 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDE foundation models are skillful AI weather emulators for the Martian atmosphere
Feb 16, 2026We show that AI foundation models that are pretrained on numerical solutions to a diverse corpus of partial differential equations can be adapted and fine-tuned to obtain skillful predictive weather emulators for the Martian atmosphere. We base our work on the Poseidon PDE foundation model for two-dimensional systems. We develop a method to extend Poseidon from two to three dimensions while keeping the pretraining information. Moreover, we investigate the performance of the model in the presence of sparse initial conditions. Our results make use of four Martian years (approx.~34 GB) of training data and a median compute budget of 13 GPU hours. We find that the combination of pretraining and model extension yields a performance increase of 34.4\% on a held-out year. This shows that PDEs-FMs can not only approximate solutions to (other) PDEs but also anchor models for real-world problems with complex interactions that lack a sufficient amount of training data or a suitable compute budget.
GEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025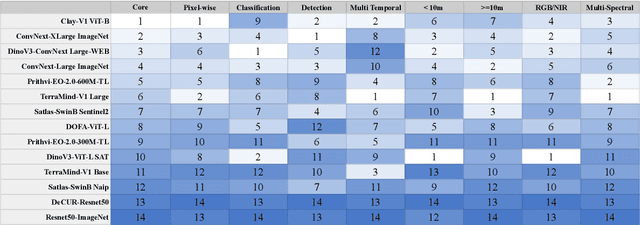


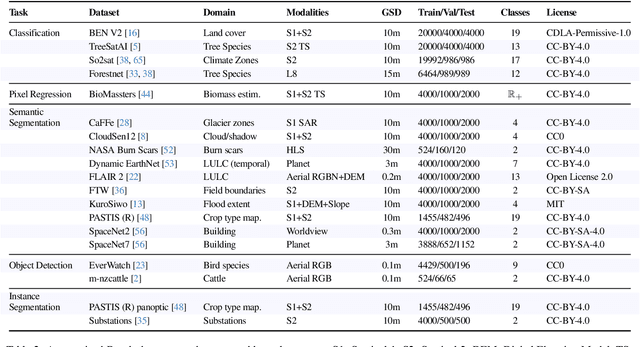
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Apr 15, 2025Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9 million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training and fostering robust cross-modal correlation learning. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset will be made publicly available with a permissive license.
A Perspective on Foundation Models for the Electric Power Grid
Jul 12, 2024



Foundation models (FMs) currently dominate news headlines. They employ advanced deep learning architectures to extract structural information autonomously from vast datasets through self-supervision. The resulting rich representations of complex systems and dynamics can be applied to many downstream applications. Therefore, FMs can find uses in electric power grids, challenged by the energy transition and climate change. In this paper, we call for the development of, and state why we believe in, the potential of FMs for electric grids. We highlight their strengths and weaknesses amidst the challenges of a changing grid. We argue that an FM learning from diverse grid data and topologies could unlock transformative capabilities, pioneering a new approach in leveraging AI to redefine how we manage complexity and uncertainty in the electric grid. Finally, we discuss a power grid FM concept, namely GridFM, based on graph neural networks and show how different downstream tasks benefit.
The Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.