 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Data Poisoning Attacks Break Data Sanitization Defenses
Paper and Code
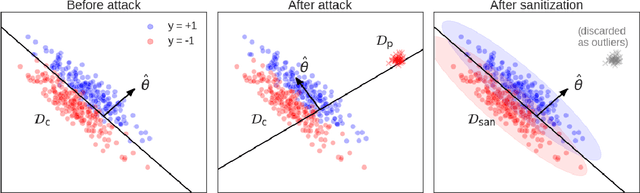

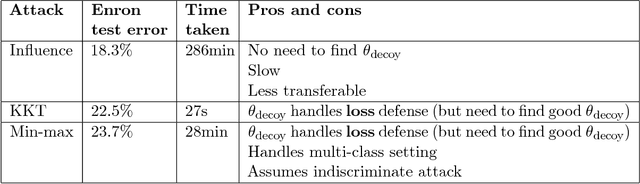
Machine learning models trained on data from the outside world can be corrupted by data poisoning attacks that inject malicious points into the models' training sets. A common defense against these attacks is data sanitization: first filter out anomalous training points before training the model. Can data poisoning attacks break data sanitization defenses? In this paper, we develop three new attacks that can all bypass a broad range of data sanitization defenses, including commonly-used anomaly detectors based on nearest neighbors, training loss, and singular-value decomposition. For example, our attacks successfully increase the test error on the Enron spam detection dataset from 3% to 24% and on the IMDB sentiment classification dataset from 12% to 29% by adding just 3% poisoned data. In contrast, many existing attacks from the literature do not explicitly consider defenses, and we show that those attacks are ineffective in the presence of the defenses we consider. Our attacks are based on two ideas: (i) we coordinate our attacks to place poisoned points near one another, which fools some anomaly detectors, and (ii) we formulate each attack as a constrained optimization problem, with constraints designed to ensure that the poisoned points evade detection. While this optimization involves solving an expensive bilevel problem, we explore and develop three efficient approximations to this problem based on influence functions; minimax duality; and the Karush-Kuhn-Tucker (KKT) conditions. Our results underscore the urgent need to develop more sophisticated and robust defenses against data poisoning attacks.