 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024



We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Inference
Jan 08, 2024The large number of parameters in Pretrained Language Models enhance their performance, but also make them resource-intensive, making it challenging to deploy them on commodity hardware like a single GPU. Due to the memory and power limitations of these devices, model compression techniques are often used to decrease both the model's size and its inference latency. This usually results in a trade-off between model accuracy and efficiency. Therefore, optimizing this balance is essential for effectively deploying LLMs on commodity hardware. A significant portion of the efficiency challenge is the Feed-forward network (FFN) component, which accounts for roughly $\frac{2}{3}$ total parameters and inference latency. In this paper, we first observe that only a few neurons of FFN module have large output norm for any input tokens, a.k.a. heavy hitters, while the others are sparsely triggered by different tokens. Based on this observation, we explicitly split the FFN into two parts according to the heavy hitters. We improve the efficiency-accuracy trade-off of existing compression methods by allocating more resource to FFN parts with heavy hitters. In practice, our method can reduce model size by 43.1\% and bring $1.25\sim1.56\times$ wall clock time speedup on different hardware with negligible accuracy drop.
mSAM: Micro-Batch-Averaged Sharpness-Aware Minimization
Feb 19, 2023



Modern deep learning models are over-parameterized, where different optima can result in widely varying generalization performance. To account for this, Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as micro-batch SAM (mSAM), which, during training, averages the updates generated by adversarial perturbations across several disjoint shards (micro batches) of a mini-batch. We extend a recently developed and well-studied general framework for flatness analysis to show that distributed gradient computation for sharpness-aware minimization theoretically achieves even flatter minima. In order to support this theoretical superiority, we provide a thorough empirical evaluation on a variety of image classification and natural language processing tasks. We also show that contrary to previous work, mSAM can be implemented in a flexible and parallelizable manner without significantly increasing computational costs. Our practical implementation of mSAM yields superior generalization performance across a wide range of tasks compared to SAM, further supporting our theoretical framework.
Improved Deep Neural Network Generalization Using m-Sharpness-Aware Minimization
Dec 07, 2022



Modern deep learning models are over-parameterized, where the optimization setup strongly affects the generalization performance. A key element of reliable optimization for these systems is the modification of the loss function. Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as mSAM, which, during training, averages the updates generated by adversarial perturbations across several disjoint shards of a mini-batch. Recent work suggests that mSAM can outperform SAM in terms of test accuracy. However, a comprehensive empirical study of mSAM is missing from the literature -- previous results have mostly been limited to specific architectures and datasets. To that end, this paper presents a thorough empirical evaluation of mSAM on various tasks and datasets. We provide a flexible implementation of mSAM and compare the generalization performance of mSAM to the performance of SAM and vanilla training on different image classification and natural language processing tasks. We also conduct careful experiments to understand the computational cost of training with mSAM, its sensitivity to hyperparameters and its correlation with the flatness of the loss landscape. Our analysis reveals that mSAM yields superior generalization performance and flatter minima, compared to SAM, across a wide range of tasks without significantly increasing computational costs.
Geometric Graph Representation Learning via Maximizing Rate Reduction
Feb 13, 2022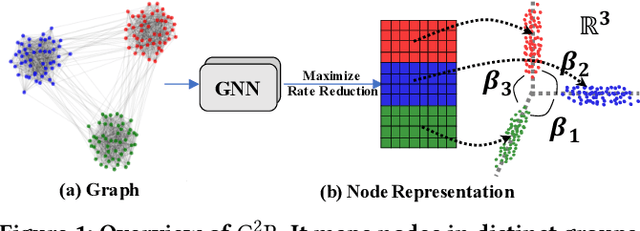
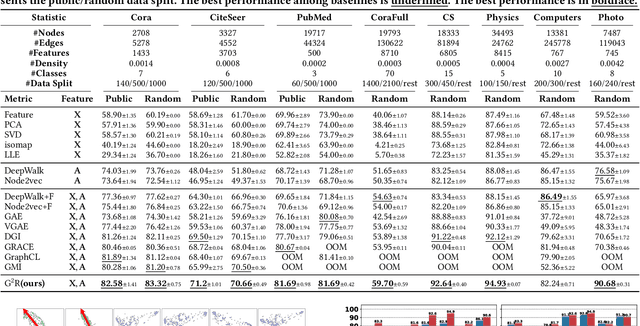
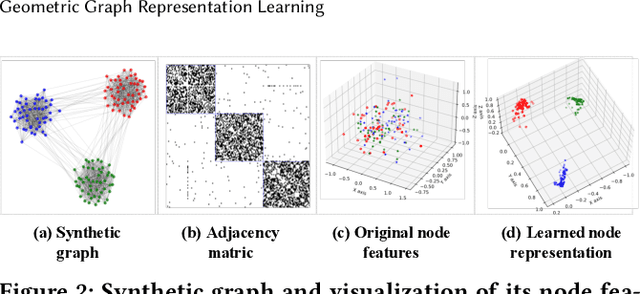

Learning discriminative node representations benefits various downstream tasks in graph analysis such as community detection and node classification. Existing graph representation learning methods (e.g., based on random walk and contrastive learning) are limited to maximizing the local similarity of connected nodes. Such pair-wise learning schemes could fail to capture the global distribution of representations, since it has no explicit constraints on the global geometric properties of representation space. To this end, we propose Geometric Graph Representation Learning (G2R) to learn node representations in an unsupervised manner via maximizing rate reduction. In this way, G2R maps nodes in distinct groups (implicitly stored in the adjacency matrix) into different subspaces, while each subspace is compact and different subspaces are dispersedly distributed. G2R adopts a graph neural network as the encoder and maximizes the rate reduction with the adjacency matrix. Furthermore, we theoretically and empirically demonstrate that rate reduction maximization is equivalent to maximizing the principal angles between different subspaces. Experiments on real-world datasets show that G2R outperforms various baselines on node classification and community detection tasks.
Towards Interaction Detection Using Topological Analysis on Neural Networks
Nov 04, 2020
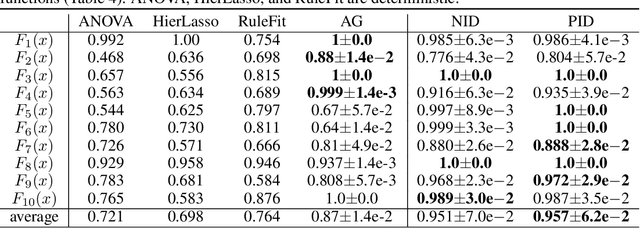
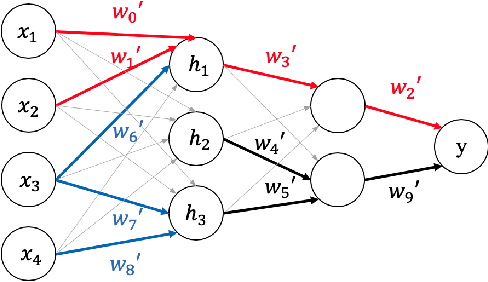

Detecting statistical interactions between input features is a crucial and challenging task. Recent advances demonstrate that it is possible to extract learned interactions from trained neural networks. It has also been observed that, in neural networks, any interacting features must follow a strongly weighted connection to common hidden units. Motivated by the observation, in this paper, we propose to investigate the interaction detection problem from a novel topological perspective by analyzing the connectivity in neural networks. Specially, we propose a new measure for quantifying interaction strength, based upon the well-received theory of persistent homology. Based on this measure, a Persistence Interaction detection~(PID) algorithm is developed to efficiently detect interactions. Our proposed algorithm is evaluated across a number of interaction detection tasks on several synthetic and real world datasets with different hyperparameters. Experimental results validate that the PID algorithm outperforms the state-of-the-art baselines.
Towards Automated Neural Interaction Discovery for Click-Through Rate Prediction
Jun 29, 2020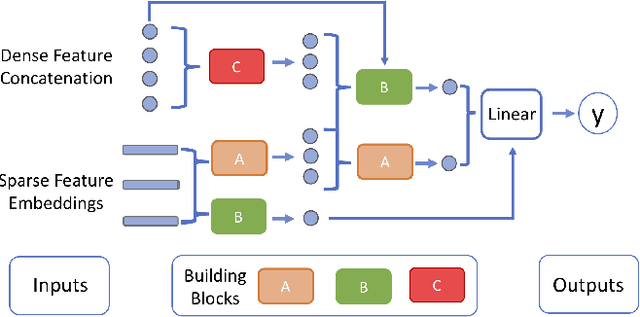
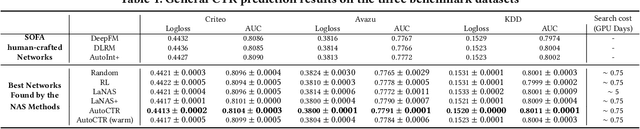
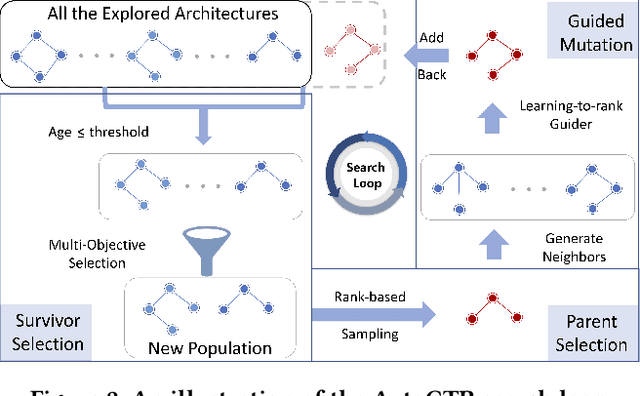
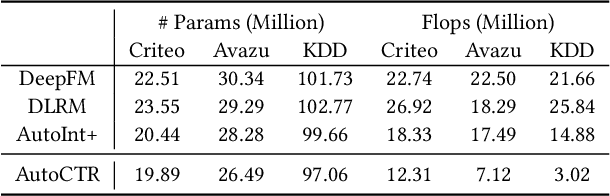
Click-Through Rate (CTR) prediction is one of the most important machine learning tasks in recommender systems, driving personalized experience for billions of consumers. Neural architecture search (NAS), as an emerging field, has demonstrated its capabilities in discovering powerful neural network architectures, which motivates us to explore its potential for CTR predictions. Due to 1) diverse unstructured feature interactions, 2) heterogeneous feature space, and 3) high data volume and intrinsic data randomness, it is challenging to construct, search, and compare different architectures effectively for recommendation models. To address these challenges, we propose an automated interaction architecture discovering framework for CTR prediction named AutoCTR. Via modularizing simple yet representative interactions as virtual building blocks and wiring them into a space of direct acyclic graphs, AutoCTR performs evolutionary architecture exploration with learning-to-rank guidance at the architecture level and achieves acceleration using low-fidelity model. Empirical analysis demonstrates the effectiveness of AutoCTR on different datasets comparing to human-crafted architectures. The discovered architecture also enjoys generalizability and transferability among different datasets.
AutoRec: An Automated Recommender System
Jun 26, 2020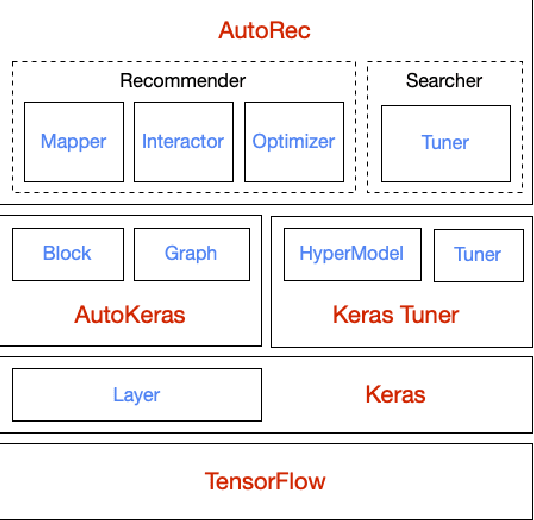
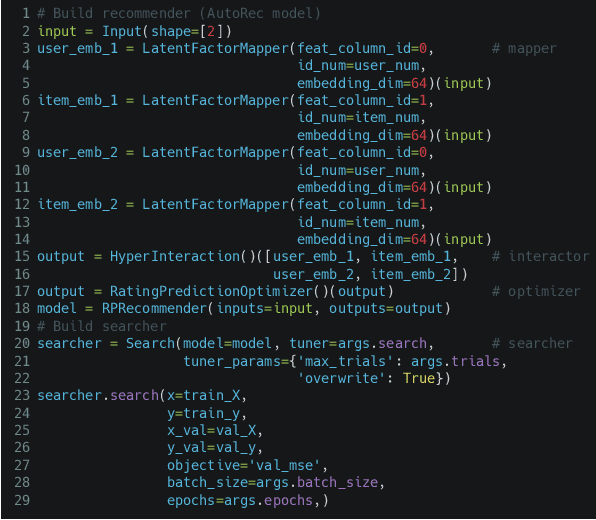
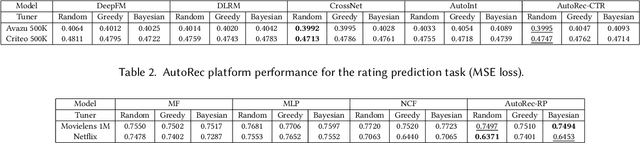
Realistic recommender systems are often required to adapt to ever-changing data and tasks or to explore different models systematically. To address the need, we present AutoRec, an open-source automated machine learning (AutoML) platform extended from the TensorFlow ecosystem and, to our knowledge, the first framework to leverage AutoML for model search and hyperparameter tuning in deep recommendation models. AutoRec also supports a highly flexible pipeline that accommodates both sparse and dense inputs, rating prediction and click-through rate (CTR) prediction tasks, and an array of recommendation models. Lastly, AutoRec provides a simple, user-friendly API. Experiments conducted on the benchmark datasets reveal AutoRec is reliable and can identify models which resemble the best model without prior knowledge.
Multi-Channel Graph Convolutional Networks
Dec 17, 2019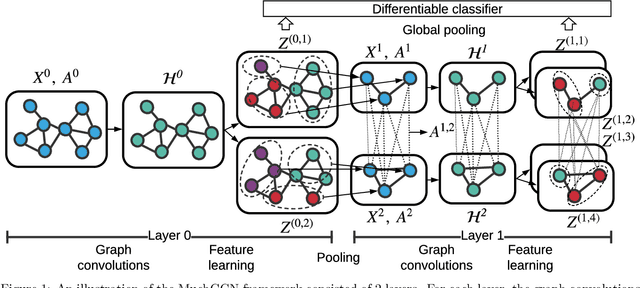
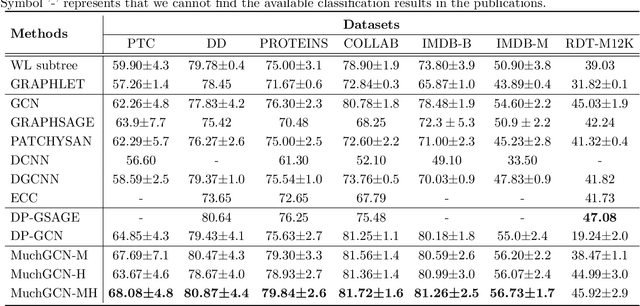
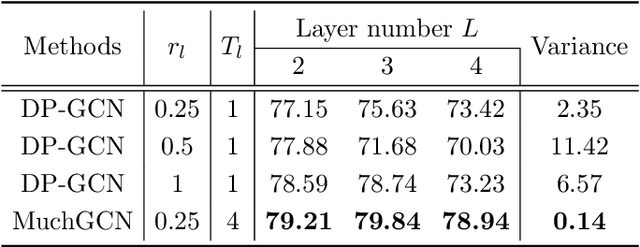
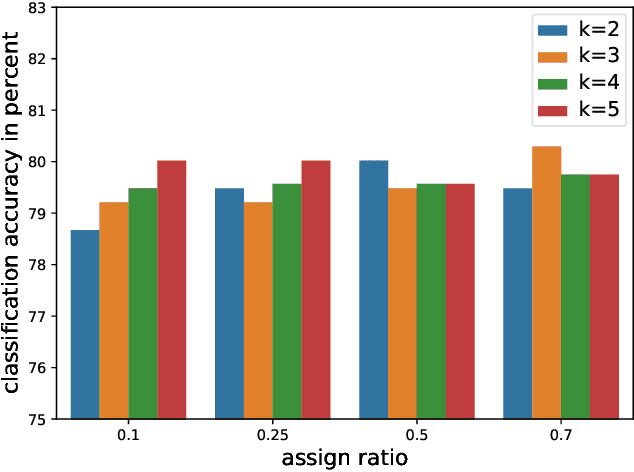
Graph neural networks (GNN) has been demonstrated to be effective in classifying graph structures. To further improve the graph representation learning ability, hierarchical GNN has been explored. It leverages the differentiable pooling to cluster nodes into fixed groups, and generates a coarse-grained structure accompanied with the shrinking of the original graph. However, such clustering would discard some graph information and achieve the suboptimal results. It is because the node inherently has different characteristics or roles, and two non-isomorphic graphs may have the same coarse-grained structure that cannot be distinguished after pooling. To compensate the loss caused by coarse-grained clustering and further advance GNN, we propose a multi-channel graph convolutional networks (MuchGCN). It is motivated by the convolutional neural networks, at which a series of channels are encoded to preserve the comprehensive characteristics of the input image. Thus, we define the specific graph convolutions to learn a series of graph channels at each layer, and pool graphs iteratively to encode the hierarchical structures. Experiments have been carefully carried out to demonstrate the superiority of MuchGCN over the state-of-the-art graph classification algorithms.
Sub-Architecture Ensemble Pruning in Neural Architecture Search
Oct 01, 2019
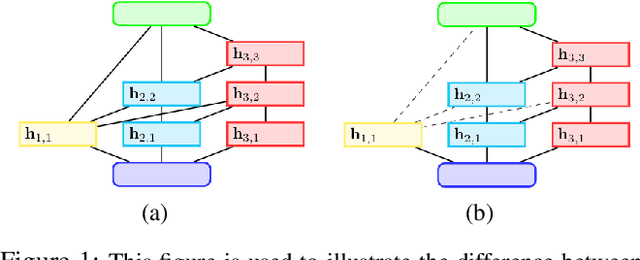
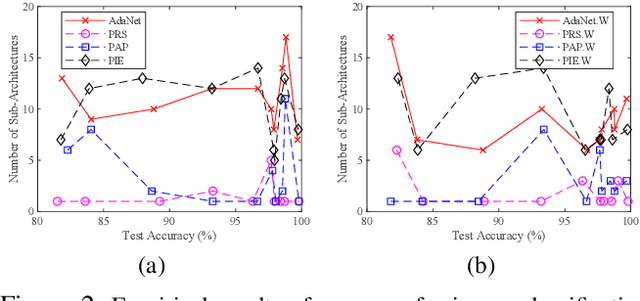
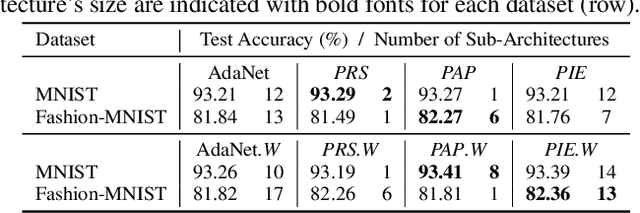
Neural architecture search (NAS) is gaining more and more attention in recent years due to its flexibility and the remarkable capability of reducing the burden of neural network design. To achieve better performance, however, the searching process usually costs massive computation, which might not be affordable to researchers and practitioners. While recent attempts have employed ensemble learning methods to mitigate the enormous computation, an essential characteristic of diversity in ensemble methods is missed out, causing more similar sub-architectures to be gathered and potential redundancy in the final ensemble architecture. To bridge this gap, we propose a pruning method for NAS ensembles, named as ''Sub-Architecture Ensemble Pruning in Neural Architecture Search (SAEP).'' It targets to utilize diversity and achieve sub-ensemble architectures in a smaller size with comparable performance to the unpruned ensemble architectures. Three possible solutions are proposed to decide which subarchitectures should be pruned during the searching process. Experimental results demonstrate the effectiveness of the proposed method in largely reducing the size of ensemble architectures while maintaining the final performance. Moreover, distinct deeper architectures could be discovered if the searched sub-architectures are not diverse enough.