 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting For Distribution Shifts with Conditional Conformal Test Martingales
Feb 14, 2026We propose a sequential test for detecting arbitrary distribution shifts that allows conformal test martingales (CTMs) to work under a fixed, reference-conditional setting. Existing CTM detectors construct test martingales by continually growing a reference set with each incoming sample, using it to assess how atypical the new sample is relative to past observations. While this design yields anytime-valid type-I error control, it suffers from test-time contamination: after a change, post-shift observations enter the reference set and dilute the evidence for distribution shift, increasing detection delay and reducing power. In contrast, our method avoids contamination by design by comparing each new sample to a fixed null reference dataset. Our main technical contribution is a robust martingale construction that remains valid conditional on the null reference data, achieved by explicitly accounting for the estimation error in the reference distribution induced by the finite reference set. This yields anytime-valid type-I error control together with guarantees of asymptotic power one and bounded expected detection delay. Empirically, our method detects shifts faster than standard CTMs, providing a powerful and reliable distribution-shift detector.
Protected Test-Time Adaptation via Online Entropy Matching: A Betting Approach
Aug 14, 2024We present a novel approach for test-time adaptation via online self-training, consisting of two components. First, we introduce a statistical framework that detects distribution shifts in the classifier's entropy values obtained on a stream of unlabeled samples. Second, we devise an online adaptation mechanism that utilizes the evidence of distribution shifts captured by the detection tool to dynamically update the classifier's parameters. The resulting adaptation process drives the distribution of test entropy values obtained from the self-trained classifier to match those of the source domain, building invariance to distribution shifts. This approach departs from the conventional self-training method, which focuses on minimizing the classifier's entropy. Our approach combines concepts in betting martingales and online learning to form a detection tool capable of quickly reacting to distribution shifts. We then reveal a tight relation between our adaptation scheme and optimal transport, which forms the basis of our novel self-supervised loss. Experimental results demonstrate that our approach improves test-time accuracy under distribution shifts while maintaining accuracy and calibration in their absence, outperforming leading entropy minimization methods across various scenarios.
Towards Weakly-Supervised Text Spotting using a Multi-Task Transformer
Feb 14, 2022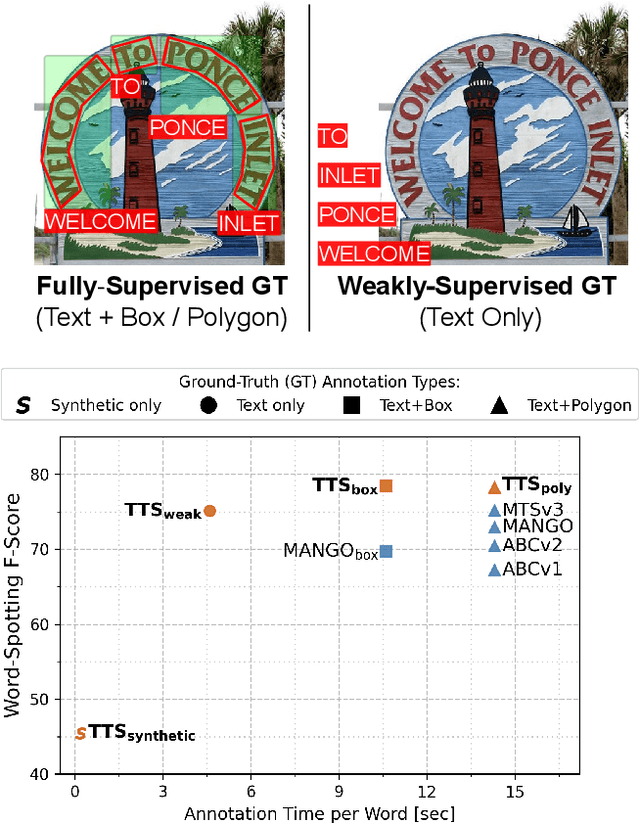
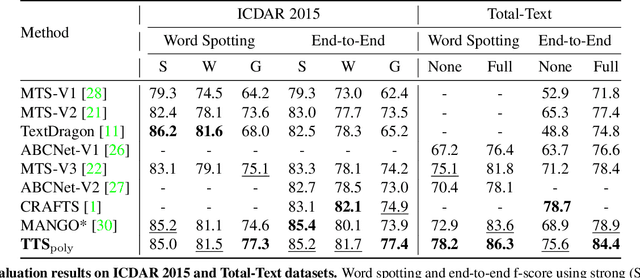
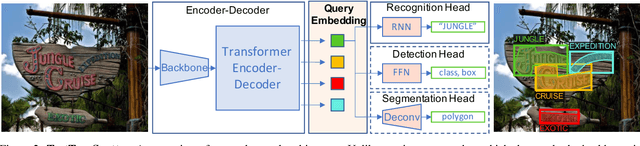
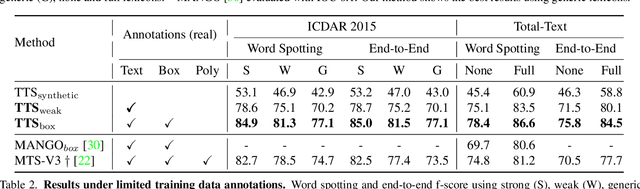
Text spotting end-to-end methods have recently gained attention in the literature due to the benefits of jointly optimizing the text detection and recognition components. Existing methods usually have a distinct separation between the detection and recognition branches, requiring exact annotations for the two tasks. We introduce TextTranSpotter (TTS), a transformer-based approach for text spotting and the first text spotting framework which may be trained with both fully- and weakly-supervised settings. By learning a single latent representation per word detection, and using a novel loss function based on the Hungarian loss, our method alleviates the need for expensive localization annotations. Trained with only text transcription annotations on real data, our weakly-supervised method achieves competitive performance with previous state-of-the-art fully-supervised methods. When trained in a fully-supervised manner, TextTranSpotter shows state-of-the-art results on multiple benchmarks.