 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Act: Unified Policy for Interleaving Language Reasoning with Actions
Apr 18, 2023



The success of transformer models trained with a language modeling objective brings a promising opportunity to the reinforcement learning framework. Decision Transformer is a step towards this direction, showing how to train transformers with a similar next-step prediction objective on offline data. Another important development in this area is the recent emergence of large-scale datasets collected from the internet, such as the ones composed of tutorial videos with captions where people talk about what they are doing. To take advantage of this language component, we propose a novel method for unifying language reasoning with actions in a single policy. Specifically, we augment a transformer policy with word outputs, so it can generate textual captions interleaved with actions. When tested on the most challenging task in BabyAI, with captions describing next subgoals, our reasoning policy consistently outperforms the caption-free baseline.
Sub-meter resolution canopy height maps using self-supervised learning and a vision transformer trained on Aerial and GEDI Lidar
Apr 17, 2023



Vegetation structure mapping is critical for understanding the global carbon cycle and monitoring nature-based approaches to climate adaptation and mitigation. Repeat measurements of these data allow for the observation of deforestation or degradation of existing forests, natural forest regeneration, and the implementation of sustainable agricultural practices like agroforestry. Assessments of tree canopy height and crown projected area at a high spatial resolution are also important for monitoring carbon fluxes and assessing tree-based land uses, since forest structures can be highly spatially heterogeneous, especially in agroforestry systems. Very high resolution satellite imagery (less than one meter (1m) ground sample distance) makes it possible to extract information at the tree level while allowing monitoring at a very large scale. This paper presents the first high-resolution canopy height map concurrently produced for multiple sub-national jurisdictions. Specifically, we produce canopy height maps for the states of California and S\~{a}o Paolo, at sub-meter resolution, a significant improvement over the ten meter (10m) resolution of previous Sentinel / GEDI based worldwide maps of canopy height. The maps are generated by applying a vision transformer to features extracted from a self-supervised model in Maxar imagery from 2017 to 2020, and are trained against aerial lidar and GEDI observations. We evaluate the proposed maps with set-aside validation lidar data as well as by comparing with other remotely sensed maps and field-collected data, and find our model produces an average Mean Absolute Error (MAE) within set-aside validation areas of 3.0 meters.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023



The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Jan 19, 2023



This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) predict several target blocks in the image, (b) sample target blocks with sufficiently large scale (occupying 15%-20% of the image), and (c) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transformers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/16 on ImageNet using 32 A100 GPUs in under 38 hours to achieve strong downstream performance across a wide range of tasks requiring various levels of abstraction, from linear classification to object counting and depth prediction.
Learning Goal-Conditioned Policies Offline with Self-Supervised Reward Shaping
Jan 05, 2023



Developing agents that can execute multiple skills by learning from pre-collected datasets is an important problem in robotics, where online interaction with the environment is extremely time-consuming. Moreover, manually designing reward functions for every single desired skill is prohibitive. Prior works targeted these challenges by learning goal-conditioned policies from offline datasets without manually specified rewards, through hindsight relabelling. These methods suffer from the issue of sparsity of rewards, and fail at long-horizon tasks. In this work, we propose a novel self-supervised learning phase on the pre-collected dataset to understand the structure and the dynamics of the model, and shape a dense reward function for learning policies offline. We evaluate our method on three continuous control tasks, and show that our model significantly outperforms existing approaches, especially on tasks that involve long-term planning.
* Code: https://github.com/facebookresearch/go-fresh
Co-training $2^L$ Submodels for Visual Recognition
Dec 09, 2022We introduce submodel co-training, a regularization method related to co-training, self-distillation and stochastic depth. Given a neural network to be trained, for each sample we implicitly instantiate two altered networks, ``submodels'', with stochastic depth: we activate only a subset of the layers. Each network serves as a soft teacher to the other, by providing a loss that complements the regular loss provided by the one-hot label. Our approach, dubbed cosub, uses a single set of weights, and does not involve a pre-trained external model or temporal averaging. Experimentally, we show that submodel co-training is effective to train backbones for recognition tasks such as image classification and semantic segmentation. Our approach is compatible with multiple architectures, including RegNet, ViT, PiT, XCiT, Swin and ConvNext. Our training strategy improves their results in comparable settings. For instance, a ViT-B pretrained with cosub on ImageNet-21k obtains 87.4% top-1 acc. @448 on ImageNet-val.
The Hidden Uniform Cluster Prior in Self-Supervised Learning
Oct 13, 2022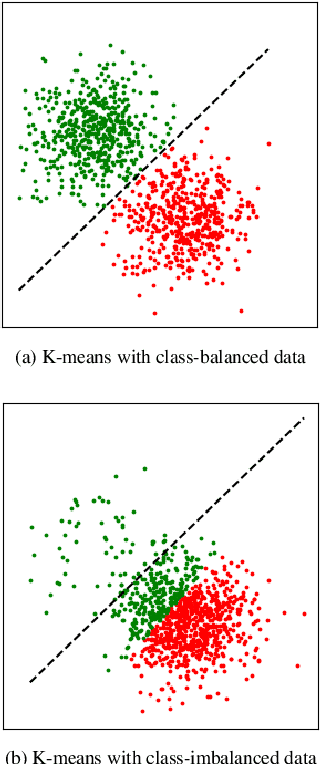
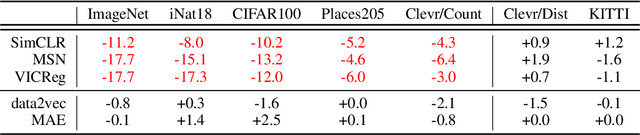


A successful paradigm in representation learning is to perform self-supervised pretraining using tasks based on mini-batch statistics (e.g., SimCLR, VICReg, SwAV, MSN). We show that in the formulation of all these methods is an overlooked prior to learn features that enable uniform clustering of the data. While this prior has led to remarkably semantic representations when pretraining on class-balanced data, such as ImageNet, we demonstrate that it can hamper performance when pretraining on class-imbalanced data. By moving away from conventional uniformity priors and instead preferring power-law distributed feature clusters, we show that one can improve the quality of the learned representations on real-world class-imbalanced datasets. To demonstrate this, we develop an extension of the Masked Siamese Networks (MSN) method to support the use of arbitrary features priors.
Walk the Random Walk: Learning to Discover and Reach Goals Without Supervision
Jun 23, 2022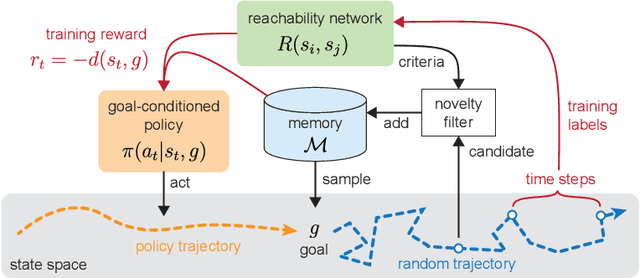
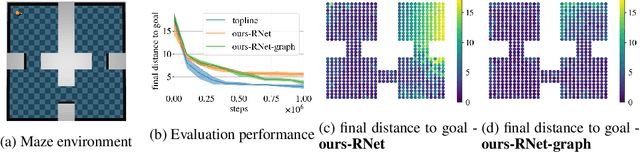
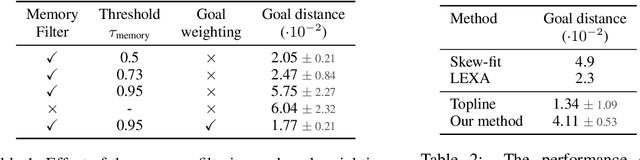
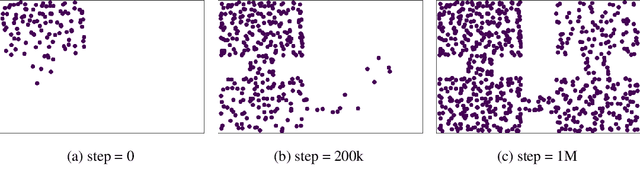
Learning a diverse set of skills by interacting with an environment without any external supervision is an important challenge. In particular, obtaining a goal-conditioned agent that can reach any given state is useful in many applications. We propose a novel method for training such a goal-conditioned agent without any external rewards or any domain knowledge. We use random walk to train a reachability network that predicts the similarity between two states. This reachability network is then used in building goal memory containing past observations that are diverse and well-balanced. Finally, we train a goal-conditioned policy network with goals sampled from the goal memory and reward it by the reachability network and the goal memory. All the components are kept updated throughout training as the agent discovers and learns new goals. We apply our method to a continuous control navigation and robotic manipulation tasks.
Masked Siamese Networks for Label-Efficient Learning
Apr 14, 2022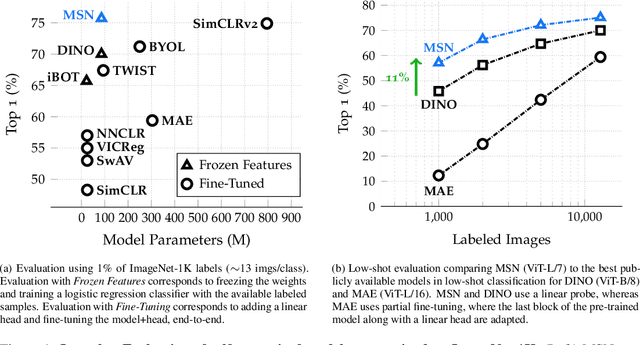
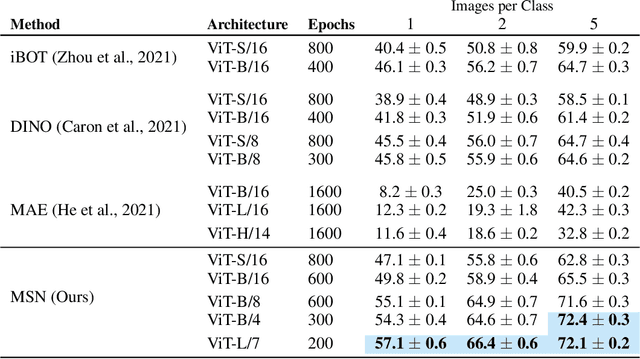

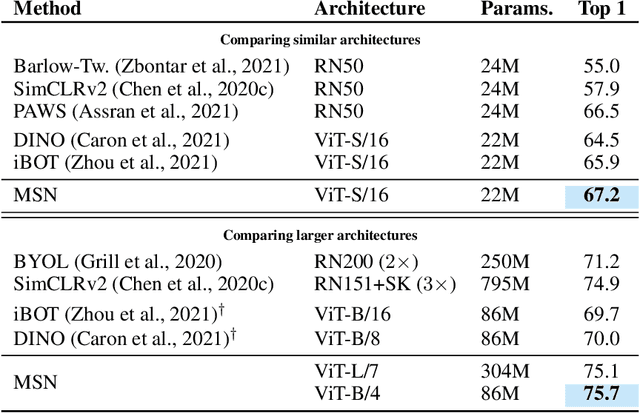
We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our approach matches the representation of an image view containing randomly masked patches to the representation of the original unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures, while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance, on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy, and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark. Our code is publicly available.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022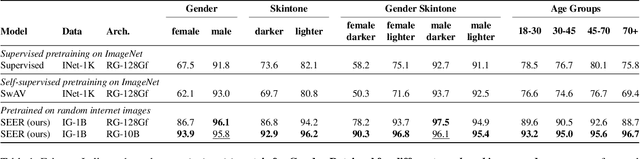
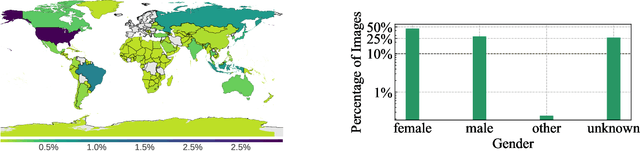
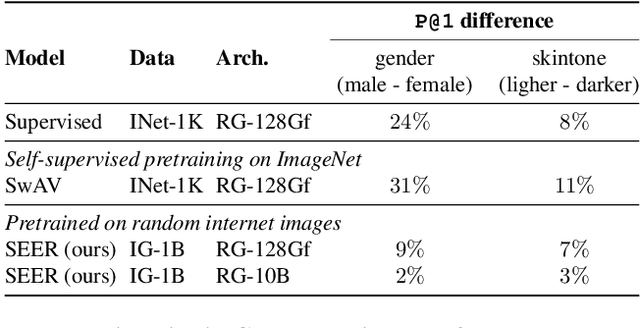
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.