 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecode2vec: Learning Distributed Representations of Code
Oct 30, 2018

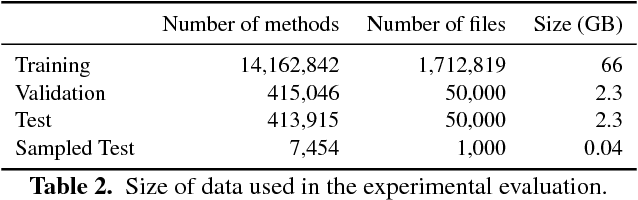
We present a neural model for representing snippets of code as continuous distributed vectors ("code embeddings"). The main idea is to represent a code snippet as a single fixed-length $\textit{code vector}$, which can be used to predict semantic properties of the snippet. This is performed by decomposing code to a collection of paths in its abstract syntax tree, and learning the atomic representation of each path $\textit{simultaneously}$ with learning how to aggregate a set of them. We demonstrate the effectiveness of our approach by using it to predict a method's name from the vector representation of its body. We evaluate our approach by training a model on a dataset of 14M methods. We show that code vectors trained on this dataset can predict method names from files that were completely unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies. Comparing previous techniques over the same data set, our approach obtains a relative improvement of over 75%, being the first to successfully predict method names based on a large, cross-project, corpus. Our trained model, visualizations and vector similarities are available as an interactive online demo at http://code2vec.org. The code, data, and trained models are available at https://github.com/tech-srl/code2vec.
A General Path-Based Representation for Predicting Program Properties
Apr 22, 2018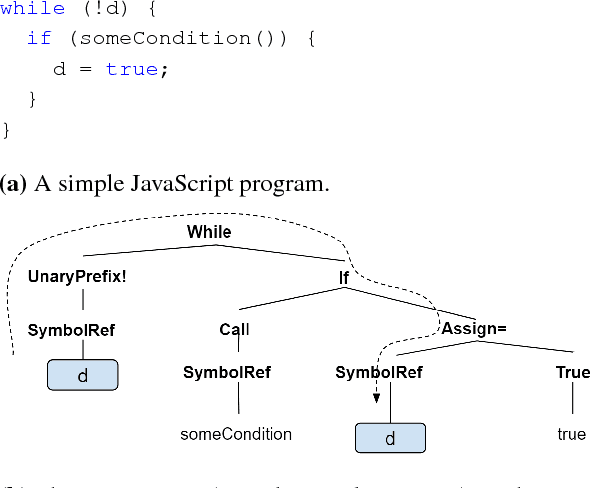
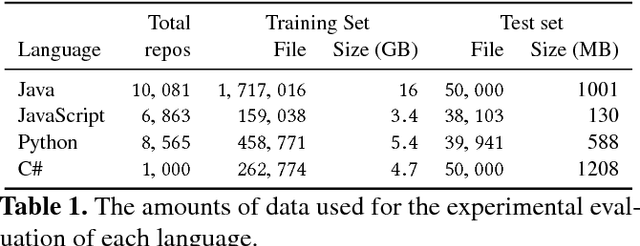
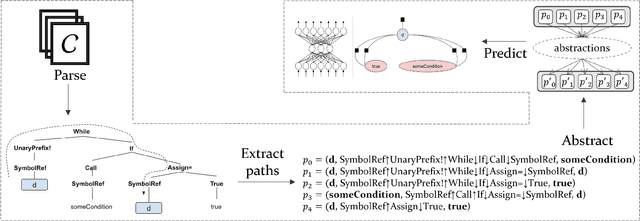
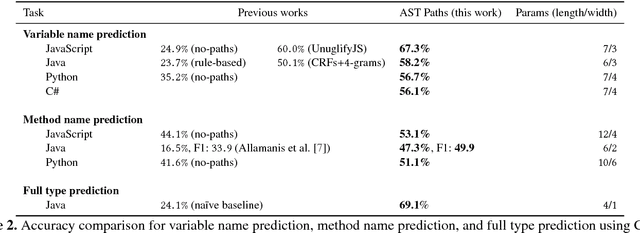
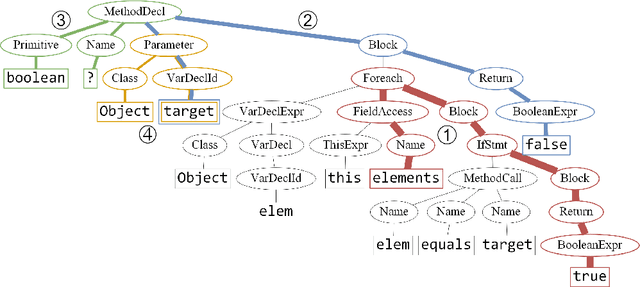
Predicting program properties such as names or expression types has a wide range of applications. It can ease the task of programming and increase programmer productivity. A major challenge when learning from programs is $\textit{how to represent programs in a way that facilitates effective learning}$. We present a $\textit{general path-based representation}$ for learning from programs. Our representation is purely syntactic and extracted automatically. The main idea is to represent a program using paths in its abstract syntax tree (AST). This allows a learning model to leverage the structured nature of code rather than treating it as a flat sequence of tokens. We show that this representation is general and can: (i) cover different prediction tasks, (ii) drive different learning algorithms (for both generative and discriminative models), and (iii) work across different programming languages. We evaluate our approach on the tasks of predicting variable names, method names, and full types. We use our representation to drive both CRF-based and word2vec-based learning, for programs of four languages: JavaScript, Java, Python and C\#. Our evaluation shows that our approach obtains better results than task-specific handcrafted representations across different tasks and programming languages.