 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Sampling is Preconditioned Stochastic Gradient Descent on Zero-One Loss
Paper and Code
Dec 05, 2018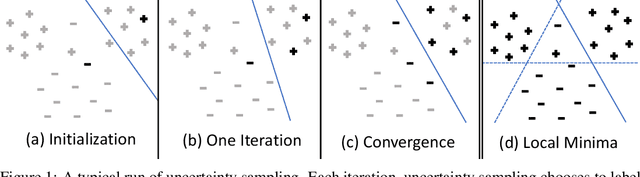
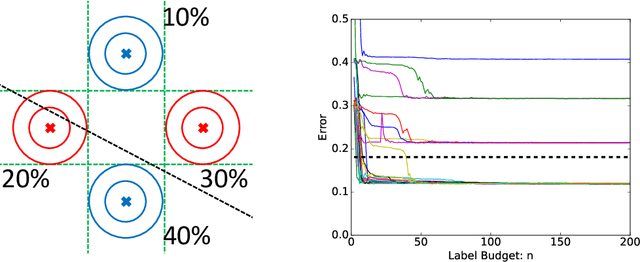
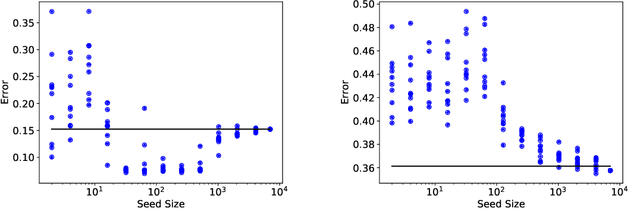
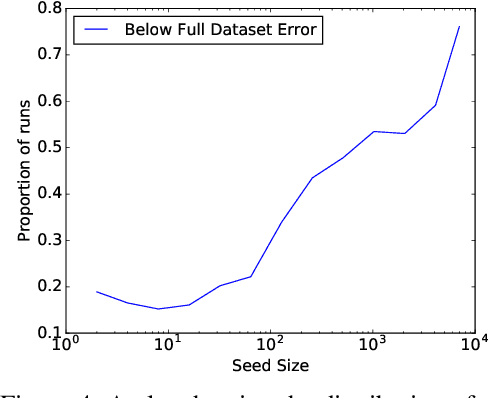
Uncertainty sampling, a popular active learning algorithm, is used to reduce the amount of data required to learn a classifier, but it has been observed in practice to converge to different parameters depending on the initialization and sometimes to even better parameters than standard training on all the data. In this work, we give a theoretical explanation of this phenomenon, showing that uncertainty sampling on a convex loss can be interpreted as performing a preconditioned stochastic gradient step on a smoothed version of the population zero-one loss that converges to the population zero-one loss. Furthermore, uncertainty sampling moves in a descent direction and converges to stationary points of the smoothed population zero-one loss. Experiments on synthetic and real datasets support this connection.