 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Adversarial Risk and Training
Jun 11, 2018
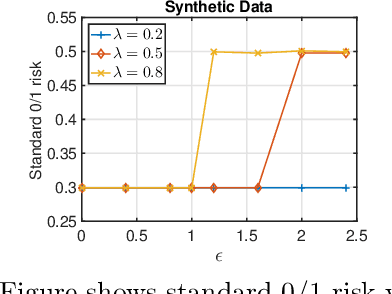
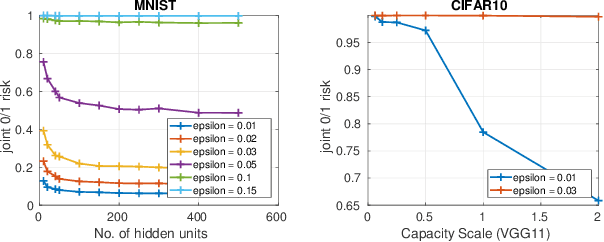
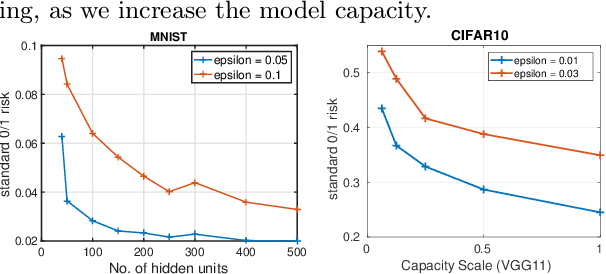
In this work we formally define the notions of adversarial perturbations, adversarial risk and adversarial training and analyze their properties. Our analysis provides several interesting insights into adversarial risk, adversarial training, and their relation to the classification risk, "traditional" training. We also show that adversarial training can result in models with better classification accuracy and can result in better explainable models than traditional training. Although adversarial training is computationally expensive, our results and insights suggest that one should prefer adversarial training over traditional risk minimization for learning complex models from data.
Binary Classification with Karmic, Threshold-Quasi-Concave Metrics
Jun 02, 2018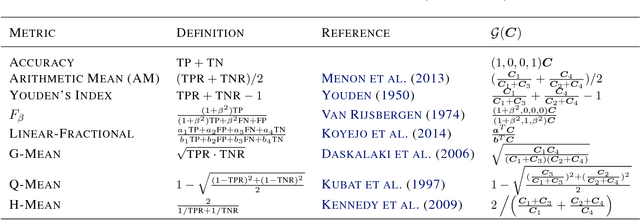
Complex performance measures, beyond the popular measure of accuracy, are increasingly being used in the context of binary classification. These complex performance measures are typically not even decomposable, that is, the loss evaluated on a batch of samples cannot typically be expressed as a sum or average of losses evaluated at individual samples, which in turn requires new theoretical and methodological developments beyond standard treatments of supervised learning. In this paper, we advance this understanding of binary classification for complex performance measures by identifying two key properties: a so-called Karmic property, and a more technical threshold-quasi-concavity property, which we show is milder than existing structural assumptions imposed on performance measures. Under these properties, we show that the Bayes optimal classifier is a threshold function of the conditional probability of positive class. We then leverage this result to come up with a computationally practical plug-in classifier, via a novel threshold estimator, and further, provide a novel statistical analysis of classification error with respect to complex performance measures.
Robust Nonparametric Regression under Huber's $ε$-contamination Model
May 26, 2018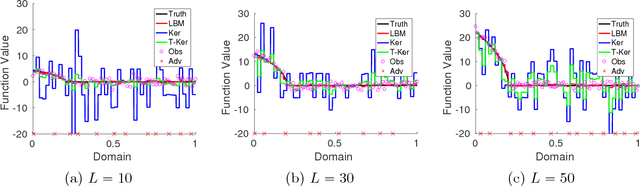
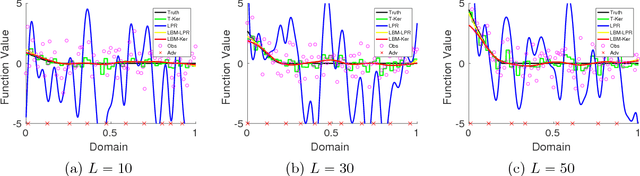
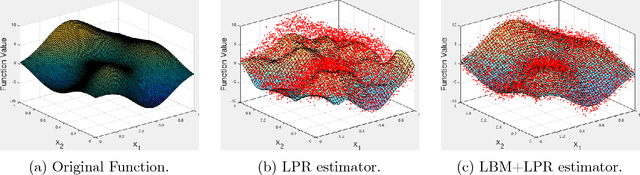

We consider the non-parametric regression problem under Huber's $\epsilon$-contamination model, in which an $\epsilon$ fraction of observations are subject to arbitrary adversarial noise. We first show that a simple local binning median step can effectively remove the adversary noise and this median estimator is minimax optimal up to absolute constants over the H\"{o}lder function class with smoothness parameters smaller than or equal to 1. Furthermore, when the underlying function has higher smoothness, we show that using local binning median as pre-preprocessing step to remove the adversarial noise, then we can apply any non-parametric estimator on top of the medians. In particular we show local median binning followed by kernel smoothing and local polynomial regression achieve minimaxity over H\"{o}lder and Sobolev classes with arbitrary smoothness parameters. Our main proof technique is a decoupled analysis of adversary noise and stochastic noise, which can be potentially applied to other robust estimation problems. We also provide numerical results to verify the effectiveness of our proposed methods.
D2KE: From Distance to Kernel and Embedding
May 25, 2018



For many machine learning problem settings, particularly with structured inputs such as sequences or sets of objects, a distance measure between inputs can be specified more naturally than a feature representation. However, most standard machine models are designed for inputs with a vector feature representation. In this work, we consider the estimation of a function $f:\mathcal{X} \rightarrow \R$ based solely on a dissimilarity measure $d:\mathcal{X}\times\mathcal{X} \rightarrow \R$ between inputs. In particular, we propose a general framework to derive a family of \emph{positive definite kernels} from a given dissimilarity measure, which subsumes the widely-used \emph{representative-set method} as a special case, and relates to the well-known \emph{distance substitution kernel} in a limiting case. We show that functions in the corresponding Reproducing Kernel Hilbert Space (RKHS) are Lipschitz-continuous w.r.t. the given distance metric. We provide a tractable algorithm to estimate a function from this RKHS, and show that it enjoys better generalizability than Nearest-Neighbor estimates. Our approach draws from the literature of Random Features, but instead of deriving feature maps from an existing kernel, we construct novel kernels from a random feature map, that we specify given the distance measure. We conduct classification experiments with such disparate domains as strings, time series, and sets of vectors, where our proposed framework compares favorably to existing distance-based learning methods such as $k$-nearest-neighbors, distance-substitution kernels, pseudo-Euclidean embedding, and the representative-set method.
Identifiability of Nonparametric Mixture Models and Bayes Optimal Clustering
Apr 22, 2018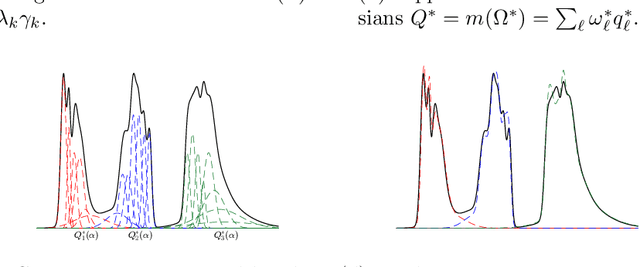
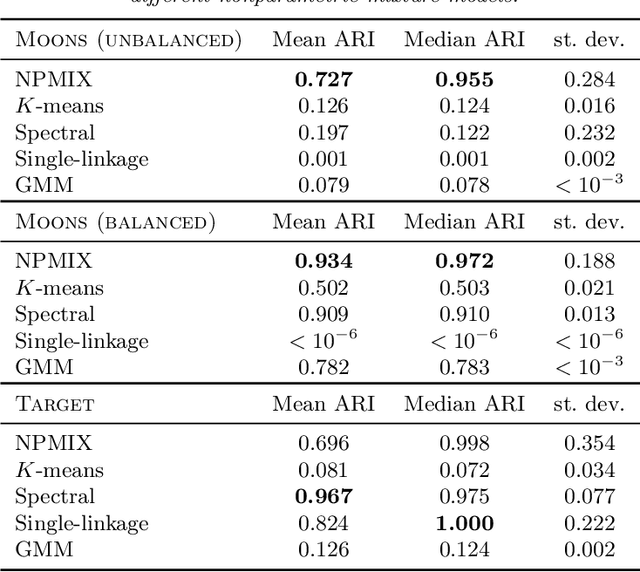
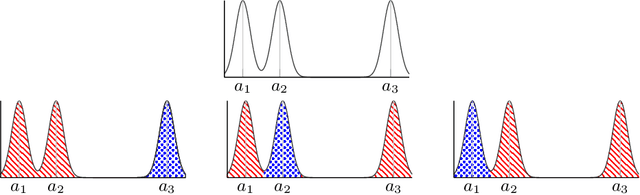
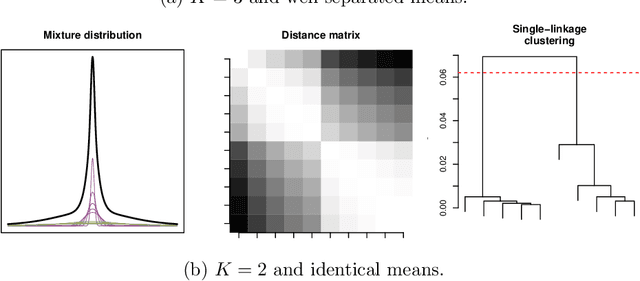
Motivated by problems in data clustering, we establish general conditions under which families of nonparametric mixture models are identifiable by introducing a novel framework for clustering overfitted \emph{parametric} (i.e. misspecified) mixture models. These conditions generalize existing conditions in the literature, and are flexible enough to include for example mixtures of Gaussian mixtures. In contrast to the recent literature on estimating nonparametric mixtures, we allow for general nonparametric mixture components, and instead impose regularity assumptions on the underlying mixing measure. As our primary application, we apply these results to partition-based clustering, generalizing the well-known notion of a Bayes optimal partition from classical model-based clustering to nonparametric settings. Furthermore, this framework is constructive in that it yields a practical algorithm for learning identified mixtures, which is illustrated through several examples. The key conceptual device in the analysis is the convex, metric geometry of probability distributions on metric spaces and its connection to optimal transport and the Wasserstein convergence of mixing measures. The result is a flexible framework for nonparametric clustering with formal consistency guarantees.
Robust Estimation via Robust Gradient Estimation
Apr 20, 2018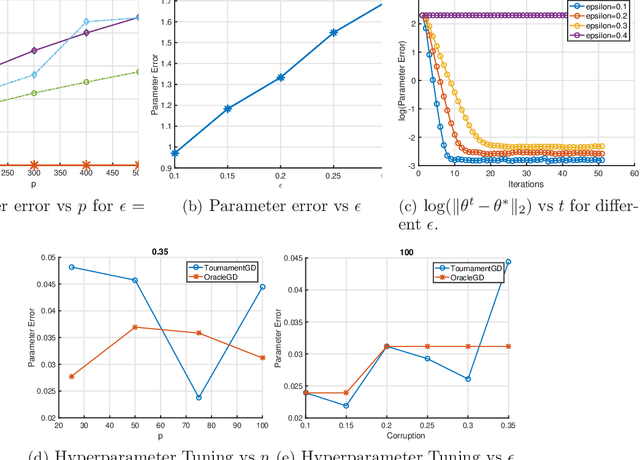

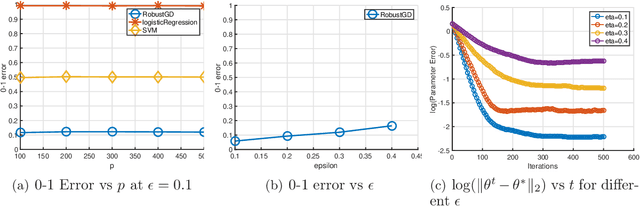
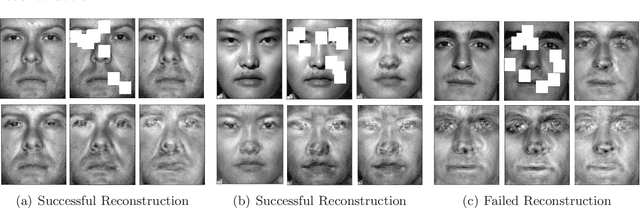
We provide a new computationally-efficient class of estimators for risk minimization. We show that these estimators are robust for general statistical models: in the classical Huber epsilon-contamination model and in heavy-tailed settings. Our workhorse is a novel robust variant of gradient descent, and we provide conditions under which our gradient descent variant provides accurate estimators in a general convex risk minimization problem. We provide specific consequences of our theory for linear regression, logistic regression and for estimation of the canonical parameters in an exponential family. These results provide some of the first computationally tractable and provably robust estimators for these canonical statistical models. Finally, we study the empirical performance of our proposed methods on synthetic and real datasets, and find that our methods convincingly outperform a variety of baselines.
Online Classification with Complex Metrics
Feb 10, 2018We present a framework and analysis of consistent binary classification for complex and non-decomposable performance metrics such as the F-measure and the Jaccard measure. The proposed framework is general, as it applies to both batch and online learning, and to both linear and non-linear models. Our work follows recent results showing that the Bayes optimal classifier for many complex metrics is given by a thresholding of the conditional probability of the positive class. This manuscript extends this thresholding characterization -- showing that the utility is strictly locally quasi-concave with respect to the threshold for a wide range of models and performance metrics. This, in turn, motivates simple normalized gradient ascent updates for threshold estimation. We present a finite-sample regret analysis for the resulting procedure. In particular, the risk for the batch case converges to the Bayes risk at the same rate as that of the underlying conditional probability estimation, and the risk of proposed online algorithm converges at a rate that depends on the conditional probability estimation risk. For instance, in the special case where the conditional probability model is logistic regression, our procedure achieves $O(\frac{1}{\sqrt{n}})$ sample complexity, both for batch and online training. Empirical evaluation shows that the proposed algorithms out-perform alternatives in practice, with comparable or better prediction performance and reduced run time for various metrics and datasets.
A Voting-Based System for Ethical Decision Making
Sep 20, 2017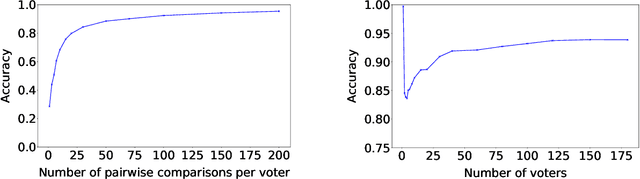
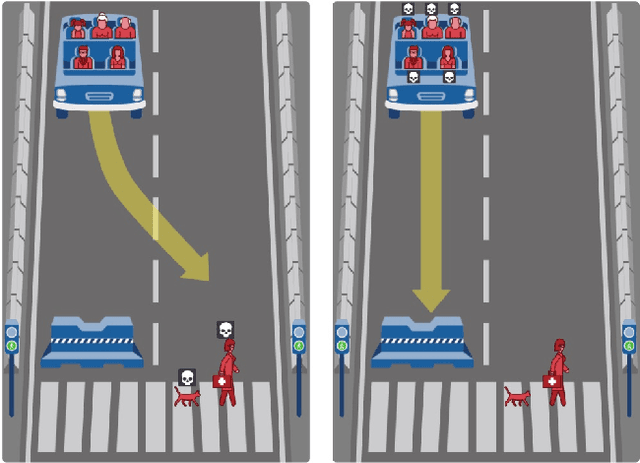
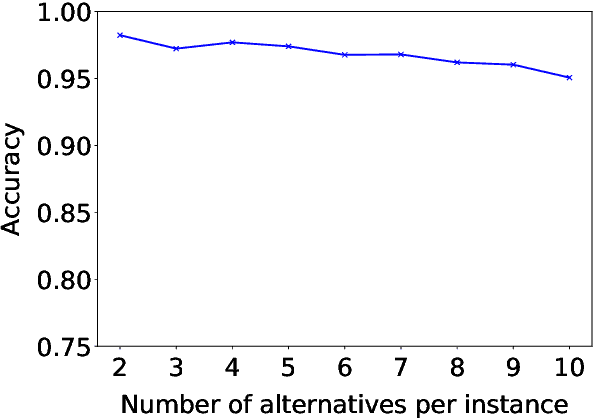
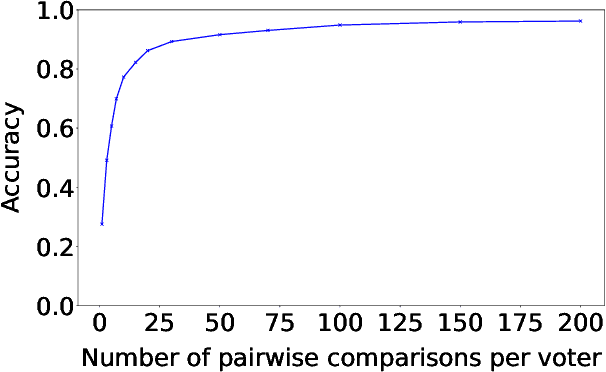
We present a general approach to automating ethical decisions, drawing on machine learning and computational social choice. In a nutshell, we propose to learn a model of societal preferences, and, when faced with a specific ethical dilemma at runtime, efficiently aggregate those preferences to identify a desirable choice. We provide a concrete algorithm that instantiates our approach; some of its crucial steps are informed by a new theory of swap-dominance efficient voting rules. Finally, we implement and evaluate a system for ethical decision making in the autonomous vehicle domain, using preference data collected from 1.3 million people through the Moral Machine website.
A Review of Multivariate Distributions for Count Data Derived from the Poisson Distribution
Dec 27, 2016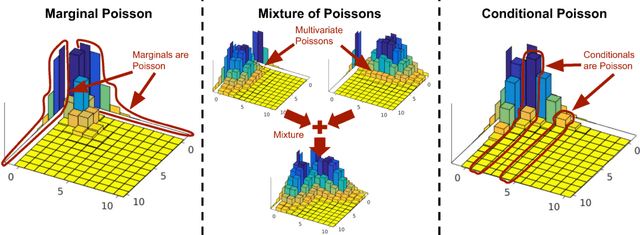
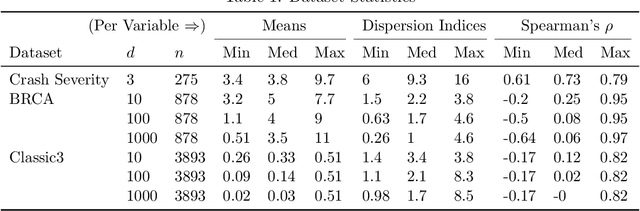
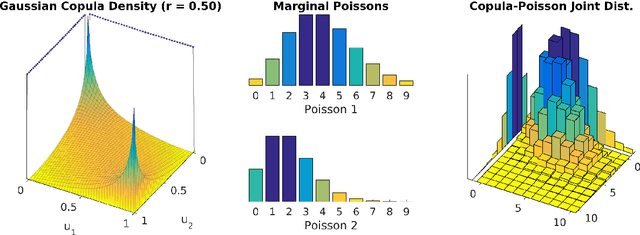
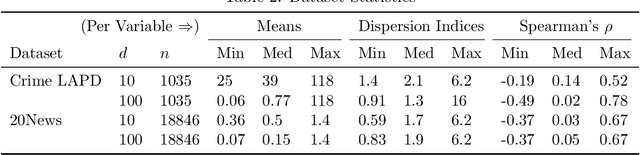
The Poisson distribution has been widely studied and used for modeling univariate count-valued data. Multivariate generalizations of the Poisson distribution that permit dependencies, however, have been far less popular. Yet, real-world high-dimensional count-valued data found in word counts, genomics, and crime statistics, for example, exhibit rich dependencies, and motivate the need for multivariate distributions that can appropriately model this data. We review multivariate distributions derived from the univariate Poisson, categorizing these models into three main classes: 1) where the marginal distributions are Poisson, 2) where the joint distribution is a mixture of independent multivariate Poisson distributions, and 3) where the node-conditional distributions are derived from the Poisson. We discuss the development of multiple instances of these classes and compare the models in terms of interpretability and theory. Then, we empirically compare multiple models from each class on three real-world datasets that have varying data characteristics from different domains, namely traffic accident data, biological next generation sequencing data, and text data. These empirical experiments develop intuition about the comparative advantages and disadvantages of each class of multivariate distribution that was derived from the Poisson. Finally, we suggest new research directions as explored in the subsequent discussion section.
Kernel Ridge Regression via Partitioning
Aug 05, 2016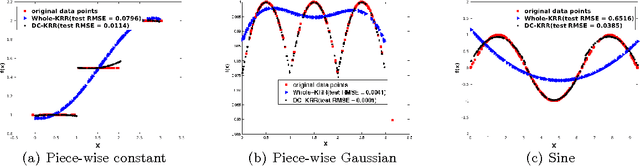
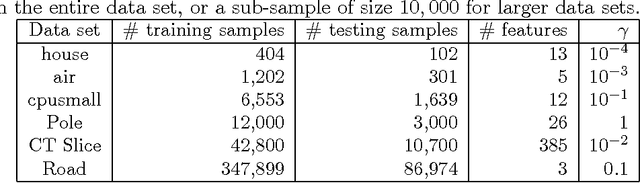
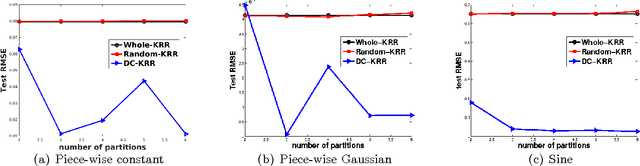

In this paper, we investigate a divide and conquer approach to Kernel Ridge Regression (KRR). Given n samples, the division step involves separating the points based on some underlying disjoint partition of the input space (possibly via clustering), and then computing a KRR estimate for each partition. The conquering step is simple: for each partition, we only consider its own local estimate for prediction. We establish conditions under which we can give generalization bounds for this estimator, as well as achieve optimal minimax rates. We also show that the approximation error component of the generalization error is lesser than when a single KRR estimate is fit on the data: thus providing both statistical and computational advantages over a single KRR estimate over the entire data (or an averaging over random partitions as in other recent work, [30]). Lastly, we provide experimental validation for our proposed estimator and our assumptions.