 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
Jumpstarting Surgical Computer Vision
Dec 10, 2023



Purpose: General consensus amongst researchers and industry points to a lack of large, representative annotated datasets as the biggest obstacle to progress in the field of surgical data science. Self-supervised learning represents a solution to part of this problem, removing the reliance on annotations. However, the robustness of current self-supervised learning methods to domain shifts remains unclear, limiting our understanding of its utility for leveraging diverse sources of surgical data. Methods: In this work, we employ self-supervised learning to flexibly leverage diverse surgical datasets, thereby learning taskagnostic representations that can be used for various surgical downstream tasks. Based on this approach, to elucidate the impact of pre-training on downstream task performance, we explore 22 different pre-training dataset combinations by modulating three variables: source hospital, type of surgical procedure, and pre-training scale (number of videos). We then finetune the resulting model initializations on three diverse downstream tasks: namely, phase recognition and critical view of safety in laparoscopic cholecystectomy and phase recognition in laparoscopic hysterectomy. Results: Controlled experimentation highlights sizable boosts in performance across various tasks, datasets, and labeling budgets. However, this performance is intricately linked to the composition of the pre-training dataset, robustly proven through several study stages. Conclusion: The composition of pre-training datasets can severely affect the effectiveness of SSL methods for various downstream tasks and should critically inform future data collection efforts to scale the application of SSL methodologies. Keywords: Self-Supervised Learning, Transfer Learning, Surgical Computer Vision, Endoscopic Videos, Critical View of Safety, Phase Recognition
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Jul 27, 2023



Recent advancements in surgical computer vision applications have been driven by fully-supervised methods, primarily using only visual data. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. SurgVLP constructs a new contrastive learning objective to align video clip embeddings with the corresponding multiple text embeddings by bringing them together within a joint latent space. To effectively show the representation capability of the learned joint latent space, we introduce several vision-and-language tasks for surgery, such as text-based video retrieval, temporal activity grounding, and video captioning, as benchmarks for evaluation. We further demonstrate that without using any labeled ground truth, our approach can be employed for traditional vision-only surgical downstream tasks, such as surgical tool, phase, and triplet recognition. The code will be made available at https://github.com/CAMMA-public/SurgVLP
Weakly Supervised Temporal Convolutional Networks for Fine-grained Surgical Activity Recognition
Feb 21, 2023



Automatic recognition of fine-grained surgical activities, called steps, is a challenging but crucial task for intelligent intra-operative computer assistance. The development of current vision-based activity recognition methods relies heavily on a high volume of manually annotated data. This data is difficult and time-consuming to generate and requires domain-specific knowledge. In this work, we propose to use coarser and easier-to-annotate activity labels, namely phases, as weak supervision to learn step recognition with fewer step annotated videos. We introduce a step-phase dependency loss to exploit the weak supervision signal. We then employ a Single-Stage Temporal Convolutional Network (SS-TCN) with a ResNet-50 backbone, trained in an end-to-end fashion from weakly annotated videos, for temporal activity segmentation and recognition. We extensively evaluate and show the effectiveness of the proposed method on a large video dataset consisting of 40 laparoscopic gastric bypass procedures and the public benchmark CATARACTS containing 50 cataract surgeries.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023



Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Preserving Privacy in Surgical Video Analysis Using Artificial Intelligence: A Deep Learning Classifier to Identify Out-of-Body Scenes in Endoscopic Videos
Jan 17, 2023Objective: To develop and validate a deep learning model for the identification of out-of-body images in endoscopic videos. Background: Surgical video analysis facilitates education and research. However, video recordings of endoscopic surgeries can contain privacy-sensitive information, especially if out-of-body scenes are recorded. Therefore, identification of out-of-body scenes in endoscopic videos is of major importance to preserve the privacy of patients and operating room staff. Methods: A deep learning model was trained and evaluated on an internal dataset of 12 different types of laparoscopic and robotic surgeries. External validation was performed on two independent multicentric test datasets of laparoscopic gastric bypass and cholecystectomy surgeries. All images extracted from the video datasets were annotated as inside or out-of-body. Model performance was evaluated compared to human ground truth annotations measuring the receiver operating characteristic area under the curve (ROC AUC). Results: The internal dataset consisting of 356,267 images from 48 videos and the two multicentric test datasets consisting of 54,385 and 58,349 images from 10 and 20 videos, respectively, were annotated. Compared to ground truth annotations, the model identified out-of-body images with 99.97% ROC AUC on the internal test dataset. Mean $\pm$ standard deviation ROC AUC on the multicentric gastric bypass dataset was 99.94$\pm$0.07% and 99.71$\pm$0.40% on the multicentric cholecystectomy dataset, respectively. Conclusion: The proposed deep learning model can reliably identify out-of-body images in endoscopic videos. The trained model is publicly shared. This facilitates privacy preservation in surgical video analysis.
Real-Time Artificial Intelligence Assistance for Safe Laparoscopic Cholecystectomy: Early-Stage Clinical Evaluation
Dec 13, 2022
Artificial intelligence is set to be deployed in operating rooms to improve surgical care. This early-stage clinical evaluation shows the feasibility of concurrently attaining real-time, high-quality predictions from several deep neural networks for endoscopic video analysis deployed for assistance during three laparoscopic cholecystectomies.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022



Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022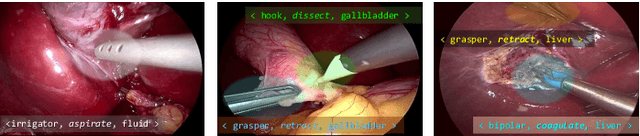

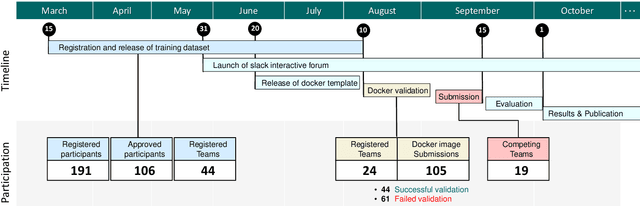
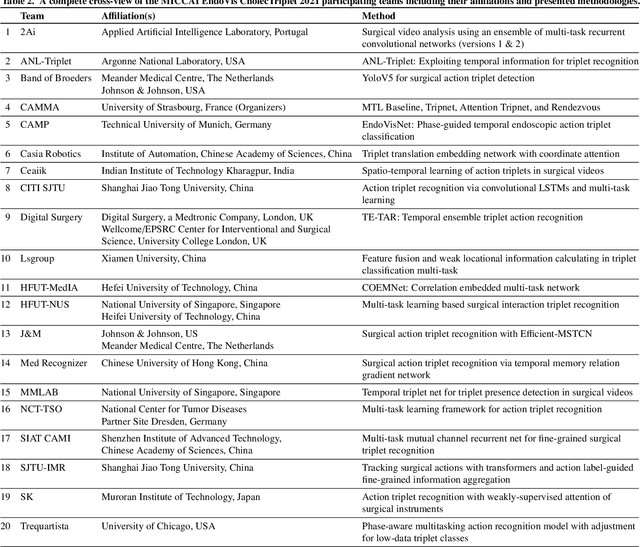
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Federated Cycling (FedCy): Semi-supervised Federated Learning of Surgical Phases
Mar 14, 2022
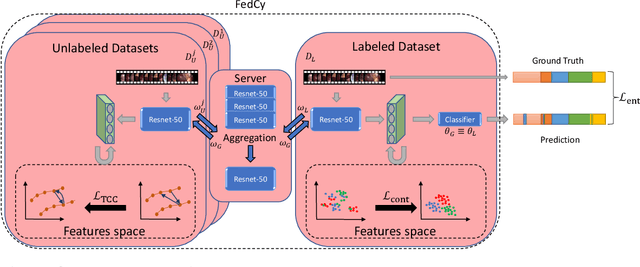
Recent advancements in deep learning methods bring computer-assistance a step closer to fulfilling promises of safer surgical procedures. However, the generalizability of such methods is often dependent on training on diverse datasets from multiple medical institutions, which is a restrictive requirement considering the sensitive nature of medical data. Recently proposed collaborative learning methods such as Federated Learning (FL) allow for training on remote datasets without the need to explicitly share data. Even so, data annotation still represents a bottleneck, particularly in medicine and surgery where clinical expertise is often required. With these constraints in mind, we propose FedCy, a federated semi-supervised learning (FSSL) method that combines FL and self-supervised learning to exploit a decentralized dataset of both labeled and unlabeled videos, thereby improving performance on the task of surgical phase recognition. By leveraging temporal patterns in the labeled data, FedCy helps guide unsupervised training on unlabeled data towards learning task-specific features for phase recognition. We demonstrate significant performance gains over state-of-the-art FSSL methods on the task of automatic recognition of surgical phases using a newly collected multi-institutional dataset of laparoscopic cholecystectomy videos. Furthermore, we demonstrate that our approach also learns more generalizable features when tested on data from an unseen domain.