 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models as a Complex Systems Science: How can we make sense of large language model behavior?
Jul 31, 2023Coaxing out desired behavior from pretrained models, while avoiding undesirable ones, has redefined NLP and is reshaping how we interact with computers. What was once a scientific engineering discipline-in which building blocks are stacked one on top of the other-is arguably already a complex systems science, in which emergent behaviors are sought out to support previously unimagined use cases. Despite the ever increasing number of benchmarks that measure task performance, we lack explanations of what behaviors language models exhibit that allow them to complete these tasks in the first place. We argue for a systematic effort to decompose language model behavior into categories that explain cross-task performance, to guide mechanistic explanations and help future-proof analytic research.
Minding Language Models' Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker
Jun 01, 2023Theory of Mind (ToM)$\unicode{x2014}$the ability to reason about the mental states of other people$\unicode{x2014}$is a key element of our social intelligence. Yet, despite their ever more impressive performance, large-scale neural language models still lack basic theory of mind capabilities out-of-the-box. We posit that simply scaling up models will not imbue them with theory of mind due to the inherently symbolic and implicit nature of the phenomenon, and instead investigate an alternative: can we design a decoding-time algorithm that enhances theory of mind of off-the-shelf neural language models without explicit supervision? We present SymbolicToM, a plug-and-play approach to reason about the belief states of multiple characters in reading comprehension tasks via explicit symbolic representation. More concretely, our approach tracks each entity's beliefs, their estimation of other entities' beliefs, and higher-order levels of reasoning, all through graphical representations, allowing for more precise and interpretable reasoning than previous approaches. Empirical results on the well-known ToMi benchmark (Le et al., 2019) demonstrate that SymbolicToM dramatically enhances off-the-shelf neural networks' theory of mind in a zero-shot setting while showing robust out-of-distribution performance compared to supervised baselines. Our work also reveals spurious patterns in existing theory of mind benchmarks, emphasizing the importance of out-of-distribution evaluation and methods that do not overfit a particular dataset.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.
Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing
May 26, 2023



It is commonly perceived that the strongest language models (LMs) rely on a combination of massive scale, instruction data, and human feedback to perform specialized tasks -- e.g. summarization and paraphrasing, without supervision. In this paper, we propose that language models can learn to summarize and paraphrase sentences, with none of these 3 factors. We present Impossible Distillation, a framework that distills a task-specific dataset directly from an off-the-shelf LM, even when it is impossible for the LM itself to reliably solve the task. By training a student model on the generated dataset and amplifying its capability through self-distillation, our method yields a high-quality model and dataset from a low-quality teacher model, without the need for scale or supervision. Using Impossible Distillation, we are able to distill an order of magnitude smaller model (with only 770M parameters) that outperforms 175B parameter GPT-3, in both quality and controllability, as confirmed by automatic and human evaluations. Furthermore, as a useful byproduct of our approach, we obtain DIMSUM+, a high-quality dataset with 3.4M sentence summaries and paraphrases. Our analyses show that this dataset, as a purely LM-generated corpus, is more diverse and more effective for generalization to unseen domains than all human-authored datasets -- including Gigaword with 4M samples.
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning
May 24, 2023Large language models excel at a variety of language tasks when prompted with examples or instructions. Yet controlling these models through prompting alone is limited. Tailoring language models through fine-tuning (e.g., via reinforcement learning) can be effective, but it is expensive and requires model access. We propose Inference-time Policy Adapters (IPA), which efficiently tailors a language model such as GPT-3 without fine-tuning it. IPA guides a large base model during decoding time through a lightweight policy adaptor trained to optimize an arbitrary user objective with reinforcement learning. On five challenging text generation tasks, such as toxicity reduction and open-domain generation, IPA consistently brings significant improvements over off-the-shelf language models. It outperforms competitive baseline methods, sometimes even including expensive fine-tuning. In particular, tailoring GPT-2 with IPA can outperform GPT-3, while tailoring GPT- 3 with IPA brings a major performance boost over GPT-3 (and sometimes even over GPT-4). Our promising results highlight the potential of IPA as a lightweight alternative to tailoring extreme-scale language models.
We're Afraid Language Models Aren't Modeling Ambiguity
Apr 27, 2023Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our interpretations as listeners. As language models (LMs) are increasingly employed as dialogue interfaces and writing aids, handling ambiguous language is critical to their success. We characterize ambiguity in a sentence by its effect on entailment relations with another sentence, and collect AmbiEnt, a linguist-annotated benchmark of 1,645 examples with diverse kinds of ambiguity. We design a suite of tests based on AmbiEnt, presenting the first evaluation of pretrained LMs to recognize ambiguity and disentangle possible meanings. We find that the task remains extremely challenging, including for the recent GPT-4, whose generated disambiguations are considered correct only 32% of the time in human evaluation, compared to 90% for disambiguations in our dataset. Finally, to illustrate the value of ambiguity-sensitive tools, we show that a multilabel NLI model can flag political claims in the wild that are misleading due to ambiguity. We encourage the field to rediscover the importance of ambiguity for NLP.
I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Dec 19, 2022Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.
Generating Sequences by Learning to Self-Correct
Oct 31, 2022Sequence generation applications require satisfying semantic constraints, such as ensuring that programs are correct, using certain keywords, or avoiding undesirable content. Language models, whether fine-tuned or prompted with few-shot demonstrations, frequently violate these constraints, and lack a mechanism to iteratively revise their outputs. Moreover, some powerful language models are of extreme scale or inaccessible, making it inefficient, if not infeasible, to update their parameters for task-specific adaptation. We present Self-Correction, an approach that decouples an imperfect base generator (an off-the-shelf language model or supervised sequence-to-sequence model) from a separate corrector that learns to iteratively correct imperfect generations. To train the corrector, we propose an online training procedure that can use either scalar or natural language feedback on intermediate imperfect generations. We show that Self-Correction improves upon the base generator in three diverse generation tasks - mathematical program synthesis, lexically-constrained generation, and toxicity control - even when the corrector is much smaller than the base generator.
Referee: Reference-Free Sentence Summarization with Sharper Controllability through Symbolic Knowledge Distillation
Oct 25, 2022We present Referee, a novel framework for sentence summarization that can be trained reference-free (i.e., requiring no gold summaries for supervision), while allowing direct control for compression ratio. Our work is the first to demonstrate that reference-free, controlled sentence summarization is feasible via the conceptual framework of Symbolic Knowledge Distillation (West et al., 2022), where latent knowledge in pre-trained language models is distilled via explicit examples sampled from the teacher models, further purified with three types of filters: length, fidelity, and Information Bottleneck. Moreover, we uniquely propose iterative distillation of knowledge, where student models from the previous iteration of distillation serve as teacher models in the next iteration. Starting off from a relatively modest set of GPT3-generated summaries, we demonstrate how iterative knowledge distillation can lead to considerably smaller, but better summarizers with sharper controllability. A useful by-product of this iterative distillation process is a high-quality dataset of sentence-summary pairs with varying degrees of compression ratios. Empirical results demonstrate that the final student models vastly outperform the much larger GPT3-Instruct model in terms of the controllability of compression ratios, without compromising the quality of resulting summarization.
Quark: Controllable Text Generation with Reinforced Unlearning
May 26, 2022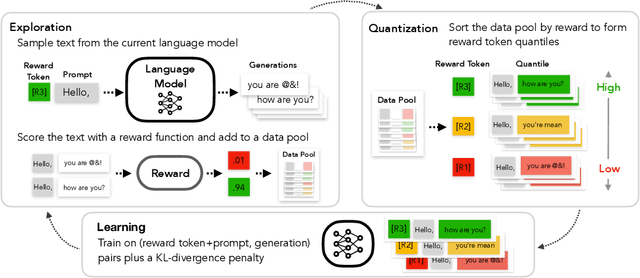
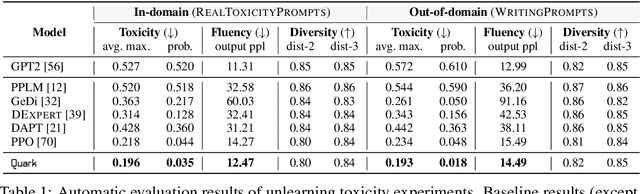
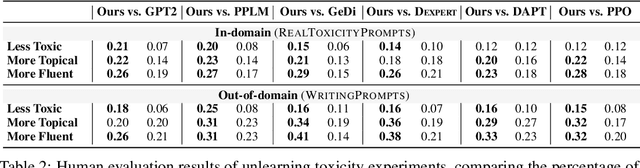

Large-scale language models often learn behaviors that are misaligned with user expectations. Generated text may contain offensive or toxic language, contain significant repetition, or be of a different sentiment than desired by the user. We consider the task of unlearning these misalignments by fine-tuning the language model on signals of what not to do. We introduce Quantized Reward Konditioning (Quark), an algorithm for optimizing a reward function that quantifies an (un)wanted property, while not straying too far from the original model. Quark alternates between (i) collecting samples with the current language model, (ii) sorting them into quantiles based on reward, with each quantile identified by a reward token prepended to the language model's input, and (iii) using a standard language modeling loss on samples from each quantile conditioned on its reward token, while remaining nearby the original language model via a KL-divergence penalty. By conditioning on a high-reward token at generation time, the model generates text that exhibits less of the unwanted property. For unlearning toxicity, negative sentiment, and repetition, our experiments show that Quark outperforms both strong baselines and state-of-the-art reinforcement learning methods like PPO (Schulman et al. 2017), while relying only on standard language modeling primitives.