 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating NODE with Pre-trained Neural Differential Operator for Learning Dynamics
Jun 09, 2021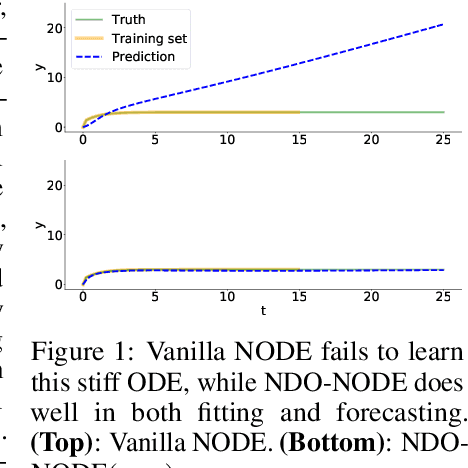
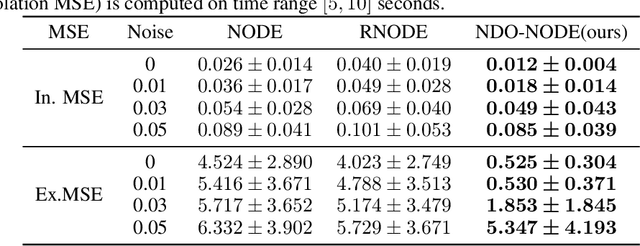
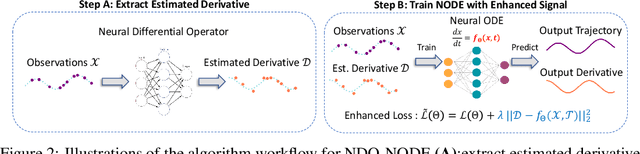
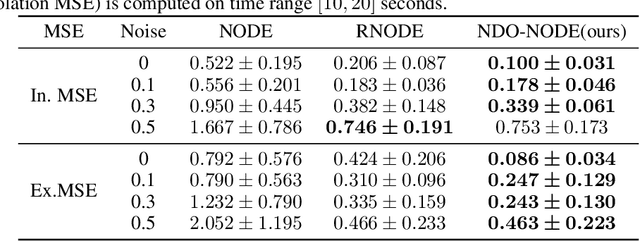
Learning dynamics governed by differential equations is crucial for predicting and controlling the systems in science and engineering. Neural Ordinary Differential Equation (NODE), a deep learning model integrated with differential equations, learns the dynamics directly from the samples on the trajectory and shows great promise in the scientific field. However, the training of NODE highly depends on the numerical solver, which can amplify numerical noise and be unstable, especially for ill-conditioned dynamical systems. In this paper, to reduce the reliance on the numerical solver, we propose to enhance the supervised signal in learning dynamics. Specifically, beyond learning directly from the trajectory samples, we pre-train a neural differential operator (NDO) to output an estimation of the derivatives to serve as an additional supervised signal. The NDO is pre-trained on a class of symbolic functions, and it learns the mapping between the trajectory samples of these functions to their derivatives. We provide theoretical guarantee on that the output of NDO can well approximate the ground truth derivatives by proper tuning the complexity of the library. To leverage both the trajectory signal and the estimated derivatives from NDO, we propose an algorithm called NDO-NODE, in which the loss function contains two terms: the fitness on the true trajectory samples and the fitness on the estimated derivatives that are output by the pre-trained NDO. Experiments on various of dynamics show that our proposed NDO-NODE can consistently improve the forecasting accuracy.
Machine-Learning Non-Conservative Dynamics for New-Physics Detection
Jun 02, 2021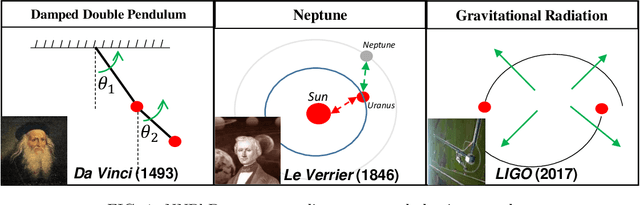
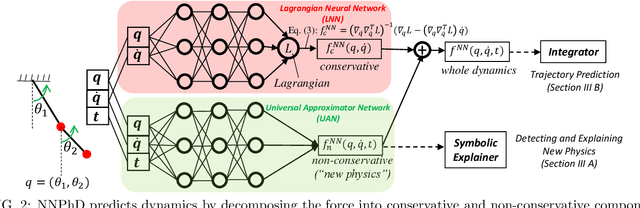
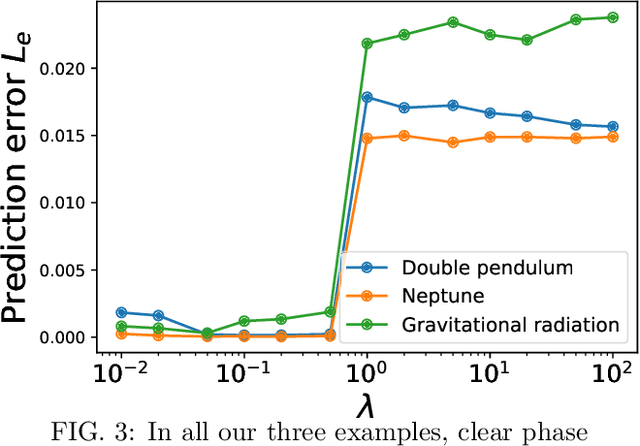
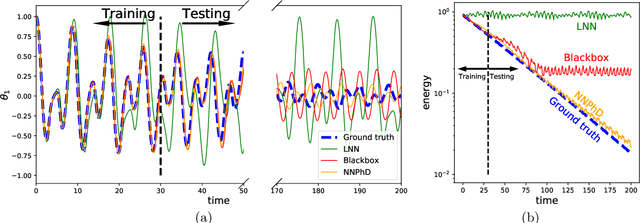
Energy conservation is a basic physics principle, the breakdown of which often implies new physics. This paper presents a method for data-driven "new physics" discovery. Specifically, given a trajectory governed by unknown forces, our Neural New-Physics Detector (NNPhD) aims to detect new physics by decomposing the force field into conservative and non-conservative components, which are represented by a Lagrangian Neural Network (LNN) and a universal approximator network (UAN), respectively, trained to minimize the force recovery error plus a constant $\lambda$ times the magnitude of the predicted non-conservative force. We show that a phase transition occurs at $\lambda$=1, universally for arbitrary forces. We demonstrate that NNPhD successfully discovers new physics in toy numerical experiments, rediscovering friction (1493) from a damped double pendulum, Neptune from Uranus' orbit (1846) and gravitational waves (2017) from an inspiraling orbit. We also show how NNPhD coupled with an integrator outperforms previous methods for predicting the future of a damped double pendulum.
UniDrop: A Simple yet Effective Technique to Improve Transformer without Extra Cost
Apr 11, 2021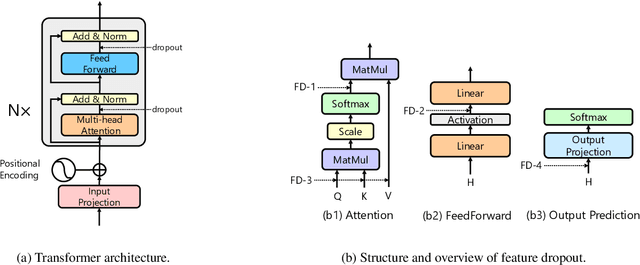

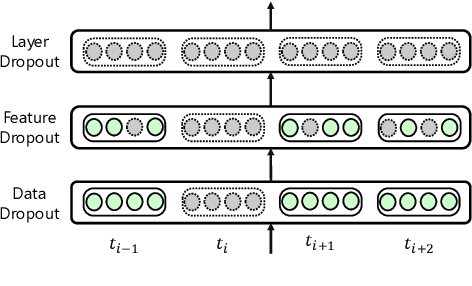

Transformer architecture achieves great success in abundant natural language processing tasks. The over-parameterization of the Transformer model has motivated plenty of works to alleviate its overfitting for superior performances. With some explorations, we find simple techniques such as dropout, can greatly boost model performance with a careful design. Therefore, in this paper, we integrate different dropout techniques into the training of Transformer models. Specifically, we propose an approach named UniDrop to unites three different dropout techniques from fine-grain to coarse-grain, i.e., feature dropout, structure dropout, and data dropout. Theoretically, we demonstrate that these three dropouts play different roles from regularization perspectives. Empirically, we conduct experiments on both neural machine translation and text classification benchmark datasets. Extensive results indicate that Transformer with UniDrop can achieve around 1.5 BLEU improvement on IWSLT14 translation tasks, and better accuracy for the classification even using strong pre-trained RoBERTa as backbone.
Towards Accelerating Training of Batch Normalization: A Manifold Perspective
Jan 08, 2021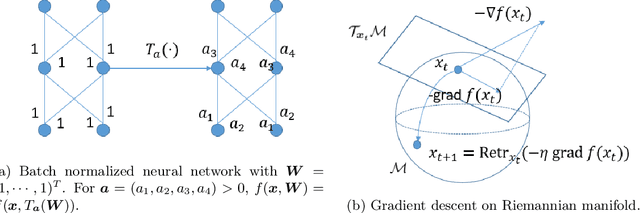
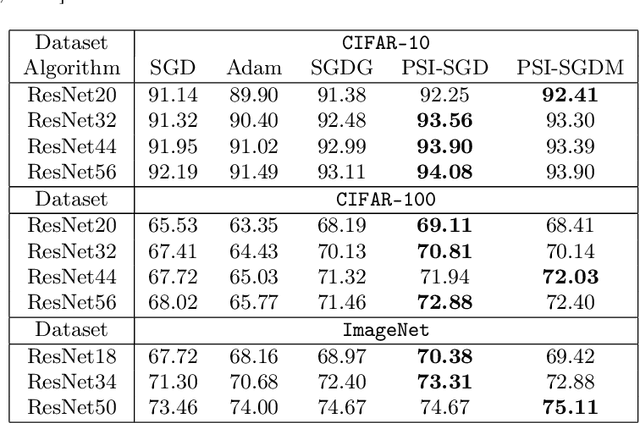


Batch normalization (BN) has become a crucial component across diverse deep neural networks. The network with BN is invariant to positively linear re-scaling of weights, which makes there exist infinite functionally equivalent networks with various scales of weights. However, optimizing these equivalent networks with the first-order method such as stochastic gradient descent will converge to different local optima owing to different gradients across training. To alleviate this, we propose a quotient manifold \emph{PSI manifold}, in which all the equivalent weights of the network with BN are regarded as the same one element. Then, gradient descent and stochastic gradient descent on the PSI manifold are also constructed. The two algorithms guarantee that every group of equivalent weights (caused by positively re-scaling) converge to the equivalent optima. Besides that, we give the convergence rate of the proposed algorithms on PSI manifold and justify that they accelerate training compared with the algorithms on the Euclidean weight space. Empirical studies show that our algorithms can consistently achieve better performances over various experimental settings.
The Implicit Bias for Adaptive Optimization Algorithms on Homogeneous Neural Networks
Dec 11, 2020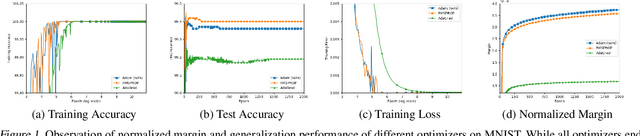
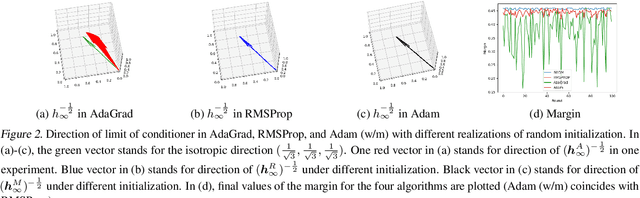
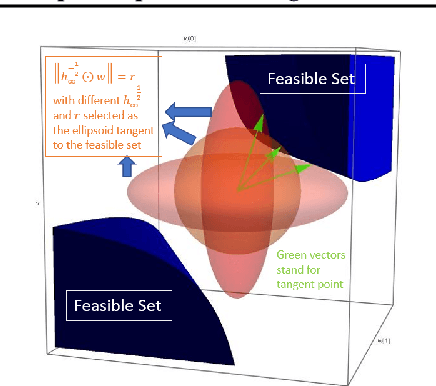
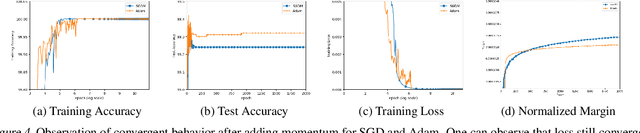
Despite their overwhelming capacity to overfit, deep neural networks trained by specific optimization algorithms tend to generalize relatively well to unseen data. Recently, researchers explained it by investigating the implicit bias of optimization algorithms. A remarkable progress is the work [18], which proves gradient descent (GD) maximizes the margin of homogeneous deep neural networks. Except the first-order optimization algorithms like GD, adaptive algorithms such as AdaGrad, RMSProp and Adam are popular owing to its rapid training process. Meanwhile, numerous works have provided empirical evidence that adaptive methods may suffer from poor generalization performance. However, theoretical explanation for the generalization of adaptive optimization algorithms is still lacking. In this paper, we study the implicit bias of adaptive optimization algorithms on homogeneous neural networks. In particular, we study the convergent direction of parameters when they are optimizing the logistic loss. We prove that the convergent direction of RMSProp is the same with GD, while for AdaGrad, the convergent direction depends on the adaptive conditioner. Technically, we provide a unified framework to analyze convergent direction of adaptive optimization algorithms by constructing novel and nontrivial adaptive gradient flow and surrogate margin. The theoretical findings explain the superiority on generalization of exponential moving average strategy that is adopted by RMSProp and Adam. To the best of knowledge, it is the first work to study the convergent direction of adaptive optimizations on non-linear deep neural networks
Dynamic of Stochastic Gradient Descent with State-Dependent Noise
Jul 06, 2020
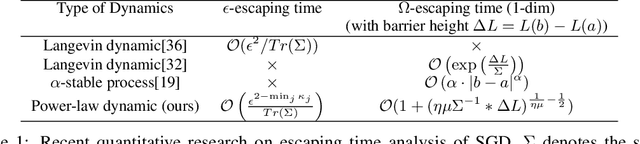
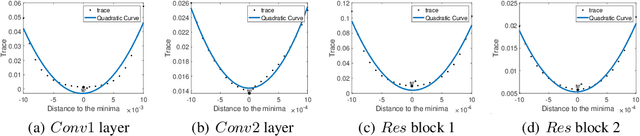
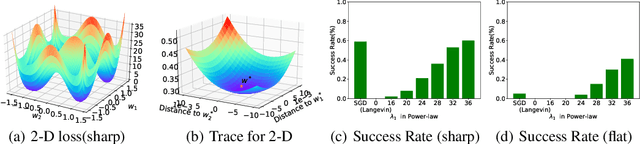
Stochastic gradient descent (SGD) and its variants are mainstream methods to train deep neural networks. Since neural networks are non-convex, more and more works study the dynamic behavior of SGD and the impact to its generalization, especially the escaping efficiency from local minima. However, these works take the over-simplified assumption that the covariance of the noise in SGD is (or can be upper bounded by) constant, although it is actually state-dependent. In this work, we conduct a formal study on the dynamic behavior of SGD with state-dependent noise. Specifically, we show that the covariance of the noise of SGD in the local region of the local minima is a quadratic function of the state. Thus, we propose a novel power-law dynamic with state-dependent diffusion to approximate the dynamic of SGD. We prove that, power-law dynamic can escape from sharp minima exponentially faster than flat minima, while the previous dynamics can only escape sharp minima polynomially faster than flat minima. Our experiments well verified our theoretical results. Inspired by our theory, we propose to add additional state-dependent noise into (large-batch) SGD to further improve its generalization ability. Experiments verify that our method is effective.
Interpreting Basis Path Set in Neural Networks
Oct 18, 2019



Based on basis path set, G-SGD algorithm significantly outperforms conventional SGD algorithm in optimizing neural networks. However, how the inner mechanism of basis paths work remains mysterious. From the aspect of graph theory, this paper defines basis path, investigates structure properties of basis paths in regular fully connected neural network and interprets the graph representation of basis path set. Moreover, we propose hierarchical algorithm HBPS to find basis path set B in fully connected neural network by decomposing the network into several independent and parallel substructures. Algorithm HBPS demands that there doesn't exist shared edges between any two independent substructure paths.
Reinforcement Learning with Dynamic Boltzmann Softmax Updates
Mar 15, 2019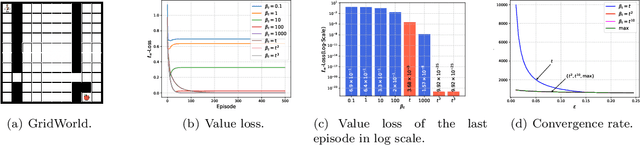
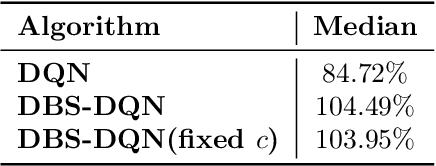
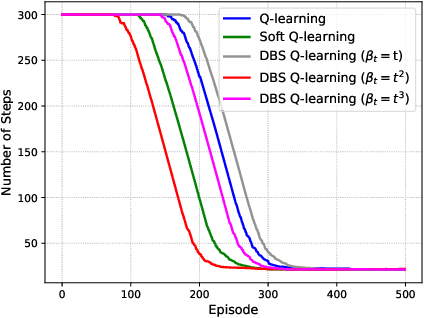
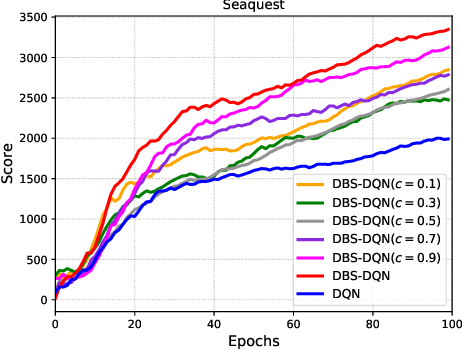
Value function estimation is an important task in reinforcement learning, i.e., prediction. The commonly used operator for prediction in Q-learning is the hard max operator, which always commits to the maximum action-value according to current estimation. Such `hard' updating scheme results in pure exploitation and may lead to misbehavior due to noise in stochastic environments. Thus, it is critical to balancing exploration and exploitation in value function estimation. The Boltzmann softmax operator has a greater capability in exploring potential action-values. However, it does not satisfy the non-expansion property, and its direct use may fail to converge even in value iteration. In this paper, we propose to update the value function with dynamic Boltzmann softmax (DBS) operator in value function estimation, which has good convergence property in the setting of planning and learning. Moreover, we prove that dynamic Boltzmann softmax updates can eliminate the overestimation phenomenon introduced by the hard max operator. Experimental results on GridWorld show that the DBS operator enables convergence and a better trade-off between exploration and exploitation in value function estimation. Finally, we propose the DBS-DQN algorithm by generalizing the dynamic Boltzmann softmax update in deep Q-network, which outperforms DQN substantially in 40 out of 49 Atari games.
Positively Scale-Invariant Flatness of ReLU Neural Networks
Mar 06, 2019
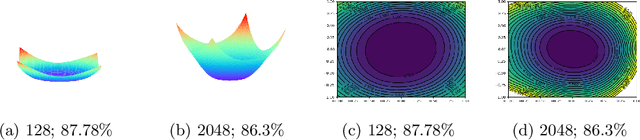
It was empirically confirmed by Keskar et al.\cite{SharpMinima} that flatter minima generalize better. However, for the popular ReLU network, sharp minimum can also generalize well \cite{SharpMinimacan}. The conclusion demonstrates that the existing definitions of flatness fail to account for the complex geometry of ReLU neural networks because they can't cover the Positively Scale-Invariant (PSI) property of ReLU network. In this paper, we formalize the PSI causes problem of existing definitions of flatness and propose a new description of flatness - \emph{PSI-flatness}. PSI-flatness is defined on the values of basis paths \cite{GSGD} instead of weights. Values of basis paths have been shown to be the PSI-variables and can sufficiently represent the ReLU neural networks which ensure the PSI property of PSI-flatness. Then we study the relation between PSI-flatness and generalization theoretically and empirically. First, we formulate a generalization bound based on PSI-flatness which shows generalization error decreasing with the ratio between the largest basis path value and the smallest basis path value. That is to say, the minimum with balanced values of basis paths will more likely to be flatter and generalize better. Finally. we visualize the PSI-flatness of loss surface around two learned models which indicates the minimum with smaller PSI-flatness can indeed generalize better.
$\mathcal{G}$-SGD: Optimizing ReLU Neural Networks in its Positively Scale-Invariant Space
Oct 09, 2018



It is well known that neural networks with rectified linear units (ReLU) activation functions are positively scale-invariant. Conventional algorithms like stochastic gradient descent optimize the neural networks in the vector space of weights, which is, however, not positively scale-invariant. This mismatch may lead to problems during the optimization process. Then, a natural question is: \emph{can we construct a new vector space that is positively scale-invariant and sufficient to represent ReLU neural networks so as to better facilitate the optimization process }? In this paper, we provide our positive answer to this question. First, we conduct a formal study on the positive scaling operators which forms a transformation group, denoted as $\mathcal{G}$. We show that the value of a path (i.e. the product of the weights along the path) in the neural network is invariant to positive scaling and prove that the value vector of all the paths is sufficient to represent the neural networks under mild conditions. Second, we show that one can identify some basis paths out of all the paths and prove that the linear span of their value vectors (denoted as $\mathcal{G}$-space) is an invariant space with lower dimension under the positive scaling group. Finally, we design stochastic gradient descent algorithm in $\mathcal{G}$-space (abbreviated as $\mathcal{G}$-SGD) to optimize the value vector of the basis paths of neural networks with little extra cost by leveraging back-propagation. Our experiments show that $\mathcal{G}$-SGD significantly outperforms the conventional SGD algorithm in optimizing ReLU networks on benchmark datasets.