 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Graph Based Neural Architecture Search
Dec 15, 2021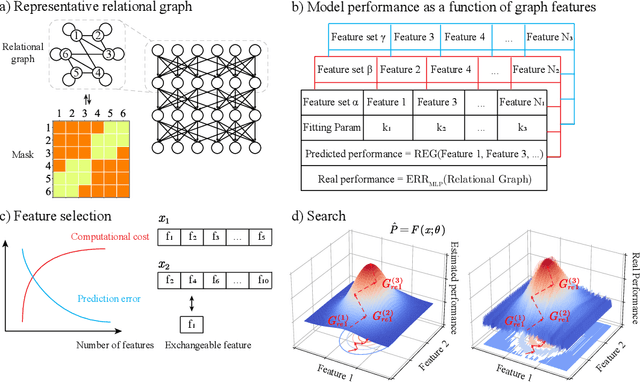

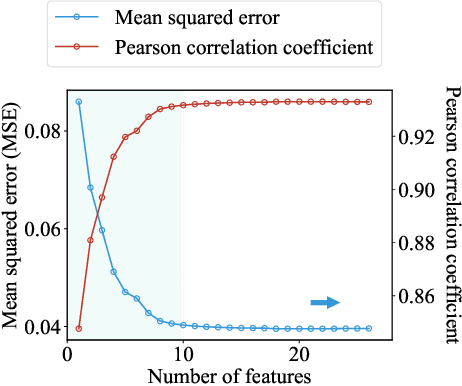
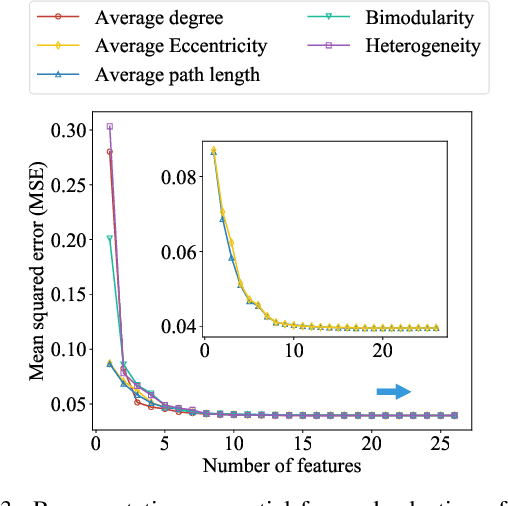
Neural architecture search enables automation of architecture design. Despite its success, it is computationally costly and does not provide an insight on how to design a desirable architecture. Here we propose a new way of searching neural network where we search neural architecture by rewiring the corresponding graph and predict the architecture performance by graph properties. Because we do not perform machine learning over the entire graph space and use predicted architecture performance to search architecture, the searching process is remarkably efficient. We find graph based search can give a reasonably good prediction of desirable architecture. In addition, we find graph properties that are effective to predict architecture performance. Our work proposes a new way of searching neural architecture and provides insights on neural architecture design.
Revisiting Contrastive Learning through the Lens of Neighborhood Component Analysis: an Integrated Framework
Dec 08, 2021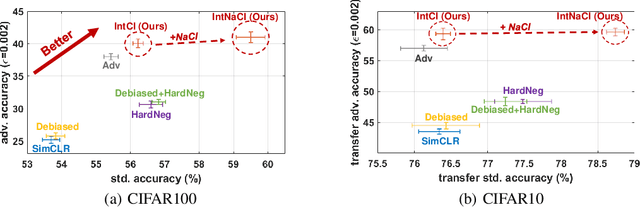
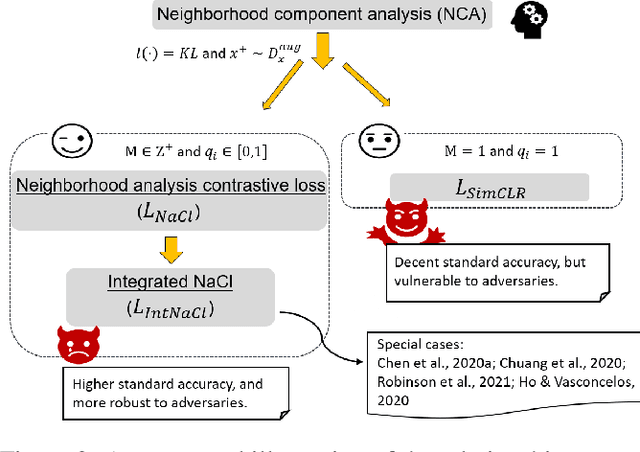
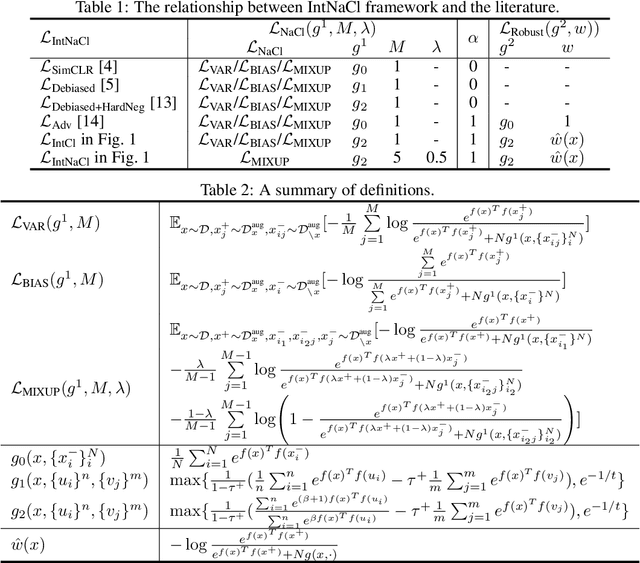
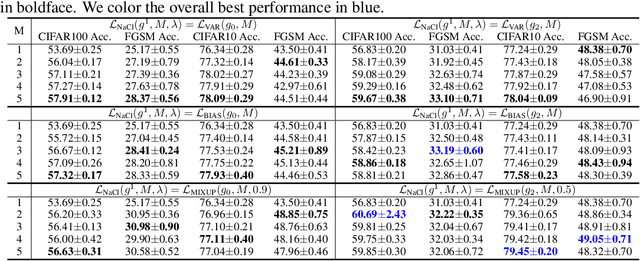
As a seminal tool in self-supervised representation learning, contrastive learning has gained unprecedented attention in recent years. In essence, contrastive learning aims to leverage pairs of positive and negative samples for representation learning, which relates to exploiting neighborhood information in a feature space. By investigating the connection between contrastive learning and neighborhood component analysis (NCA), we provide a novel stochastic nearest neighbor viewpoint of contrastive learning and subsequently propose a series of contrastive losses that outperform the existing ones. Under our proposed framework, we show a new methodology to design integrated contrastive losses that could simultaneously achieve good accuracy and robustness on downstream tasks. With the integrated framework, we achieve up to 6\% improvement on the standard accuracy and 17\% improvement on the adversarial accuracy.
Certified Adversarial Defenses Meet Out-of-Distribution Corruptions: Benchmarking Robustness and Simple Baselines
Dec 01, 2021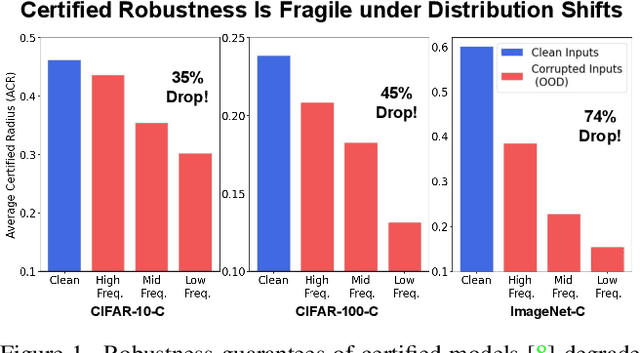
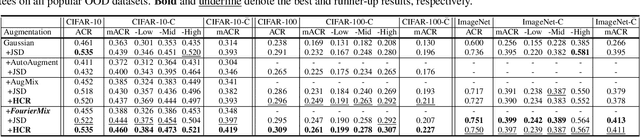
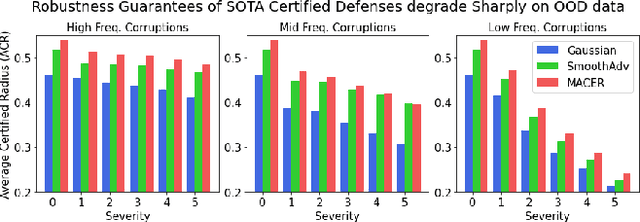
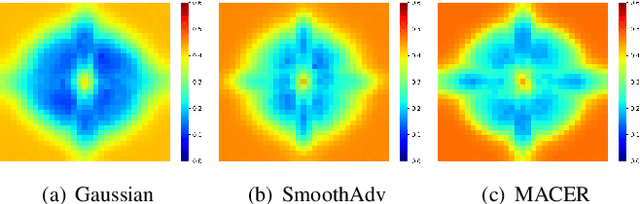
Certified robustness guarantee gauges a model's robustness to test-time attacks and can assess the model's readiness for deployment in the real world. In this work, we critically examine how the adversarial robustness guarantees from randomized smoothing-based certification methods change when state-of-the-art certifiably robust models encounter out-of-distribution (OOD) data. Our analysis demonstrates a previously unknown vulnerability of these models to low-frequency OOD data such as weather-related corruptions, rendering these models unfit for deployment in the wild. To alleviate this issue, we propose a novel data augmentation scheme, FourierMix, that produces augmentations to improve the spectral coverage of the training data. Furthermore, we propose a new regularizer that encourages consistent predictions on noise perturbations of the augmented data to improve the quality of the smoothed models. We find that FourierMix augmentations help eliminate the spectral bias of certifiably robust models enabling them to achieve significantly better robustness guarantees on a range of OOD benchmarks. Our evaluation also uncovers the inability of current OOD benchmarks at highlighting the spectral biases of the models. To this end, we propose a comprehensive benchmarking suite that contains corruptions from different regions in the spectral domain. Evaluation of models trained with popular augmentation methods on the proposed suite highlights their spectral biases and establishes the superiority of FourierMix trained models at achieving better-certified robustness guarantees under OOD shifts over the entire frequency spectrum.
Pessimistic Model Selection for Offline Deep Reinforcement Learning
Nov 29, 2021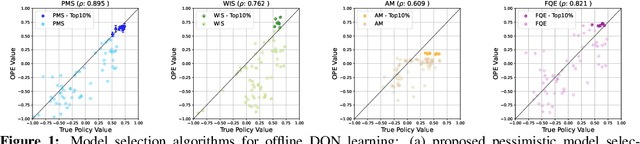
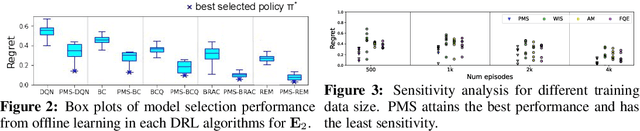

Deep Reinforcement Learning (DRL) has demonstrated great potentials in solving sequential decision making problems in many applications. Despite its promising performance, practical gaps exist when deploying DRL in real-world scenarios. One main barrier is the over-fitting issue that leads to poor generalizability of the policy learned by DRL. In particular, for offline DRL with observational data, model selection is a challenging task as there is no ground truth available for performance demonstration, in contrast with the online setting with simulated environments. In this work, we propose a pessimistic model selection (PMS) approach for offline DRL with a theoretical guarantee, which features a provably effective framework for finding the best policy among a set of candidate models. Two refined approaches are also proposed to address the potential bias of DRL model in identifying the optimal policy. Numerical studies demonstrated the superior performance of our approach over existing methods.
Make an Omelette with Breaking Eggs: Zero-Shot Learning for Novel Attribute Synthesis
Nov 28, 2021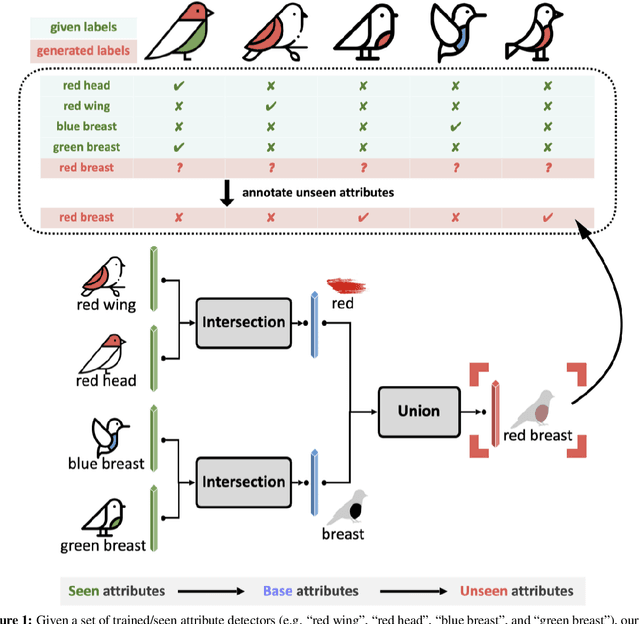
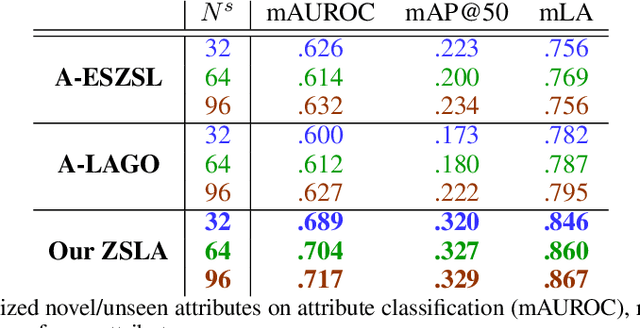
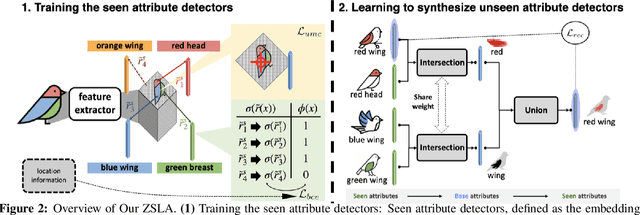
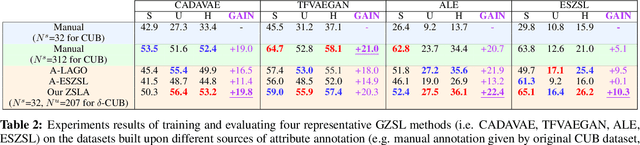
Most of the existing algorithms for zero-shot classification problems typically rely on the attribute-based semantic relations among categories to realize the classification of novel categories without observing any of their instances. However, training the zero-shot classification models still requires attribute labeling for each class (or even instance) in the training dataset, which is also expensive. To this end, in this paper, we bring up a new problem scenario: "Are we able to derive zero-shot learning for novel attribute detectors/classifiers and use them to automatically annotate the dataset for labeling efficiency?" Basically, given only a small set of detectors that are learned to recognize some manually annotated attributes (i.e., the seen attributes), we aim to synthesize the detectors of novel attributes in a zero-shot learning manner. Our proposed method, Zero Shot Learning for Attributes (ZSLA), which is the first of its kind to the best of our knowledge, tackles this new research problem by applying the set operations to first decompose the seen attributes into their basic attributes and then recombine these basic attributes into the novel ones. Extensive experiments are conducted to verify the capacity of our synthesized detectors for accurately capturing the semantics of the novel attributes and show their superior performance in terms of detection and localization compared to other baseline approaches. Moreover, with using only 32 seen attributes on the Caltech-UCSD Birds-200-2011 dataset, our proposed method is able to synthesize other 207 novel attributes, while various generalized zero-shot classification algorithms trained upon the dataset re-annotated by our synthesized attribute detectors are able to provide comparable performance with those trained with the manual ground-truth annotations.
Meta Adversarial Perturbations
Nov 19, 2021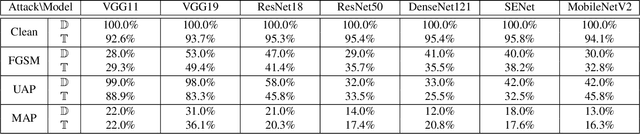
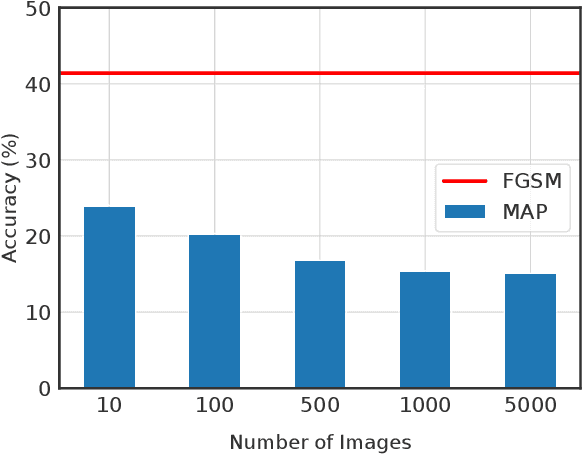
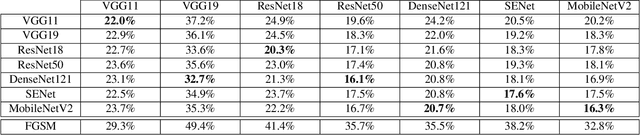
A plethora of attack methods have been proposed to generate adversarial examples, among which the iterative methods have been demonstrated the ability to find a strong attack. However, the computation of an adversarial perturbation for a new data point requires solving a time-consuming optimization problem from scratch. To generate a stronger attack, it normally requires updating a data point with more iterations. In this paper, we show the existence of a meta adversarial perturbation (MAP), a better initialization that causes natural images to be misclassified with high probability after being updated through only a one-step gradient ascent update, and propose an algorithm for computing such perturbations. We conduct extensive experiments, and the empirical results demonstrate that state-of-the-art deep neural networks are vulnerable to meta perturbations. We further show that these perturbations are not only image-agnostic, but also model-agnostic, as a single perturbation generalizes well across unseen data points and different neural network architectures.
Mean-based Best Arm Identification in Stochastic Bandits under Reward Contamination
Nov 14, 2021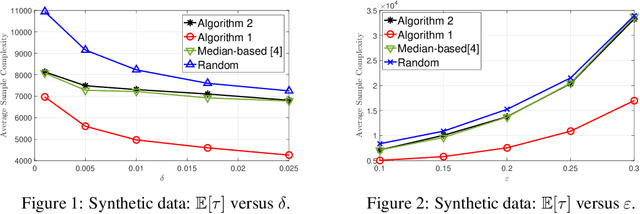
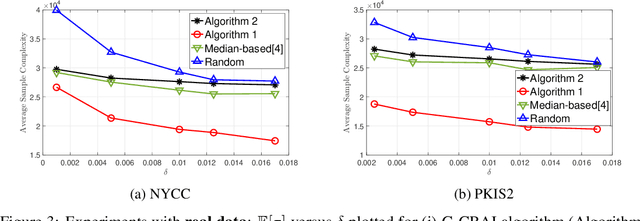
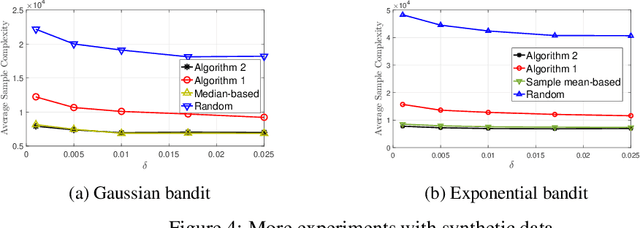
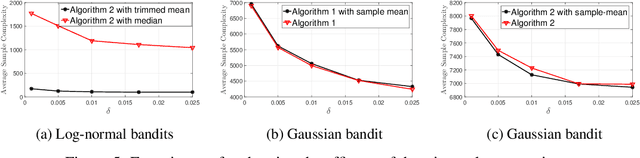
This paper investigates the problem of best arm identification in $\textit{contaminated}$ stochastic multi-arm bandits. In this setting, the rewards obtained from any arm are replaced by samples from an adversarial model with probability $\varepsilon$. A fixed confidence (infinite-horizon) setting is considered, where the goal of the learner is to identify the arm with the largest mean. Owing to the adversarial contamination of the rewards, each arm's mean is only partially identifiable. This paper proposes two algorithms, a gap-based algorithm and one based on the successive elimination, for best arm identification in sub-Gaussian bandits. These algorithms involve mean estimates that achieve the optimal error guarantee on the deviation of the true mean from the estimate asymptotically. Furthermore, these algorithms asymptotically achieve the optimal sample complexity. Specifically, for the gap-based algorithm, the sample complexity is asymptotically optimal up to constant factors, while for the successive elimination-based algorithm, it is optimal up to logarithmic factors. Finally, numerical experiments are provided to illustrate the gains of the algorithms compared to the existing baselines.
CAFE: Catastrophic Data Leakage in Vertical Federated Learning
Nov 02, 2021
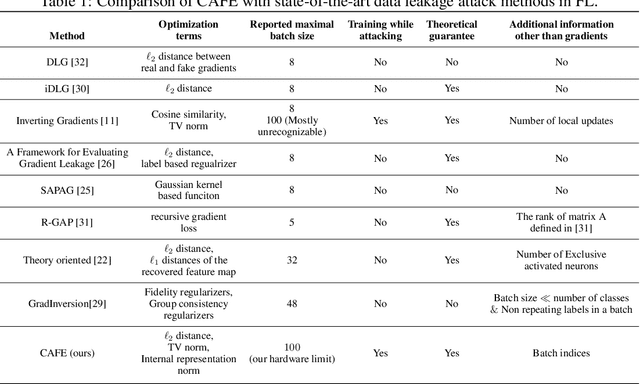
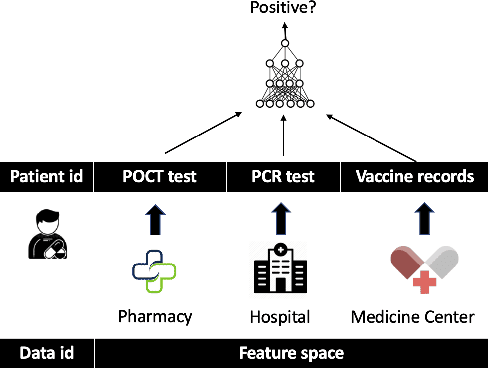
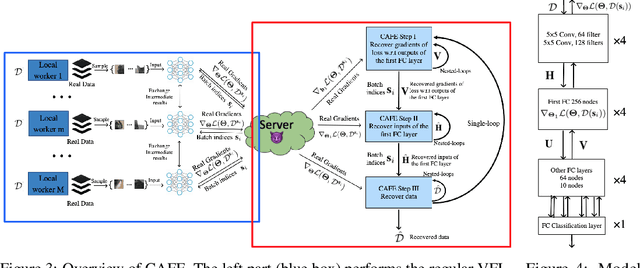
Recent studies show that private training data can be leaked through the gradients sharing mechanism deployed in distributed machine learning systems, such as federated learning (FL). Increasing batch size to complicate data recovery is often viewed as a promising defense strategy against data leakage. In this paper, we revisit this defense premise and propose an advanced data leakage attack with theoretical justification to efficiently recover batch data from the shared aggregated gradients. We name our proposed method as catastrophic data leakage in vertical federated learning (CAFE). Comparing to existing data leakage attacks, our extensive experimental results on vertical FL settings demonstrate the effectiveness of CAFE to perform large-batch data leakage attack with improved data recovery quality. We also propose a practical countermeasure to mitigate CAFE. Our results suggest that private data participated in standard FL, especially the vertical case, have a high risk of being leaked from the training gradients. Our analysis implies unprecedented and practical data leakage risks in those learning settings. The code of our work is available at https://github.com/DeRafael/CAFE.
When Does Contrastive Learning Preserve Adversarial Robustness from Pretraining to Finetuning?
Nov 01, 2021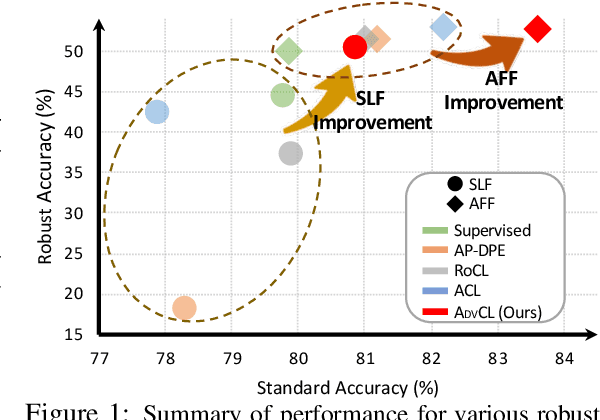
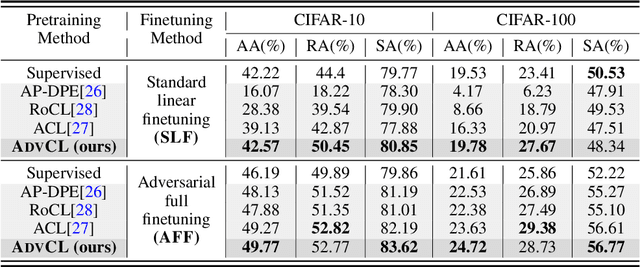
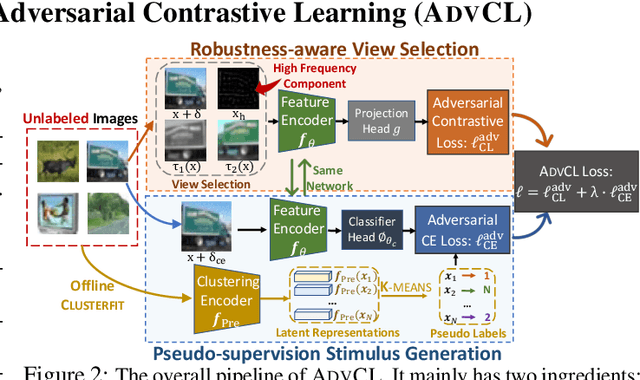
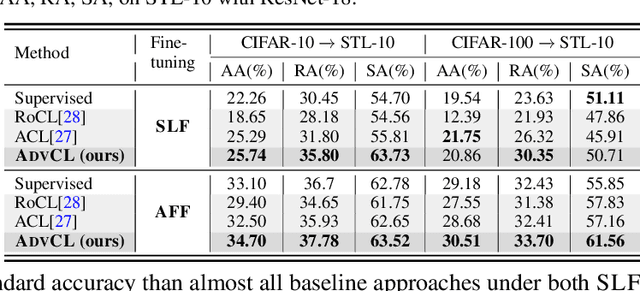
Contrastive learning (CL) can learn generalizable feature representations and achieve the state-of-the-art performance of downstream tasks by finetuning a linear classifier on top of it. However, as adversarial robustness becomes vital in image classification, it remains unclear whether or not CL is able to preserve robustness to downstream tasks. The main challenge is that in the self-supervised pretraining + supervised finetuning paradigm, adversarial robustness is easily forgotten due to a learning task mismatch from pretraining to finetuning. We call such a challenge 'cross-task robustness transferability'. To address the above problem, in this paper we revisit and advance CL principles through the lens of robustness enhancement. We show that (1) the design of contrastive views matters: High-frequency components of images are beneficial to improving model robustness; (2) Augmenting CL with pseudo-supervision stimulus (e.g., resorting to feature clustering) helps preserve robustness without forgetting. Equipped with our new designs, we propose AdvCL, a novel adversarial contrastive pretraining framework. We show that AdvCL is able to enhance cross-task robustness transferability without loss of model accuracy and finetuning efficiency. With a thorough experimental study, we demonstrate that AdvCL outperforms the state-of-the-art self-supervised robust learning methods across multiple datasets (CIFAR-10, CIFAR-100, and STL-10) and finetuning schemes (linear evaluation and full model finetuning).
How and When Adversarial Robustness Transfers in Knowledge Distillation?
Oct 22, 2021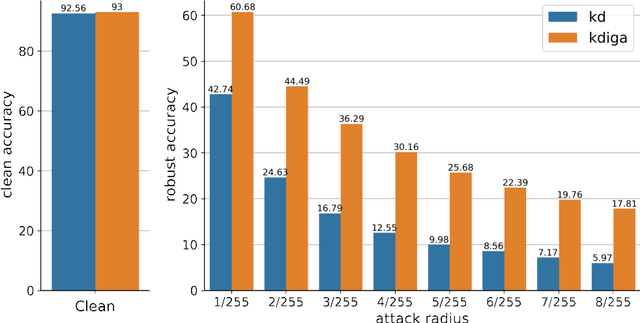
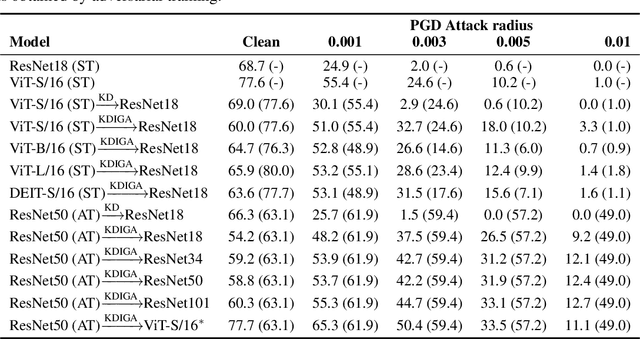
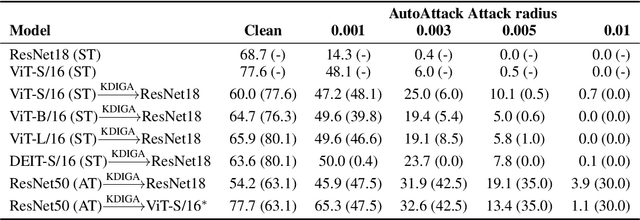
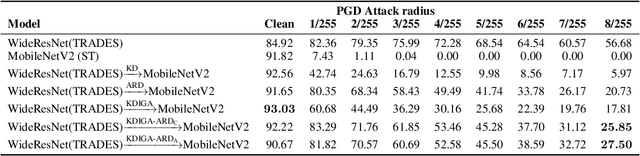
Knowledge distillation (KD) has been widely used in teacher-student training, with applications to model compression in resource-constrained deep learning. Current works mainly focus on preserving the accuracy of the teacher model. However, other important model properties, such as adversarial robustness, can be lost during distillation. This paper studies how and when the adversarial robustness can be transferred from a teacher model to a student model in KD. We show that standard KD training fails to preserve adversarial robustness, and we propose KD with input gradient alignment (KDIGA) for remedy. Under certain assumptions, we prove that the student model using our proposed KDIGA can achieve at least the same certified robustness as the teacher model. Our experiments of KD contain a diverse set of teacher and student models with varying network architectures and sizes evaluated on ImageNet and CIFAR-10 datasets, including residual neural networks (ResNets) and vision transformers (ViTs). Our comprehensive analysis shows several novel insights that (1) With KDIGA, students can preserve or even exceed the adversarial robustness of the teacher model, even when their models have fundamentally different architectures; (2) KDIGA enables robustness to transfer to pre-trained students, such as KD from an adversarially trained ResNet to a pre-trained ViT, without loss of clean accuracy; and (3) Our derived local linearity bounds for characterizing adversarial robustness in KD are consistent with the empirical results.