 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Depth for Pixel-Wise Detection of Adversarial Attacks in Crowd Counting
Nov 26, 2019

State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. While effective, deep learning approaches are vulnerable to adversarial attacks, which, in a crowd-counting context, can lead to serious security issues. However, attack and defense mechanisms have been virtually unexplored in regression tasks, let alone for crowd density estimation. In this paper, we investigate the effectiveness of existing attack strategies on crowd-counting networks, and introduce a simple yet effective pixel-wise detection mechanism. It builds on the intuition that, when attacking a multitask network, in our case estimating crowd density and scene depth, both outputs will be perturbed, and thus the second one can be used for detection purposes. We will demonstrate that this significantly outperforms heuristic-based and uncertainty-based strategies.
Shape Reconstruction by Learning Differentiable Surface Representations
Nov 25, 2019
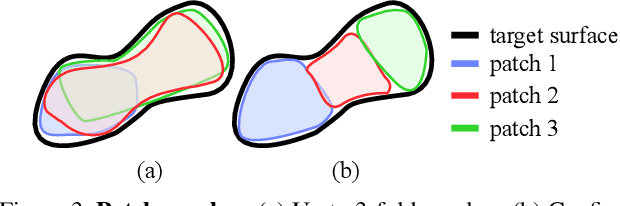
Generative models that produce point clouds have emerged as a powerful tool to represent 3D surfaces, and the best current ones rely on learning an ensemble of parametric representations. Unfortunately, they offer no control over the deformations of the surface patches that form the ensemble and thus fail to prevent them from either overlapping or collapsing into single points or lines. As a consequence, computing shape properties such as surface normals and curvatures becomes difficult and unreliable. In this paper, we show that we can exploit the inherent differentiability of deep networks to leverage differential surface properties during training so as to prevent patch collapse and strongly reduce patch overlap. Furthermore, this lets us reliably compute quantities such as surface normals and curvatures. We will demonstrate on several tasks that this yields more accurate surface reconstructions than the state-of-the-art methods in terms of normals estimation and amount of collapsed and overlapped patches.
Estimating People Flows to Better Count them in Crowded Scenes
Nov 25, 2019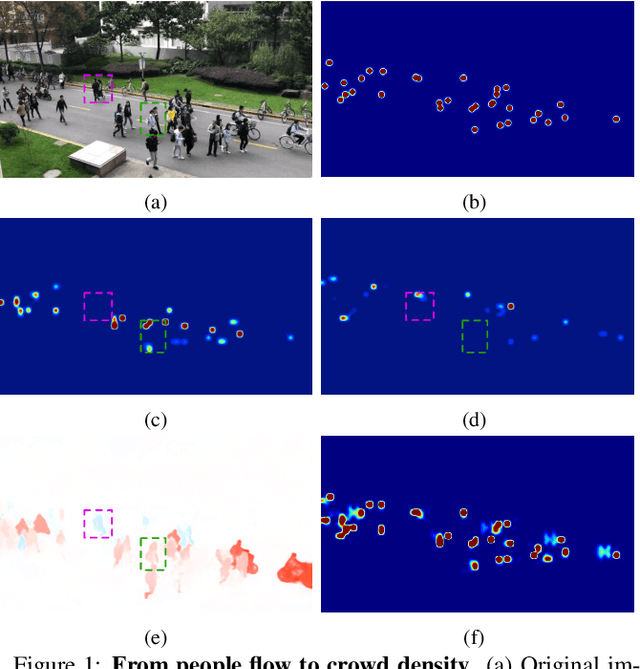
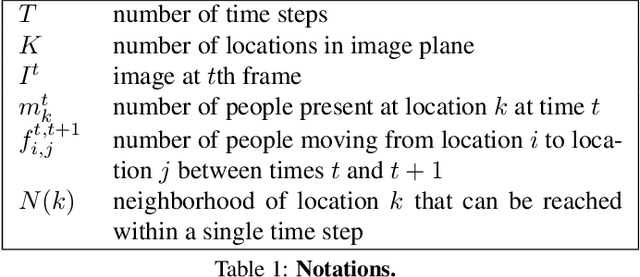
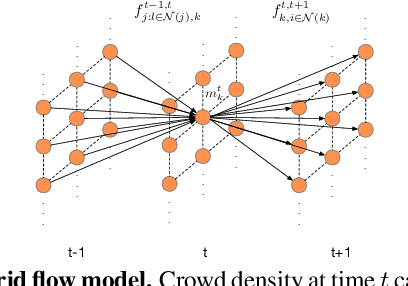
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate people densities in individual images. As such, only very few take advantage of temporal consistency in video sequences, and those that do only impose weak smoothness constraints across consecutive frames. In this paper, we show that estimating people flows across image locations between consecutive images and inferring the people densities from these flows instead of directly regressing them makes it possible to impose much stronger constraints encoding the conservation of the number of people, which significantly boost performance without requiring a more complex architecture. Furthermore, it also enables us to exploit the correlation between people flow and optical flow to further improve the results. We will demonstrate that we consistently outperform state-of-the-art methods on five benchmark datasets.
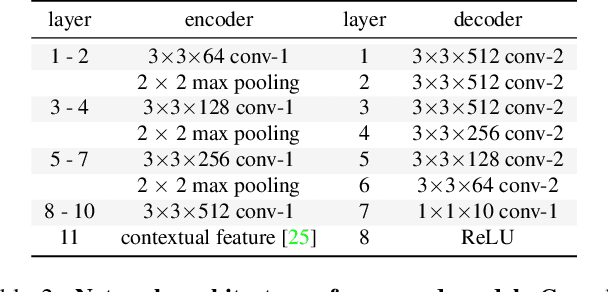
Single-Stage 6D Object Pose Estimation
Nov 19, 2019
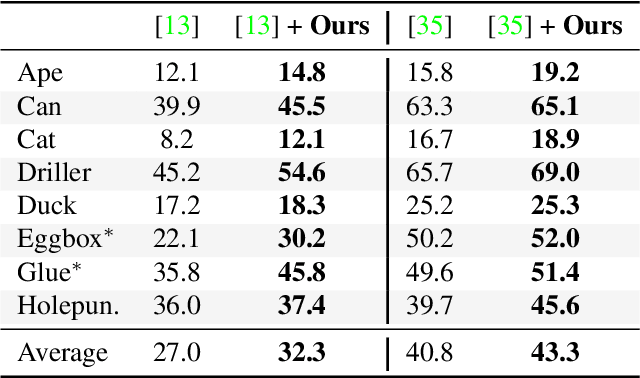
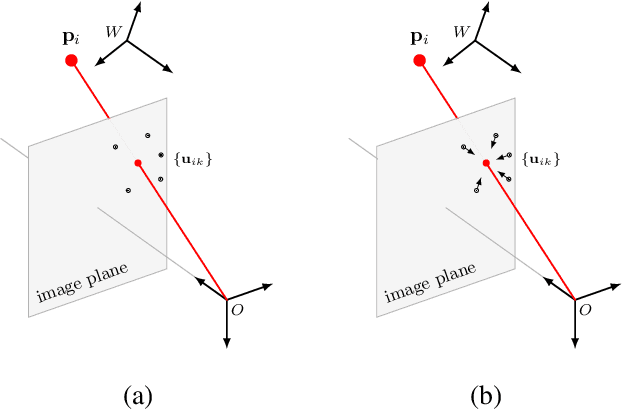
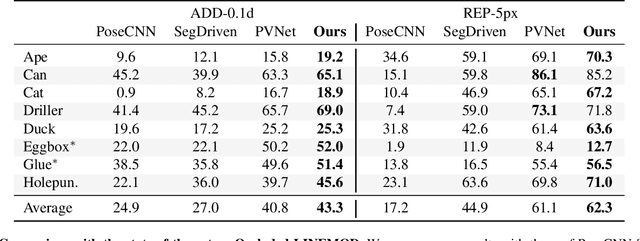
Most recent 6D pose estimation frameworks first rely on a deep network to establish correspondences between 3D object keypoints and 2D image locations and then use a variant of a RANSAC-based Perspective-n-Point (PnP) algorithm. This two-stage process, however, is suboptimal: First, it is not end-to-end trainable. Second, training the deep network relies on a surrogate loss that does not directly reflect the final 6D pose estimation task. In this work, we introduce a deep architecture that directly regresses 6D poses from correspondences. It takes as input a group of candidate correspondences for each 3D keypoint and accounts for the fact that the order of the correspondences within each group is irrelevant, while the order of the groups, that is, of the 3D keypoints, is fixed. Our architecture is generic and can thus be exploited in conjunction with existing correspondence-extraction networks so as to yield single-stage 6D pose estimation frameworks. Our experiments demonstrate that these single-stage frameworks consistently outperform their two-stage counterparts in terms of both accuracy and speed.
Gravity as a Reference for Estimating a Person's Height from Video
Oct 16, 2019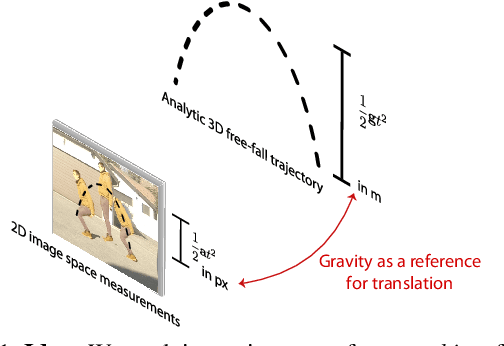
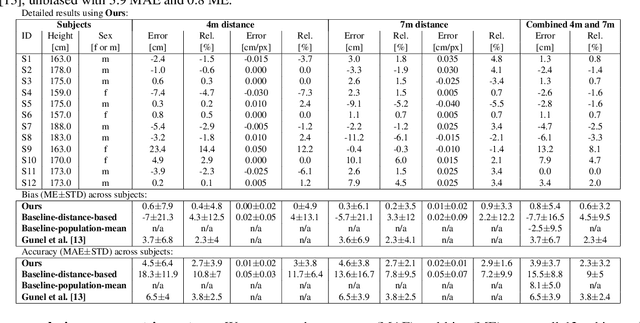
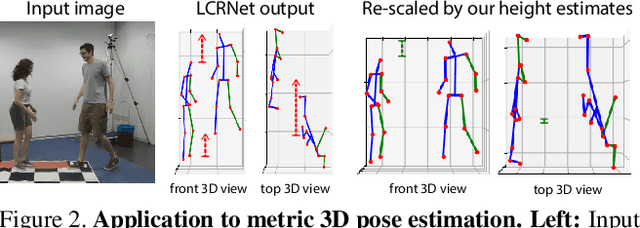

Estimating the metric height of a person from monocular imagery without additional assumptions is ill-posed. Existing solutions either require manual calibration of ground plane and camera geometry, special cameras, or reference objects of known size. We focus on motion cues and exploit gravity on earth as an omnipresent reference 'object' to translate acceleration, and subsequently height, measured in image-pixels to values in meters. We require videos of motion as input, where gravity is the only external force. This limitation is different to those of existing solutions that recover a person's height and, therefore, our method opens up new application fields. We show theoretically and empirically that a simple motion trajectory analysis suffices to translate from pixel measurements to the person's metric height, reaching a MAE of up to 3.9 cm on jumping motions, and that this works without camera and ground plane calibration.
Probabilistic Atlases to Enforce Topological Constraints
Sep 18, 2019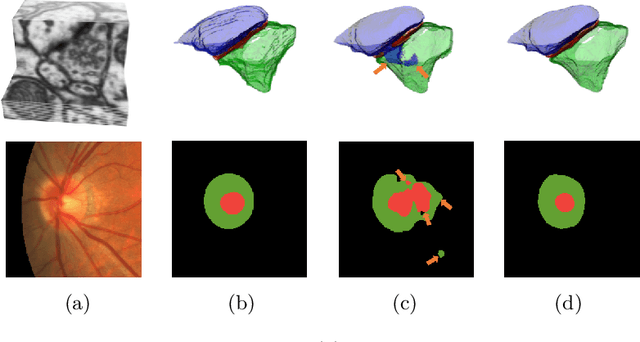
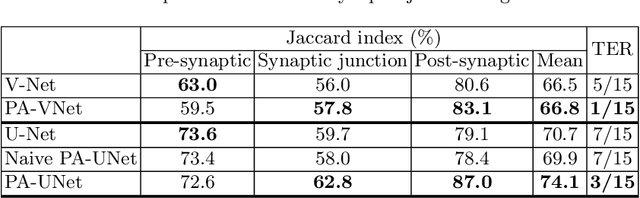
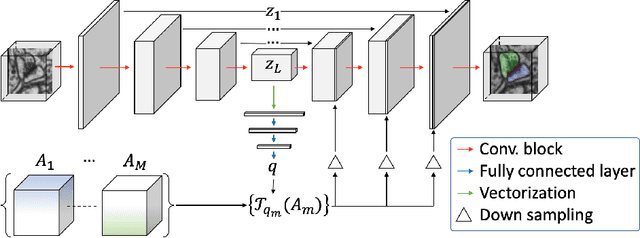
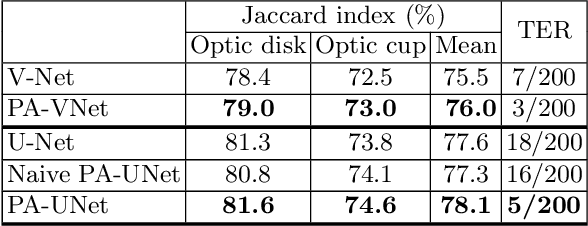
Probabilistic atlases (PAs) have long been used in standard segmentation approaches and, more recently, in conjunction with Convolutional Neural Networks (CNNs). However, their use has been restricted to relatively standardized structures such as the brain or heart which have limited or predictable range of deformations. Here we propose an encoding-decoding CNN architecture that can exploit rough atlases that encode only the topology of the target structures that can appear in any pose and have arbitrarily complex shapes to improve the segmentation results. It relies on the output of the encoder to compute both the pose parameters used to deform the atlas and the segmentation mask itself, which makes it effective and end-to-end trainable.
Motion Capture from Pan-Tilt Cameras with Unknown Orientation
Aug 30, 2019
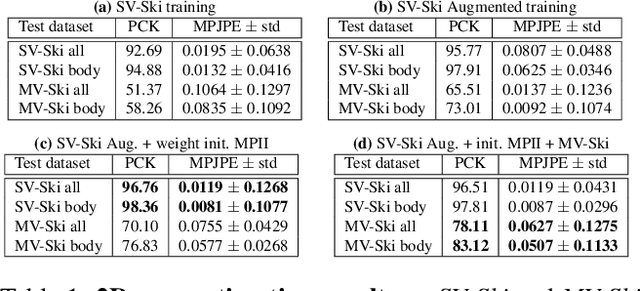
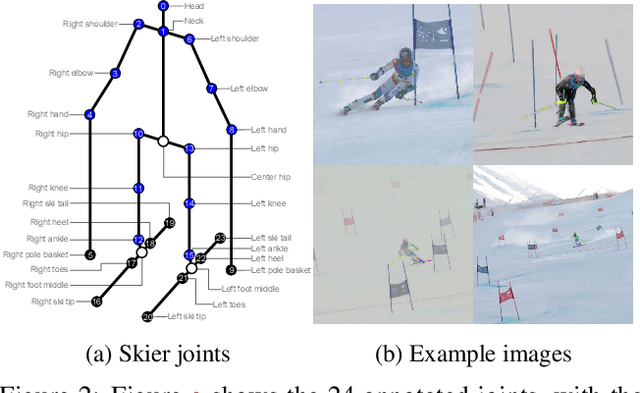
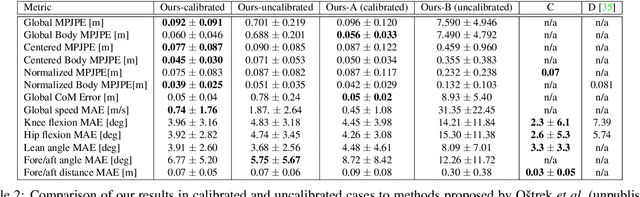
In sports, such as alpine skiing, coaches would like to know the speed and various biomechanical variables of their athletes and competitors. Existing methods use either body-worn sensors, which are cumbersome to setup, or manual image annotation, which is time consuming. We propose a method for estimating an athlete's global 3D position and articulated pose using multiple cameras. By contrast to classical markerless motion capture solutions, we allow cameras to rotate freely so that large capture volumes can be covered. In a first step, tight crops around the skier are predicted and fed to a 2D pose estimator network. The 3D pose is then reconstructed using a bundle adjustment method. Key to our solution is the rotation estimation of Pan-Tilt cameras in a joint optimization with the athlete pose and conditioning on relative background motion computed with feature tracking. Furthermore, we created a new alpine skiing dataset and annotated it with 2D pose labels, to overcome shortcomings of existing ones. Our method estimates accurate global 3D poses from images only and provides coaches with an automatic and fast tool for measuring and improving an athlete's performance.
Beyond Cartesian Representations for Local Descriptors
Aug 15, 2019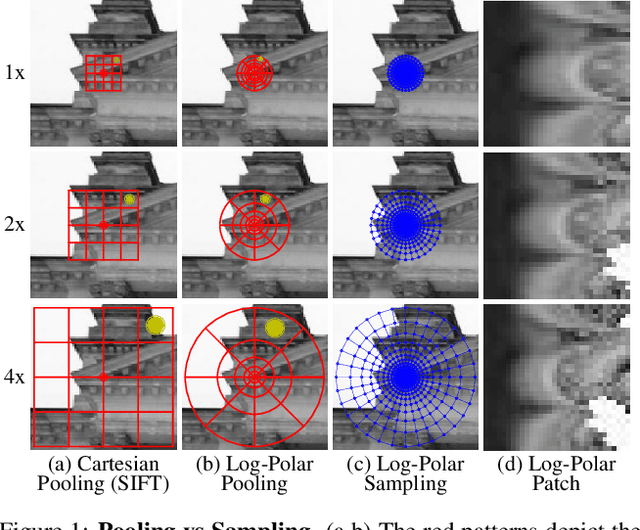
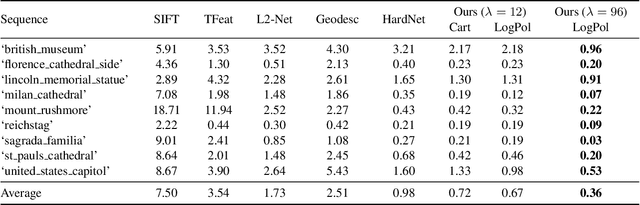

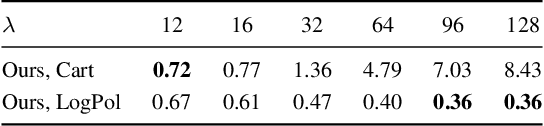
The dominant approach for learning local patch descriptors relies on small image regions whose scale must be properly estimated a priori by a keypoint detector. In other words, if two patches are not in correspondence, their descriptors will not match. A strategy often used to alleviate this problem is to "pool" the pixel-wise features over log-polar regions, rather than regularly spaced ones. By contrast, we propose to extract the "support region" directly with a log-polar sampling scheme. We show that this provides us with a better representation by simultaneously oversampling the immediate neighbourhood of the point and undersampling regions far away from it. We demonstrate that this representation is particularly amenable to learning descriptors with deep networks. Our models can match descriptors across a much wider range of scales than was possible before, and also leverage much larger support regions without suffering from occlusions. We report state-of-the-art results on three different datasets.
Self-supervised Training of Proposal-based Segmentation via Background Prediction
Jul 18, 2019

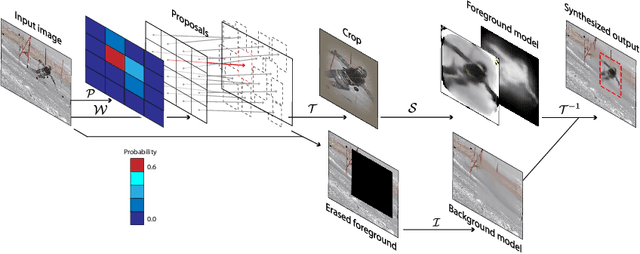
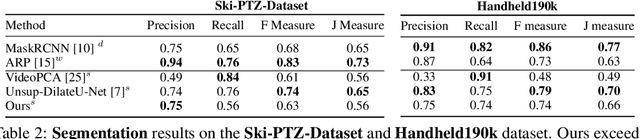
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.
XNect: Real-time Multi-person 3D Human Pose Estimation with a Single RGB Camera
Jul 01, 2019
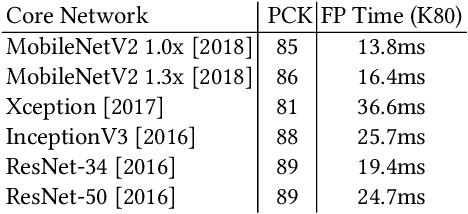
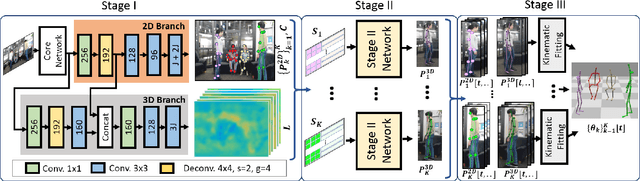
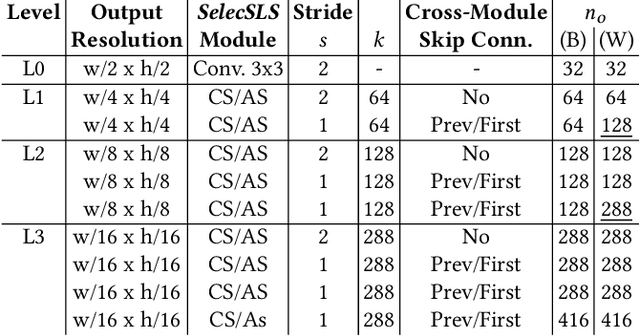
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates in generic scenes and is robust to difficult occlusions both by other people and objects. Our method operates in subsequent stages. The first stage is a convolutional neural network (CNN) that estimates 2D and 3D pose features along with identity assignments for all visible joints of all individuals. We contribute a new architecture for this CNN, called SelecSLS Net, that uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy. In the second stage, a fully-connected neural network turns the possibly partial (on account of occlusion) 2D pose and 3D pose features for each subject into a complete 3D pose estimate per individual. The third stage applies space-time skeletal model fitting to the predicted 2D and 3D pose per subject to further reconcile the 2D and 3D pose, and enforce temporal coherence. Our method returns the full skeletal pose in joint angles for each subject. This is a further key distinction from previous work that neither extracted global body positions nor joint angle results of a coherent skeleton in real time for multi-person scenes. The proposed system runs on consumer hardware at a previously unseen speed of more than 30 fps given 512x320 images as input while achieving state-of-the-art accuracy, which we will demonstrate on a range of challenging real-world scenes.