 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicNet: Semi-Supervised Multi-Organ Segmentation via Magic-Cube Partition and Recovery
Dec 29, 2022We propose a novel teacher-student model for semi-supervised multi-organ segmentation. In teacher-student model, data augmentation is usually adopted on unlabeled data to regularize the consistent training between teacher and student. We start from a key perspective that fixed relative locations and variable sizes of different organs can provide distribution information where a multi-organ CT scan is drawn. Thus, we treat the prior anatomy as a strong tool to guide the data augmentation and reduce the mismatch between labeled and unlabeled images for semi-supervised learning. More specifically, we propose a data augmentation strategy based on partition-and-recovery N$^3$ cubes cross- and within- labeled and unlabeled images. Our strategy encourages unlabeled images to learn organ semantics in relative locations from the labeled images (cross-branch) and enhances the learning ability for small organs (within-branch). For within-branch, we further propose to refine the quality of pseudo labels by blending the learned representations from small cubes to incorporate local attributes. Our method is termed as MagicNet, since it treats the CT volume as a magic-cube and $N^3$-cube partition-and-recovery process matches with the rule of playing a magic-cube. Extensive experiments on two public CT multi-organ datasets demonstrate the effectiveness of MagicNet, and noticeably outperforms state-of-the-art semi-supervised medical image segmentation approaches, with +7% DSC improvement on MACT dataset with 10% labeled images.
CLIP-ReID: Exploiting Vision-Language Model for Image Re-Identification without Concrete Text Labels
Dec 07, 2022Pre-trained vision-language models like CLIP have recently shown superior performances on various downstream tasks, including image classification and segmentation. However, in fine-grained image re-identification (ReID), the labels are indexes, lacking concrete text descriptions. Therefore, it remains to be determined how such models could be applied to these tasks. This paper first finds out that simply fine-tuning the visual model initialized by the image encoder in CLIP, has already obtained competitive performances in various ReID tasks. Then we propose a two-stage strategy to facilitate a better visual representation. The key idea is to fully exploit the cross-modal description ability in CLIP through a set of learnable text tokens for each ID and give them to the text encoder to form ambiguous descriptions. In the first training stage, image and text encoders from CLIP keep fixed, and only the text tokens are optimized from scratch by the contrastive loss computed within a batch. In the second stage, the ID-specific text tokens and their encoder become static, providing constraints for fine-tuning the image encoder. With the help of the designed loss in the downstream task, the image encoder is able to represent data as vectors in the feature embedding accurately. The effectiveness of the proposed strategy is validated on several datasets for the person or vehicle ReID tasks. Code is available at https://github.com/Syliz517/CLIP-ReID.
IoU-Enhanced Attention for End-to-End Task Specific Object Detection
Oct 05, 2022
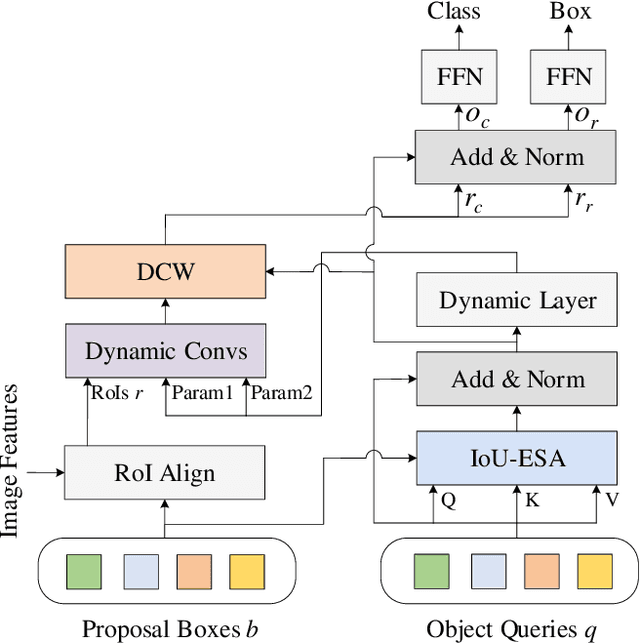

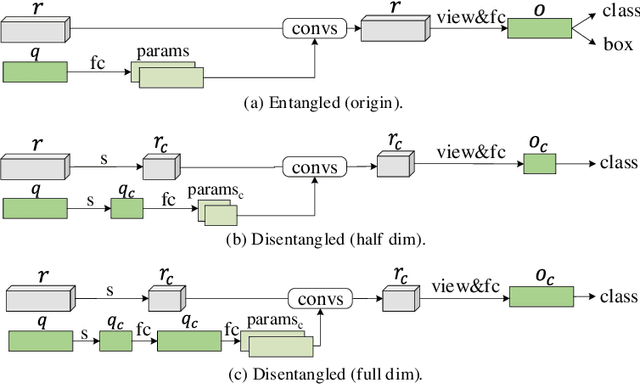
Without densely tiled anchor boxes or grid points in the image, sparse R-CNN achieves promising results through a set of object queries and proposal boxes updated in the cascaded training manner. However, due to the sparse nature and the one-to-one relation between the query and its attending region, it heavily depends on the self attention, which is usually inaccurate in the early training stage. Moreover, in a scene of dense objects, the object query interacts with many irrelevant ones, reducing its uniqueness and harming the performance. This paper proposes to use IoU between different boxes as a prior for the value routing in self attention. The original attention matrix multiplies the same size matrix computed from the IoU of proposal boxes, and they determine the routing scheme so that the irrelevant features can be suppressed. Furthermore, to accurately extract features for both classification and regression, we add two lightweight projection heads to provide the dynamic channel masks based on object query, and they multiply with the output from dynamic convs, making the results suitable for the two different tasks. We validate the proposed scheme on different datasets, including MS-COCO and CrowdHuman, showing that it significantly improves the performance and increases the model convergence speed.
S$^3$R: Self-supervised Spectral Regression for Hyperspectral Histopathology Image Classification
Sep 19, 2022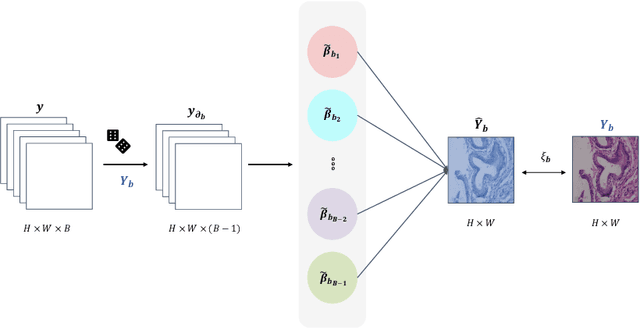
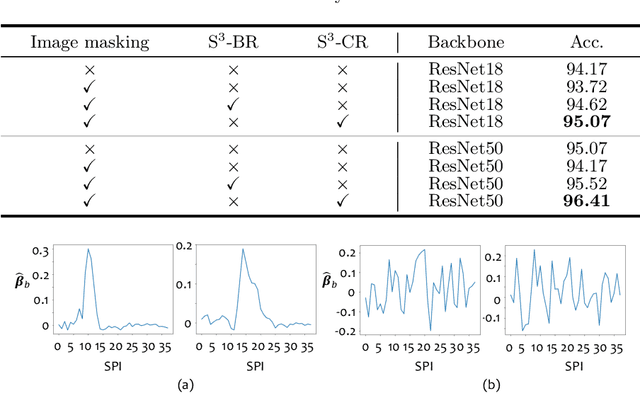
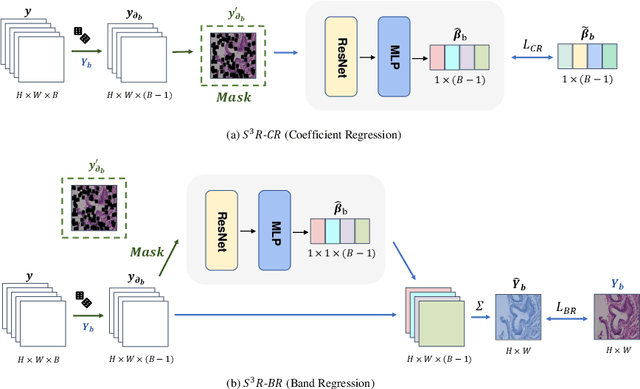
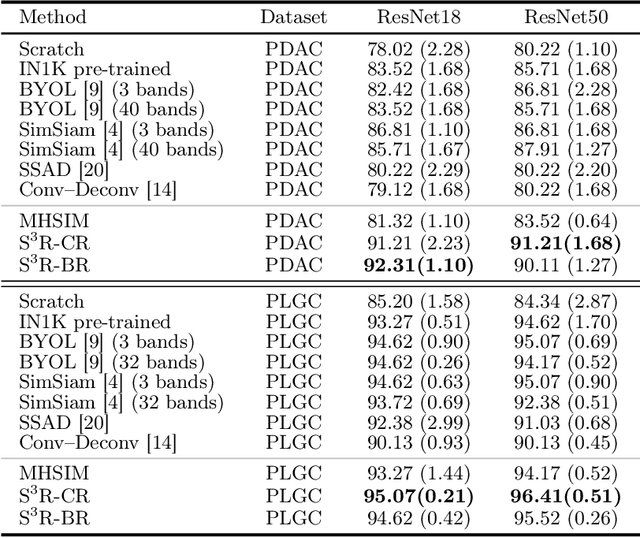
Benefited from the rich and detailed spectral information in hyperspectral images (HSI), HSI offers great potential for a wide variety of medical applications such as computational pathology. But, the lack of adequate annotated data and the high spatiospectral dimensions of HSIs usually make classification networks prone to overfit. Thus, learning a general representation which can be transferred to the downstream tasks is imperative. To our knowledge, no appropriate self-supervised pre-training method has been designed for histopathology HSIs. In this paper, we introduce an efficient and effective Self-supervised Spectral Regression (S$^3$R) method, which exploits the low rank characteristic in the spectral domain of HSI. More concretely, we propose to learn a set of linear coefficients that can be used to represent one band by the remaining bands via masking out these bands. Then, the band is restored by using the learned coefficients to reweight the remaining bands. Two pre-text tasks are designed: (1)S$^3$R-CR, which regresses the linear coefficients, so that the pre-trained model understands the inherent structures of HSIs and the pathological characteristics of different morphologies; (2)S$^3$R-BR, which regresses the missing band, making the model to learn the holistic semantics of HSIs. Compared to prior arts i.e., contrastive learning methods, which focuses on natural images, S$^3$R converges at least 3 times faster, and achieves significant improvements up to 14% in accuracy when transferring to HSI classification tasks.
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Aug 01, 2022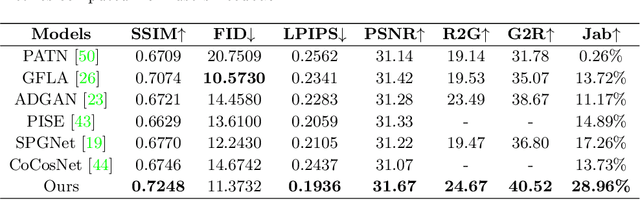
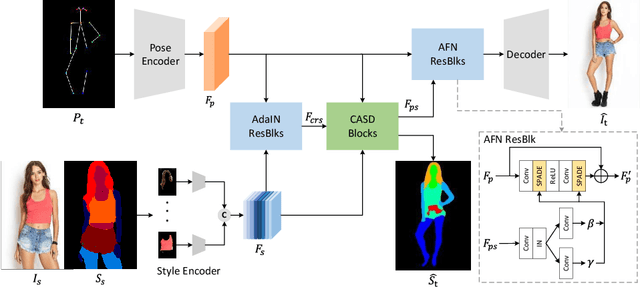
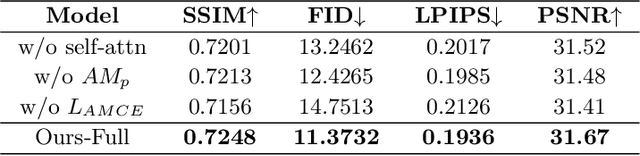
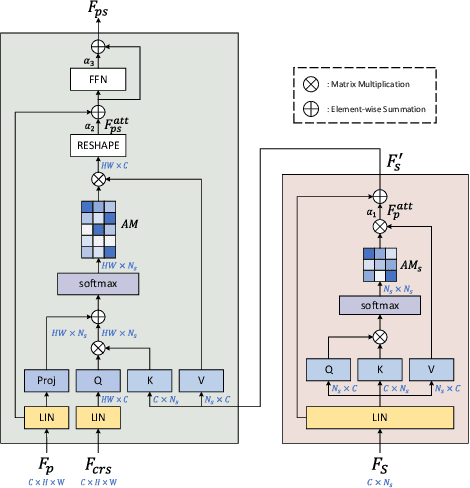
Controllable person image synthesis task enables a wide range of applications through explicit control over body pose and appearance. In this paper, we propose a cross attention based style distribution module that computes between the source semantic styles and target pose for pose transfer. The module intentionally selects the style represented by each semantic and distributes them according to the target pose. The attention matrix in cross attention expresses the dynamic similarities between the target pose and the source styles for all semantics. Therefore, it can be utilized to route the color and texture from the source image, and is further constrained by the target parsing map to achieve a clearer objective. At the same time, to encode the source appearance accurately, the self attention among different semantic styles is also added. The effectiveness of our model is validated quantitatively and qualitatively on pose transfer and virtual try-on tasks.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022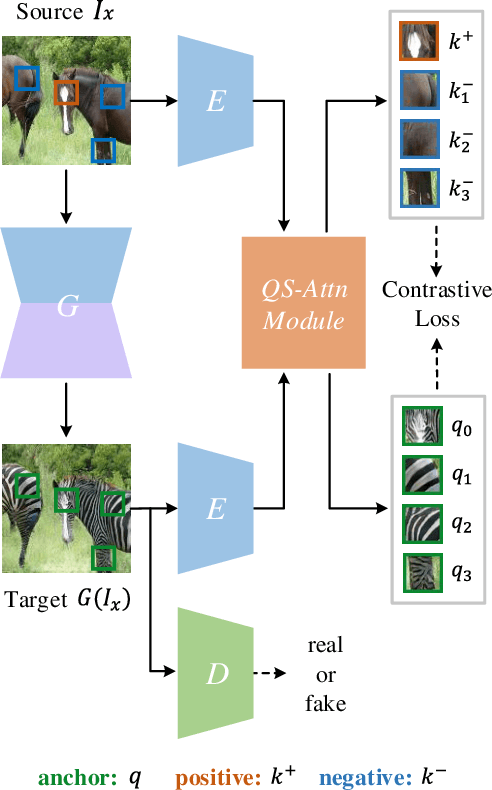
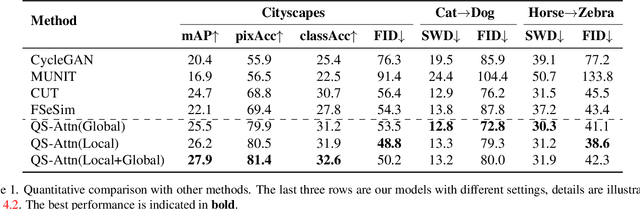

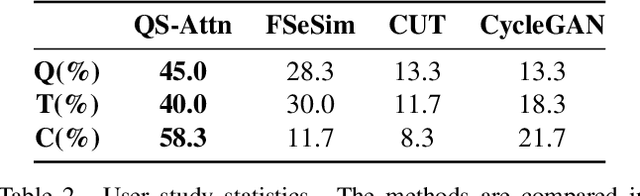
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Style Transformer for Image Inversion and Editing
Mar 15, 2022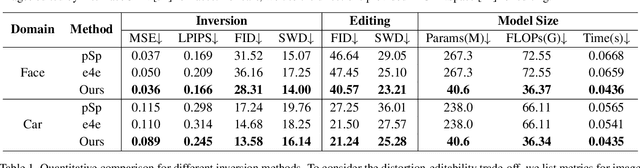
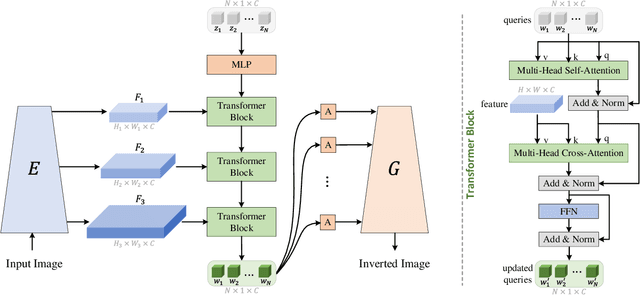
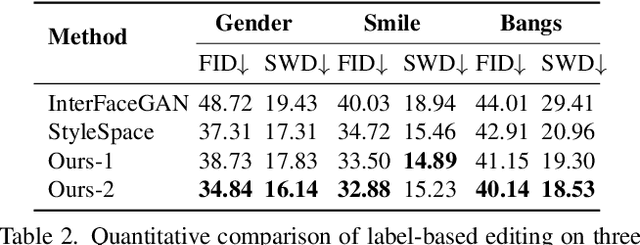
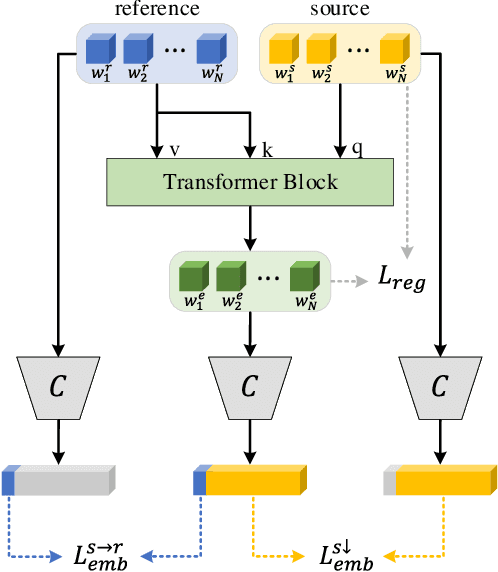
Existing GAN inversion methods fail to provide latent codes for reliable reconstruction and flexible editing simultaneously. This paper presents a transformer-based image inversion and editing model for pretrained StyleGAN which is not only with less distortions, but also of high quality and flexibility for editing. The proposed model employs a CNN encoder to provide multi-scale image features as keys and values. Meanwhile it regards the style code to be determined for different layers of the generator as queries. It first initializes query tokens as learnable parameters and maps them into W+ space. Then the multi-stage alternate self- and cross-attention are utilized, updating queries with the purpose of inverting the input by the generator. Moreover, based on the inverted code, we investigate the reference- and label-based attribute editing through a pretrained latent classifier, and achieve flexible image-to-image translation with high quality results. Extensive experiments are carried out, showing better performances on both inversion and editing tasks within StyleGAN.
Deep Residual Fourier Transformation for Single Image Deblurring
Nov 23, 2021
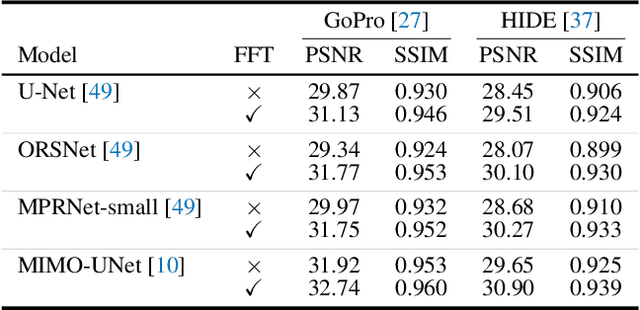
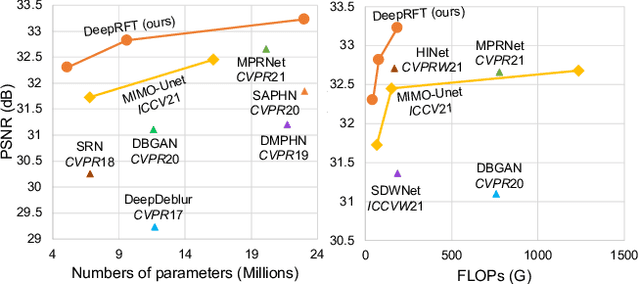
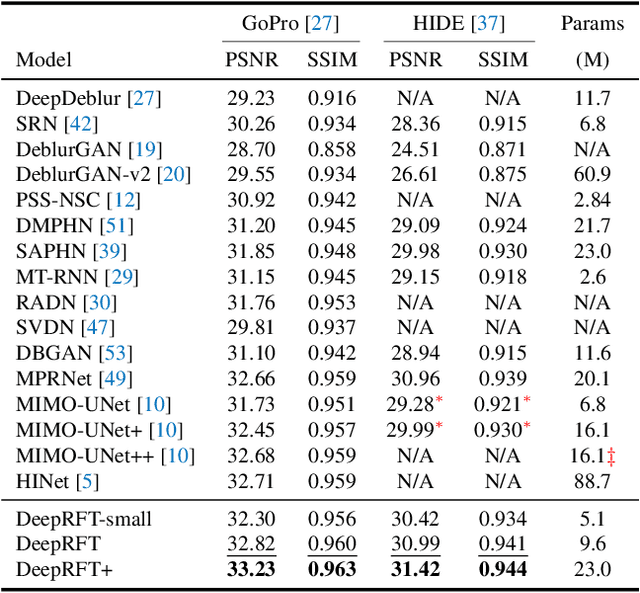
It has been a common practice to adopt the ResBlock, which learns the difference between blurry and sharp image pairs, in end-to-end image deblurring architectures. Reconstructing a sharp image from its blurry counterpart requires changes regarding both low- and high-frequency information. Although conventional ResBlock may have good abilities in capturing the high-frequency components of images, it tends to overlook the low-frequency information. Moreover, ResBlock usually fails to felicitously model the long-distance information which is non-trivial in reconstructing a sharp image from its blurry counterpart. In this paper, we present a Residual Fast Fourier Transform with Convolution Block (Res FFT-Conv Block), capable of capturing both long-term and short-term interactions, while integrating both low- and high-frequency residual information. Res FFT-Conv Block is a conceptually simple yet computationally efficient, and plug-and-play block, leading to remarkable performance gains in different architectures. With Res FFT-Conv Block, we further propose a Deep Residual Fourier Transformation (DeepRFT) framework, based upon MIMO-UNet, achieving state-of-the-art image deblurring performance on GoPro, HIDE, RealBlur and DPDD datasets. Experiments show our DeepRFT can boost image deblurring performance significantly (e.g., with 1.09 dB improvement in PSNR on GoPro dataset compared with MIMO-UNet), and DeepRFT+ even reaches 33.23 dB in PSNR on GoPro dataset.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021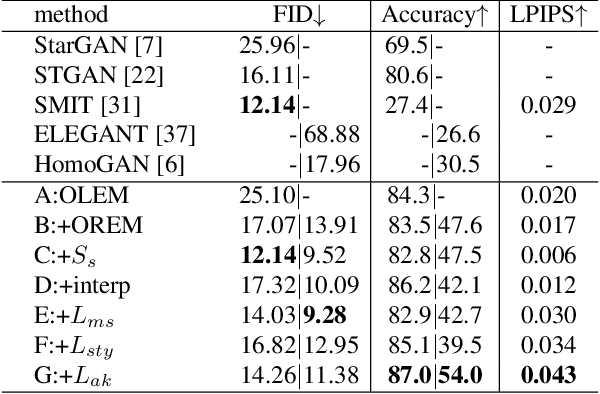
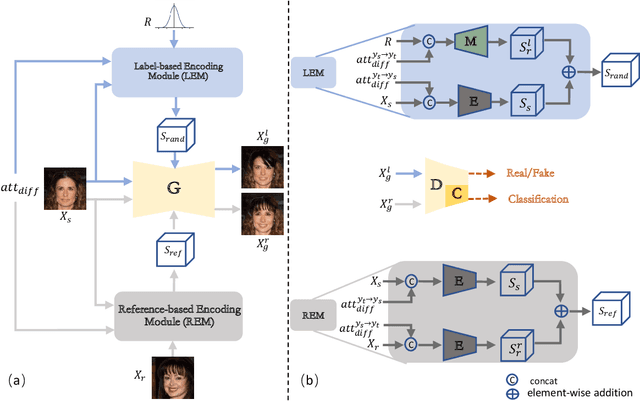


The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021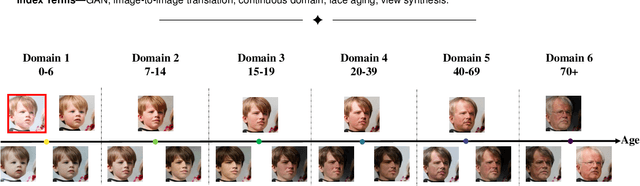

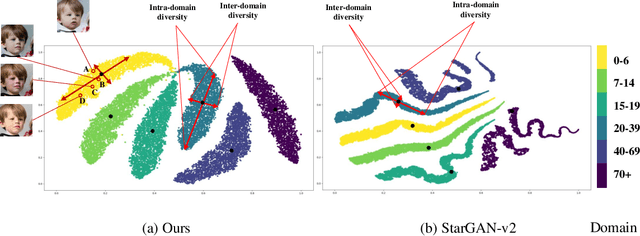
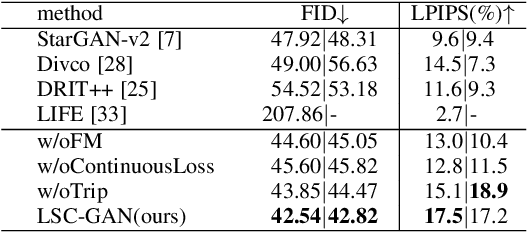
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.