 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Lexicon Induction for Low-Resource Languages using Graph Matching via Optimal Transport
Oct 25, 2022



Bilingual lexicons form a critical component of various natural language processing applications, including unsupervised and semisupervised machine translation and crosslingual information retrieval. We improve bilingual lexicon induction performance across 40 language pairs with a graph-matching method based on optimal transport. The method is especially strong with low amounts of supervision.
IsoVec: Controlling the Relative Isomorphism of Word Embedding Spaces
Oct 11, 2022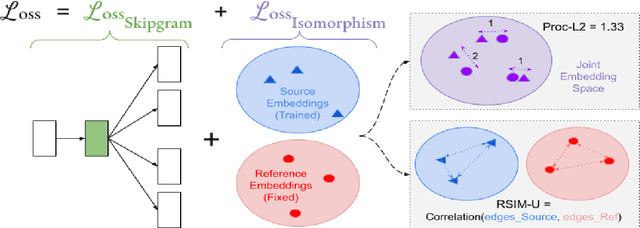
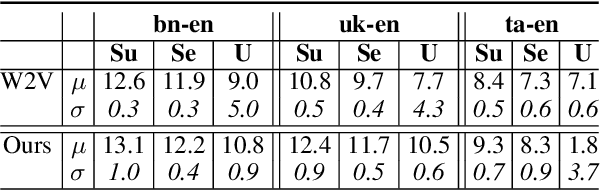
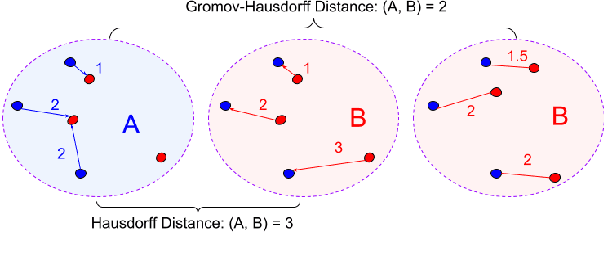

The ability to extract high-quality translation dictionaries from monolingual word embedding spaces depends critically on the geometric similarity of the spaces -- their degree of "isomorphism." We address the root-cause of faulty cross-lingual mapping: that word embedding training resulted in the underlying spaces being non-isomorphic. We incorporate global measures of isomorphism directly into the skipgram loss function, successfully increasing the relative isomorphism of trained word embedding spaces and improving their ability to be mapped to a shared cross-lingual space. The result is improved bilingual lexicon induction in general data conditions, under domain mismatch, and with training algorithm dissimilarities. We release IsoVec at https://github.com/kellymarchisio/isovec.
Multilingual Representation Distillation with Contrastive Learning
Oct 10, 2022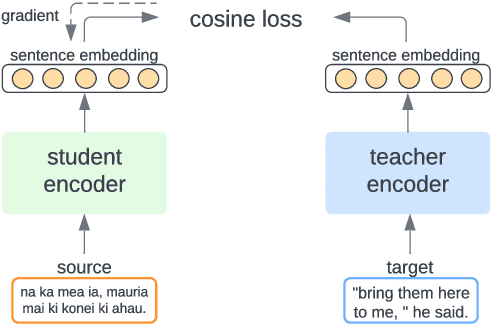

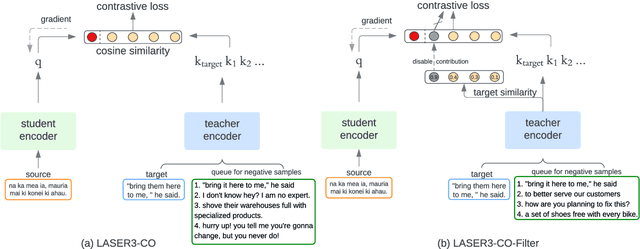
Multilingual sentence representations from large models can encode semantic information from two or more languages and can be used for different cross-lingual information retrieval tasks. In this paper, we integrate contrastive learning into multilingual representation distillation and use it for quality estimation of parallel sentences (find semantically similar sentences that can be used as translations of each other). We validate our approach with multilingual similarity search and corpus filtering tasks. Experiments across different low-resource languages show that our method significantly outperforms previous sentence encoders such as LASER, LASER3, and LaBSE.
Bitext Mining for Low-Resource Languages via Contrastive Learning
Aug 23, 2022
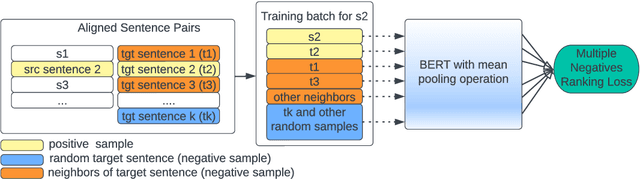
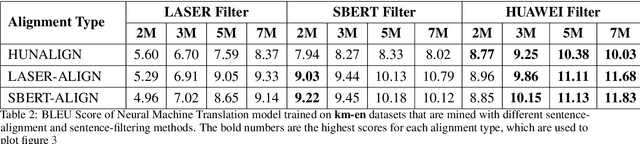
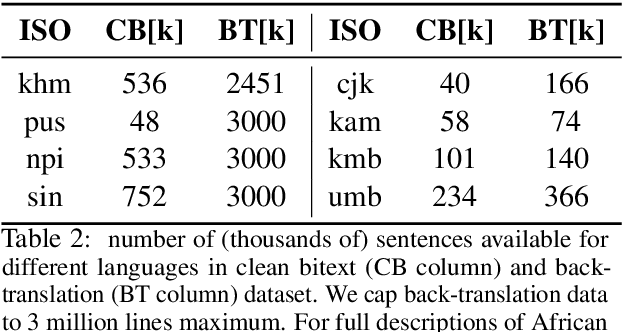
Mining high-quality bitexts for low-resource languages is challenging. This paper shows that sentence representation of language models fine-tuned with multiple negatives ranking loss, a contrastive objective, helps retrieve clean bitexts. Experiments show that parallel data mined from our approach substantially outperform the previous state-of-the-art method on low resource languages Khmer and Pashto.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
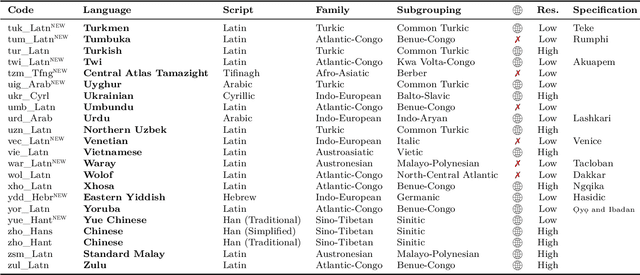
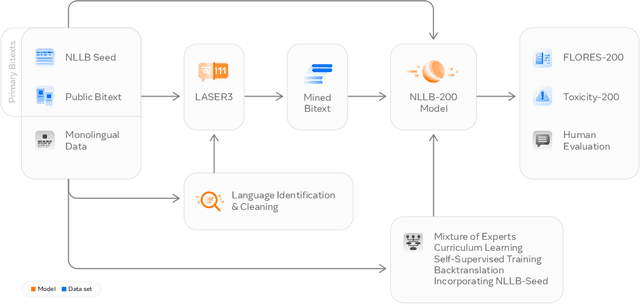
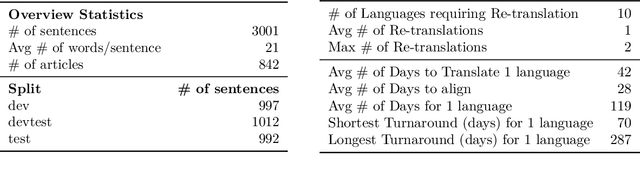
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
The Importance of Being Parameters: An Intra-Distillation Method for Serious Gains
May 23, 2022

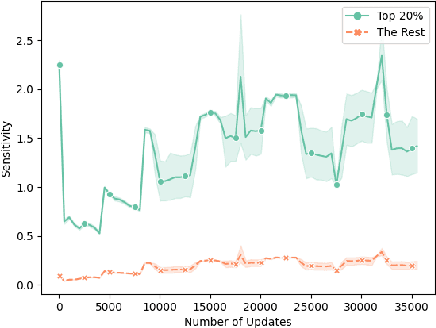

Recent model pruning methods have demonstrated the ability to remove redundant parameters without sacrificing model performance. Common methods remove redundant parameters according to the parameter sensitivity, a gradient-based measure reflecting the contribution of the parameters. In this paper, however, we argue that redundant parameters can be trained to make beneficial contributions. We first highlight the large sensitivity (contribution) gap among high-sensitivity and low-sensitivity parameters and show that the model generalization performance can be significantly improved after balancing the contribution of all parameters. Our goal is to balance the sensitivity of all parameters and encourage all of them to contribute equally. We propose a general task-agnostic method, namely intra-distillation, appended to the regular training loss to balance parameter sensitivity. Moreover, we also design a novel adaptive learning method to control the strength of intra-distillation loss for faster convergence. Our experiments show the strong effectiveness of our methods on machine translation, natural language understanding, and zero-shot cross-lingual transfer across up to 48 languages, e.g., a gain of 3.54 BLEU on average across 8 language pairs from the IWSLT'14 translation dataset.
Consistent Human Evaluation of Machine Translation across Language Pairs
May 17, 2022
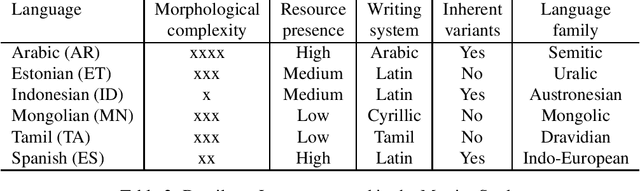
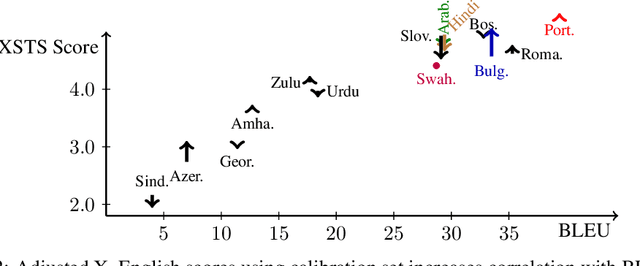
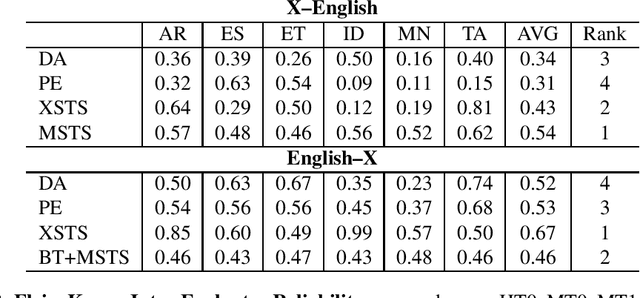
Obtaining meaningful quality scores for machine translation systems through human evaluation remains a challenge given the high variability between human evaluators, partly due to subjective expectations for translation quality for different language pairs. We propose a new metric called XSTS that is more focused on semantic equivalence and a cross-lingual calibration method that enables more consistent assessment. We demonstrate the effectiveness of these novel contributions in large scale evaluation studies across up to 14 language pairs, with translation both into and out of English.
Learn To Remember: Transformer with Recurrent Memory for Document-Level Machine Translation
May 03, 2022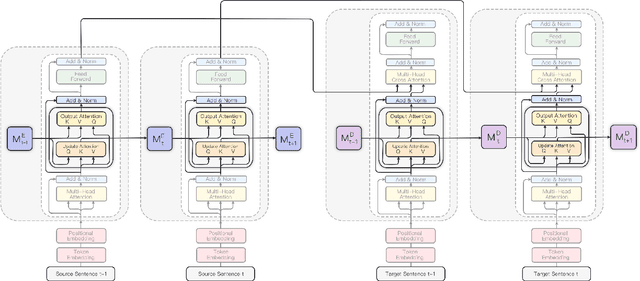
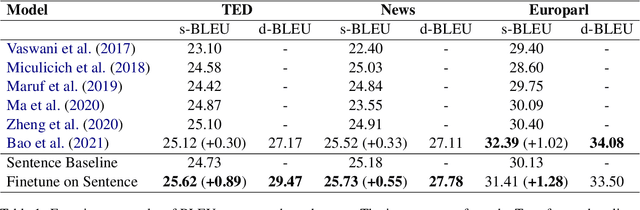

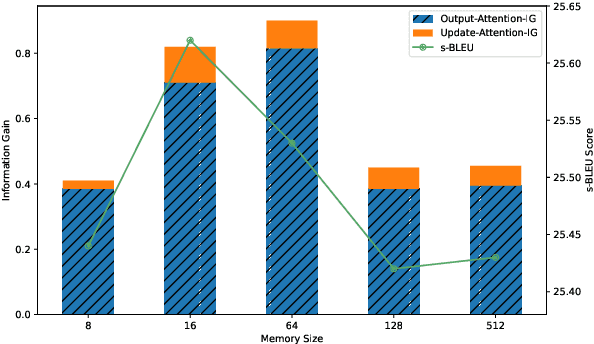
The Transformer architecture has led to significant gains in machine translation. However, most studies focus on only sentence-level translation without considering the context dependency within documents, leading to the inadequacy of document-level coherence. Some recent research tried to mitigate this issue by introducing an additional context encoder or translating with multiple sentences or even the entire document. Such methods may lose the information on the target side or have an increasing computational complexity as documents get longer. To address such problems, we introduce a recurrent memory unit to the vanilla Transformer, which supports the information exchange between the sentence and previous context. The memory unit is recurrently updated by acquiring information from sentences, and passing the aggregated knowledge back to subsequent sentence states. We follow a two-stage training strategy, in which the model is first trained at the sentence level and then finetuned for document-level translation. We conduct experiments on three popular datasets for document-level machine translation and our model has an average improvement of 0.91 s-BLEU over the sentence-level baseline. We also achieve state-of-the-art results on TED and News, outperforming the previous work by 0.36 s-BLEU and 1.49 d-BLEU on average.
Data Selection Curriculum for Neural Machine Translation
Mar 25, 2022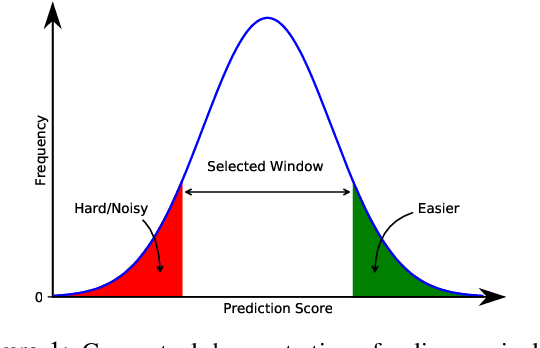
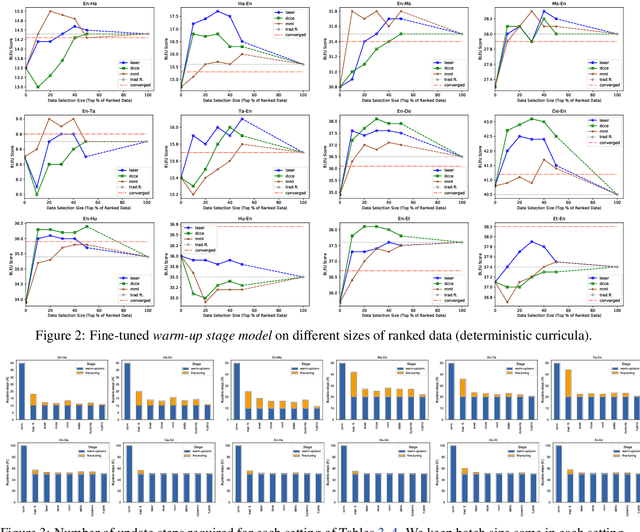
Neural Machine Translation (NMT) models are typically trained on heterogeneous data that are concatenated and randomly shuffled. However, not all of the training data are equally useful to the model. Curriculum training aims to present the data to the NMT models in a meaningful order. In this work, we introduce a two-stage curriculum training framework for NMT where we fine-tune a base NMT model on subsets of data, selected by both deterministic scoring using pre-trained methods and online scoring that considers prediction scores of the emerging NMT model. Through comprehensive experiments on six language pairs comprising low- and high-resource languages from WMT'21, we have shown that our curriculum strategies consistently demonstrate better quality (up to +2.2 BLEU improvement) and faster convergence (approximately 50% fewer updates).
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Oct 15, 2021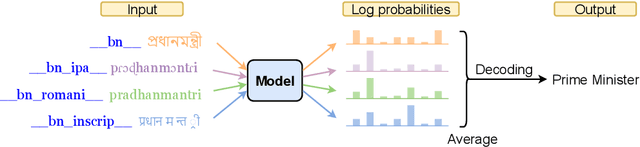
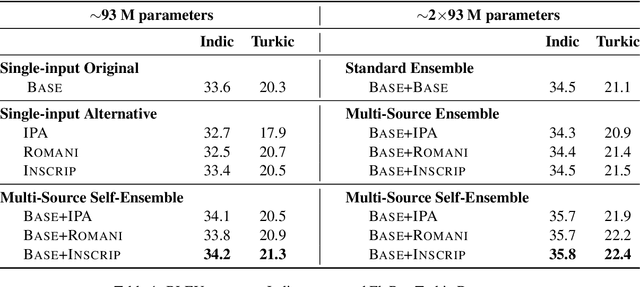
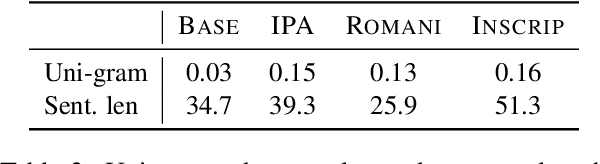
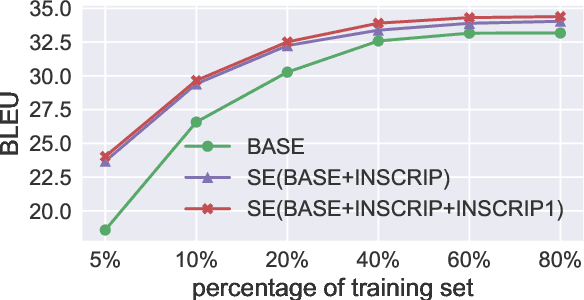
Recent work in multilingual machine translation (MMT) has focused on the potential of positive transfer between languages, particularly cases where higher-resourced languages can benefit lower-resourced ones. While training an MMT model, the supervision signals learned from one language pair can be transferred to the other via the tokens shared by multiple source languages. However, the transfer is inhibited when the token overlap among source languages is small, which manifests naturally when languages use different writing systems. In this paper, we tackle inhibited transfer by augmenting the training data with alternative signals that unify different writing systems, such as phonetic, romanized, and transliterated input. We test these signals on Indic and Turkic languages, two language families where the writing systems differ but languages still share common features. Our results indicate that a straightforward multi-source self-ensemble -- training a model on a mixture of various signals and ensembling the outputs of the same model fed with different signals during inference, outperforms strong ensemble baselines by 1.3 BLEU points on both language families. Further, we find that incorporating alternative inputs via self-ensemble can be particularly effective when training set is small, leading to +5 BLEU when only 5% of the total training data is accessible. Finally, our analysis demonstrates that including alternative signals yields more consistency and translates named entities more accurately, which is crucial for increased factuality of automated systems.