 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer
Oct 30, 2021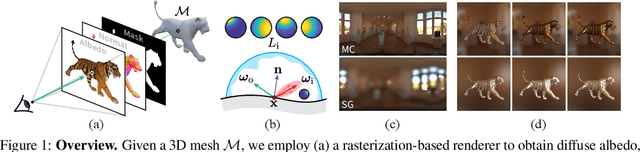
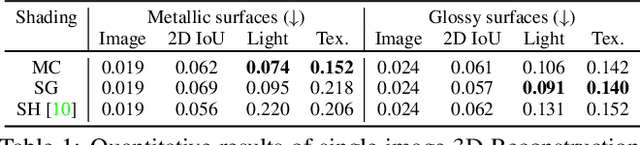
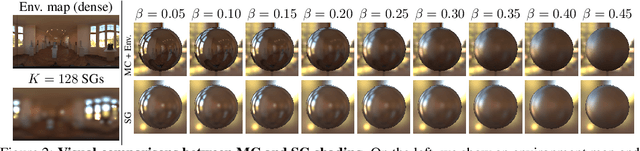

We consider the challenging problem of predicting intrinsic object properties from a single image by exploiting differentiable renderers. Many previous learning-based approaches for inverse graphics adopt rasterization-based renderers and assume naive lighting and material models, which often fail to account for non-Lambertian, specular reflections commonly observed in the wild. In this work, we propose DIBR++, a hybrid differentiable renderer which supports these photorealistic effects by combining rasterization and ray-tracing, taking the advantage of their respective strengths -- speed and realism. Our renderer incorporates environmental lighting and spatially-varying material models to efficiently approximate light transport, either through direct estimation or via spherical basis functions. Compared to more advanced physics-based differentiable renderers leveraging path tracing, DIBR++ is highly performant due to its compact and expressive shading model, which enables easy integration with learning frameworks for geometry, reflectance and lighting prediction from a single image without requiring any ground-truth. We experimentally demonstrate that our approach achieves superior material and lighting disentanglement on synthetic and real data compared to existing rasterization-based approaches and showcase several artistic applications including material editing and relighting.
Mix3D: Out-of-Context Data Augmentation for 3D Scenes
Oct 05, 2021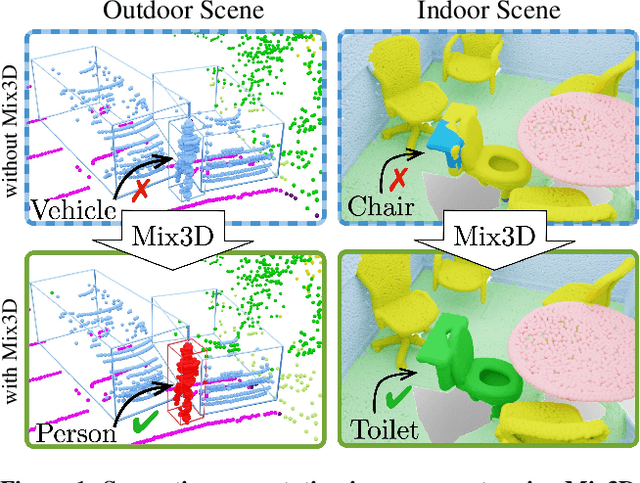
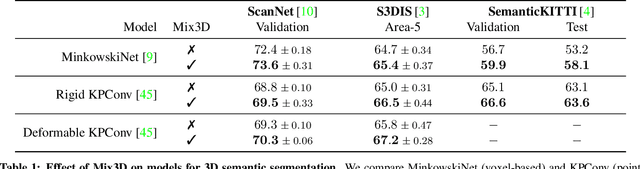


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/
StrobeNet: Category-Level Multiview Reconstruction of Articulated Objects
May 17, 2021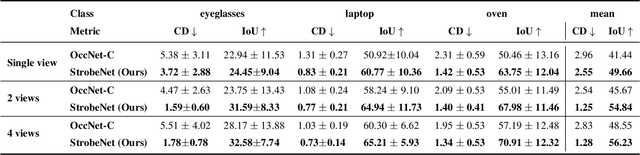
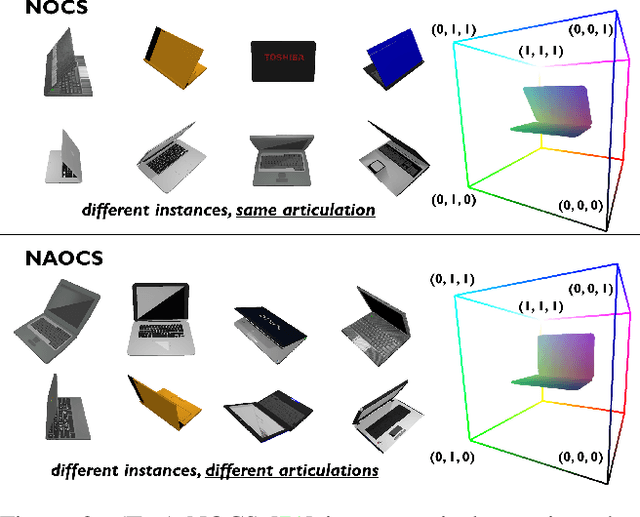
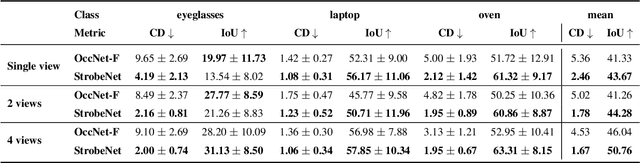
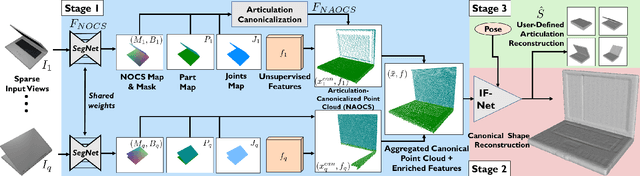
We present StrobeNet, a method for category-level 3D reconstruction of articulating objects from one or more unposed RGB images. Reconstructing general articulating object categories % has important applications, but is challenging since objects can have wide variation in shape, articulation, appearance and topology. We address this by building on the idea of category-level articulation canonicalization -- mapping observations to a canonical articulation which enables correspondence-free multiview aggregation. Our end-to-end trainable neural network estimates feature-enriched canonical 3D point clouds, articulation joints, and part segmentation from one or more unposed images of an object. These intermediate estimates are used to generate a final implicit 3D reconstruction.Our approach reconstructs objects even when they are observed in different articulations in images with large baselines, and animation of reconstructed shapes. Quantitative and qualitative evaluations on different object categories show that our method is able to achieve high reconstruction accuracy, especially as more views are added.
Vector Neurons: A General Framework for SO-Equivariant Networks
Apr 25, 2021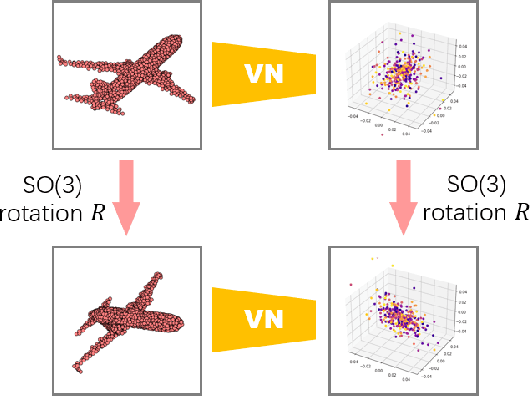
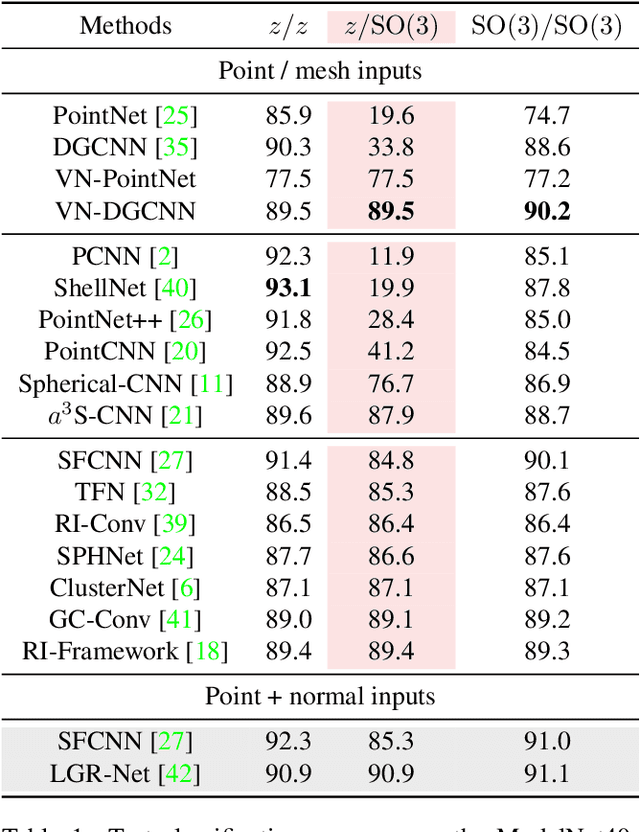
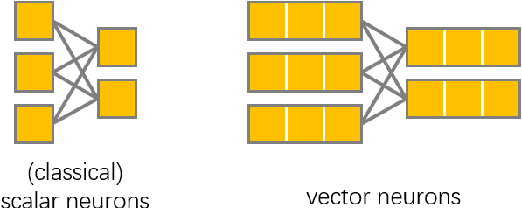
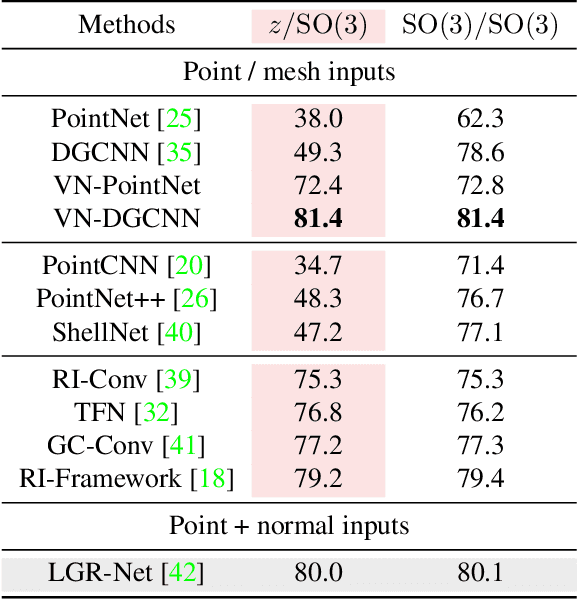
Invariance and equivariance to the rotation group have been widely discussed in the 3D deep learning community for pointclouds. Yet most proposed methods either use complex mathematical tools that may limit their accessibility, or are tied to specific input data types and network architectures. In this paper, we introduce a general framework built on top of what we call Vector Neuron representations for creating SO(3)-equivariant neural networks for pointcloud processing. Extending neurons from 1D scalars to 3D vectors, our vector neurons enable a simple mapping of SO(3) actions to latent spaces thereby providing a framework for building equivariance in common neural operations -- including linear layers, non-linearities, pooling, and normalizations. Due to their simplicity, vector neurons are versatile and, as we demonstrate, can be incorporated into diverse network architecture backbones, allowing them to process geometry inputs in arbitrary poses. Despite its simplicity, our method performs comparably well in accuracy and generalization with other more complex and specialized state-of-the-art methods on classification and segmentation tasks. We also show for the first time a rotation equivariant reconstruction network.
Spectral Unions of Partial Deformable 3D Shapes
Mar 31, 2021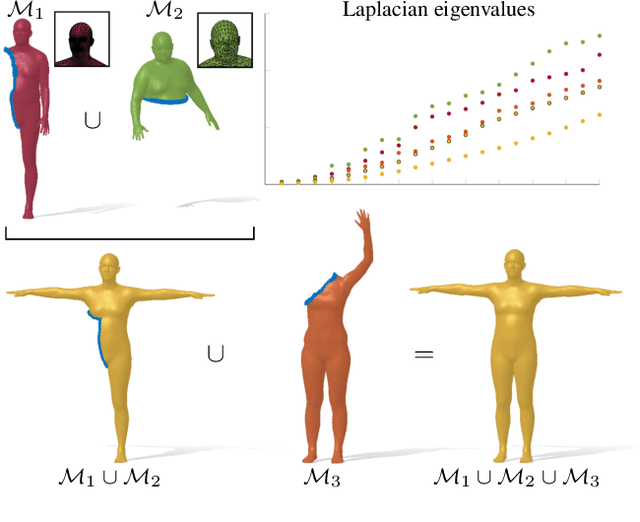

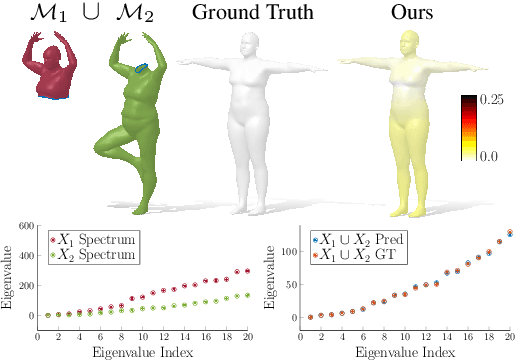
Spectral geometric methods have brought revolutionary changes to the field of geometry processing -- however, when the data to be processed exhibits severe partiality, such methods fail to generalize. As a result, there exists a big performance gap between methods dealing with complete shapes, and methods that address missing geometry. In this paper, we propose a possible way to fill this gap. We introduce the first method to compute compositions of non-rigidly deforming shapes, without requiring to solve first for a dense correspondence between the given partial shapes. We do so by operating in a purely spectral domain, where we define a union operation between short sequences of eigenvalues. Working with eigenvalues allows to deal with unknown correspondence, different sampling, and different discretization (point clouds and meshes alike), making this operation especially robust and general. Our approach is data-driven, and can generalize to isometric and non-isometric deformations of the surface, as long as these stay within the same semantic class (e.g., human bodies), as well as to partiality artifacts not seen at training time.
Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels
Mar 25, 2021
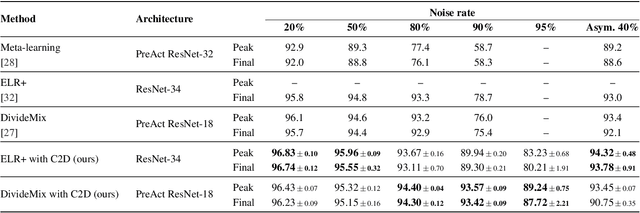
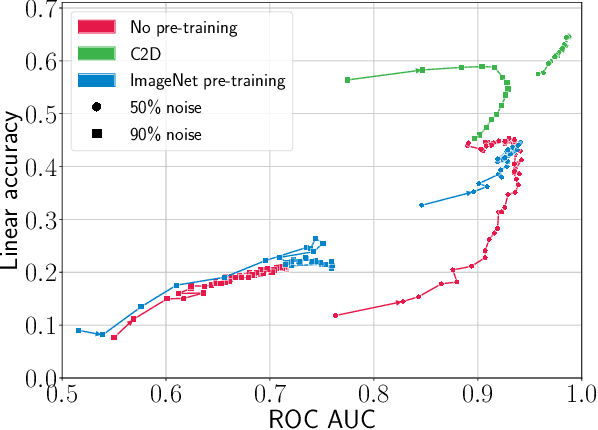
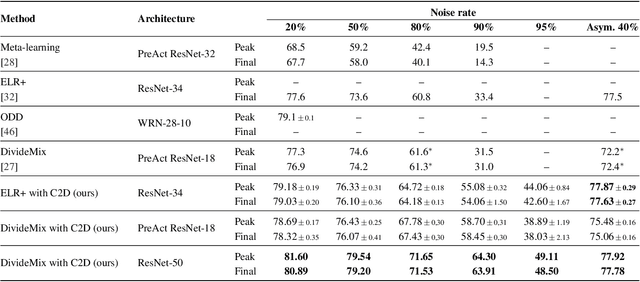
The success of learning with noisy labels (LNL) methods relies heavily on the success of a warm-up stage where standard supervised training is performed using the full (noisy) training set. In this paper, we identify a "warm-up obstacle": the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels. We propose "Contrast to Divide" (C2D), a simple framework that solves this problem by pre-training the feature extractor in a self-supervised fashion. Using self-supervised pre-training boosts the performance of existing LNL approaches by drastically reducing the warm-up stage's susceptibility to noise level, shortening its duration, and increasing extracted feature quality. C2D works out of the box with existing methods and demonstrates markedly improved performance, especially in the high noise regime, where we get a boost of more than 27% for CIFAR-100 with 90% noise over the previous state of the art. In real-life noise settings, C2D trained on mini-WebVision outperforms previous works both in WebVision and ImageNet validation sets by 3% top-1 accuracy. We perform an in-depth analysis of the framework, including investigating the performance of different pre-training approaches and estimating the effective upper bound of the LNL performance with semi-supervised learning. Code for reproducing our experiments is available at https://github.com/ContrastToDivide/C2D
Weakly Supervised Learning of Rigid 3D Scene Flow
Feb 17, 2021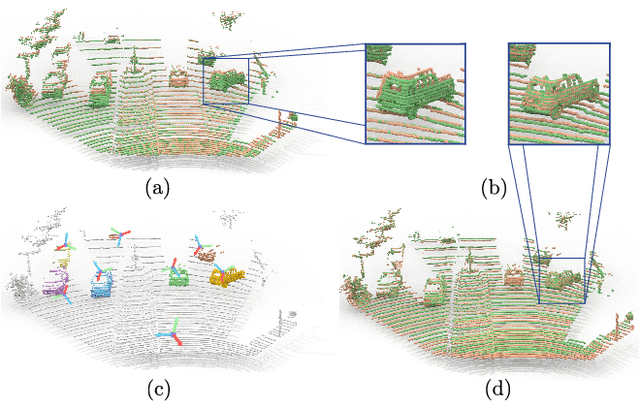
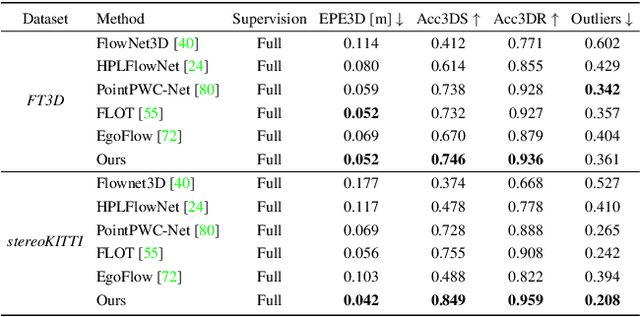
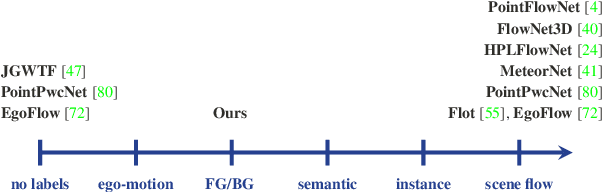
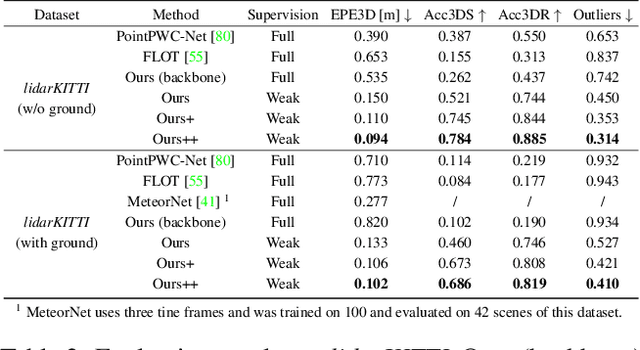
We propose a data-driven scene flow estimation algorithm exploiting the observation that many 3D scenes can be explained by a collection of agents moving as rigid bodies. At the core of our method lies a deep architecture able to reason at the \textbf{object-level} by considering 3D scene flow in conjunction with other 3D tasks. This object level abstraction, enables us to relax the requirement for dense scene flow supervision with simpler binary background segmentation mask and ego-motion annotations. Our mild supervision requirements make our method well suited for recently released massive data collections for autonomous driving, which do not contain dense scene flow annotations. As output, our model provides low-level cues like pointwise flow and higher-level cues such as holistic scene understanding at the level of rigid objects. We further propose a test-time optimization refining the predicted rigid scene flow. We showcase the effectiveness and generalization capacity of our method on four different autonomous driving datasets. We release our source code and pre-trained models under \url{github.com/zgojcic/Rigid3DSceneFlow}.
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021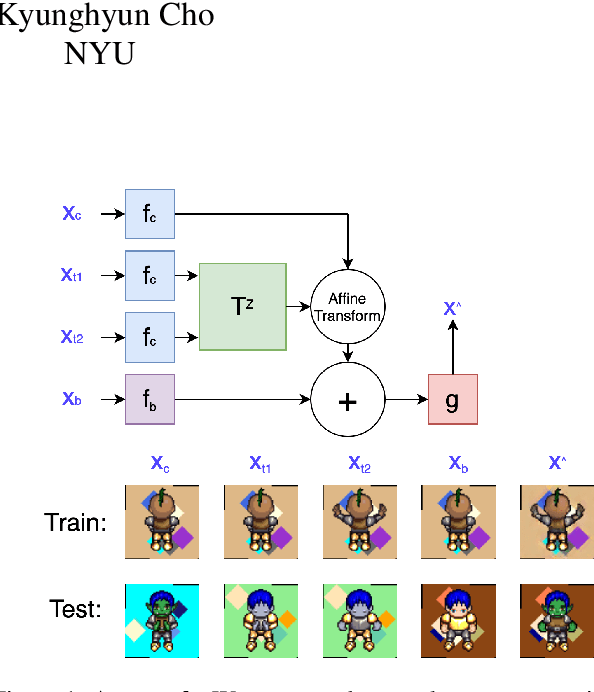
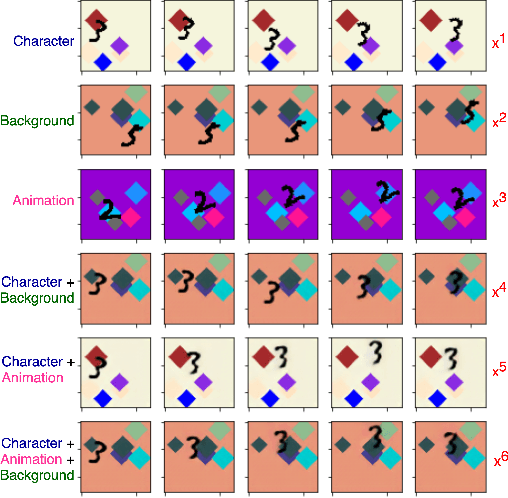
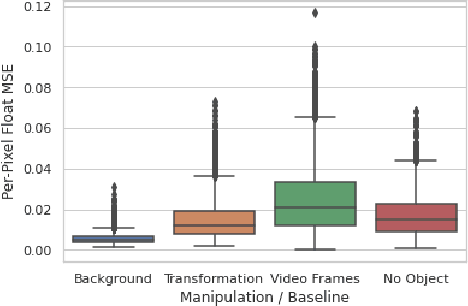
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
Human 3D keypoints via spatial uncertainty modeling
Dec 18, 2020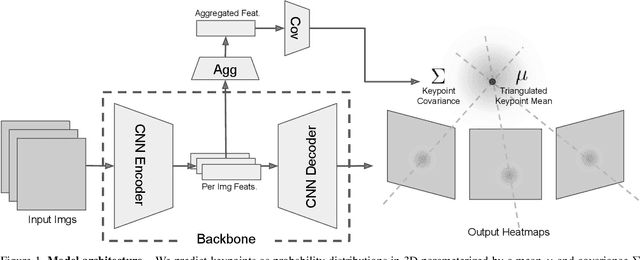
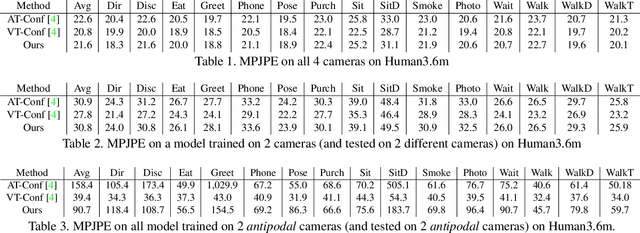

We introduce a technique for 3D human keypoint estimation that directly models the notion of spatial uncertainty of a keypoint. Our technique employs a principled approach to modelling spatial uncertainty inspired from techniques in robust statistics. Furthermore, our pipeline requires no 3D ground truth labels, relying instead on (possibly noisy) 2D image-level keypoints. Our method achieves near state-of-the-art performance on Human3.6m while being efficient to evaluate and straightforward to
3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection
Dec 08, 2020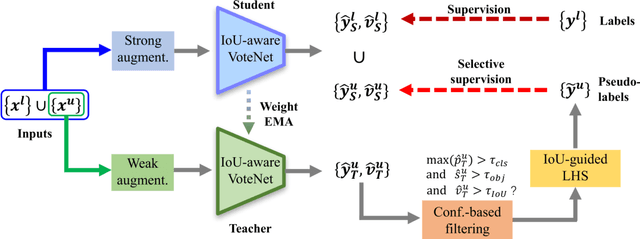
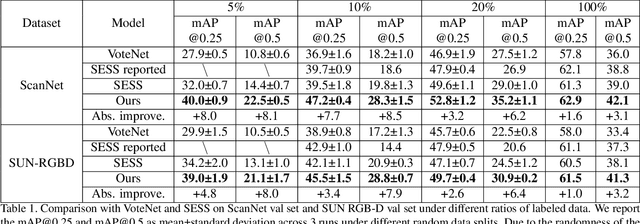
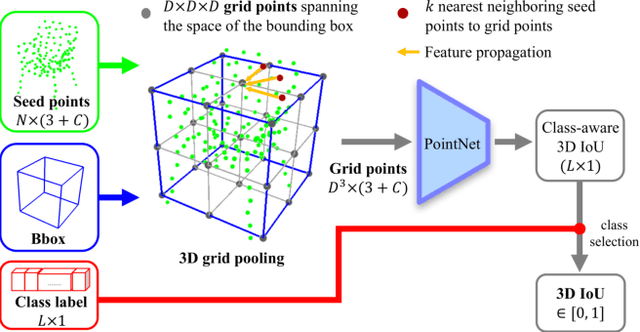
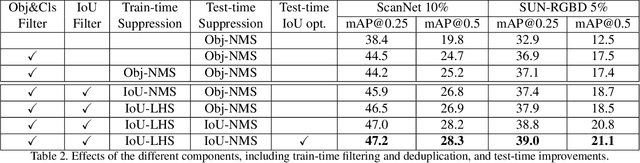
3D object detection is an important yet demanding task that heavily relies on difficult to obtain 3D annotations. To reduce the required amount of supervision, we propose 3DIoUMatch, a novel method for semi-supervised 3D object detection. We adopt VoteNet, a popular point cloud-based object detector, as our backbone and leverage a teacher-student mutual learning framework to propagate information from the labeled to the unlabeled train set in the form of pseudo-labels. However, due to the high task complexity, we observe that the pseudo-labels suffer from significant noise and are thus not directly usable. To that end, we introduce a confidence-based filtering mechanism. The key to our approach is a novel differentiable 3D IoU estimation module. This module is used for filtering poorly localized proposals as well as for IoU-guided bounding box deduplication. At inference time, this module is further utilized to improve localization through test-time optimization. Our method consistently improves state-of-the-art methods on both ScanNet and SUN-RGBD benchmarks by significant margins. For example, when training using only 10\% labeled data on ScanNet, 3DIoUMatch achieves 7.7 absolute improvement on mAP@0.25 and 8.5 absolute improvement on mAP@0.5 upon the prior art.