 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePietro Perona
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022
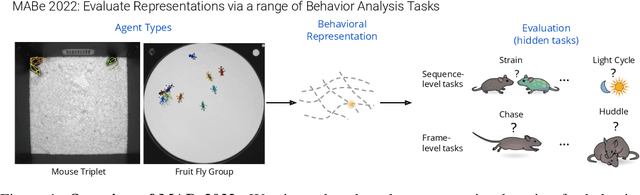
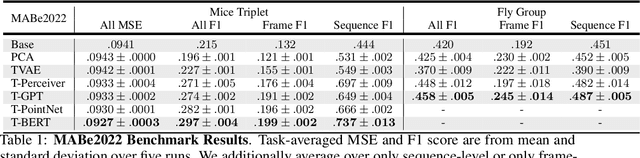
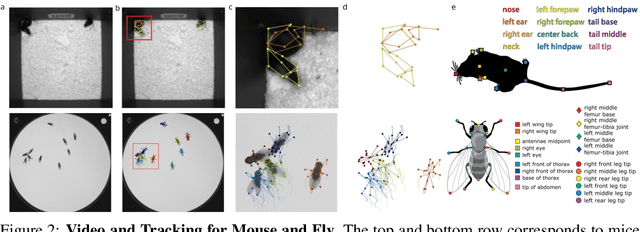
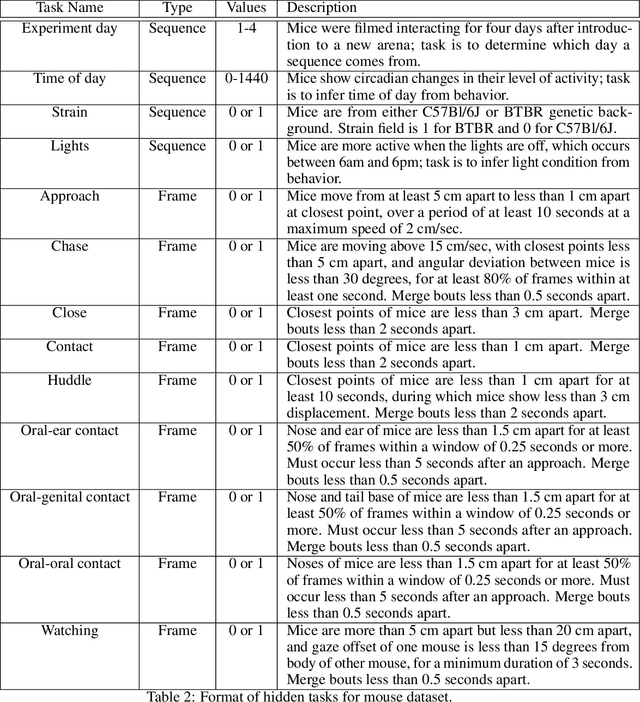
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.
On Label Granularity and Object Localization
Jul 20, 2022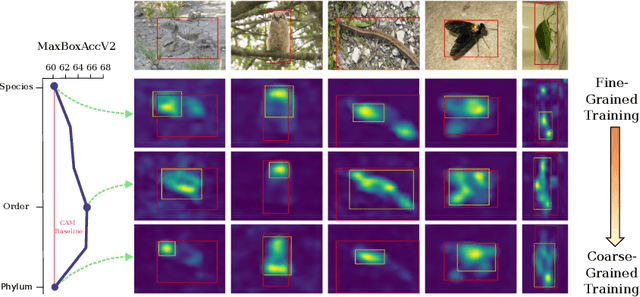

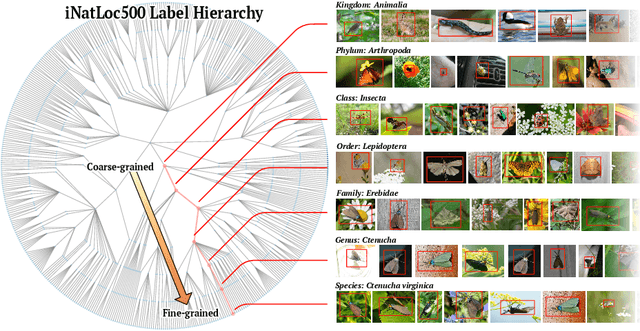
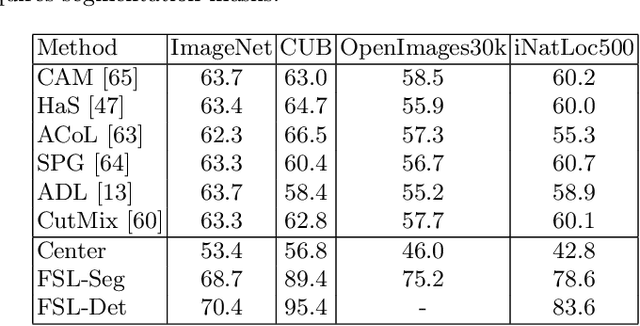
Weakly supervised object localization (WSOL) aims to learn representations that encode object location using only image-level category labels. However, many objects can be labeled at different levels of granularity. Is it an animal, a bird, or a great horned owl? Which image-level labels should we use? In this paper we study the role of label granularity in WSOL. To facilitate this investigation we introduce iNatLoc500, a new large-scale fine-grained benchmark dataset for WSOL. Surprisingly, we find that choosing the right training label granularity provides a much larger performance boost than choosing the best WSOL algorithm. We also show that changing the label granularity can significantly improve data efficiency.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022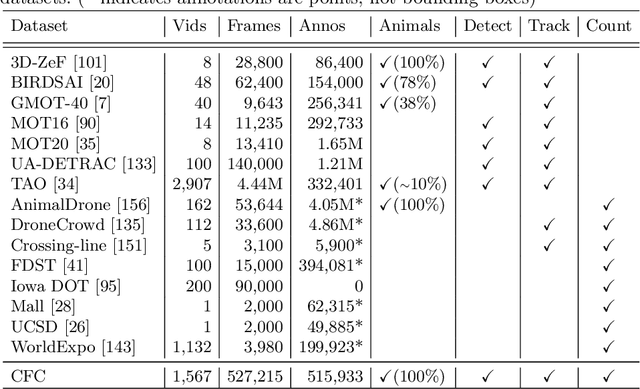
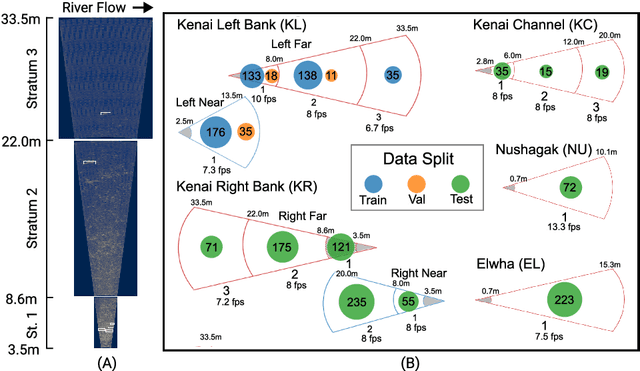
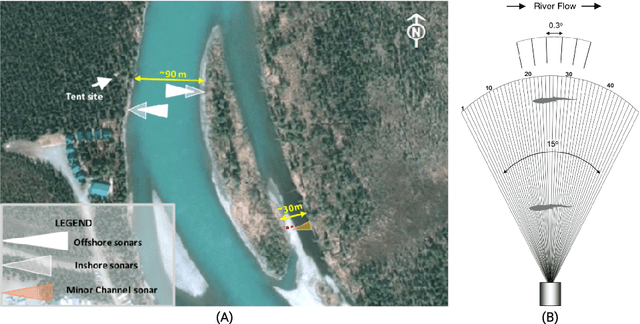

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.
Near Perfect GAN Inversion
Feb 23, 2022



To edit a real photo using Generative Adversarial Networks (GANs), we need a GAN inversion algorithm to identify the latent vector that perfectly reproduces it. Unfortunately, whereas existing inversion algorithms can synthesize images similar to real photos, they cannot generate the identical clones needed in most applications. Here, we derive an algorithm that achieves near perfect reconstructions of photos. Rather than relying on encoder- or optimization-based methods to find an inverse mapping on a fixed generator $G(\cdot)$, we derive an approach to locally adjust $G(\cdot)$ to more optimally represent the photos we wish to synthesize. This is done by locally tweaking the learned mapping $G(\cdot)$ s.t. $\| {\bf x} - G({\bf z}) \|<\epsilon$, with ${\bf x}$ the photo we wish to reproduce, ${\bf z}$ the latent vector, $\|\cdot\|$ an appropriate metric, and $\epsilon > 0$ a small scalar. We show that this approach can not only produce synthetic images that are indistinguishable from the real photos we wish to replicate, but that these images are readily editable. We demonstrate the effectiveness of the derived algorithm on a variety of datasets including human faces, animals, and cars, and discuss its importance for diversity and inclusion.
Towards Weakly-Supervised Text Spotting using a Multi-Task Transformer
Feb 14, 2022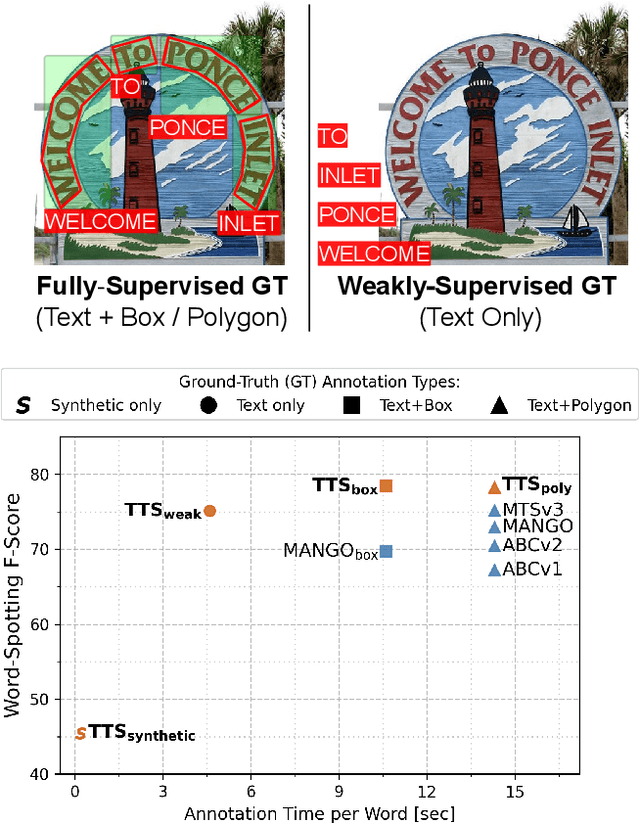
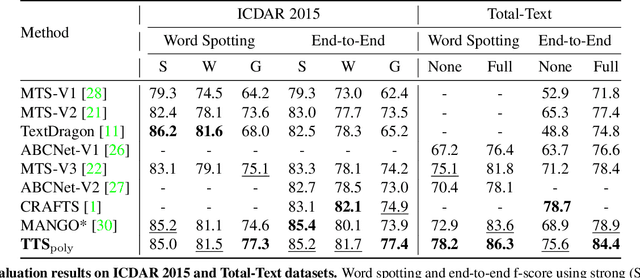
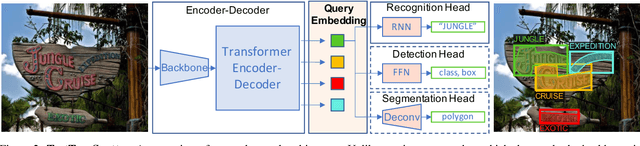
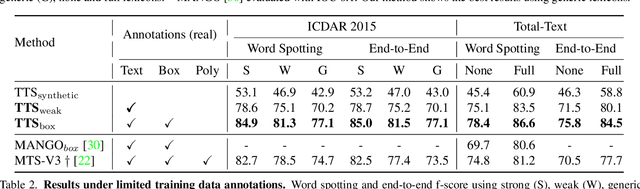
Text spotting end-to-end methods have recently gained attention in the literature due to the benefits of jointly optimizing the text detection and recognition components. Existing methods usually have a distinct separation between the detection and recognition branches, requiring exact annotations for the two tasks. We introduce TextTranSpotter (TTS), a transformer-based approach for text spotting and the first text spotting framework which may be trained with both fully- and weakly-supervised settings. By learning a single latent representation per word detection, and using a novel loss function based on the Hungarian loss, our method alleviates the need for expensive localization annotations. Trained with only text transcription annotations on real data, our weakly-supervised method achieves competitive performance with previous state-of-the-art fully-supervised methods. When trained in a fully-supervised manner, TextTranSpotter shows state-of-the-art results on multiple benchmarks.
Rayleigh EigenDirections (REDs): GAN latent space traversals for multidimensional features
Jan 25, 2022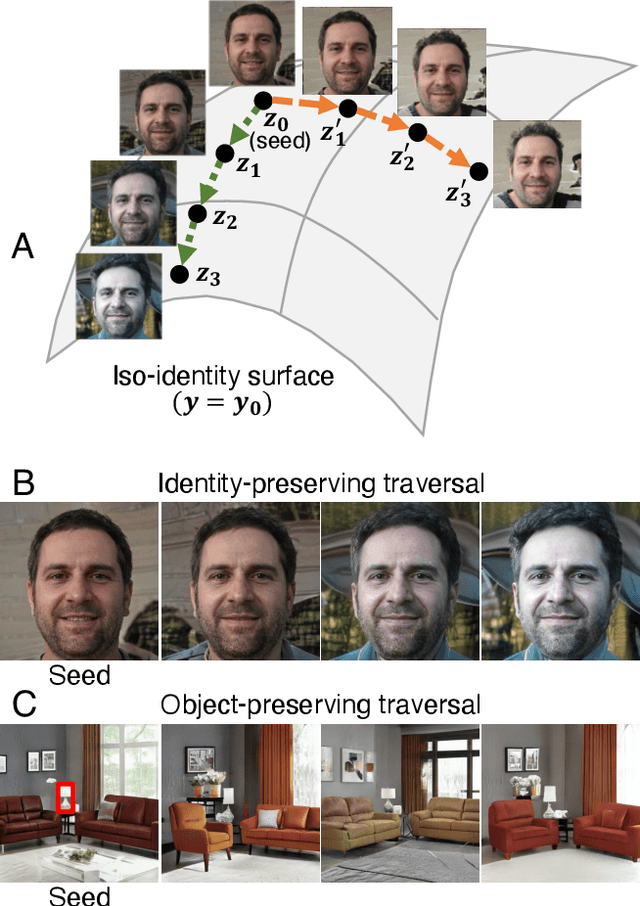

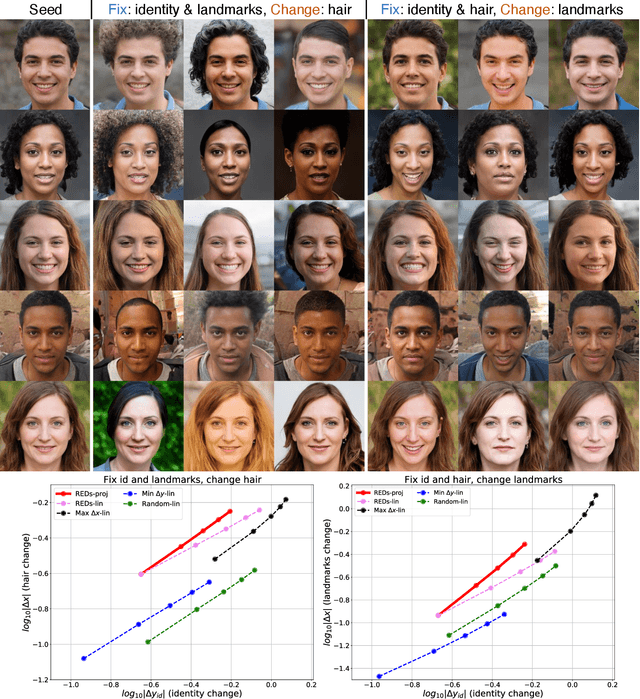

We present a method for finding paths in a deep generative model's latent space that can maximally vary one set of image features while holding others constant. Crucially, unlike past traversal approaches, ours can manipulate multidimensional features of an image such as facial identity and pixels within a specified region. Our method is principled and conceptually simple: optimal traversal directions are chosen by maximizing differential changes to one feature set such that changes to another set are negligible. We show that this problem is nearly equivalent to one of Rayleigh quotient maximization, and provide a closed-form solution to it based on solving a generalized eigenvalue equation. We use repeated computations of the corresponding optimal directions, which we call Rayleigh EigenDirections (REDs), to generate appropriately curved paths in latent space. We empirically evaluate our method using StyleGAN2 on two image domains: faces and living rooms. We show that our method is capable of controlling various multidimensional features out of the scope of previous latent space traversal methods: face identity, spatial frequency bands, pixels within a region, and the appearance and position of an object. Our work suggests that a wealth of opportunities lies in the local analysis of the geometry and semantics of latent spaces.
Self-Supervised Keypoint Discovery in Behavioral Videos
Dec 09, 2021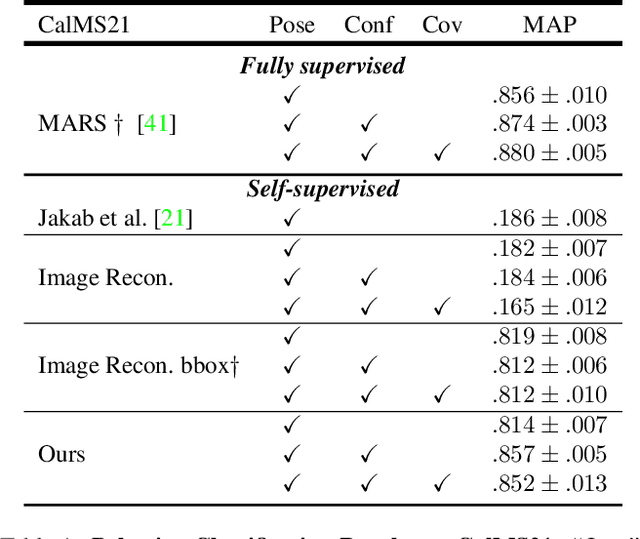
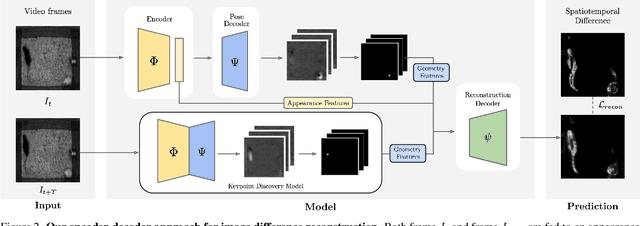

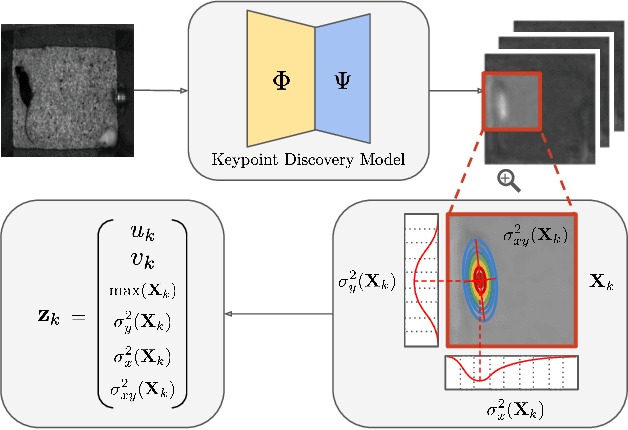
We propose a method for learning the posture and structure of agents from unlabelled behavioral videos. Starting from the observation that behaving agents are generally the main sources of movement in behavioral videos, our method uses an encoder-decoder architecture with a geometric bottleneck to reconstruct the difference between video frames. By focusing only on regions of movement, our approach works directly on input videos without requiring manual annotations, such as keypoints or bounding boxes. Experiments on a variety of agent types (mouse, fly, human, jellyfish, and trees) demonstrate the generality of our approach and reveal that our discovered keypoints represent semantically meaningful body parts, which achieve state-of-the-art performance on keypoint regression among self-supervised methods. Additionally, our discovered keypoints achieve comparable performance to supervised keypoints on downstream tasks, such as behavior classification, suggesting that our method can dramatically reduce the cost of model training vis-a-vis supervised methods.
Weakly Supervised Keypoint Discovery
Sep 28, 2021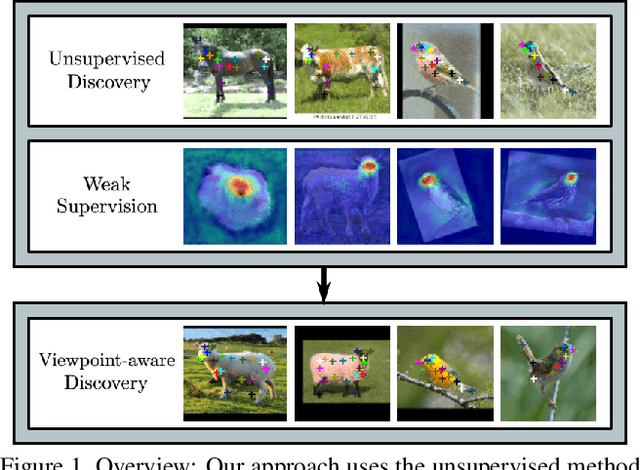

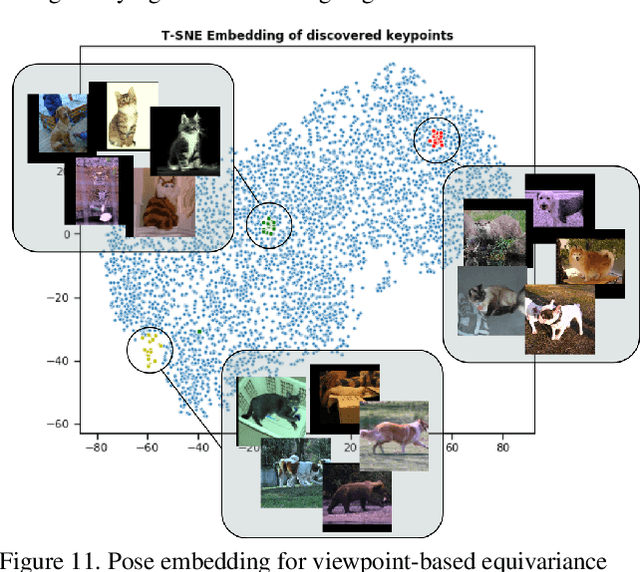

In this paper, we propose a method for keypoint discovery from a 2D image using image-level supervision. Recent works on unsupervised keypoint discovery reliably discover keypoints of aligned instances. However, when the target instances have high viewpoint or appearance variation, the discovered keypoints do not match the semantic correspondences over different images. Our work aims to discover keypoints even when the target instances have high viewpoint and appearance variation by using image-level supervision. Motivated by the weakly-supervised learning approach, our method exploits image-level supervision to identify discriminative parts and infer the viewpoint of the target instance. To discover diverse parts, we adopt a conditional image generation approach using a pair of images with structural deformation. Finally, we enforce a viewpoint-based equivariance constraint using the keypoints from the image-level supervision to resolve the spatial correlation problem that consistently appears in the images taken from various viewpoints. Our approach achieves state-of-the-art performance for the task of keypoint estimation on the limited supervision scenarios. Furthermore, the discovered keypoints are directly applicable to downstream tasks without requiring any keypoint labels.
Species Distribution Modeling for Machine Learning Practitioners: A Review
Jul 03, 2021
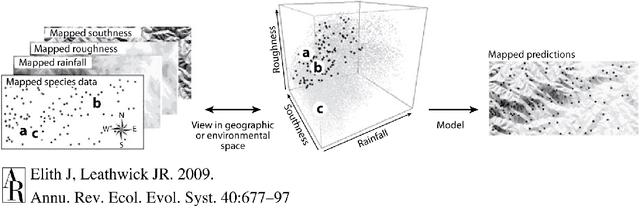

Conservation science depends on an accurate understanding of what's happening in a given ecosystem. How many species live there? What is the makeup of the population? How is that changing over time? Species Distribution Modeling (SDM) seeks to predict the spatial (and sometimes temporal) patterns of species occurrence, i.e. where a species is likely to be found. The last few years have seen a surge of interest in applying powerful machine learning tools to challenging problems in ecology. Despite its considerable importance, SDM has received relatively little attention from the computer science community. Our goal in this work is to provide computer scientists with the necessary background to read the SDM literature and develop ecologically useful ML-based SDM algorithms. In particular, we introduce key SDM concepts and terminology, review standard models, discuss data availability, and highlight technical challenges and pitfalls.
Multi-Label Learning from Single Positive Labels
Jun 17, 2021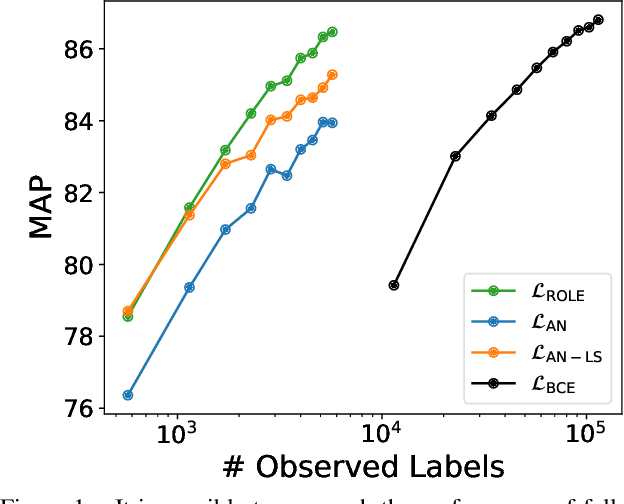
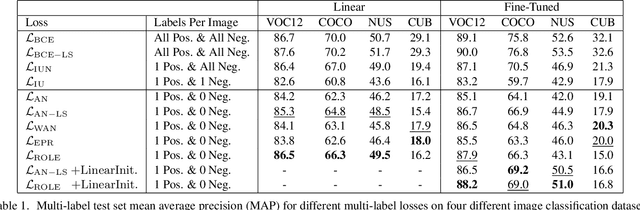
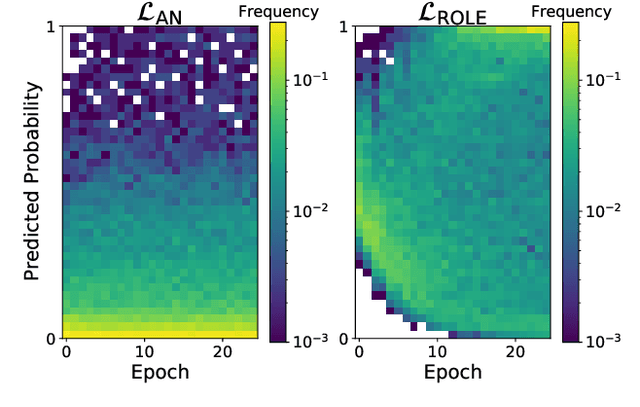
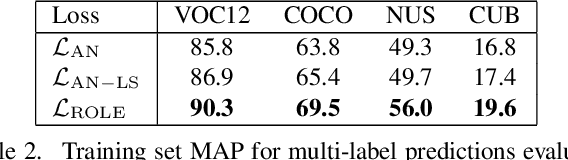
Predicting all applicable labels for a given image is known as multi-label classification. Compared to the standard multi-class case (where each image has only one label), it is considerably more challenging to annotate training data for multi-label classification. When the number of potential labels is large, human annotators find it difficult to mention all applicable labels for each training image. Furthermore, in some settings detection is intrinsically difficult e.g. finding small object instances in high resolution images. As a result, multi-label training data is often plagued by false negatives. We consider the hardest version of this problem, where annotators provide only one relevant label for each image. As a result, training sets will have only one positive label per image and no confirmed negatives. We explore this special case of learning from missing labels across four different multi-label image classification datasets for both linear classifiers and end-to-end fine-tuned deep networks. We extend existing multi-label losses to this setting and propose novel variants that constrain the number of expected positive labels during training. Surprisingly, we show that in some cases it is possible to approach the performance of fully labeled classifiers despite training with significantly fewer confirmed labels.