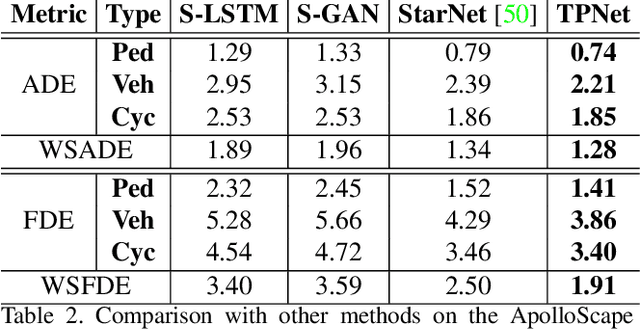
Making accurate motion prediction of the surrounding traffic agents such as pedestrians, vehicles, and cyclists is crucial for autonomous driving. Recent data-driven motion prediction methods have attempted to learn to directly regress the exact future position or its distribution from massive amount of trajectory data. However, it remains difficult for these methods to provide multimodal predictions as well as integrate physical constraints such as traffic rules and movable areas. In this work we propose a novel two-stage motion prediction framework, Trajectory Proposal Network (TPNet). TPNet first generates a candidate set of future trajectories as hypothesis proposals, then makes the final predictions by classifying and refining the proposals which meets the physical constraints. By steering the proposal generation process, safe and multimodal predictions are realized. Thus this framework effectively mitigates the complexity of motion prediction problem while ensuring the multimodal output. Experiments on four large-scale trajectory prediction datasets, i.e. the ETH, UCY, Apollo and Argoverse datasets, show that TPNet achieves the state-of-the-art results both quantitatively and qualitatively.
Recursive Social Behavior Graph for Trajectory Prediction
Apr 22, 2020
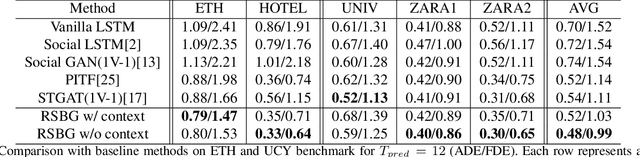


Social interaction is an important topic in human trajectory prediction to generate plausible paths. In this paper, we present a novel insight of group-based social interaction model to explore relationships among pedestrians. We recursively extract social representations supervised by group-based annotations and formulate them into a social behavior graph, called Recursive Social Behavior Graph. Our recursive mechanism explores the representation power largely. Graph Convolutional Neural Network then is used to propagate social interaction information in such a graph. With the guidance of Recursive Social Behavior Graph, we surpass state-of-the-art method on ETH and UCY dataset for 11.1% in ADE and 10.8% in FDE in average, and successfully predict complex social behaviors.
Disp R-CNN: Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation
Apr 07, 2020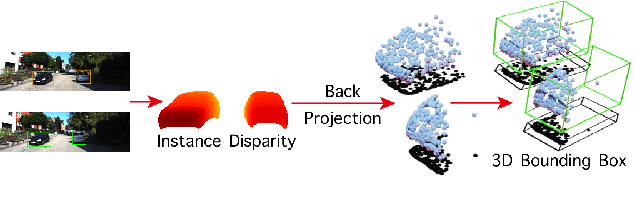
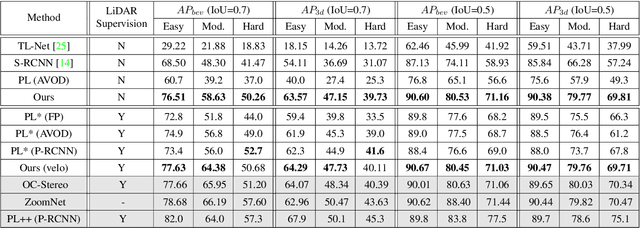
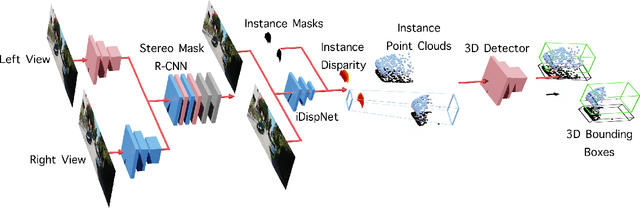
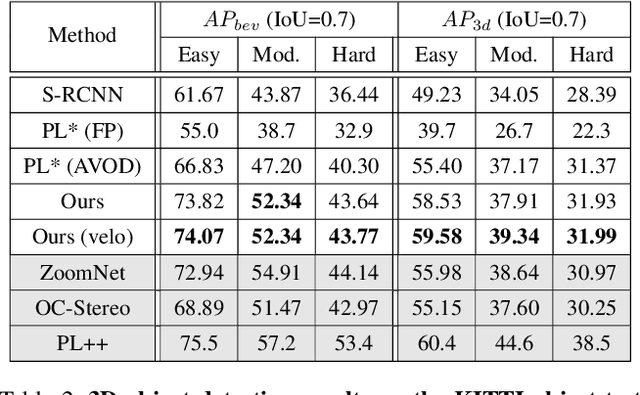
In this paper, we propose a novel system named Disp R-CNN for 3D object detection from stereo images. Many recent works solve this problem by first recovering a point cloud with disparity estimation and then apply a 3D detector. The disparity map is computed for the entire image, which is costly and fails to leverage category-specific prior. In contrast, we design an instance disparity estimation network (iDispNet) that predicts disparity only for pixels on objects of interest and learns a category-specific shape prior for more accurate disparity estimation. To address the challenge from scarcity of disparity annotation in training, we propose to use a statistical shape model to generate dense disparity pseudo-ground-truth without the need of LiDAR point clouds, which makes our system more widely applicable. Experiments on the KITTI dataset show that, even when LiDAR ground-truth is not available at training time, Disp R-CNN achieves competitive performance and outperforms previous state-of-the-art methods by 20% in terms of average precision.