 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation
Apr 25, 2022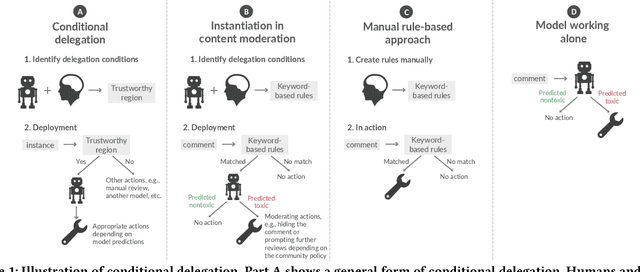

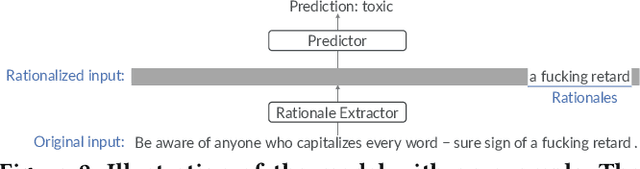
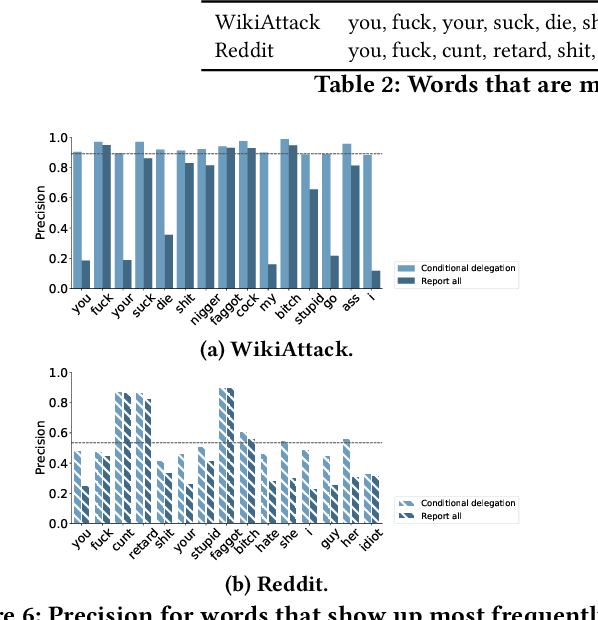
Despite impressive performance in many benchmark datasets, AI models can still make mistakes, especially among out-of-distribution examples. It remains an open question how such imperfect models can be used effectively in collaboration with humans. Prior work has focused on AI assistance that helps people make individual high-stakes decisions, which is not scalable for a large amount of relatively low-stakes decisions, e.g., moderating social media comments. Instead, we propose conditional delegation as an alternative paradigm for human-AI collaboration where humans create rules to indicate trustworthy regions of a model. Using content moderation as a testbed, we develop novel interfaces to assist humans in creating conditional delegation rules and conduct a randomized experiment with two datasets to simulate in-distribution and out-of-distribution scenarios. Our study demonstrates the promise of conditional delegation in improving model performance and provides insights into design for this novel paradigm, including the effect of AI explanations.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022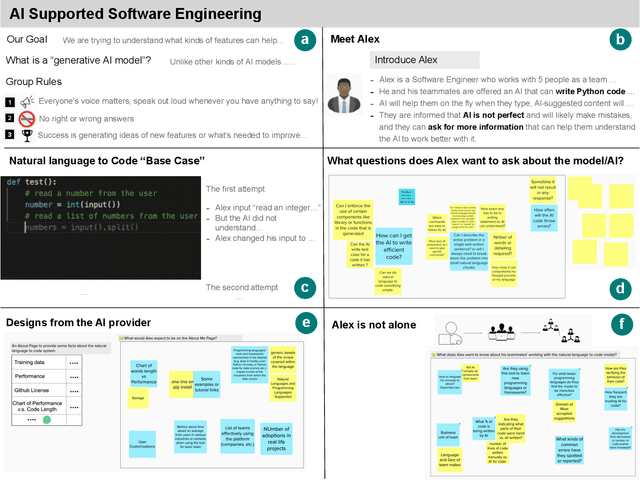
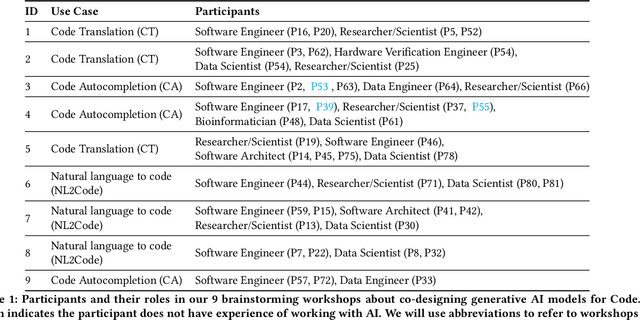

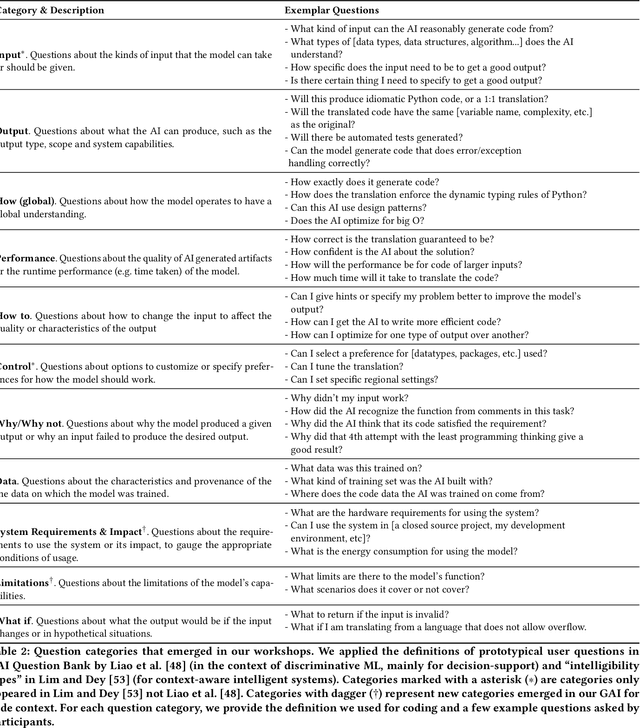
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.
Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies
Dec 21, 2021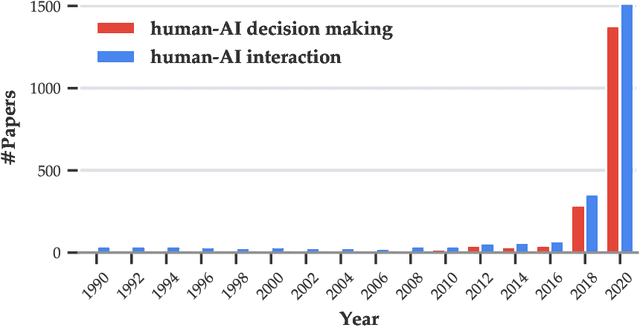
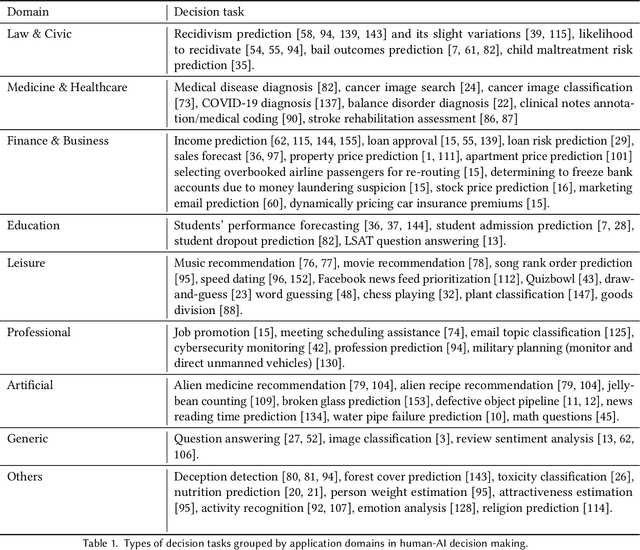
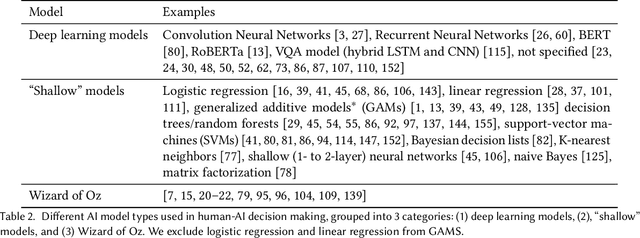
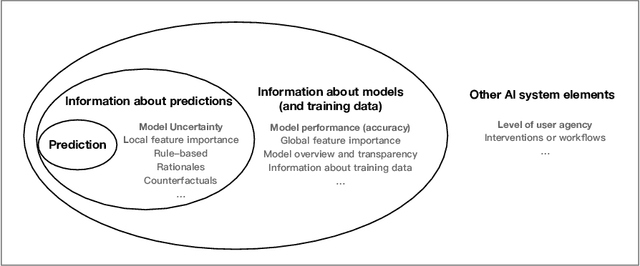
As AI systems demonstrate increasingly strong predictive performance, their adoption has grown in numerous domains. However, in high-stakes domains such as criminal justice and healthcare, full automation is often not desirable due to safety, ethical, and legal concerns, yet fully manual approaches can be inaccurate and time consuming. As a result, there is growing interest in the research community to augment human decision making with AI assistance. Besides developing AI technologies for this purpose, the emerging field of human-AI decision making must embrace empirical approaches to form a foundational understanding of how humans interact and work with AI to make decisions. To invite and help structure research efforts towards a science of understanding and improving human-AI decision making, we survey recent literature of empirical human-subject studies on this topic. We summarize the study design choices made in over 100 papers in three important aspects: (1) decision tasks, (2) AI models and AI assistance elements, and (3) evaluation metrics. For each aspect, we summarize current trends, discuss gaps in current practices of the field, and make a list of recommendations for future research. Our survey highlights the need to develop common frameworks to account for the design and research spaces of human-AI decision making, so that researchers can make rigorous choices in study design, and the research community can build on each other's work and produce generalizable scientific knowledge. We also hope this survey will serve as a bridge for HCI and AI communities to work together to mutually shape the empirical science and computational technologies for human-AI decision making.
Human-Centered Explainable AI (XAI): From Algorithms to User Experiences
Oct 23, 2021
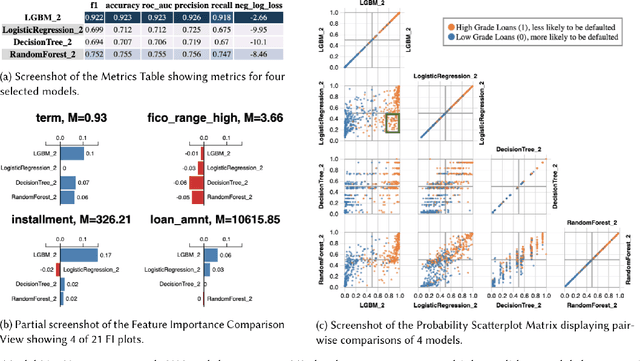
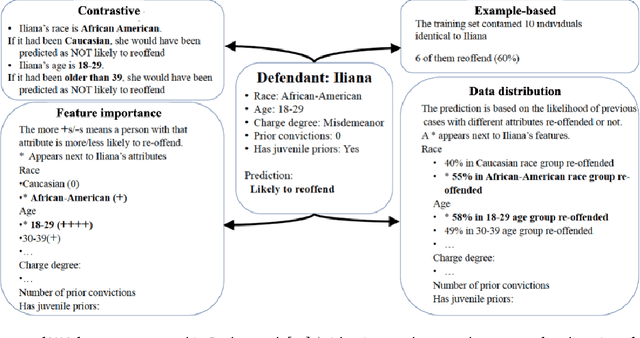
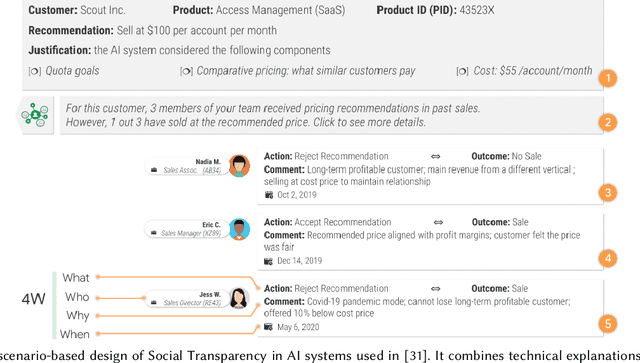
As a technical sub-field of artificial intelligence (AI), explainable AI (XAI) has produced a vast collection of algorithms, providing a toolbox for researchers and practitioners to build XAI applications. With the rich application opportunities, explainability has moved beyond a demand by data scientists or researchers to comprehend the models they are developing, to become an essential requirement for people to trust and adopt AI deployed in numerous domains. However, explainability is an inherently human-centric property and the field is starting to embrace human-centered approaches. Human-computer interaction (HCI) research and user experience (UX) design in this area are becoming increasingly important. In this chapter, we begin with a high-level overview of the technical landscape of XAI algorithms, then selectively survey our own and other recent HCI works that take human-centered approaches to design, evaluate, provide conceptual and methodological tools for XAI. We ask the question "\textit{what are human-centered approaches doing for XAI}" and highlight three roles that they play in shaping XAI technologies by helping navigate, assess and expand the XAI toolbox: to drive technical choices by users' explainability needs, to uncover pitfalls of existing XAI methods and inform new methods, and to provide conceptual frameworks for human-compatible XAI.
AI Explainability 360: Impact and Design
Sep 24, 2021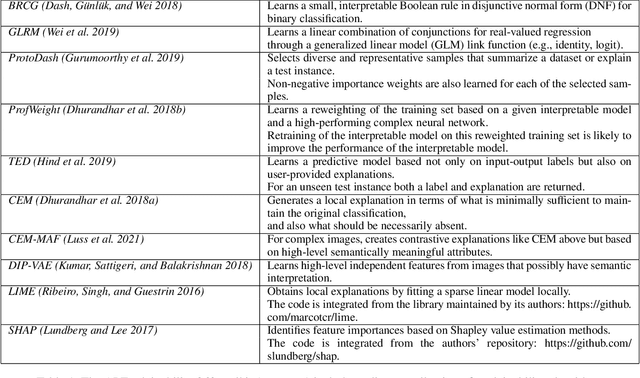
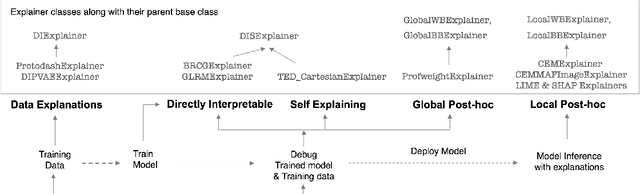

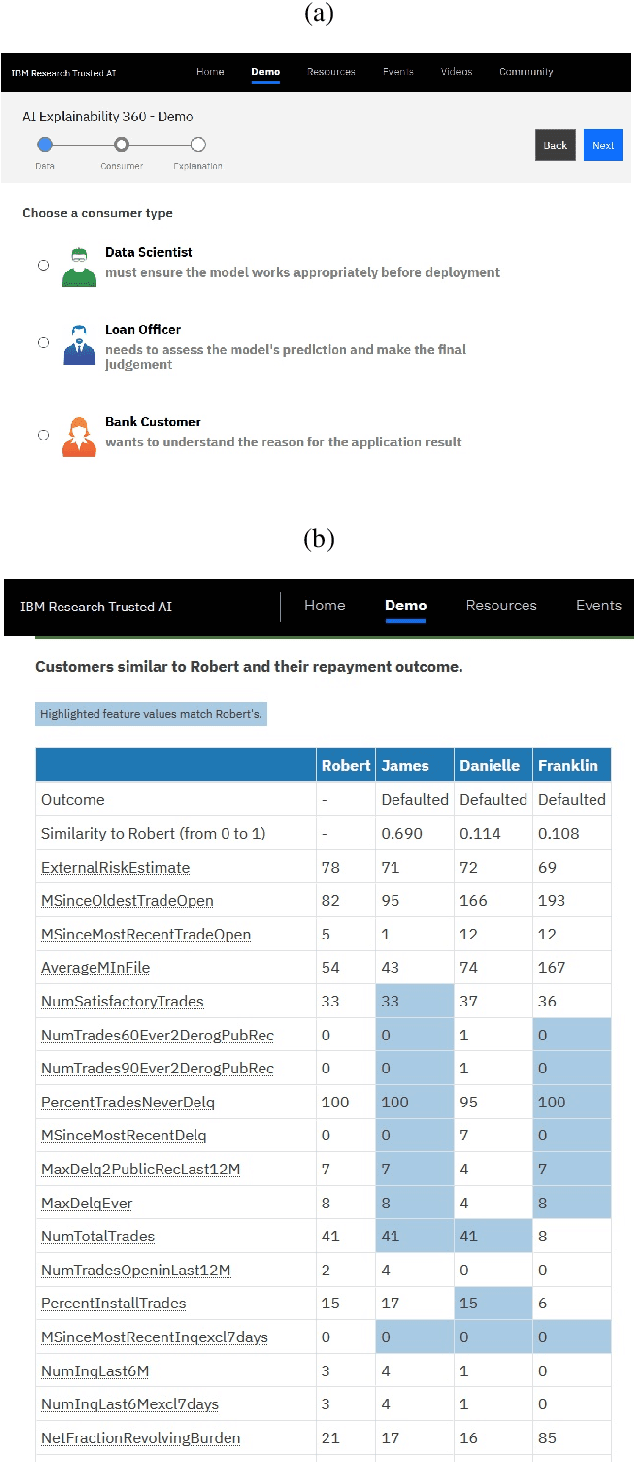
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
The Who in Explainable AI: How AI Background Shapes Perceptions of AI Explanations
Jul 28, 2021
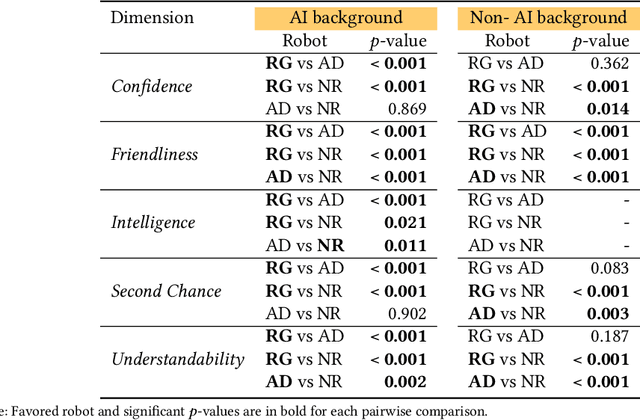
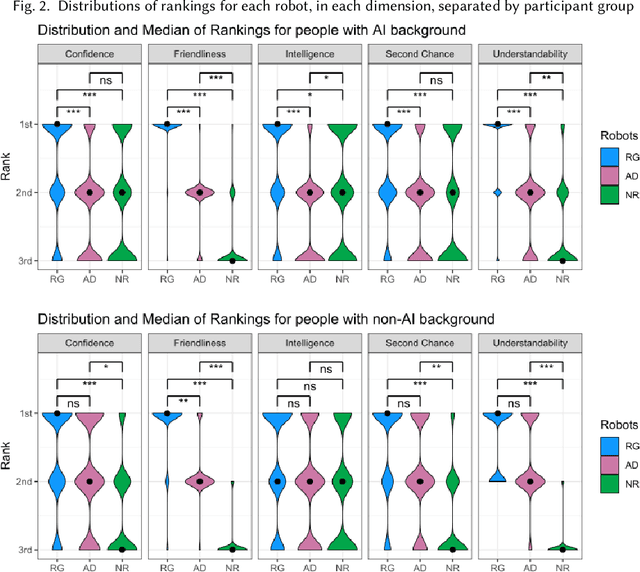
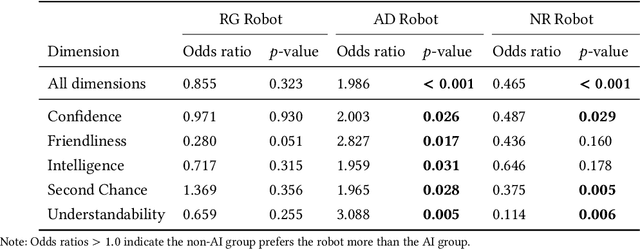
Explainability of AI systems is critical for users to take informed actions and hold systems accountable. While "opening the opaque box" is important, understanding who opens the box can govern if the Human-AI interaction is effective. In this paper, we conduct a mixed-methods study of how two different groups of whos--people with and without a background in AI--perceive different types of AI explanations. These groups were chosen to look at how disparities in AI backgrounds can exacerbate the creator-consumer gap. We quantitatively share what the perceptions are along five dimensions: confidence, intelligence, understandability, second chance, and friendliness. Qualitatively, we highlight how the AI background influences each group's interpretations and elucidate why the differences might exist through the lenses of appropriation and cognitive heuristics. We find that (1) both groups had unwarranted faith in numbers, to different extents and for different reasons, (2) each group found explanatory values in different explanations that went beyond the usage we designed them for, and (3) each group had different requirements of what counts as humanlike explanations. Using our findings, we discuss potential negative consequences such as harmful manipulation of user trust and propose design interventions to mitigate them. By bringing conscious awareness to how and why AI backgrounds shape perceptions of potential creators and consumers in XAI, our work takes a formative step in advancing a pluralistic Human-centered Explainable AI discourse.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021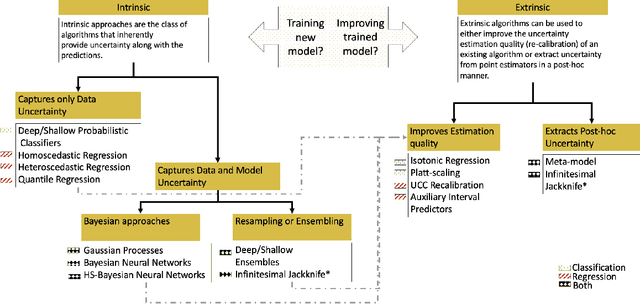
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
Model LineUpper: Supporting Interactive Model Comparison at Multiple Levels for AutoML
Apr 09, 2021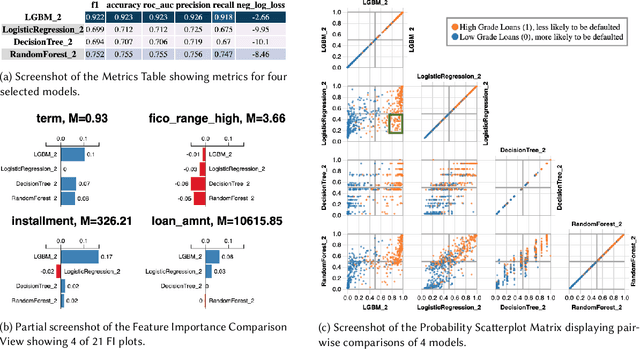
Automated Machine Learning (AutoML) is a rapidly growing set of technologies that automate the model development pipeline by searching model space and generating candidate models. A critical, final step of AutoML is human selection of a final model from dozens of candidates. In current AutoML systems, selection is supported only by performance metrics. Prior work has shown that in practice, people evaluate ML models based on additional criteria, such as the way a model makes predictions. Comparison may happen at multiple levels, from types of errors, to feature importance, to how the model makes predictions of specific instances. We developed \tool{} to support interactive model comparison for AutoML by integrating multiple Explainable AI (XAI) and visualization techniques. We conducted a user study in which we both evaluated the system and used it as a technology probe to understand how users perform model comparison in an AutoML system. We discuss design implications for utilizing XAI techniques for model comparison and supporting the unique needs of data scientists in comparing AutoML models.
Question-Driven Design Process for Explainable AI User Experiences
Apr 08, 2021
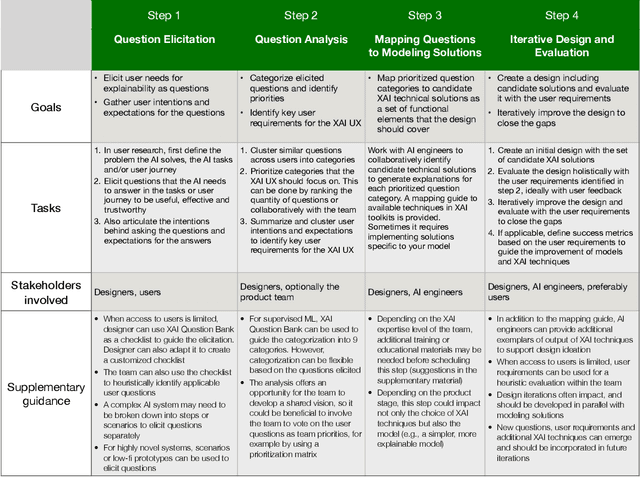
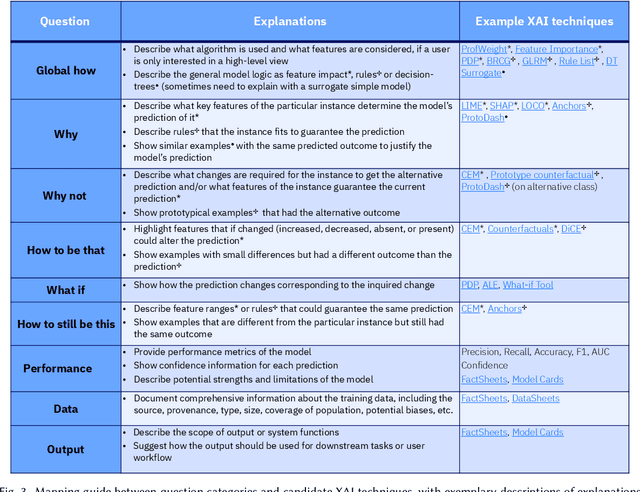
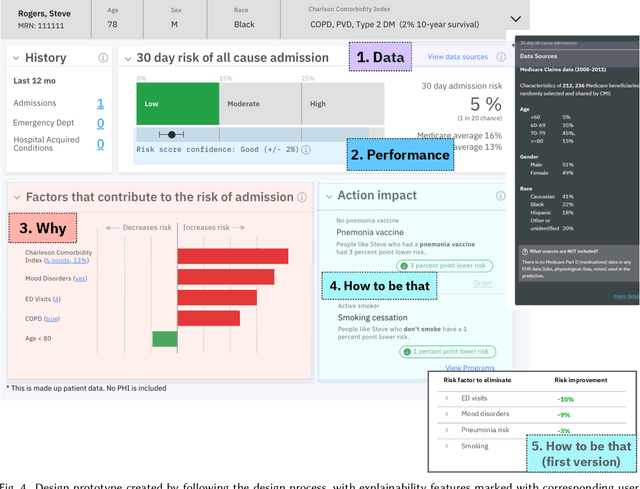
A pervasive design issue of AI systems is their explainability--how to provide appropriate information to help users understand the AI. The technical field of explainable AI (XAI) has produced a rich toolbox of techniques. Designers are now tasked with the challenges of how to select the most suitable XAI techniques and translate them into UX solutions. Informed by our previous work studying design challenges around XAI UX, this work proposes a design process to tackle these challenges. We review our and related prior work to identify requirements that the process should fulfill, and accordingly, propose a Question-Driven Design Process that grounds the user needs, choices of XAI techniques, design, and evaluation of XAI UX all in the user questions. We provide a mapping guide between prototypical user questions and exemplars of XAI techniques, serving as boundary objects to support collaboration between designers and AI engineers. We demonstrate it with a use case of designing XAI for healthcare adverse events prediction, and discuss lessons learned for tackling design challenges of AI systems.
Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models
Jan 29, 2021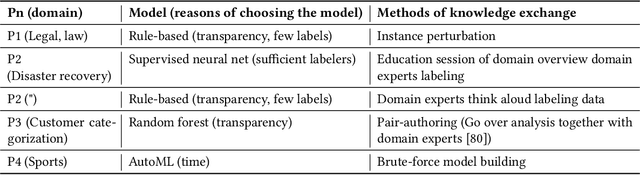

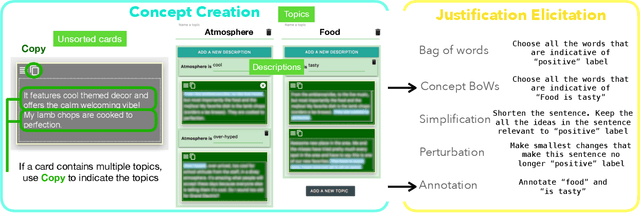
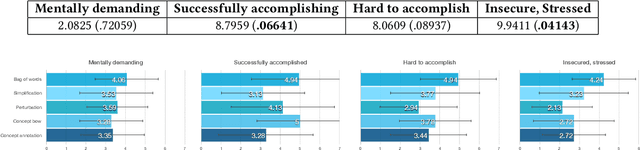
Data scientists face a steep learning curve in understanding a new domain for which they want to build machine learning (ML) models. While input from domain experts could offer valuable help, such input is often limited, expensive, and generally not in a form readily consumable by a model development pipeline. In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models. With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample. The design of Ziva is informed by preliminary interviews with data scientists, in order to understand current practices of domain knowledge acquisition process for ML development projects. To assess our design, we run a mix-method case-study to evaluate how Ziva can facilitate interaction of domain experts and data scientists. Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva's output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output by our case study.