 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation
Apr 15, 2021
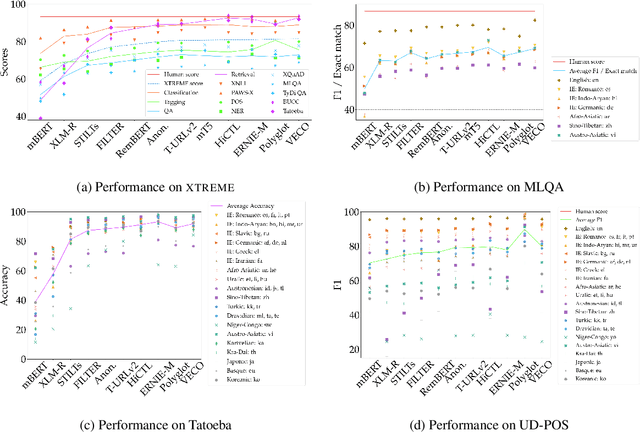
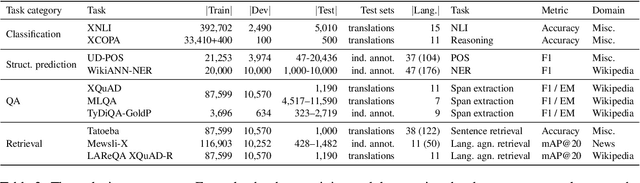
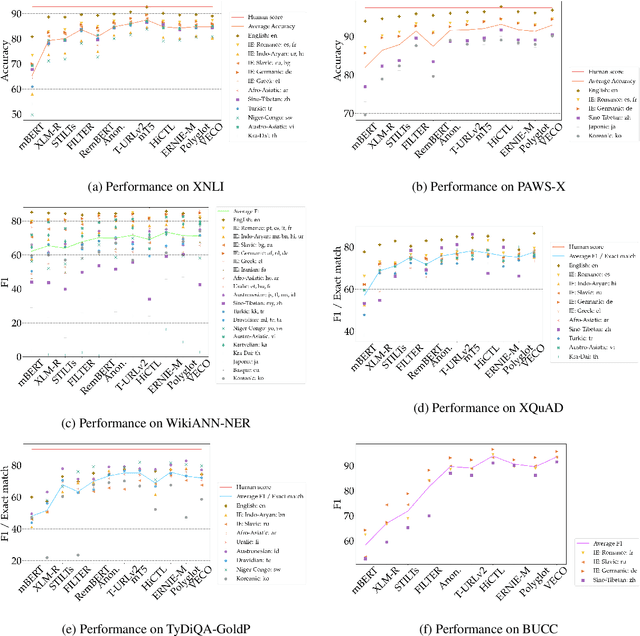
Machine learning has brought striking advances in multilingual natural language processing capabilities over the past year. For example, the latest techniques have improved the state-of-the-art performance on the XTREME multilingual benchmark by more than 13 points. While a sizeable gap to human-level performance remains, improvements have been easier to achieve in some tasks than in others. This paper analyzes the current state of cross-lingual transfer learning and summarizes some lessons learned. In order to catalyze meaningful progress, we extend XTREME to XTREME-R, which consists of an improved set of ten natural language understanding tasks, including challenging language-agnostic retrieval tasks, and covers 50 typologically diverse languages. In addition, we provide a massively multilingual diagnostic suite and fine-grained multi-dataset evaluation capabilities through an interactive public leaderboard to gain a better understanding of such models.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
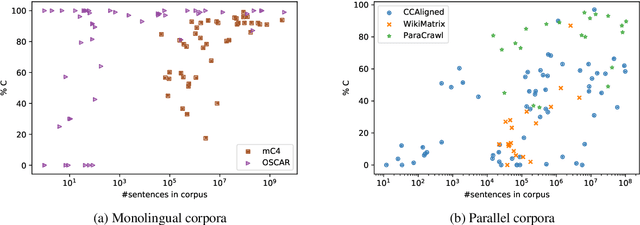

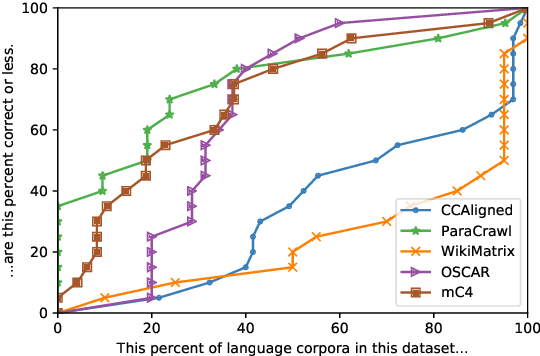
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
Mar 11, 2021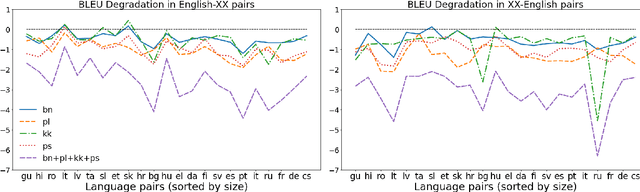
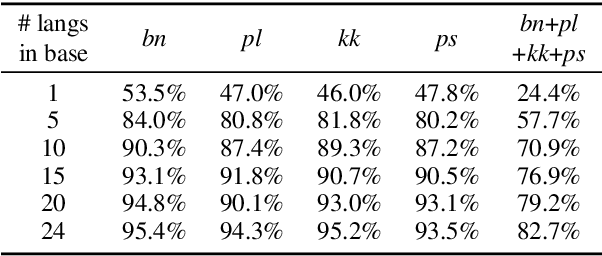
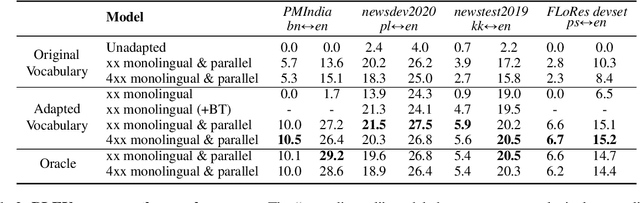
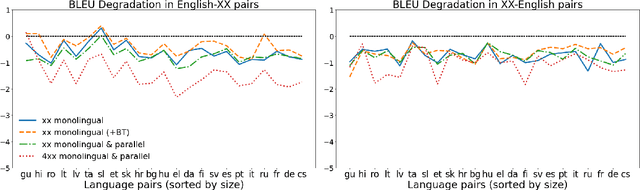
We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
Gradient-guided Loss Masking for Neural Machine Translation
Feb 26, 2021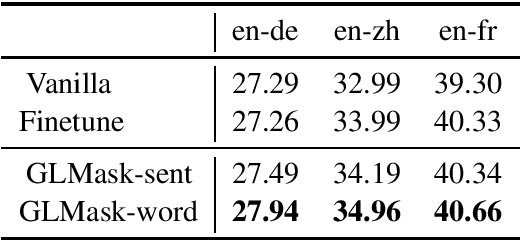
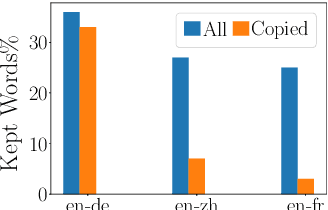
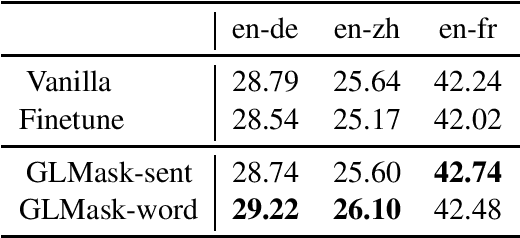
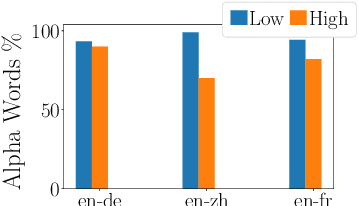
To mitigate the negative effect of low quality training data on the performance of neural machine translation models, most existing strategies focus on filtering out harmful data before training starts. In this paper, we explore strategies that dynamically optimize data usage during the training process using the model's gradients on a small set of clean data. At each training step, our algorithm calculates the gradient alignment between the training data and the clean data to mask out data with negative alignment. Our method has a natural intuition: good training data should update the model parameters in a similar direction as the clean data. Experiments on three WMT language pairs show that our method brings significant improvement over strong baselines, and the improvements are generalizable across test data from different domains.
Rapid Domain Adaptation for Machine Translation with Monolingual Data
Oct 23, 2020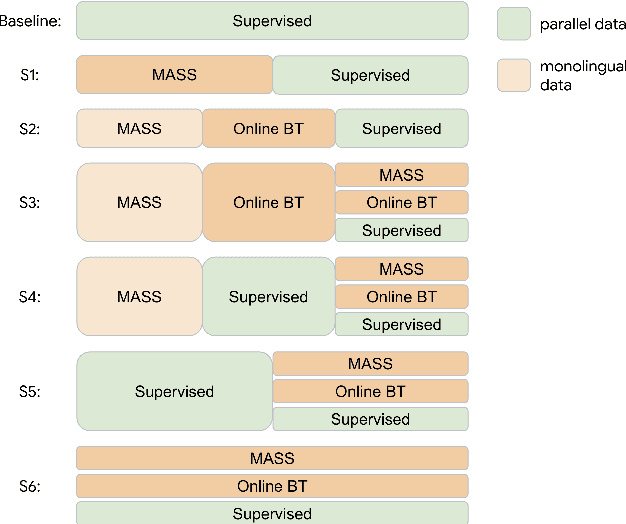
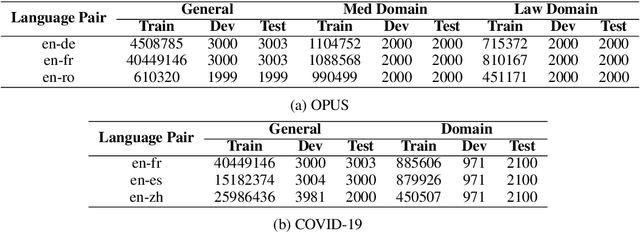
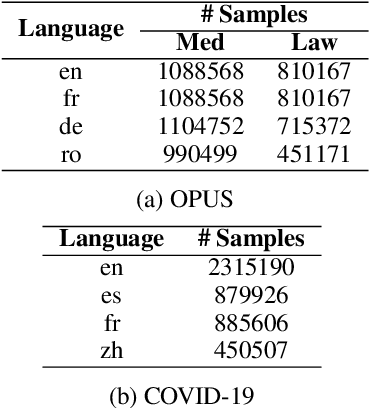
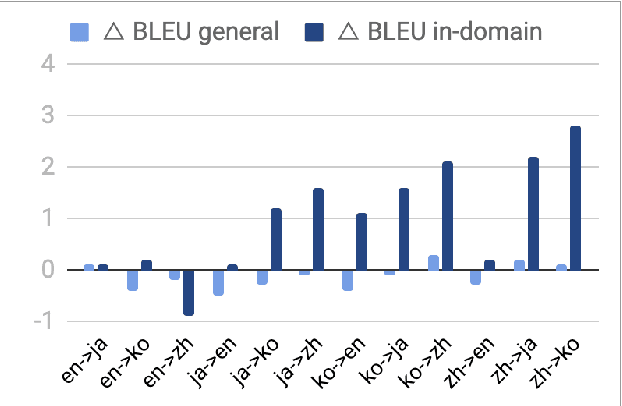
One challenge of machine translation is how to quickly adapt to unseen domains in face of surging events like COVID-19, in which case timely and accurate translation of in-domain information into multiple languages is critical but little parallel data is available yet. In this paper, we propose an approach that enables rapid domain adaptation from the perspective of unsupervised translation. Our proposed approach only requires in-domain monolingual data and can be quickly applied to a preexisting translation system trained on general domain, reaching significant gains on in-domain translation quality with little or no drop on general-domain. We also propose an effective procedure of simultaneous adaptation for multiple domains and languages. To the best of our knowledge, this is the first attempt that aims to address unsupervised multilingual domain adaptation.
Towards End-to-End In-Image Neural Machine Translation
Oct 20, 2020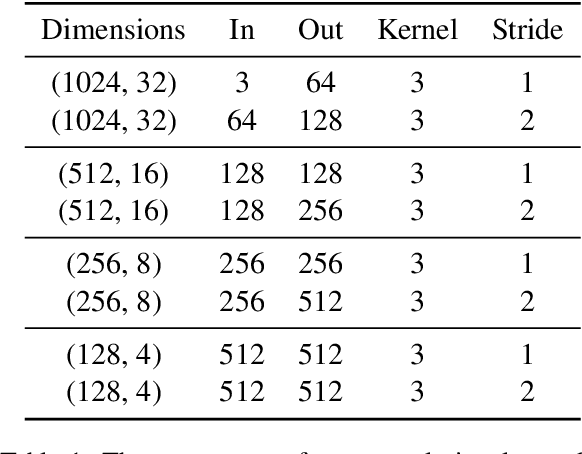

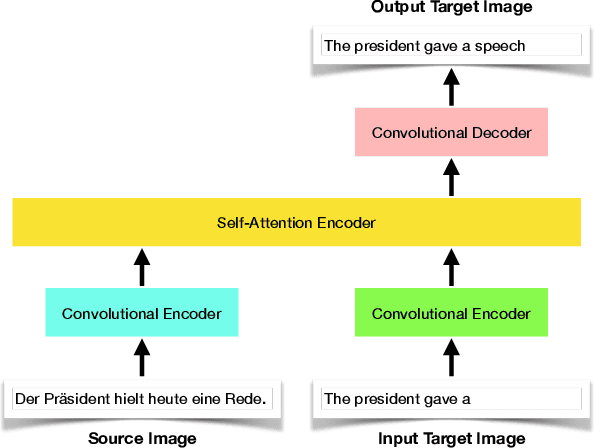
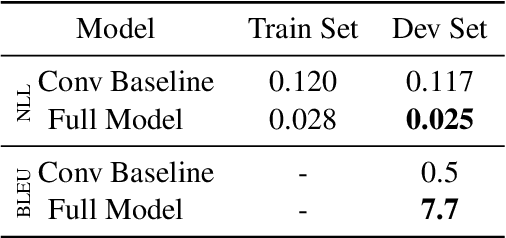
In this paper, we offer a preliminary investigation into the task of in-image machine translation: transforming an image containing text in one language into an image containing the same text in another language. We propose an end-to-end neural model for this task inspired by recent approaches to neural machine translation, and demonstrate promising initial results based purely on pixel-level supervision. We then offer a quantitative and qualitative evaluation of our system outputs and discuss some common failure modes. Finally, we conclude with directions for future work.
Complete Multilingual Neural Machine Translation
Oct 20, 2020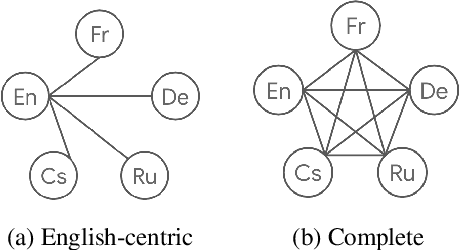
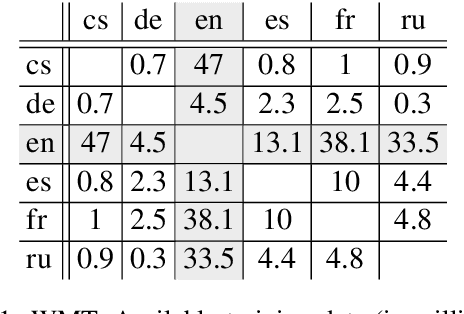
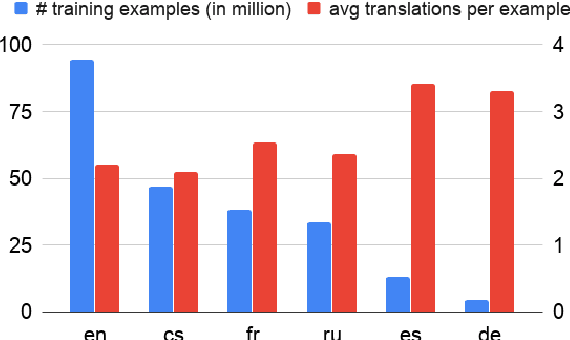
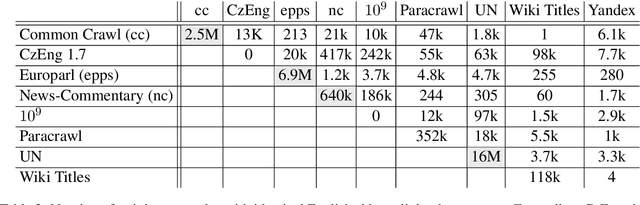
Multilingual Neural Machine Translation (MNMT) models are commonly trained on a joint set of bilingual corpora which is acutely English-centric (i.e. English either as the source or target language). While direct data between two languages that are non-English is explicitly available at times, its use is not common. In this paper, we first take a step back and look at the commonly used bilingual corpora (WMT), and resurface the existence and importance of implicit structure that existed in it: multi-way alignment across examples (the same sentence in more than two languages). We set out to study the use of multi-way aligned examples to enrich the original English-centric parallel corpora. We reintroduce this direct parallel data from multi-way aligned corpora between all source and target languages. By doing so, the English-centric graph expands into a complete graph, every language pair being connected. We call MNMT with such connectivity pattern complete Multilingual Neural Machine Translation (cMNMT) and demonstrate its utility and efficacy with a series of experiments and analysis. In combination with a novel training data sampling strategy that is conditioned on the target language only, cMNMT yields competitive translation quality for all language pairs. We further study the size effect of multi-way aligned data, its transfer learning capabilities and how it eases adding a new language in MNMT. Finally, we stress test cMNMT at scale and demonstrate that we can train a cMNMT model with up to 111*112=12,432 language pairs that provides competitive translation quality for all language pairs.
Explicit Alignment Objectives for Multilingual Bidirectional Encoders
Oct 15, 2020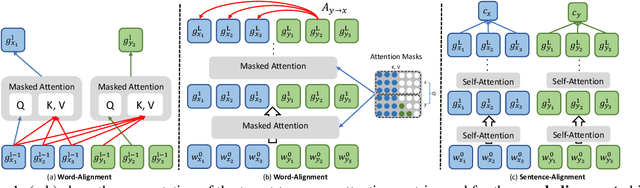
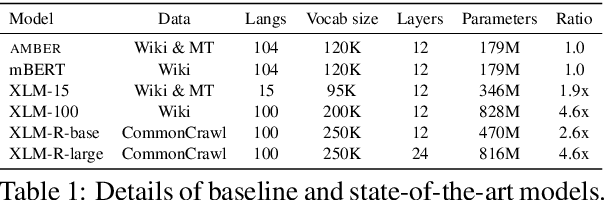
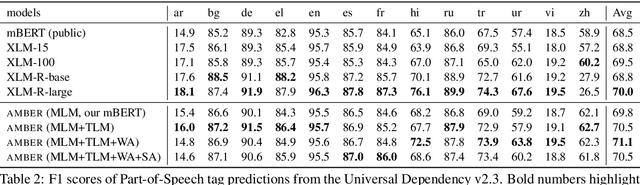
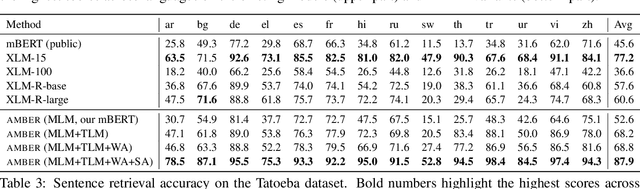
Pre-trained cross-lingual encoders such as mBERT (Devlin et al., 2019) and XLMR (Conneau et al., 2020) have proven to be impressively effective at enabling transfer-learning of NLP systems from high-resource languages to low-resource languages. This success comes despite the fact that there is no explicit objective to align the contextual embeddings of words/sentences with similar meanings across languages together in the same space. In this paper, we present a new method for learning multilingual encoders, AMBER (Aligned Multilingual Bidirectional EncodeR). AMBER is trained on additional parallel data using two explicit alignment objectives that align the multilingual representations at different granularities. We conduct experiments on zero-shot cross-lingual transfer learning for different tasks including sequence tagging, sentence retrieval and sentence classification. Experimental results show that AMBER obtains gains of up to 1.1 average F1 score on sequence tagging and up to 27.3 average accuracy on retrieval over the XLMR-large model which has 4.6x the parameters of AMBER.
Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models
Oct 12, 2020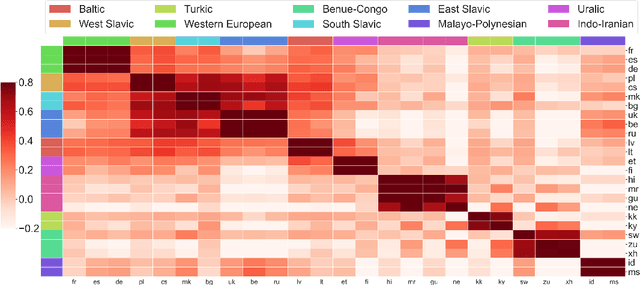
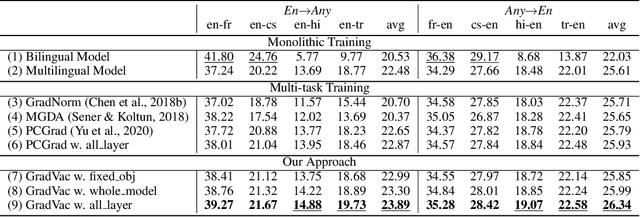
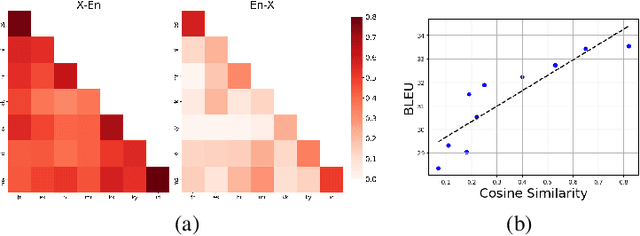
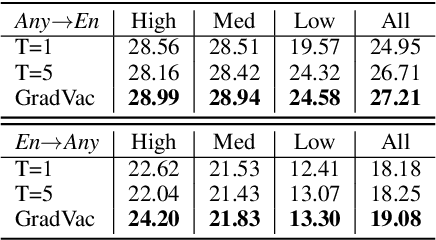
Massively multilingual models subsuming tens or even hundreds of languages pose great challenges to multi-task optimization. While it is a common practice to apply a language-agnostic procedure optimizing a joint multilingual task objective, how to properly characterize and take advantage of its underlying problem structure for improving optimization efficiency remains under-explored. In this paper, we attempt to peek into the black-box of multilingual optimization through the lens of loss function geometry. We find that gradient similarity measured along the optimization trajectory is an important signal, which correlates well with not only language proximity but also the overall model performance. Such observation helps us to identify a critical limitation of existing gradient-based multi-task learning methods, and thus we derive a simple and scalable optimization procedure, named Gradient Vaccine, which encourages more geometrically aligned parameter updates for close tasks. Empirically, our method obtains significant model performance gains on multilingual machine translation and XTREME benchmark tasks for multilingual language models. Our work reveals the importance of properly measuring and utilizing language proximity in multilingual optimization, and has broader implications for multi-task learning beyond multilingual modeling.
Harnessing Multilinguality in Unsupervised Machine Translation for Rare Languages
Sep 23, 2020

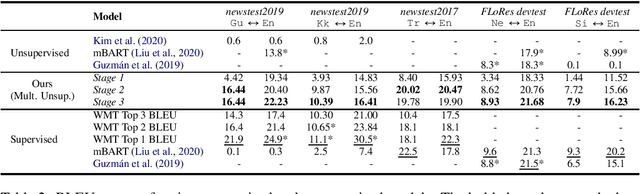
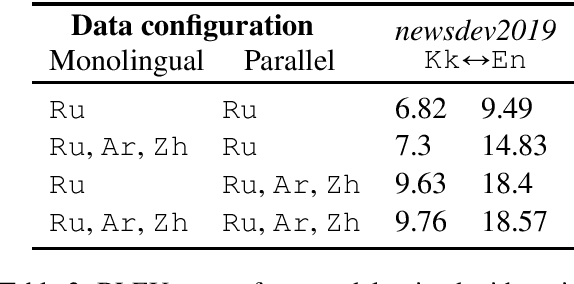
Unsupervised translation has reached impressive performance on resource-rich language pairs such as English-French and English-German. However, early studies have shown that in more realistic settings involving low-resource, rare languages, unsupervised translation performs poorly, achieving less than 3.0 BLEU. In this work, we show that multilinguality is critical to making unsupervised systems practical for low-resource settings. In particular, we present a single model for 5 low-resource languages (Gujarati, Kazakh, Nepali, Sinhala, and Turkish) to and from English directions, which leverages monolingual and auxiliary parallel data from other high-resource language pairs via a three-stage training scheme. We outperform all current state-of-the-art unsupervised baselines for these languages, achieving gains of up to 14.4 BLEU. Additionally, we outperform a large collection of supervised WMT submissions for various language pairs as well as match the performance of the current state-of-the-art supervised model for Nepali-English. We conduct a series of ablation studies to establish the robustness of our model under different degrees of data quality, as well as to analyze the factors which led to the superior performance of the proposed approach over traditional unsupervised models.