 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Reduced Methods for Machine Learning
Oct 02, 2020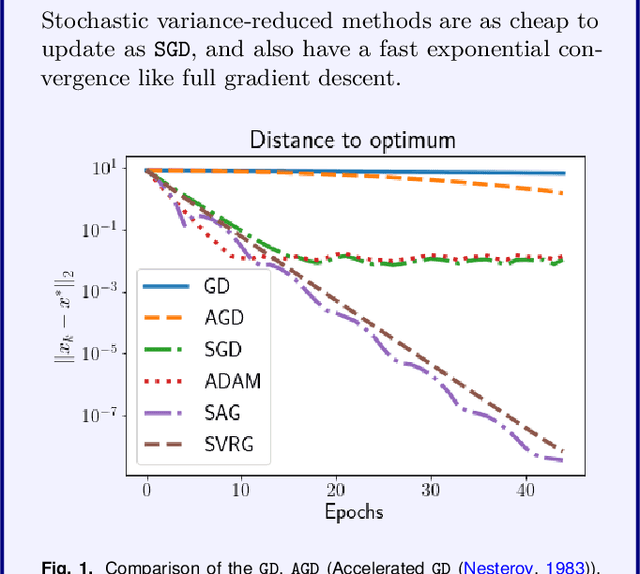
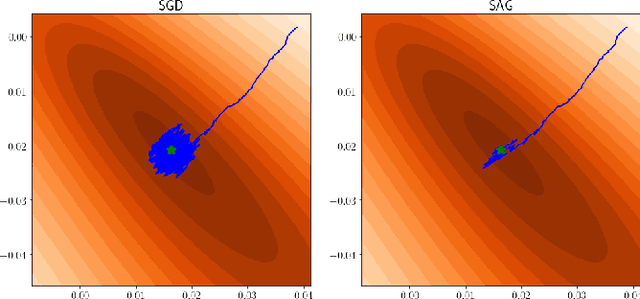

Stochastic optimization lies at the heart of machine learning, and its cornerstone is stochastic gradient descent (SGD), a method introduced over 60 years ago. The last 8 years have seen an exciting new development: variance reduction (VR) for stochastic optimization methods. These VR methods excel in settings where more than one pass through the training data is allowed, achieving a faster convergence than SGD in theory as well as practice. These speedups underline the surge of interest in VR methods and the fast-growing body of work on this topic. This review covers the key principles and main developments behind VR methods for optimization with finite data sets and is aimed at non-expert readers. We focus mainly on the convex setting, and leave pointers to readers interested in extensions for minimizing non-convex functions.
Adaptive Learning of the Optimal Mini-Batch Size of SGD
May 03, 2020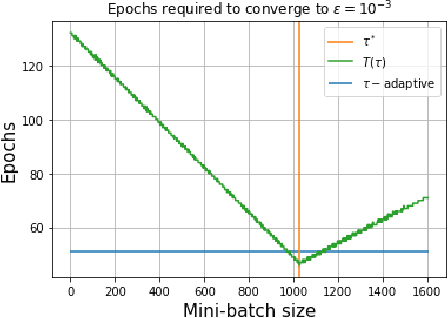
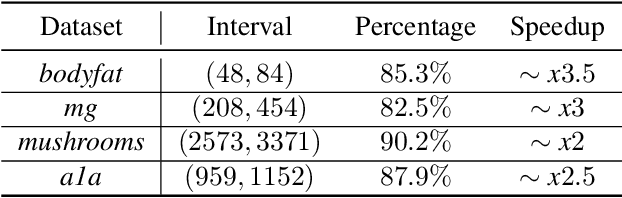
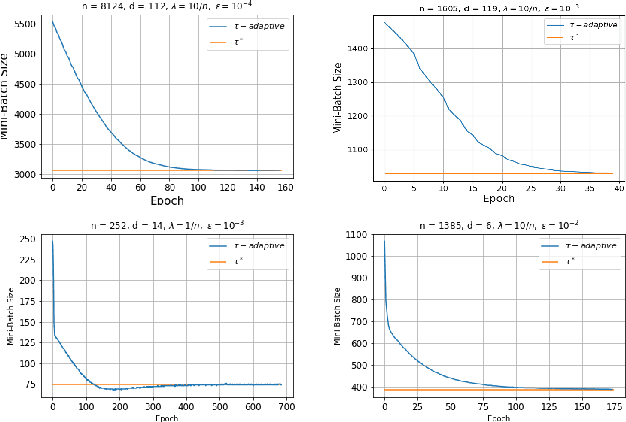
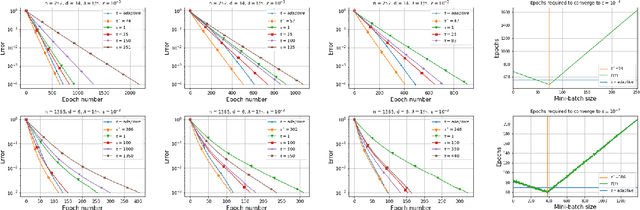
Recent advances in the theoretical understandingof SGD (Qian et al., 2019) led to a formula for the optimal mini-batch size minimizing the number of effective data passes, i.e., the number of iterations times the mini-batch size. However, this formula is of no practical value as it depends on the knowledge of the variance of the stochastic gradients evaluated at the optimum. In this paper we design a practical SGD method capable of learning the optimal mini-batch size adaptively throughout its iterations. Our method does this provably, and in our experiments with synthetic and real data robustly exhibits nearly optimal behaviour; that is, it works as if the optimal mini-batch size was known a-priori. Further, we generalize our method to several new mini-batch strategies not considered in the literature before, including a sampling suitable for distributed implementations.
Dualize, Split, Randomize: Fast Nonsmooth Optimization Algorithms
Apr 03, 2020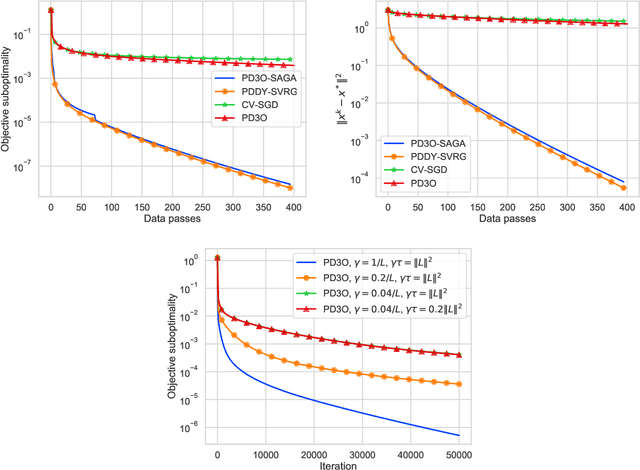
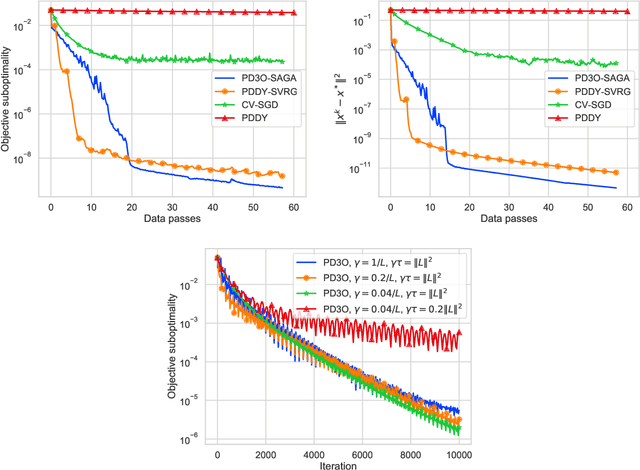
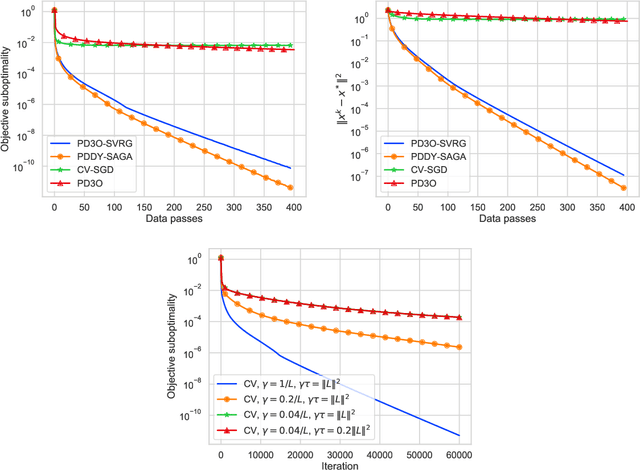
We introduce a new primal-dual algorithm for minimizing the sum of three convex functions, each of which has its own oracle. Namely, the first one is differentiable, smooth and possibly stochastic, the second is proximable, and the last one is a composition of a proximable function with a linear map. Our theory covers several settings that are not tackled by any existing algorithm; we illustrate their importance with real-world applications. By leveraging variance reduction, we obtain convergence with linear rates under strong convexity and fast sublinear convergence under convexity assumptions. The proposed theory is simple and unified by the umbrella of stochastic Davis-Yin splitting, which we design in this work. Finally, we illustrate the efficiency of our method through numerical experiments.
From Local SGD to Local Fixed Point Methods for Federated Learning
Apr 03, 2020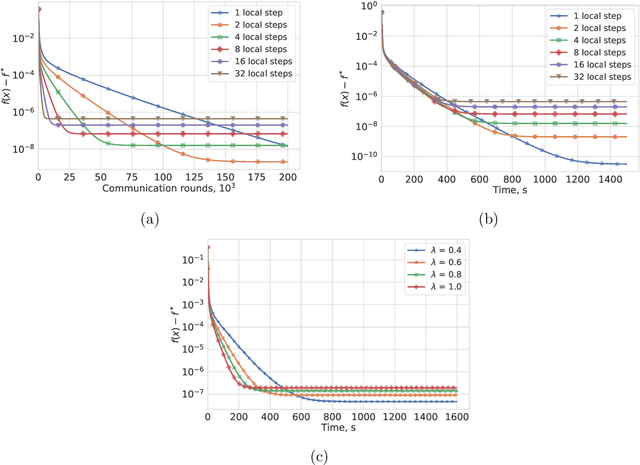
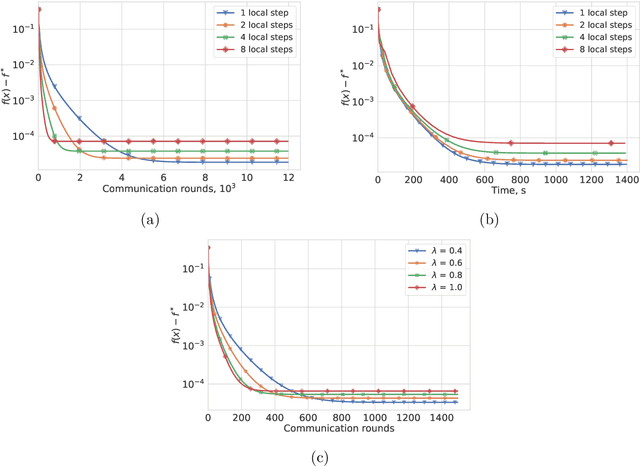
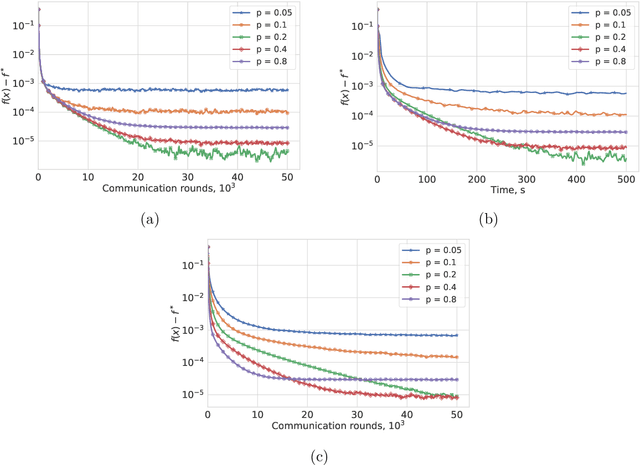
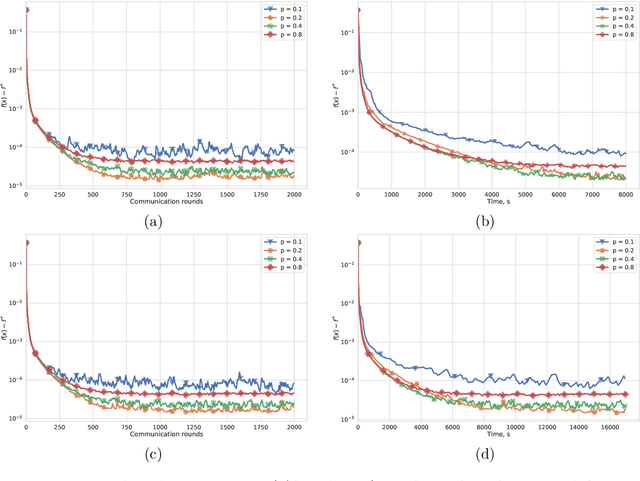
Most algorithms for solving optimization problems or finding saddle points of convex-concave functions are fixed point algorithms. In this work we consider the generic problem of finding a fixed point of an average of operators, or an approximation thereof, in a distributed setting. Our work is motivated by the needs of federated learning. In this context, each local operator models the computations done locally on a mobile device. We investigate two strategies to achieve such a consensus: one based on a fixed number of local steps, and the other based on randomized computations. In both cases, the goal is to limit communication of the locally-computed variables, which is often the bottleneck in distributed frameworks. We perform convergence analysis of both methods and conduct a number of experiments highlighting the benefits of our approach.
Variance Reduced Coordinate Descent with Acceleration: New Method With a Surprising Application to Finite-Sum Problems
Feb 11, 2020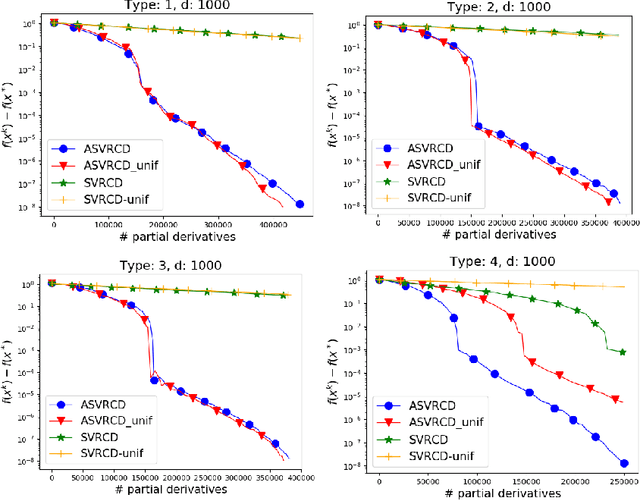

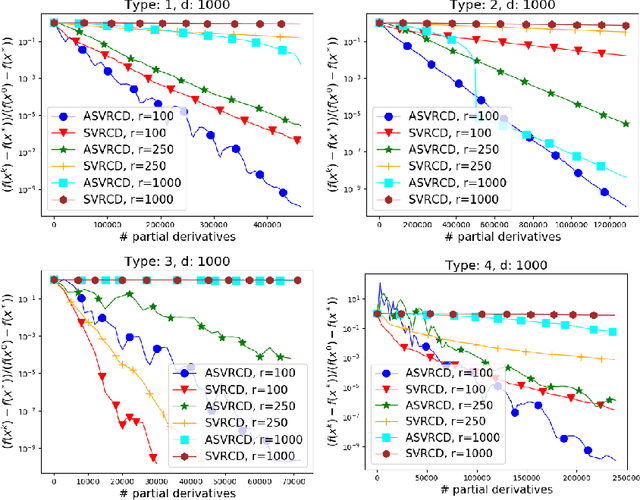
We propose an accelerated version of stochastic variance reduced coordinate descent -- ASVRCD. As other variance reduced coordinate descent methods such as SEGA or SVRCD, our method can deal with problems that include a non-separable and non-smooth regularizer, while accessing a random block of partial derivatives in each iteration only. However, ASVRCD incorporates Nesterov's momentum, which offers favorable iteration complexity guarantees over both SEGA and SVRCD. As a by-product of our theory, we show that a variant of Allen-Zhu (2017) is a specific case of ASVRCD, recovering the optimal oracle complexity for the finite sum objective.
Natural Compression for Distributed Deep Learning
May 27, 2019



Due to their hunger for big data, modern deep learning models are trained in parallel, often in distributed environments, where communication of model updates is the bottleneck. Various update compression (e.g., quantization, sparsification, dithering) techniques have been proposed in recent years as a successful tool to alleviate this problem. In this work, we introduce a new, remarkably simple and theoretically and practically effective compression technique, which we call natural compression (NC). Our technique is applied individually to all entries of the to-be-compressed update vector and works by randomized rounding to the nearest (negative or positive) power of two. NC is "natural" since the nearest power of two of a real expressed as a float can be obtained without any computation, simply by ignoring the mantissa. We show that compared to no compression, NC increases the second moment of the compressed vector by the tiny factor 9/8 only, which means that the effect of NC on the convergence speed of popular training algorithms, such as distributed SGD, is negligible. However, the communications savings enabled by NC are substantial, leading to 3-4x improvement in overall theoretical running time. For applications requiring more aggressive compression, we generalize NC to natural dithering, which we prove is exponentially better than the immensely popular random dithering technique. Our compression operators can be used on their own or in combination with existing operators for a more aggressive combined effect. Finally, we show that N is particularly effective for the in-network aggregation (INA) framework for distributed training, where the update aggregation is done on a switch, which can only perform integer computations.
SGD: General Analysis and Improved Rates
Jan 27, 2019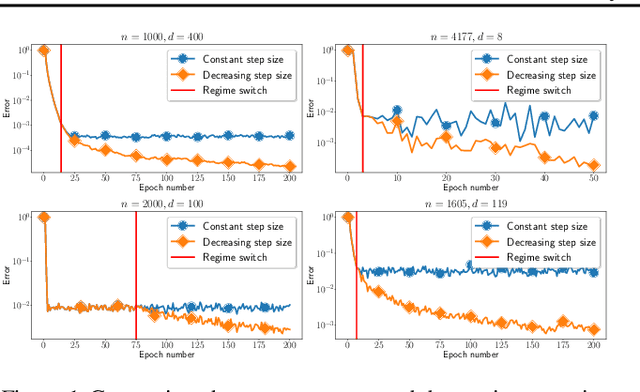
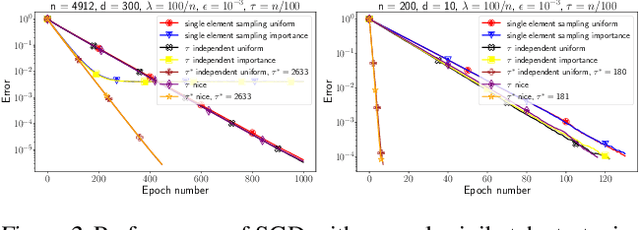
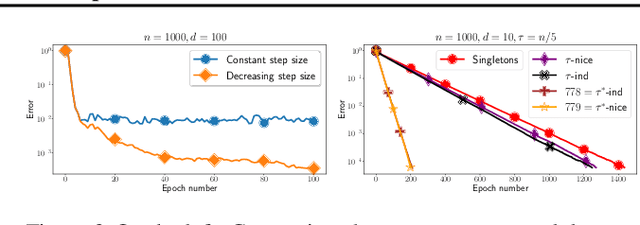
We propose a general yet simple theorem describing the convergence of SGD under the arbitrary sampling paradigm. Our theorem describes the convergence of an infinite array of variants of SGD, each of which is associated with a specific probability law governing the data selection rule used to form mini-batches. This is the first time such an analysis is performed, and most of our variants of SGD were never explicitly considered in the literature before. Our analysis relies on the recently introduced notion of expected smoothness and does not rely on a uniform bound on the variance of the stochastic gradients. By specializing our theorem to different mini-batching strategies, such as sampling with replacement and independent sampling, we derive exact expressions for the stepsize as a function of the mini-batch size. With this we can also determine the mini-batch size that optimizes the total complexity, and show explicitly that as the variance of the stochastic gradient evaluated at the minimum grows, so does the optimal mini-batch size. For zero variance, the optimal mini-batch size is one. Moreover, we prove insightful stepsize-switching rules which describe when one should switch from a constant to a decreasing stepsize regime.
Don't Jump Through Hoops and Remove Those Loops: SVRG and Katyusha are Better Without the Outer Loop
Jan 24, 2019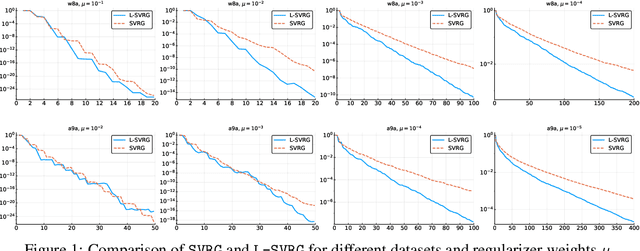
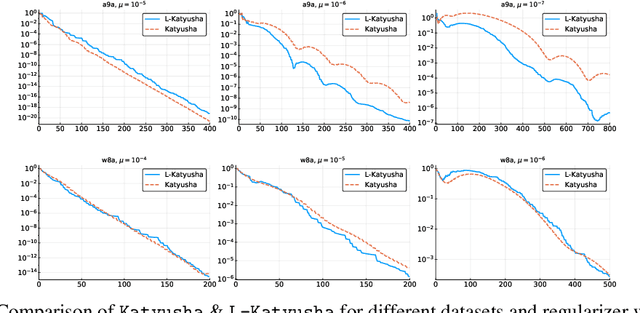
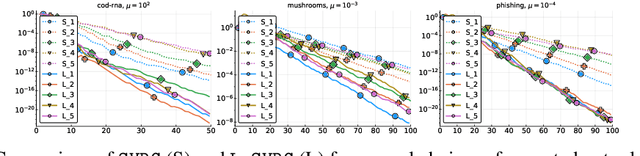
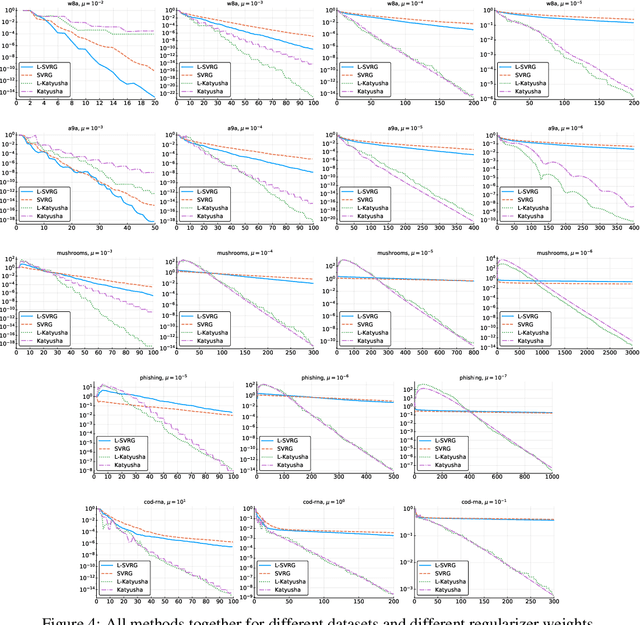
The stochastic variance-reduced gradient method (SVRG) and its accelerated variant (Katyusha) have attracted enormous attention in the machine learning community in the last few years due to their superior theoretical properties and empirical behaviour on training supervised machine learning models via the empirical risk minimization paradigm. A key structural element in both of these methods is the inclusion of an outer loop at the beginning of which a full pass over the training data is made in order to compute the exact gradient, which is then used to construct a variance-reduced estimator of the gradient. In this work we design {\em loopless variants} of both of these methods. In particular, we remove the outer loop and replace its function by a coin flip performed in each iteration designed to trigger, with a small probability, the computation of the gradient. We prove that the new methods enjoy the same superior theoretical convergence properties as the original methods. However, we demonstrate through numerical experiments that our methods have substantially superior practical behavior.
SEGA: Variance Reduction via Gradient Sketching
Oct 18, 2018

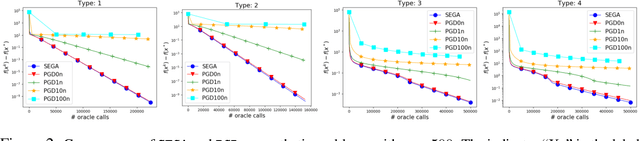
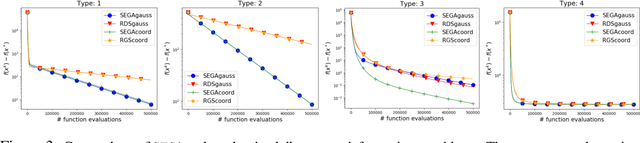
We propose a randomized first order optimization method--SEGA (SkEtched GrAdient method)-- which progressively throughout its iterations builds a variance-reduced estimate of the gradient from random linear measurements (sketches) of the gradient obtained from an oracle. In each iteration, SEGA updates the current estimate of the gradient through a sketch-and-project operation using the information provided by the latest sketch, and this is subsequently used to compute an unbiased estimate of the true gradient through a random relaxation procedure. This unbiased estimate is then used to perform a gradient step. Unlike standard subspace descent methods, such as coordinate descent, SEGA can be used for optimization problems with a non-separable proximal term. We provide a general convergence analysis and prove linear convergence for strongly convex objectives. In the special case of coordinate sketches, SEGA can be enhanced with various techniques such as importance sampling, minibatching and acceleration, and its rate is up to a small constant factor identical to the best-known rate of coordinate descent.
Weighted Low-Rank Approximation of Matrices and Background Modeling
Apr 15, 2018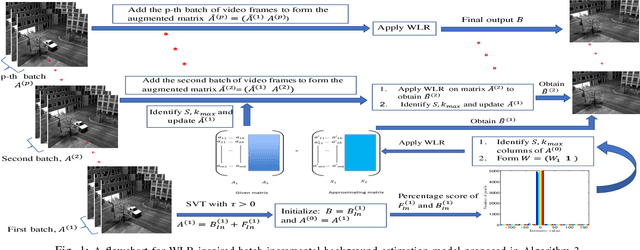



We primarily study a special a weighted low-rank approximation of matrices and then apply it to solve the background modeling problem. We propose two algorithms for this purpose: one operates in the batch mode on the entire data and the other one operates in the batch-incremental mode on the data and naturally captures more background variations and computationally more effective. Moreover, we propose a robust technique that learns the background frame indices from the data and does not require any training frames. We demonstrate through extensive experiments that by inserting a simple weight in the Frobenius norm, it can be made robust to the outliers similar to the $\ell_1$ norm. Our methods match or outperform several state-of-the-art online and batch background modeling methods in virtually all quantitative and qualitative measures.