 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
May 02, 2019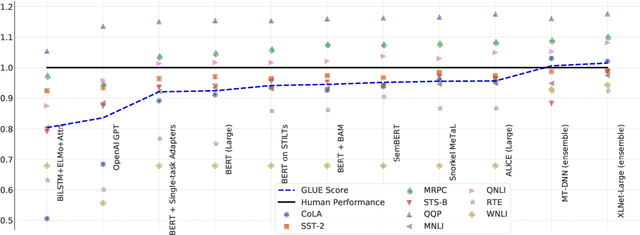
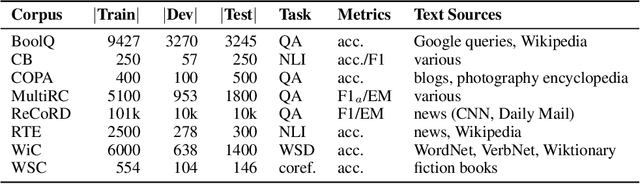

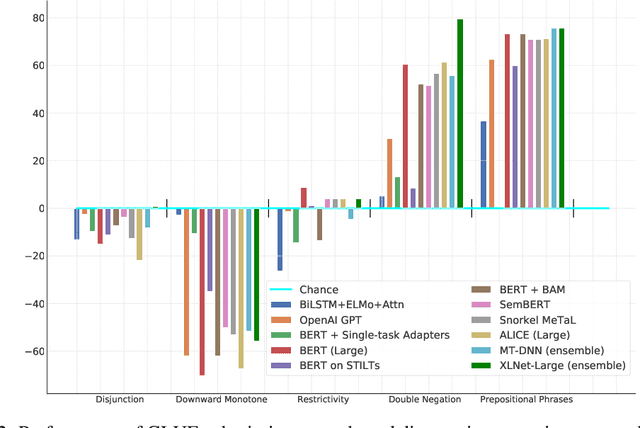
In the last year, new models and methods for pretraining and transfer learning have driven striking performance improvements across a range of language understanding tasks. The GLUE benchmark, introduced one year ago, offers a single-number metric that summarizes progress on a diverse set of such tasks, but performance on the benchmark has recently come close to the level of non-expert humans, suggesting limited headroom for further research. This paper recaps lessons learned from the GLUE benchmark and presents SuperGLUE, a new benchmark styled after GLUE with a new set of more difficult language understanding tasks, improved resources, and a new public leaderboard. SuperGLUE will be available soon at super.gluebenchmark.com.
Constant-Time Machine Translation with Conditional Masked Language Models
Apr 19, 2019
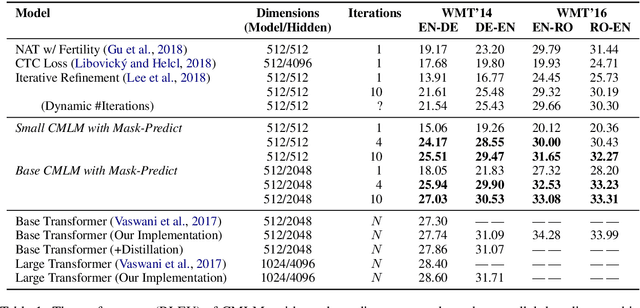
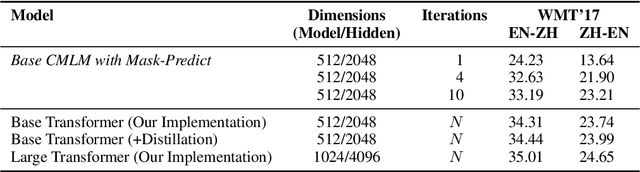
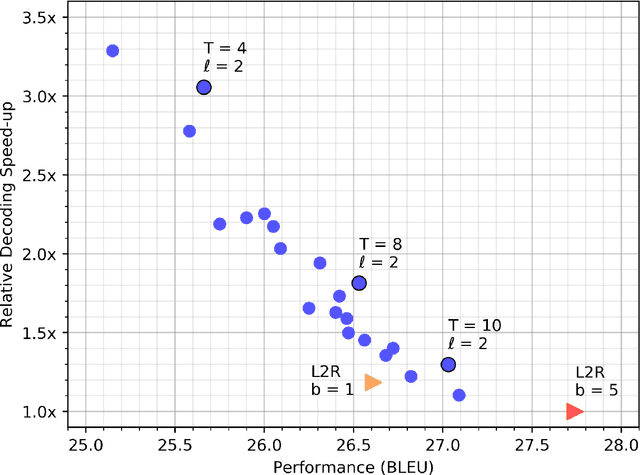
Most machine translation systems generate text autoregressively, by sequentially predicting tokens from left to right. We, instead, use a masked language modeling objective to train a model to predict any subset of the target words, conditioned on both the input text and a partially masked target translation. This approach allows for efficient iterative decoding, where we first predict all of the target words non-autoregressively, and then repeatedly mask out and regenerate the subset of words that the model is least confident about. By applying this strategy for a constant number of iterations, our model improves state-of-the-art performance levels for constant-time translation models by over 3 BLEU on average. It is also able to reach 92-95% of the performance of a typical left-to-right transformer model, while decoding significantly faster.
Training on Synthetic Noise Improves Robustness to Natural Noise in Machine Translation
Feb 05, 2019
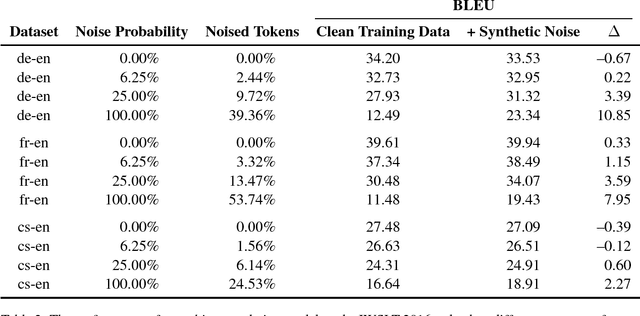
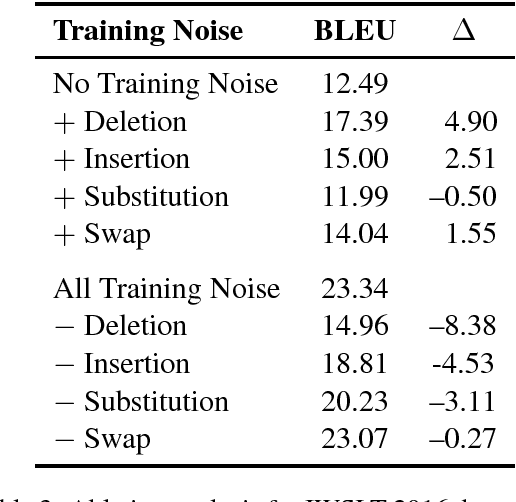

We consider the problem of making machine translation more robust to character-level variation at the source side, such as typos. Existing methods achieve greater coverage by applying subword models such as byte-pair encoding (BPE) and character-level encoders, but these methods are highly sensitive to spelling mistakes. We show how training on a mild amount of random synthetic noise can dramatically improve robustness to these variations, without diminishing performance on clean text. We focus on translation performance on natural noise, as captured by frequent corrections in Wikipedia edit logs, and show that robustness to such noise can be achieved using a balanced diet of simple synthetic noises at training time, without access to the natural noise data or distribution.
code2vec: Learning Distributed Representations of Code
Oct 30, 2018

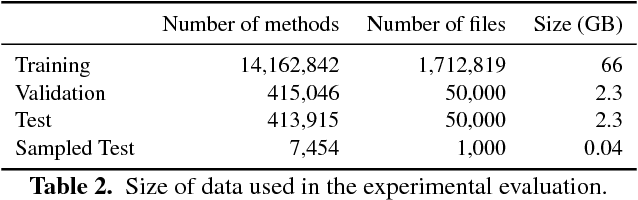
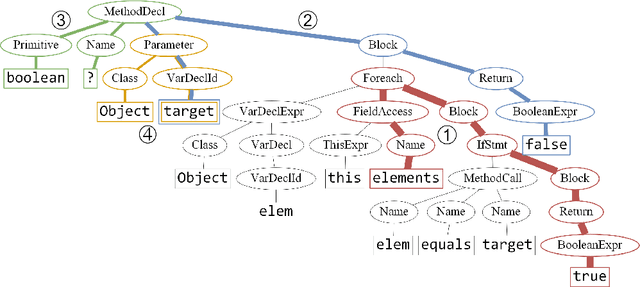
We present a neural model for representing snippets of code as continuous distributed vectors ("code embeddings"). The main idea is to represent a code snippet as a single fixed-length $\textit{code vector}$, which can be used to predict semantic properties of the snippet. This is performed by decomposing code to a collection of paths in its abstract syntax tree, and learning the atomic representation of each path $\textit{simultaneously}$ with learning how to aggregate a set of them. We demonstrate the effectiveness of our approach by using it to predict a method's name from the vector representation of its body. We evaluate our approach by training a model on a dataset of 14M methods. We show that code vectors trained on this dataset can predict method names from files that were completely unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies. Comparing previous techniques over the same data set, our approach obtains a relative improvement of over 75%, being the first to successfully predict method names based on a large, cross-project, corpus. Our trained model, visualizations and vector similarities are available as an interactive online demo at http://code2vec.org. The code, data, and trained models are available at https://github.com/tech-srl/code2vec.
pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference
Oct 20, 2018
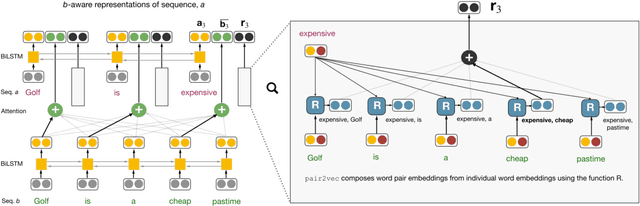

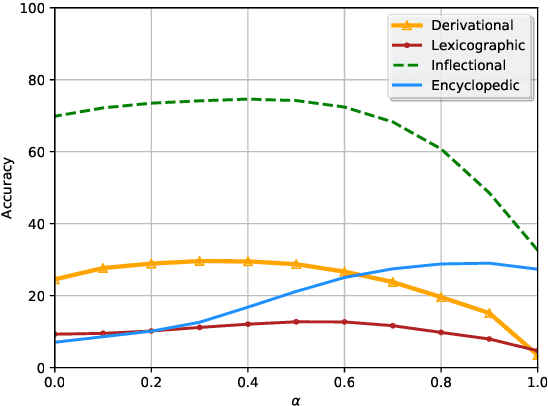
Reasoning about implied relationships (e.g. paraphrastic, common sense, encyclopedic) between pairs of words is crucial for many cross-sentence inference problems. This paper proposes new methods for learning and using embeddings of word pairs that implicitly represent background knowledge about such relationships. Our pairwise embeddings are computed as a compositional function of each word's representation, which is learned by maximizing the pointwise mutual information (PMI) with the contexts in which the the two words co-occur. We add these representations to the cross-sentence attention layer of existing inference models (e.g. BiDAF for QA, ESIM for NLI), instead of extending or replacing existing word embeddings. Experiments show a gain of 2.72% on the recently released SQuAD 2.0 and 1.3% on MultiNLI. Our representations also aid in better generalization with gains of around 6-7% on adversarial SQuAD datasets, and 8.8% on the adversarial entailment test set by Glockner et al.
code2seq: Generating Sequences from Structured Representations of Code
Oct 10, 2018
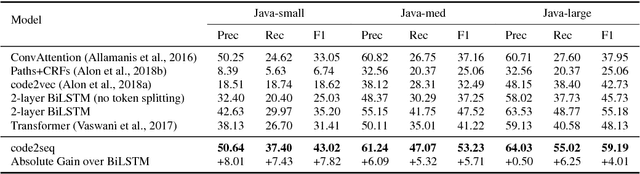
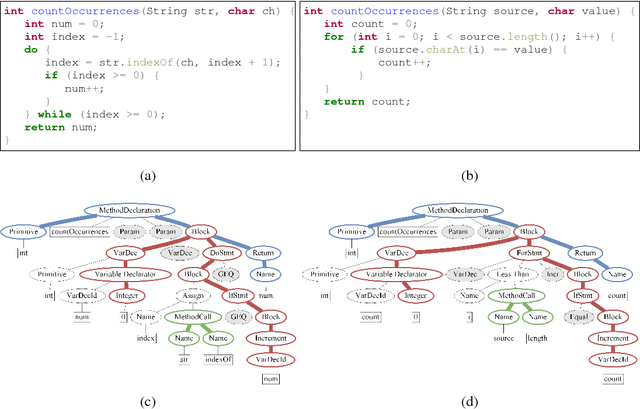
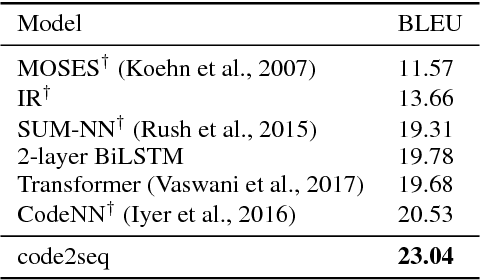
The ability to generate natural language sequences from source code snippets has a variety of applications such as code summarization, documentation, and retrieval. Sequence-to-sequence (seq2seq) models, adopted from neural machine translation (NMT), have achieved state-of-the-art performance on these tasks by treating source code as a sequence of tokens. We present ${\rm {\scriptsize CODE2SEQ}}$: an alternative approach that leverages the syntactic structure of programming languages to better encode source code. Our model represents a code snippet as the set of compositional paths in its abstract syntax tree (AST) and uses attention to select the relevant paths while decoding. We demonstrate the effectiveness of our approach for two tasks, two programming languages, and four datasets of up to $16$M examples. Our model significantly outperforms previous models that were specifically designed for programming languages, as well as state-of-the-art NMT models.
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Sep 18, 2018
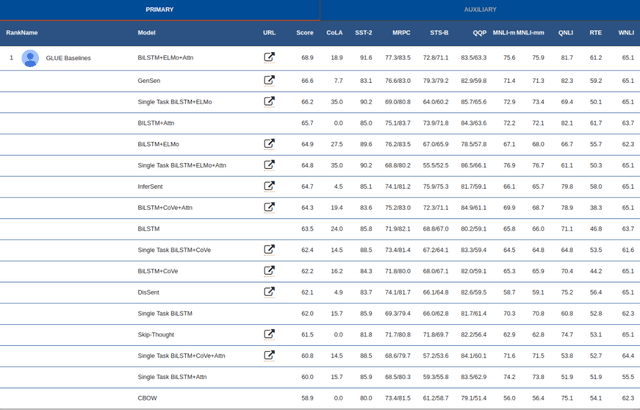
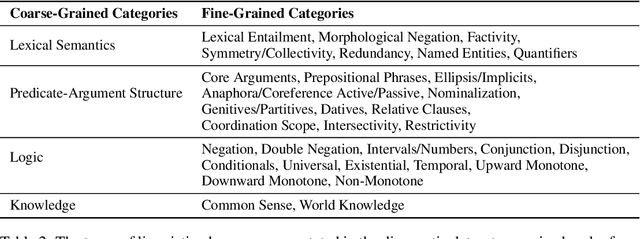
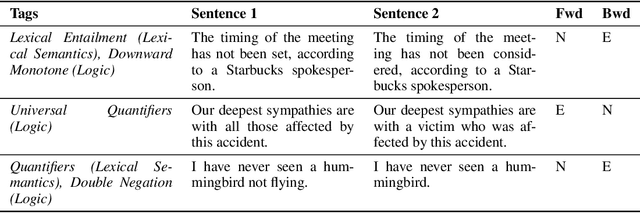
For natural language understanding (NLU) technology to be maximally useful, both practically and as a scientific object of study, it must be general: it must be able to process language in a way that is not exclusively tailored to any one specific task or dataset. In pursuit of this objective, we introduce the General Language Understanding Evaluation benchmark (GLUE), a tool for evaluating and analyzing the performance of models across a diverse range of existing NLU tasks. GLUE is model-agnostic, but it incentivizes sharing knowledge across tasks because certain tasks have very limited training data. We further provide a hand-crafted diagnostic test suite that enables detailed linguistic analysis of NLU models. We evaluate baselines based on current methods for multi-task and transfer learning and find that they do not immediately give substantial improvements over the aggregate performance of training a separate model per task, indicating room for improvement in developing general and robust NLU systems.
Jointly Predicting Predicates and Arguments in Neural Semantic Role Labeling
Aug 13, 2018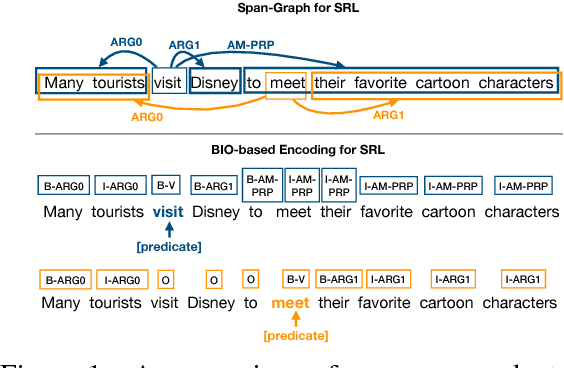

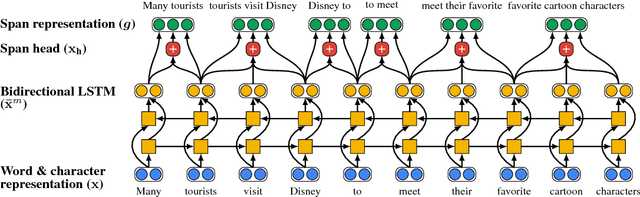
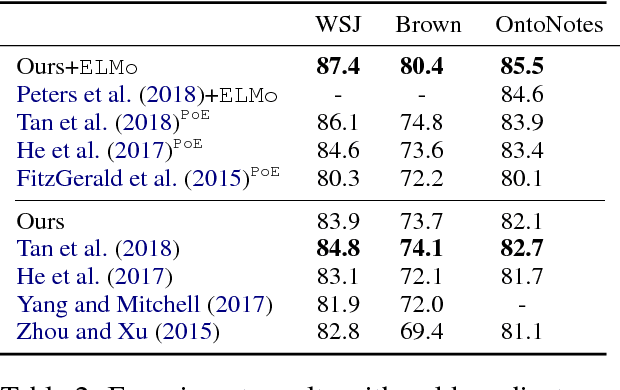
Recent BIO-tagging-based neural semantic role labeling models are very high performing, but assume gold predicates as part of the input and cannot incorporate span-level features. We propose an end-to-end approach for jointly predicting all predicates, arguments spans, and the relations between them. The model makes independent decisions about what relationship, if any, holds between every possible word-span pair, and learns contextualized span representations that provide rich, shared input features for each decision. Experiments demonstrate that this approach sets a new state of the art on PropBank SRL without gold predicates.
Ultra-Fine Entity Typing
Jul 13, 2018
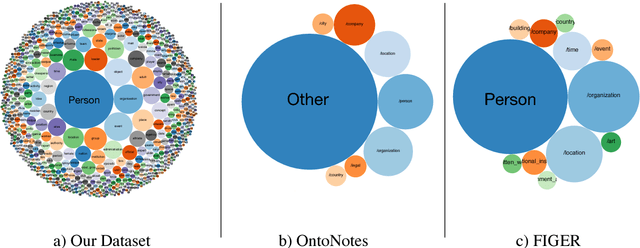
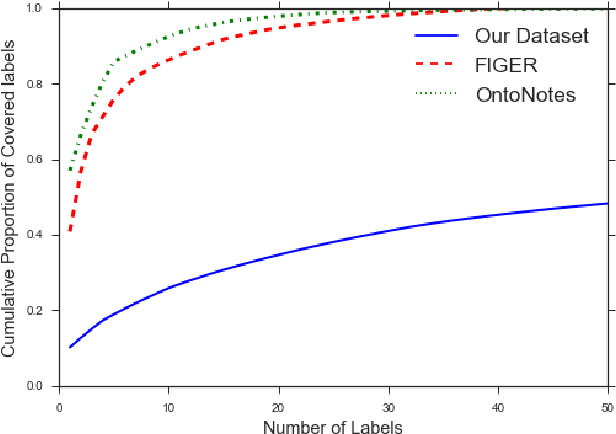

We introduce a new entity typing task: given a sentence with an entity mention, the goal is to predict a set of free-form phrases (e.g. skyscraper, songwriter, or criminal) that describe appropriate types for the target entity. This formulation allows us to use a new type of distant supervision at large scale: head words, which indicate the type of the noun phrases they appear in. We show that these ultra-fine types can be crowd-sourced, and introduce new evaluation sets that are much more diverse and fine-grained than existing benchmarks. We present a model that can predict open types, and is trained using a multitask objective that pools our new head-word supervision with prior supervision from entity linking. Experimental results demonstrate that our model is effective in predicting entity types at varying granularity; it achieves state of the art performance on an existing fine-grained entity typing benchmark, and sets baselines for our newly-introduced datasets. Our data and model can be downloaded from: http://nlp.cs.washington.edu/entity_type
LSTMs Exploit Linguistic Attributes of Data
May 29, 2018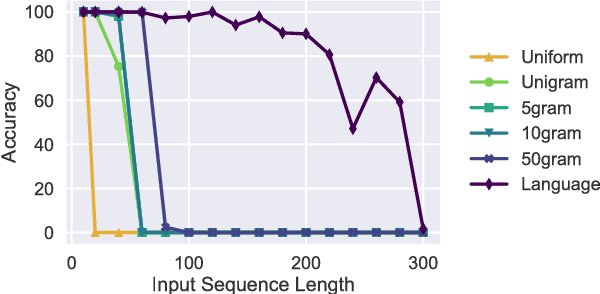
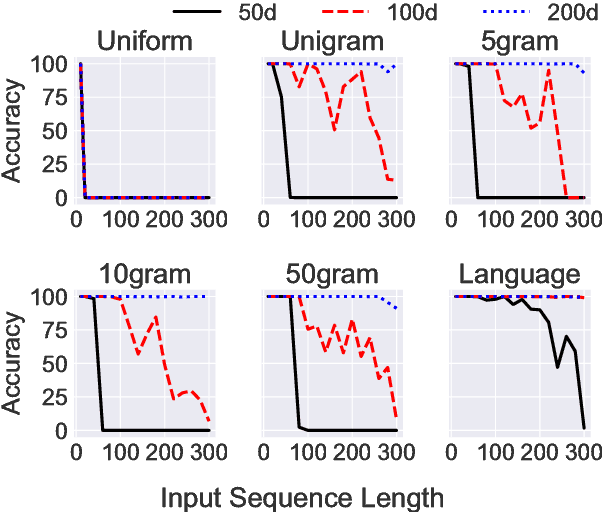
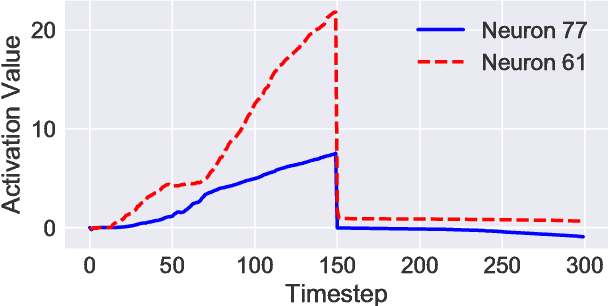
While recurrent neural networks have found success in a variety of natural language processing applications, they are general models of sequential data. We investigate how the properties of natural language data affect an LSTM's ability to learn a nonlinguistic task: recalling elements from its input. We find that models trained on natural language data are able to recall tokens from much longer sequences than models trained on non-language sequential data. Furthermore, we show that the LSTM learns to solve the memorization task by explicitly using a subset of its neurons to count timesteps in the input. We hypothesize that the patterns and structure in natural language data enable LSTMs to learn by providing approximate ways of reducing loss, but understanding the effect of different training data on the learnability of LSTMs remains an open question.