 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Implicit Feedback for Cold-start Recommendation
Jun 17, 2026Implicit feedback is widely used in recommender systems due to its accessibility and generality, yet it usually presents noisy samples (e.g., clickbait, position bias). Meanwhile, recommenders inevitably face the item cold-start problem due to the continuous influx of new items. We identify that cold items are more prone to noisy samples due to the aforementioned factors, and researchers often overlook the significance of denoising implicit feedback for cold items. Previous denoising studies usually identify noisy samples based on heuristic patterns, such as higher loss values, and mitigate noise through sample selection or re-weighting. However, these methods have limited adaptability and are ineffective in cold-start scenarios. To achieve denoising implicit feedback for cold-start recommendation, we propose a model-agnostic denoising method called DIF. First, user preferences for content remain stable, which allows us to infer pseudo-labels indicating whether a user is interested in a cold item through content-similar warm items. Furthermore, to improve pseudo-label accuracy, we model the confidence of pseudo-labels based on the content similarity between the cold item and warm items, and then aggregate multiple pseudo-labels for each sample. Finally, we explicitly estimate the uncertainty of the noisy sample label by considering its relative entropy and the cold-start status of the item, which adaptively guides the role of pseudo-labels to correct the noisy labels at the sample level. DIF's superiority is supported by both theoretical justification and extensive experiments on real-world datasets. The method has been deployed on a billion-user scale short video application Kuaishou and has significantly improved various commercial metrics within cold-start scenarios.
Privacy-Preserving Model Transcription with Differentially Private Synthetic Distillation
Jan 27, 2026While many deep learning models trained on private datasets have been deployed in various practical tasks, they may pose a privacy leakage risk as attackers could recover informative data or label knowledge from models. In this work, we present \emph{privacy-preserving model transcription}, a data-free model-to-model conversion solution to facilitate model deployment with a privacy guarantee. To this end, we propose a cooperative-competitive learning approach termed \emph{differentially private synthetic distillation} that learns to convert a pretrained model (teacher) into its privacy-preserving counterpart (student) via a trainable generator without access to private data. The learning collaborates with three players in a unified framework and performs alternate optimization: i)~the generator is learned to generate synthetic data, ii)~the teacher and student accept the synthetic data and compute differential private labels by flexible data or label noisy perturbation, and iii)~the student is updated with noisy labels and the generator is updated by taking the student as a discriminator for adversarial training. We theoretically prove that our approach can guarantee differential privacy and convergence. The transcribed student has good performance and privacy protection, while the resulting generator can generate private synthetic data for downstream tasks. Extensive experiments clearly demonstrate that our approach outperforms 26 state-of-the-arts.
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
Learning Natural Consistency Representation for Face Forgery Video Detection
Jul 15, 2024



Face Forgery videos have elicited critical social public concerns and various detectors have been proposed. However, fully-supervised detectors may lead to easily overfitting to specific forgery methods or videos, and existing self-supervised detectors are strict on auxiliary tasks, such as requiring audio or multi-modalities, leading to limited generalization and robustness. In this paper, we examine whether we can address this issue by leveraging visual-only real face videos. To this end, we propose to learn the Natural Consistency representation (NACO) of real face videos in a self-supervised manner, which is inspired by the observation that fake videos struggle to maintain the natural spatiotemporal consistency even under unknown forgery methods and different perturbations. Our NACO first extracts spatial features of each frame by CNNs then integrates them into Transformer to learn the long-range spatiotemporal representation, leveraging the advantages of CNNs and Transformer on local spatial receptive field and long-term memory respectively. Furthermore, a Spatial Predictive Module~(SPM) and a Temporal Contrastive Module~(TCM) are introduced to enhance the natural consistency representation learning. The SPM aims to predict random masked spatial features from spatiotemporal representation, and the TCM regularizes the latent distance of spatiotemporal representation by shuffling the natural order to disturb the consistency, which could both force our NACO more sensitive to the natural spatiotemporal consistency. After the representation learning stage, a MLP head is fine-tuned to perform the usual forgery video classification task. Extensive experiments show that our method outperforms other state-of-the-art competitors with impressive generalization and robustness.
DANCE: Dual-View Distribution Alignment for Dataset Condensation
Jun 03, 2024



Dataset condensation addresses the problem of data burden by learning a small synthetic training set that preserves essential knowledge from the larger real training set. To date, the state-of-the-art (SOTA) results are often yielded by optimization-oriented methods, but their inefficiency hinders their application to realistic datasets. On the other hand, the Distribution-Matching (DM) methods show remarkable efficiency but sub-optimal results compared to optimization-oriented methods. In this paper, we reveal the limitations of current DM-based methods from the inner-class and inter-class views, i.e., Persistent Training and Distribution Shift. To address these problems, we propose a new DM-based method named Dual-view distribution AligNment for dataset CondEnsation (DANCE), which exploits a few pre-trained models to improve DM from both inner-class and inter-class views. Specifically, from the inner-class view, we construct multiple "middle encoders" to perform pseudo long-term distribution alignment, making the condensed set a good proxy of the real one during the whole training process; while from the inter-class view, we use the expert models to perform distribution calibration, ensuring the synthetic data remains in the real class region during condensing. Experiments demonstrate the proposed method achieves a SOTA performance while maintaining comparable efficiency with the original DM across various scenarios. Source codes are available at https://github.com/Hansong-Zhang/DANCE.
M3D: Dataset Condensation by Minimizing Maximum Mean Discrepancy
Jan 03, 2024Training state-of-the-art (SOTA) deep models often requires extensive data, resulting in substantial training and storage costs. To address these challenges, dataset condensation has been developed to learn a small synthetic set that preserves essential information from the original large-scale dataset. Nowadays, optimization-oriented methods have been the primary method in the field of dataset condensation for achieving SOTA results. However, the bi-level optimization process hinders the practical application of such methods to realistic and larger datasets. To enhance condensation efficiency, previous works proposed Distribution-Matching (DM) as an alternative, which significantly reduces the condensation cost. Nonetheless, current DM-based methods have yielded less comparable results to optimization-oriented methods due to their focus on aligning only the first moment of the distributions. In this paper, we present a novel DM-based method named M3D for dataset condensation by Minimizing the Maximum Mean Discrepancy between feature representations of the synthetic and real images. By embedding their distributions in a reproducing kernel Hilbert space, we align all orders of moments of the distributions of real and synthetic images, resulting in a more generalized condensed set. Notably, our method even surpasses the SOTA optimization-oriented method IDC on the high-resolution ImageNet dataset. Extensive analysis is conducted to verify the effectiveness of the proposed method.
Coupled Confusion Correction: Learning from Crowds with Sparse Annotations
Dec 26, 2023



As the size of the datasets getting larger, accurately annotating such datasets is becoming more impractical due to the expensiveness on both time and economy. Therefore, crowd-sourcing has been widely adopted to alleviate the cost of collecting labels, which also inevitably introduces label noise and eventually degrades the performance of the model. To learn from crowd-sourcing annotations, modeling the expertise of each annotator is a common but challenging paradigm, because the annotations collected by crowd-sourcing are usually highly-sparse. To alleviate this problem, we propose Coupled Confusion Correction (CCC), where two models are simultaneously trained to correct the confusion matrices learned by each other. Via bi-level optimization, the confusion matrices learned by one model can be corrected by the distilled data from the other. Moreover, we cluster the ``annotator groups'' who share similar expertise so that their confusion matrices could be corrected together. In this way, the expertise of the annotators, especially of those who provide seldom labels, could be better captured. Remarkably, we point out that the annotation sparsity not only means the average number of labels is low, but also there are always some annotators who provide very few labels, which is neglected by previous works when constructing synthetic crowd-sourcing annotations. Based on that, we propose to use Beta distribution to control the generation of the crowd-sourcing labels so that the synthetic annotations could be more consistent with the real-world ones. Extensive experiments are conducted on two types of synthetic datasets and three real-world datasets, the results of which demonstrate that CCC significantly outperforms state-of-the-art approaches.
Multi-Label Noise Transition Matrix Estimation with Label Correlations: Theory and Algorithm
Sep 22, 2023



Noisy multi-label learning has garnered increasing attention due to the challenges posed by collecting large-scale accurate labels, making noisy labels a more practical alternative. Motivated by noisy multi-class learning, the introduction of transition matrices can help model multi-label noise and enable the development of statistically consistent algorithms for noisy multi-label learning. However, estimating multi-label noise transition matrices remains a challenging task, as most existing estimators in noisy multi-class learning rely on anchor points and accurate fitting of noisy class posteriors, which is hard to satisfy in noisy multi-label learning. In this paper, we address this problem by first investigating the identifiability of class-dependent transition matrices in noisy multi-label learning. Building upon the identifiability results, we propose a novel estimator that leverages label correlations without the need for anchor points or precise fitting of noisy class posteriors. Specifically, we first estimate the occurrence probability of two noisy labels to capture noisy label correlations. Subsequently, we employ sample selection techniques to extract information implying clean label correlations, which are then used to estimate the occurrence probability of one noisy label when a certain clean label appears. By exploiting the mismatches in label correlations implied by these occurrence probabilities, we demonstrate that the transition matrix becomes identifiable and can be acquired by solving a bilinear decomposition problem. Theoretically, we establish an estimation error bound for our multi-label transition matrix estimator and derive a generalization error bound for our statistically consistent algorithm. Empirically, we validate the effectiveness of our estimator in estimating multi-label noise transition matrices, leading to excellent classification performance.
Transferring Annotator- and Instance-dependent Transition Matrix for Learning from Crowds
Jun 05, 2023Learning from crowds describes that the annotations of training data are obtained with crowd-sourcing services. Multiple annotators each complete their own small part of the annotations, where labeling mistakes that depend on annotators occur frequently. Modeling the label-noise generation process by the noise transition matrix is a power tool to tackle the label noise. In real-world crowd-sourcing scenarios, noise transition matrices are both annotator- and instance-dependent. However, due to the high complexity of annotator- and instance-dependent transition matrices (AIDTM), \textit{annotation sparsity}, which means each annotator only labels a little part of instances, makes modeling AIDTM very challenging. Prior works simplify the problem by assuming the transition matrix is instance-independent or using simple parametric way, while lose modeling generality. Motivated by this, we target a more realistic problem, estimating general AIDTM in practice. Without losing modeling generality, we parameterize AIDTM with deep neural networks. To alleviate the modeling challenge, we suppose every annotator shares its noise pattern with similar annotators, and estimate AIDTM via \textit{knowledge transfer}. We hence first model the mixture of noise patterns by all annotators, and then transfer this modeling to individual annotators. Furthermore, considering that the transfer from the mixture of noise patterns to individuals may cause two annotators with highly different noise generations to perturb each other, we employ the knowledge transfer between identified neighboring annotators to calibrate the modeling. Experiments confirm the superiority of the proposed approach on synthetic and real-world crowd-sourcing data. Source codes will be released.
Trustable Co-label Learning from Multiple Noisy Annotators
Mar 08, 2022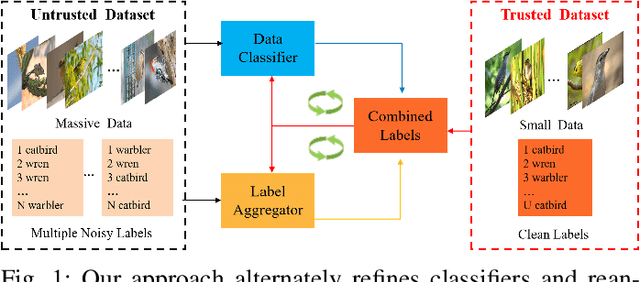
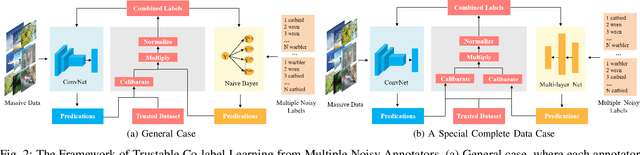
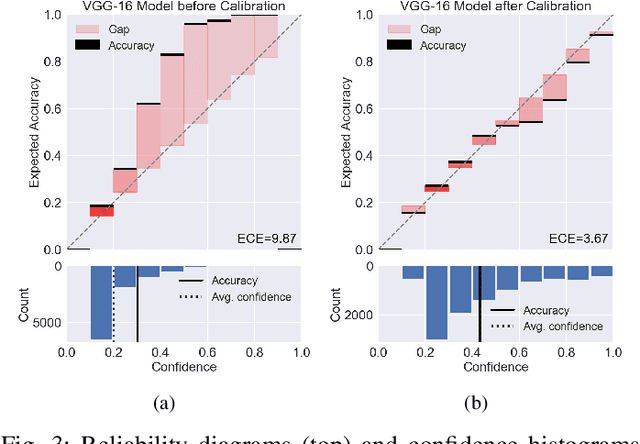
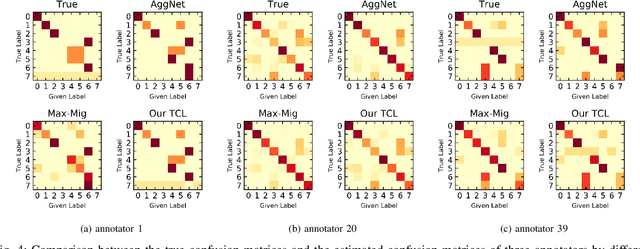
Supervised deep learning depends on massive accurately annotated examples, which is usually impractical in many real-world scenarios. A typical alternative is learning from multiple noisy annotators. Numerous earlier works assume that all labels are noisy, while it is usually the case that a few trusted samples with clean labels are available. This raises the following important question: how can we effectively use a small amount of trusted data to facilitate robust classifier learning from multiple annotators? This paper proposes a data-efficient approach, called \emph{Trustable Co-label Learning} (TCL), to learn deep classifiers from multiple noisy annotators when a small set of trusted data is available. This approach follows the coupled-view learning manner, which jointly learns the data classifier and the label aggregator. It effectively uses trusted data as a guide to generate trustable soft labels (termed co-labels). A co-label learning can then be performed by alternately reannotating the pseudo labels and refining the classifiers. In addition, we further improve TCL for a special complete data case, where each instance is labeled by all annotators and the label aggregator is represented by multilayer neural networks to enhance model capacity. Extensive experiments on synthetic and real datasets clearly demonstrate the effectiveness and robustness of the proposed approach. Source code is available at https://github.com/ShikunLi/TCL