 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Nov 03, 2020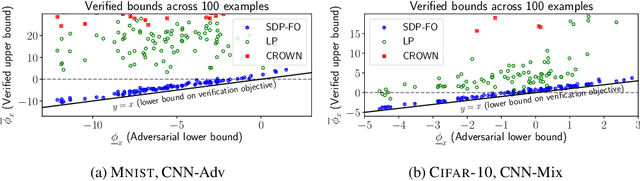
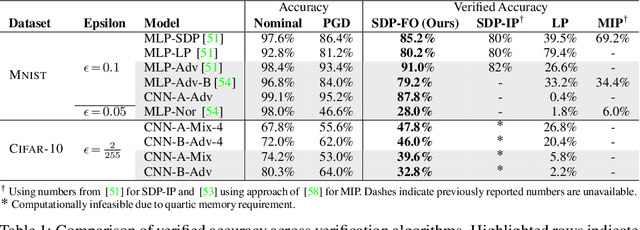
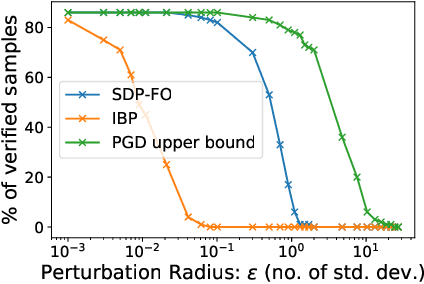

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Selective Classification Can Magnify Disparities Across Groups
Oct 27, 2020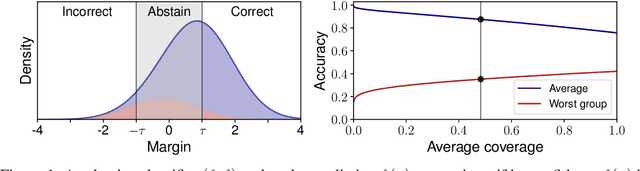

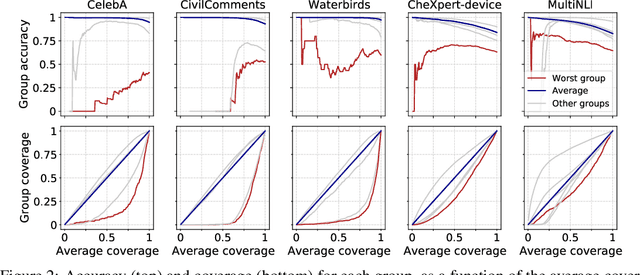
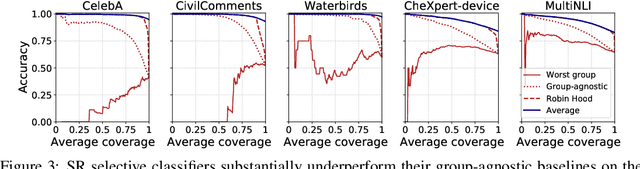
Selective classification, in which models are allowed to abstain on uncertain predictions, is a natural approach to improving accuracy in settings where errors are costly but abstentions are manageable. In this paper, we find that while selective classification can improve average accuracies, it can simultaneously magnify existing accuracy disparities between various groups within a population, especially in the presence of spurious correlations. We observe this behavior consistently across five datasets from computer vision and NLP. Surprisingly, increasing the abstention rate can even decrease accuracies on some groups. To better understand when selective classification improves or worsens accuracy on a group, we study its margin distribution, which captures the model's confidences over all predictions. For example, when the margin distribution is symmetric, we prove that whether selective classification monotonically improves or worsens accuracy is fully determined by the accuracy at full coverage (i.e., without any abstentions) and whether the distribution satisfies a property we term left-log-concavity. Our analysis also shows that selective classification tends to magnify accuracy disparities that are present at full coverage. Fortunately, we find that it uniformly improves each group when applied to distributionally-robust models that achieve similar full-coverage accuracies across groups. Altogether, our results imply selective classification should be used with care and underscore the importance of models that perform equally well across groups at full coverage.
RNNs can generate bounded hierarchical languages with optimal memory
Oct 15, 2020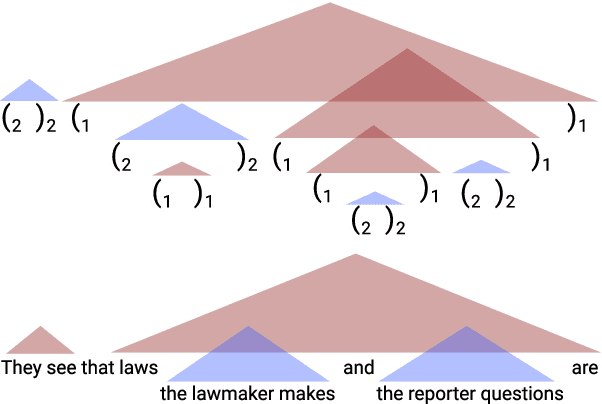
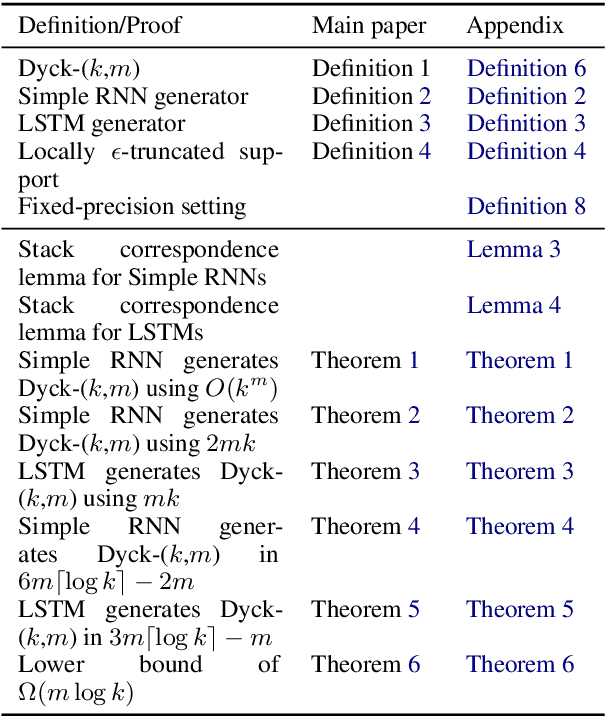
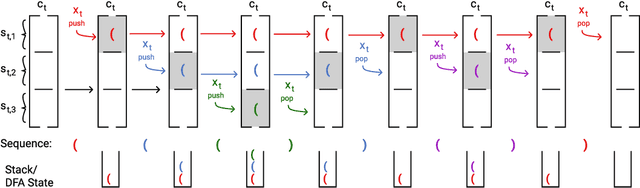
Recurrent neural networks empirically generate natural language with high syntactic fidelity. However, their success is not well-understood theoretically. We provide theoretical insight into this success, proving in a finite-precision setting that RNNs can efficiently generate bounded hierarchical languages that reflect the scaffolding of natural language syntax. We introduce Dyck-($k$,$m$), the language of well-nested brackets (of $k$ types) and $m$-bounded nesting depth, reflecting the bounded memory needs and long-distance dependencies of natural language syntax. The best known results use $O(k^{\frac{m}{2}})$ memory (hidden units) to generate these languages. We prove that an RNN with $O(m \log k)$ hidden units suffices, an exponential reduction in memory, by an explicit construction. Finally, we show that no algorithm, even with unbounded computation, can suffice with $o(m \log k)$ hidden units.
The EOS Decision and Length Extrapolation
Oct 14, 2020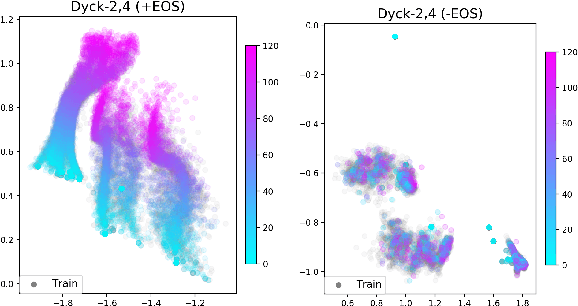

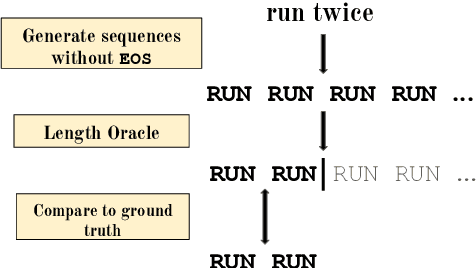

Extrapolation to unseen sequence lengths is a challenge for neural generative models of language. In this work, we characterize the effect on length extrapolation of a modeling decision often overlooked: predicting the end of the generative process through the use of a special end-of-sequence (EOS) vocabulary item. We study an oracle setting - forcing models to generate to the correct sequence length at test time - to compare the length-extrapolative behavior of networks trained to predict EOS (+EOS) with networks not trained to (-EOS). We find that -EOS substantially outperforms +EOS, for example extrapolating well to lengths 10 times longer than those seen at training time in a bracket closing task, as well as achieving a 40% improvement over +EOS in the difficult SCAN dataset length generalization task. By comparing the hidden states and dynamics of -EOS and +EOS models, we observe that +EOS models fail to generalize because they (1) unnecessarily stratify their hidden states by their linear position is a sequence (structures we call length manifolds) or (2) get stuck in clusters (which we refer to as length attractors) once the EOS token is the highest-probability prediction.
Learning Adaptive Language Interfaces through Decomposition
Oct 11, 2020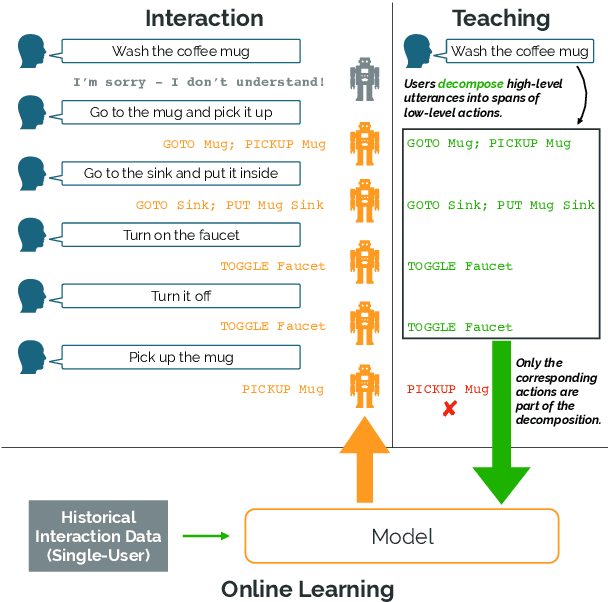

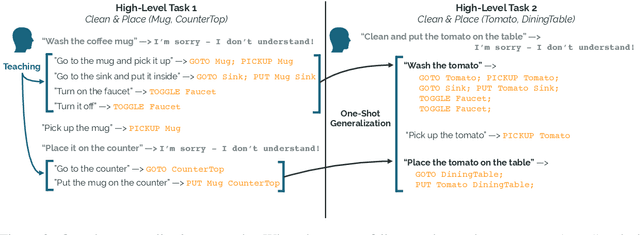
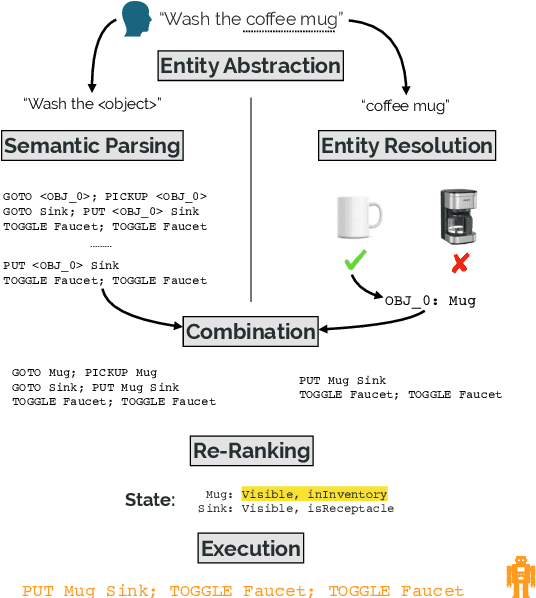
Our goal is to create an interactive natural language interface that efficiently and reliably learns from users to complete tasks in simulated robotics settings. We introduce a neural semantic parsing system that learns new high-level abstractions through decomposition: users interactively teach the system by breaking down high-level utterances describing novel behavior into low-level steps that it can understand. Unfortunately, existing methods either rely on grammars which parse sentences with limited flexibility, or neural sequence-to-sequence models that do not learn efficiently or reliably from individual examples. Our approach bridges this gap, demonstrating the flexibility of modern neural systems, as well as the one-shot reliable generalization of grammar-based methods. Our crowdsourced interactive experiments suggest that over time, users complete complex tasks more efficiently while using our system by leveraging what they just taught. At the same time, getting users to trust the system enough to be incentivized to teach high-level utterances is still an ongoing challenge. We end with a discussion of some of the obstacles we need to overcome to fully realize the potential of the interactive paradigm.
On the Importance of Adaptive Data Collection for Extremely Imbalanced Pairwise Tasks
Oct 10, 2020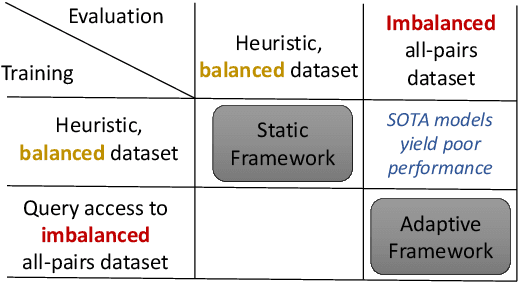
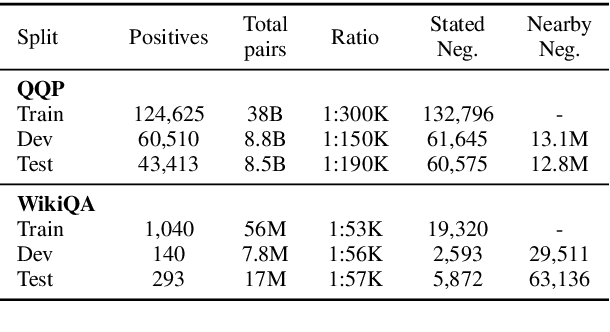
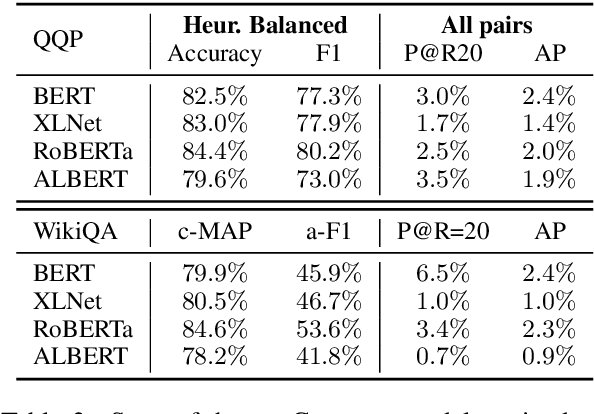
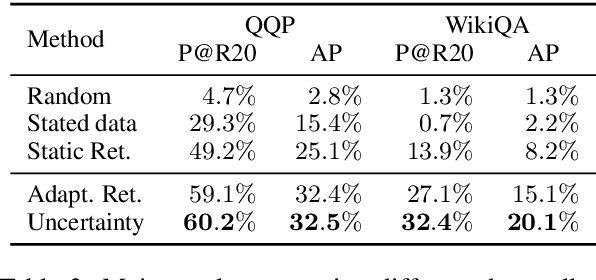
Many pairwise classification tasks, such as paraphrase detection and open-domain question answering, naturally have extreme label imbalance (e.g., $99.99\%$ of examples are negatives). In contrast, many recent datasets heuristically choose examples to ensure label balance. We show that these heuristics lead to trained models that generalize poorly: State-of-the art models trained on QQP and WikiQA each have only $2.4\%$ average precision when evaluated on realistically imbalanced test data. We instead collect training data with active learning, using a BERT-based embedding model to efficiently retrieve uncertain points from a very large pool of unlabeled utterance pairs. By creating balanced training data with more informative negative examples, active learning greatly improves average precision to $32.5\%$ on QQP and $20.1\%$ on WikiQA.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
Robustness to Spurious Correlations via Human Annotations
Aug 13, 2020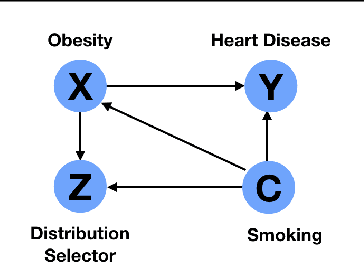
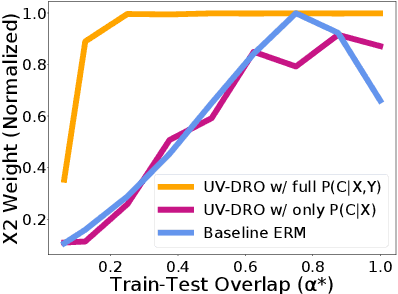
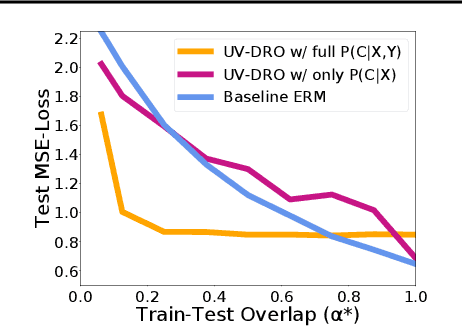
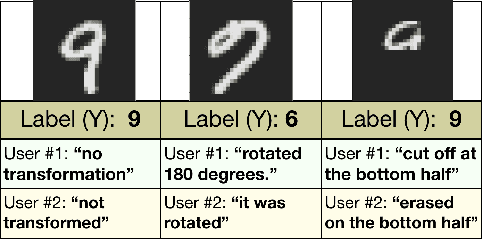
The reliability of machine learning systems critically assumes that the associations between features and labels remain similar between training and test distributions. However, unmeasured variables, such as confounders, break this assumption---useful correlations between features and labels at training time can become useless or even harmful at test time. For example, high obesity is generally predictive for heart disease, but this relation may not hold for smokers who generally have lower rates of obesity and higher rates of heart disease. We present a framework for making models robust to spurious correlations by leveraging humans' common sense knowledge of causality. Specifically, we use human annotation to augment each training example with a potential unmeasured variable (i.e. an underweight patient with heart disease may be a smoker), reducing the problem to a covariate shift problem. We then introduce a new distributionally robust optimization objective over unmeasured variables (UV-DRO) to control the worst-case loss over possible test-time shifts. Empirically, we show improvements of 5-10% on a digit recognition task confounded by rotation, and 1.5-5% on the task of analyzing NYPD Police Stops confounded by location.
Explore then Execute: Adapting without Rewards via Factorized Meta-Reinforcement Learning
Aug 06, 2020


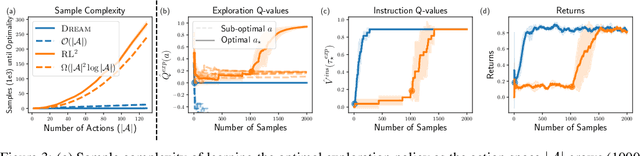
We seek to efficiently learn by leveraging shared structure between different tasks and environments. For example, cooking is similar in different kitchens, even though the ingredients may change location. In principle, meta-reinforcement learning approaches can exploit this shared structure, but in practice, they fail to adapt to new environments when adaptation requires targeted exploration (e.g., exploring the cabinets to find ingredients in a new kitchen). We show that existing approaches fail due to a chicken-and-egg problem: learning what to explore requires knowing what information is critical for solving the task, but learning to solve the task requires already gathering this information via exploration. For example, exploring to find the ingredients only helps a robot prepare a meal if it already knows how to cook, but the robot can only learn to cook if it already knows where the ingredients are. To address this, we propose a new exploration objective (DREAM), based on identifying key information in the environment, independent of how this information will exactly be used solve the task. By decoupling exploration from task execution, DREAM explores and consequently adapts to new environments, requiring no reward signal when the task is specified via an instruction. Empirically, DREAM scales to more complex problems, such as sparse-reward 3D visual navigation, while existing approaches fail from insufficient exploration.
Learning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
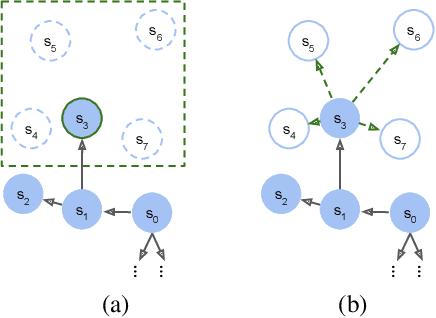

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.