 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha MAML: Adaptive Model-Agnostic Meta-Learning
May 17, 2019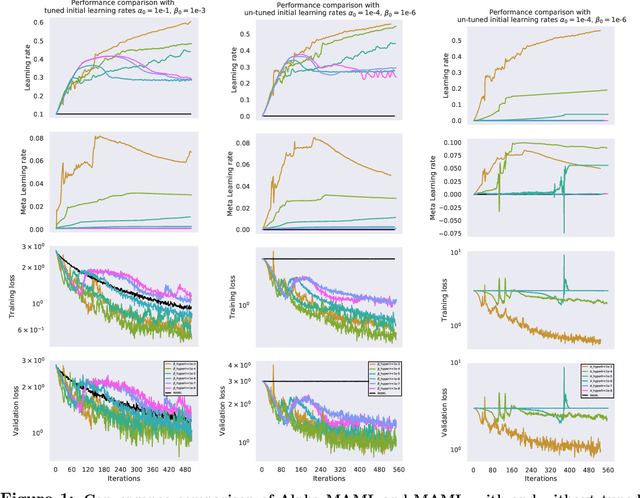
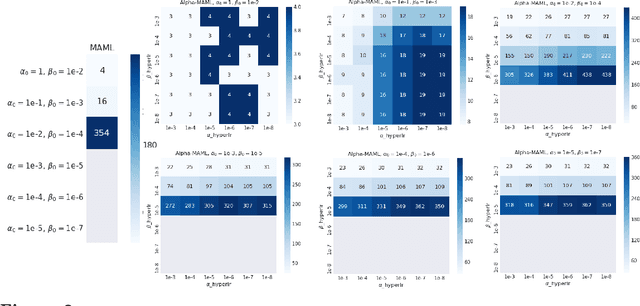
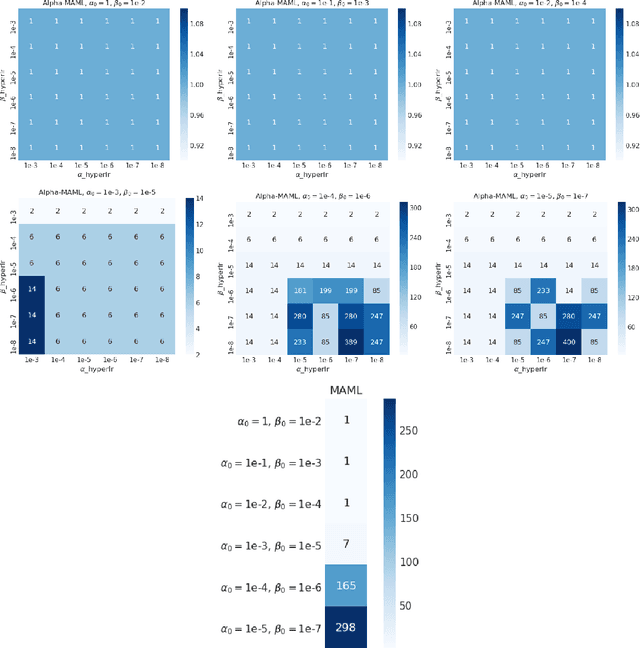
Model-agnostic meta-learning (MAML) is a meta-learning technique to train a model on a multitude of learning tasks in a way that primes the model for few-shot learning of new tasks. The MAML algorithm performs well on few-shot learning problems in classification, regression, and fine-tuning of policy gradients in reinforcement learning, but comes with the need for costly hyperparameter tuning for training stability. We address this shortcoming by introducing an extension to MAML, called Alpha MAML, to incorporate an online hyperparameter adaptation scheme that eliminates the need to tune meta-learning and learning rates. Our results with the Omniglot database demonstrate a substantial reduction in the need to tune MAML training hyperparameters and improvement to training stability with less sensitivity to hyperparameter choice.
GA-Net: Guided Aggregation Net for End-to-end Stereo Matching
Apr 13, 2019
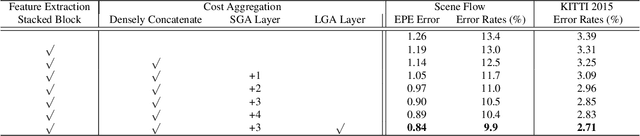
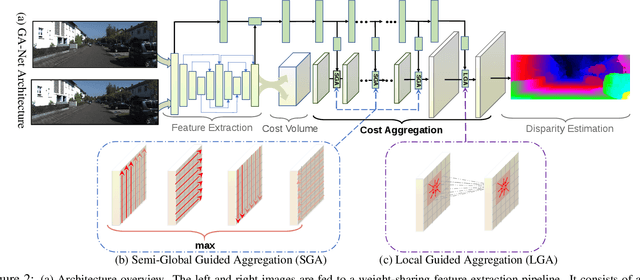
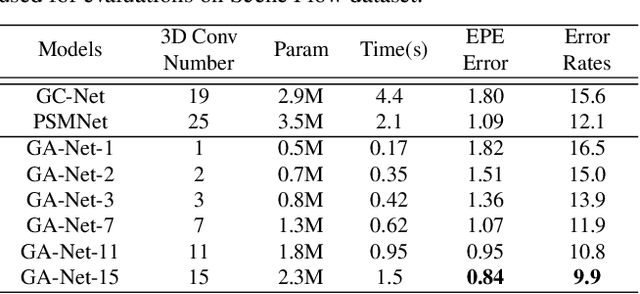
In the stereo matching task, matching cost aggregation is crucial in both traditional methods and deep neural network models in order to accurately estimate disparities. We propose two novel neural net layers, aimed at capturing local and the whole-image cost dependencies respectively. The first is a semi-global aggregation layer which is a differentiable approximation of the semi-global matching, the second is the local guided aggregation layer which follows a traditional cost filtering strategy to refine thin structures. These two layers can be used to replace the widely used 3D convolutional layer which is computationally costly and memory-consuming as it has cubic computational/memory complexity. In the experiments, we show that nets with a two-layer guided aggregation block easily outperform the state-of-the-art GC-Net which has nineteen 3D convolutional layers. We also train a deep guided aggregation network (GA-Net) which gets better accuracies than state-of-the-art methods on both Scene Flow dataset and KITTI benchmarks.
Deep Virtual Networks for Memory Efficient Inference of Multiple Tasks
Apr 09, 2019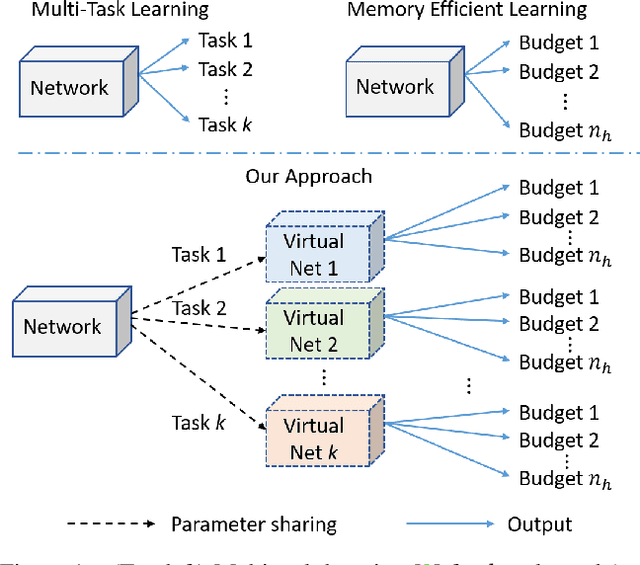
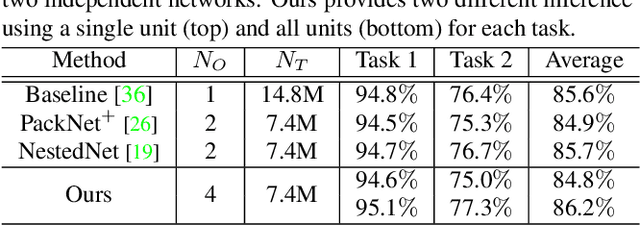
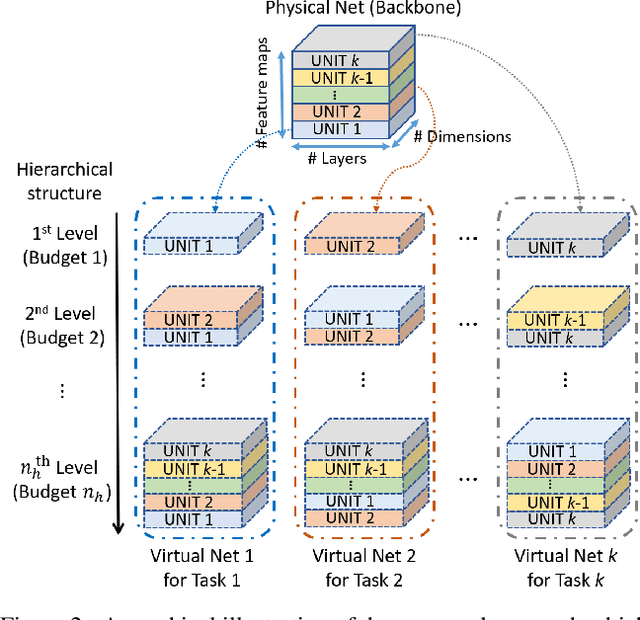
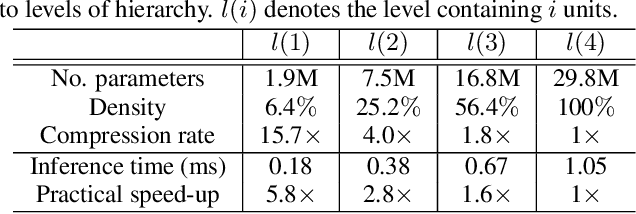
Deep networks consume a large amount of memory by their nature. A natural question arises can we reduce that memory requirement whilst maintaining performance. In particular, in this work we address the problem of memory efficient learning for multiple tasks. To this end, we propose a novel network architecture producing multiple networks of different configurations, termed deep virtual networks (DVNs), for different tasks. Each DVN is specialized for a single task and structured hierarchically. The hierarchical structure, which contains multiple levels of hierarchy corresponding to different numbers of parameters, enables multiple inference for different memory budgets. The building block of a deep virtual network is based on a disjoint collection of parameters of a network, which we call a unit. The lowest level of hierarchy in a deep virtual network is a unit, and higher levels of hierarchy contain lower levels' units and other additional units. Given a budget on the number of parameters, a different level of a deep virtual network can be chosen to perform the task. A unit can be shared by different DVNs, allowing multiple DVNs in a single network. In addition, shared units provide assistance to the target task with additional knowledge learned from another tasks. This cooperative configuration of DVNs makes it possible to handle different tasks in a memory-aware manner. Our experiments show that the proposed method outperforms existing approaches for multiple tasks. Notably, ours is more efficient than others as it allows memory-aware inference for all tasks.
Learning to Adapt for Stereo
Apr 05, 2019
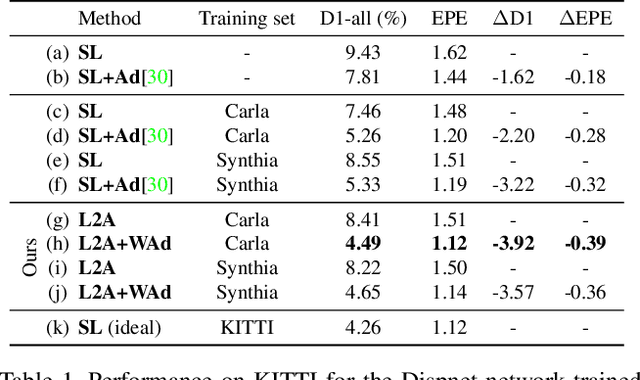
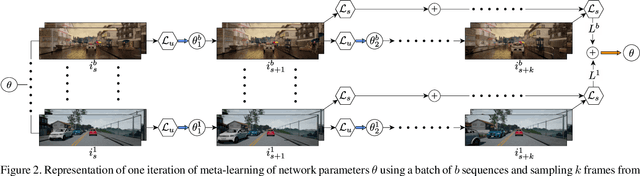
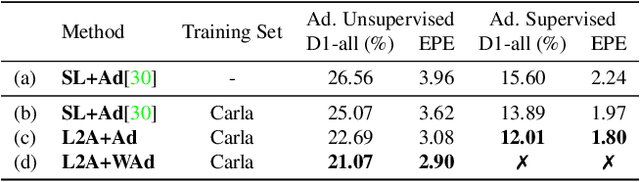
Real world applications of stereo depth estimation require models that are robust to dynamic variations in the environment. Even though deep learning based stereo methods are successful, they often fail to generalize to unseen variations in the environment, making them less suitable for practical applications such as autonomous driving. In this work, we introduce a "learning-to-adapt" framework that enables deep stereo methods to continuously adapt to new target domains in an unsupervised manner. Specifically, our approach incorporates the adaptation procedure into the learning objective to obtain a base set of parameters that are better suited for unsupervised online adaptation. To further improve the quality of the adaptation, we learn a confidence measure that effectively masks the errors introduced during the unsupervised adaptation. We evaluate our method on synthetic and real-world stereo datasets and our experiments evidence that learning-to-adapt is, indeed beneficial for online adaptation on vastly different domains.
Metric Attack and Defense for Person Re-identification
Mar 23, 2019
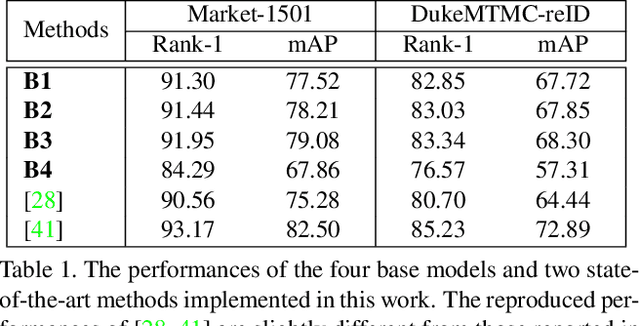

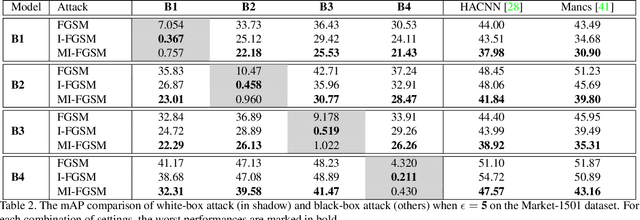
Person re-identification (re-ID) has attracted much attention recently due to its great importance in video surveillance. In general, distance metrics used to identify two person images are expected to be robust under various appearance changes. However, our work observes the extreme vulnerability of existing distance metrics to adversarial examples, generated by simply adding human-imperceptible perturbations to person images. Hence, the security danger is dramatically increased when deploying commercial re-ID systems in video surveillance. Although adversarial examples have been extensively applied for classification analysis, it is rarely studied in metric analysis like person re-identification. The most likely reason is the natural gap between the training and testing of re-ID networks, that is, the predictions of a re-ID network cannot be directly used during testing without an effective metric. In this work, we bridge the gap by proposing Adversarial Metric Attack, a parallel methodology to adversarial classification attacks. Comprehensive experiments clearly reveal the adversarial effects in re-ID systems. Meanwhile, we also present an early attempt of training a metric-preserving network, thereby defending the metric against adversarial attacks. At last, by benchmarking various adversarial settings, we expect that our work can facilitate the development of adversarial attack and defense in metric-based applications.
Continual Learning with Tiny Episodic Memories
Mar 20, 2019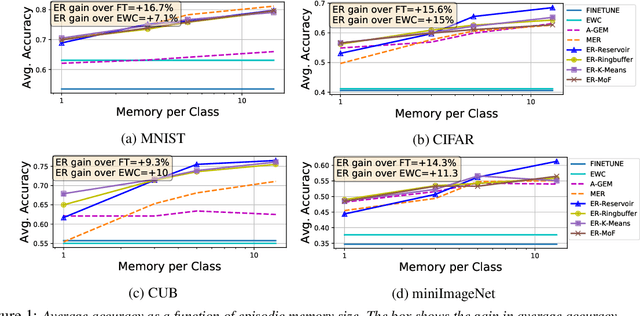
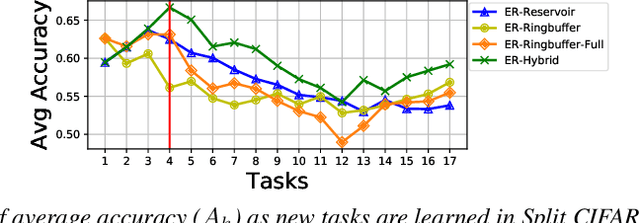

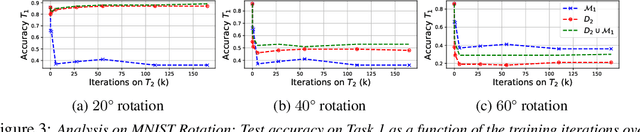
Learning with less supervision is a major challenge in artificial intelligence. One sensible approach to decrease the amount of supervision is to leverage prior experience and transfer knowledge from tasks seen in the past. However, a necessary condition for a successful transfer is the ability to remember how to perform previous tasks. The Continual Learning (CL) setting, whereby an agent learns from a stream of tasks without seeing any example twice, is an ideal framework to investigate how to accrue such knowledge. In this work, we consider supervised learning tasks and methods that leverage a very small episodic memory for continual learning. Through an extensive empirical analysis across four benchmark datasets adapted to CL, we observe that a very simple baseline, which jointly trains on both examples from the current task as well as examples stored in the memory, outperforms state-of-the-art CL approaches with and without episodic memory. Surprisingly, repeated learning over tiny episodic memories does not harm generalization on past tasks, as joint training on data from subsequent tasks acts like a data dependent regularizer. We discuss and evaluate different approaches to write into the memory. Most notably, reservoir sampling works remarkably well across the board, except when the memory size is extremely small. In this case, writing strategies that guarantee an equal representation of all classes work better. Overall, these methods should be considered as a strong baseline candidate when benchmarking new CL approaches
The StarCraft Multi-Agent Challenge
Feb 26, 2019
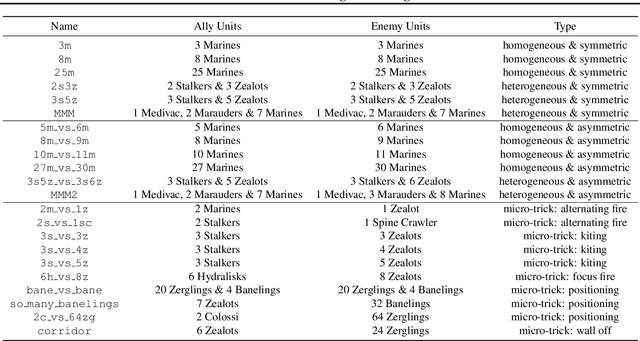

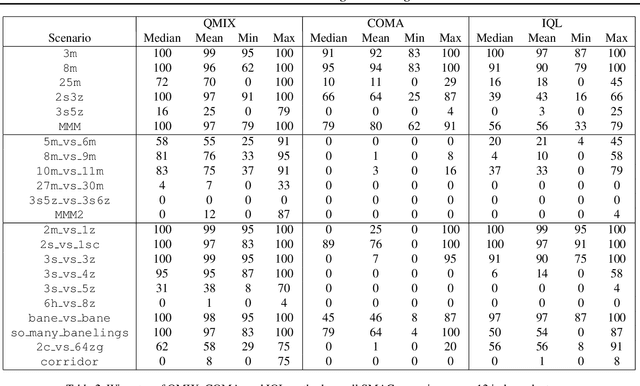
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: https://youtu.be/VZ7zmQ_obZ0.
Domain Partitioning Network
Feb 21, 2019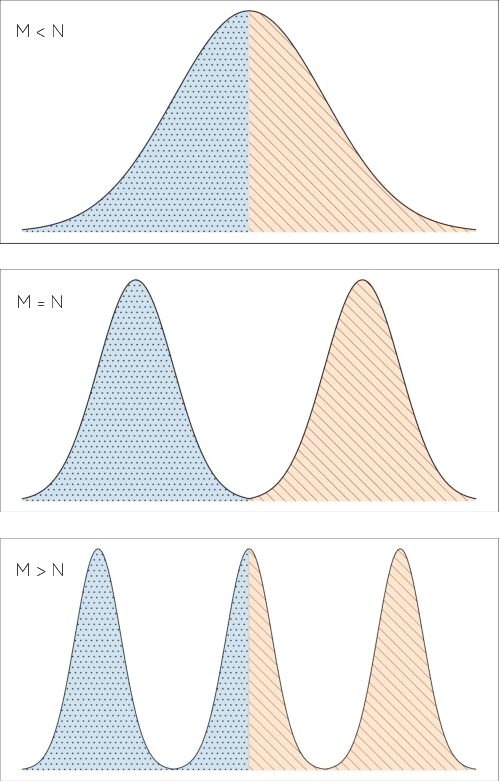
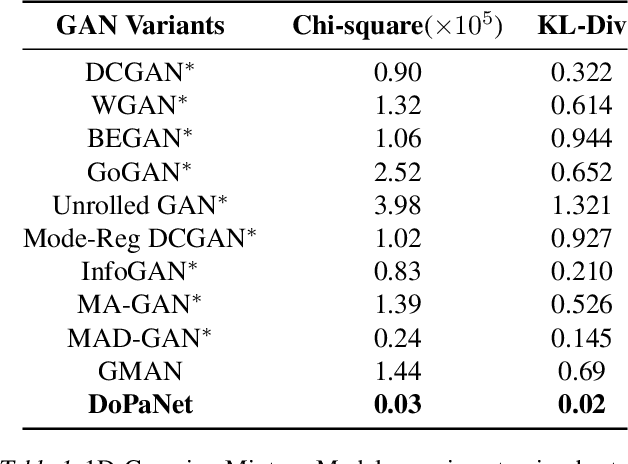
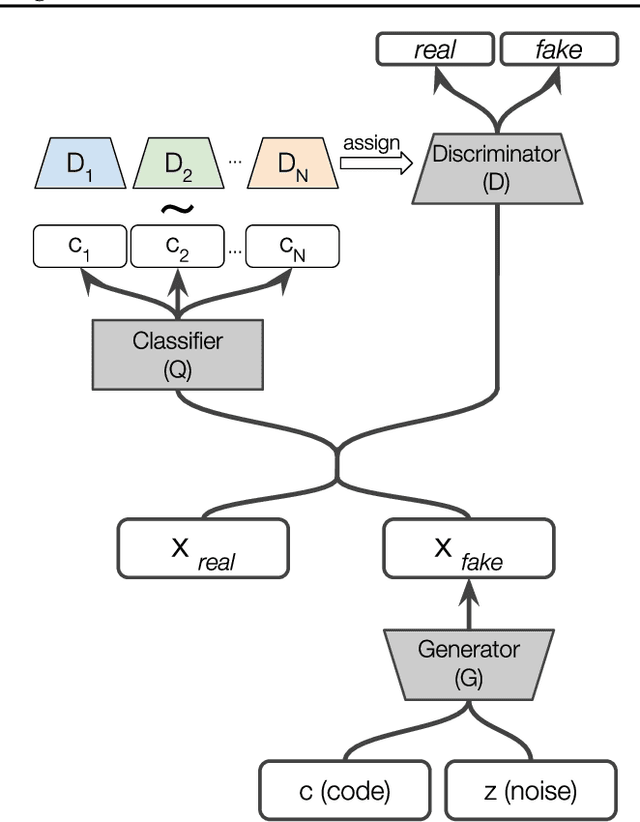
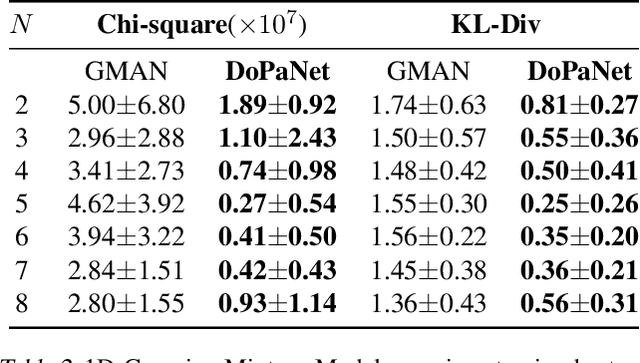
Standard adversarial training involves two agents, namely a generator and a discriminator, playing a mini-max game. However, even if the players converge to an equilibrium, the generator may only recover a part of the target data distribution, in a situation commonly referred to as mode collapse. In this work, we present the Domain Partitioning Network (DoPaNet), a new approach to deal with mode collapse in generative adversarial learning. We employ multiple discriminators, each encouraging the generator to cover a different part of the target distribution. To ensure these parts do not overlap and collapse into the same mode, we add a classifier as a third agent in the game. The classifier decides which discriminator the generator is trained against for each sample. Through experiments on toy examples and real images, we show the merits of DoPaNet in covering the real distribution and its superiority with respect to the competing methods. Besides, we also show that we can control the modes from which samples are generated using DoPaNet.
3D Hand Shape and Pose from Images in the Wild
Feb 09, 2019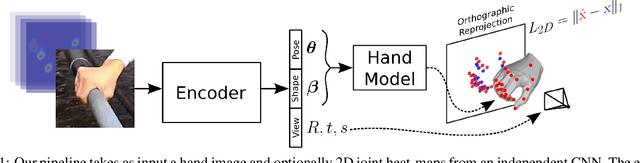


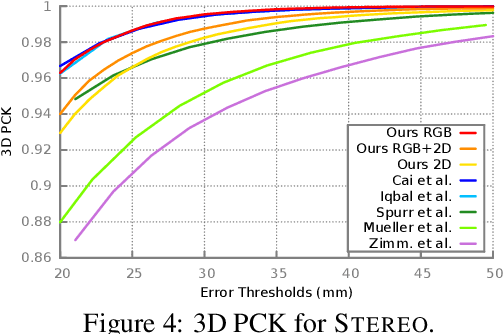
We present in this work the first end-to-end deep learning based method that predicts both 3D hand shape and pose from RGB images in the wild. Our network consists of the concatenation of a deep convolutional encoder, and a fixed model-based decoder. Given an input image, and optionally 2D joint detections obtained from an independent CNN, the encoder predicts a set of hand and view parameters. The decoder has two components: A pre-computed articulated mesh deformation hand model that generates a 3D mesh from the hand parameters, and a re-projection module controlled by the view parameters that projects the generated hand into the image domain. We show that using the shape and pose prior knowledge encoded in the hand model within a deep learning framework yields state-of-the-art performance in 3D pose prediction from images on standard benchmarks, and produces geometrically valid and plausible 3D reconstructions. Additionally, we show that training with weak supervision in the form of 2D joint annotations on datasets of images in the wild, in conjunction with full supervision in the form of 3D joint annotations on limited available datasets allows for good generalization to 3D shape and pose predictions on images in the wild.
Hypergraph Convolution and Hypergraph Attention
Jan 23, 2019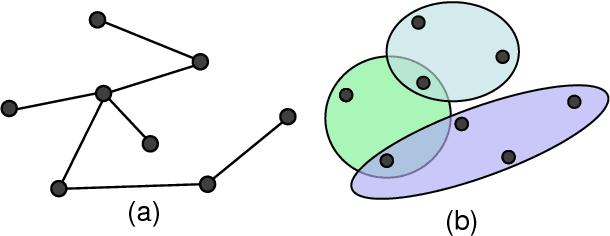
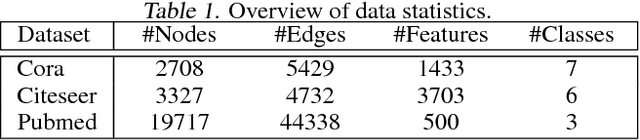
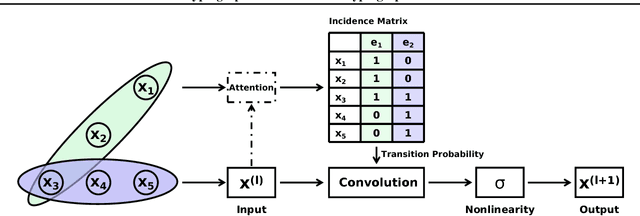
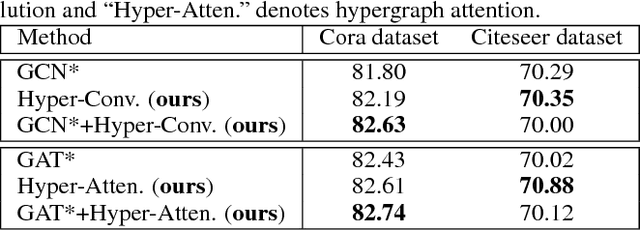
Recently, graph neural networks have attracted great attention and achieved prominent performance in various research fields. Most of those algorithms have assumed pairwise relationships of objects of interest. However, in many real applications, the relationships between objects are in higher-order, beyond a pairwise formulation. To efficiently learn deep embeddings on the high-order graph-structured data, we introduce two end-to-end trainable operators to the family of graph neural networks, i.e., hypergraph convolution and hypergraph attention. Whilst hypergraph convolution defines the basic formulation of performing convolution on a hypergraph, hypergraph attention further enhances the capacity of representation learning by leveraging an attention module. With the two operators, a graph neural network is readily extended to a more flexible model and applied to diverse applications where non-pairwise relationships are observed. Extensive experimental results with semi-supervised node classification demonstrate the effectiveness of hypergraph convolution and hypergraph attention.