 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Do What Doesn't Matter: Intrinsic Motivation with Action Usefulness
May 31, 2021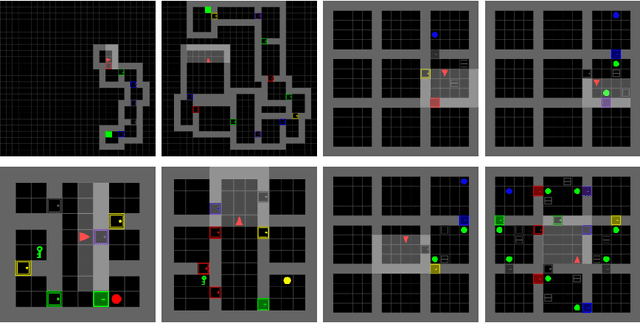
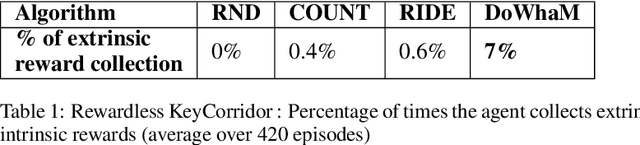
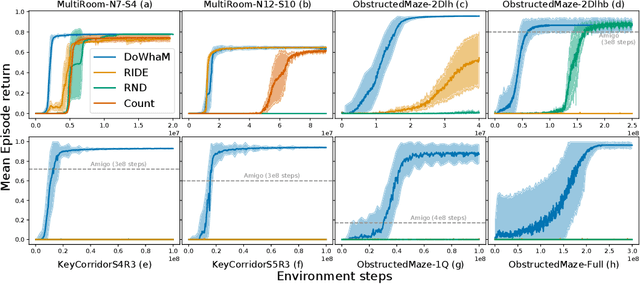
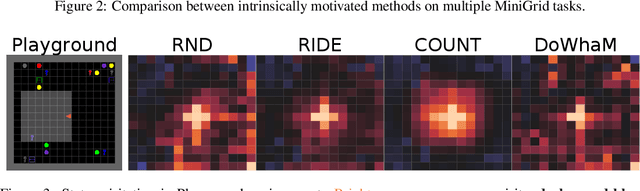
Sparse rewards are double-edged training signals in reinforcement learning: easy to design but hard to optimize. Intrinsic motivation guidances have thus been developed toward alleviating the resulting exploration problem. They usually incentivize agents to look for new states through novelty signals. Yet, such methods encourage exhaustive exploration of the state space rather than focusing on the environment's salient interaction opportunities. We propose a new exploration method, called Don't Do What Doesn't Matter (DoWhaM), shifting the emphasis from state novelty to state with relevant actions. While most actions consistently change the state when used, \textit{e.g.} moving the agent, some actions are only effective in specific states, \textit{e.g.}, \emph{opening} a door, \emph{grabbing} an object. DoWhaM detects and rewards actions that seldom affect the environment. We evaluate DoWhaM on the procedurally-generated environment MiniGrid, against state-of-the-art methods and show that DoWhaM greatly reduces sample complexity.
Hyperparameter Selection for Imitation Learning
May 25, 2021
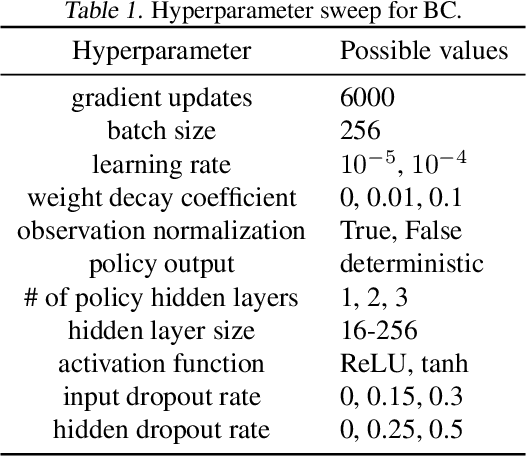
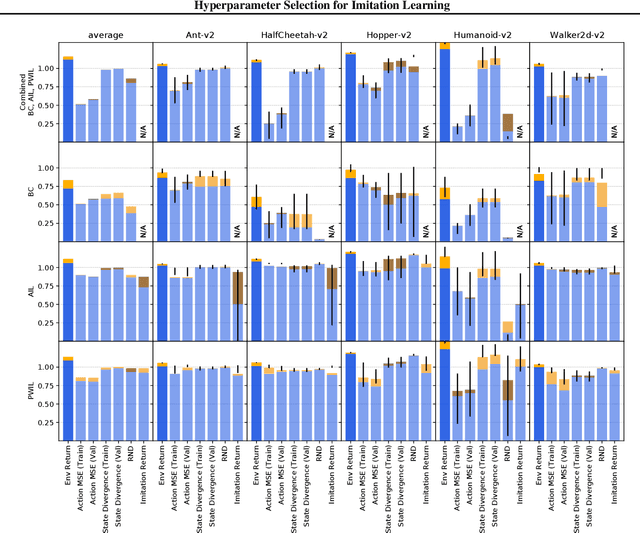
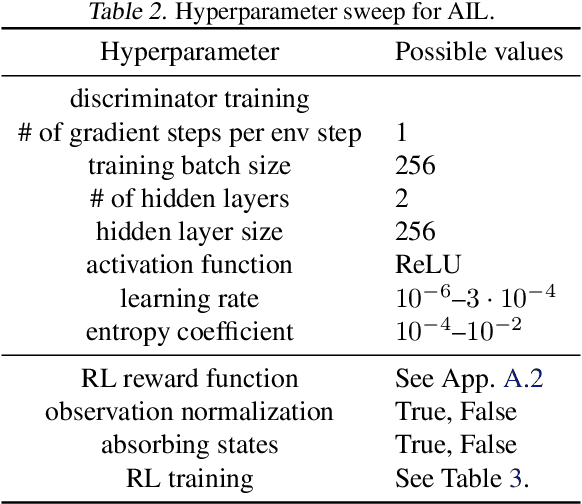
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
Mean Field Games Flock! The Reinforcement Learning Way
May 17, 2021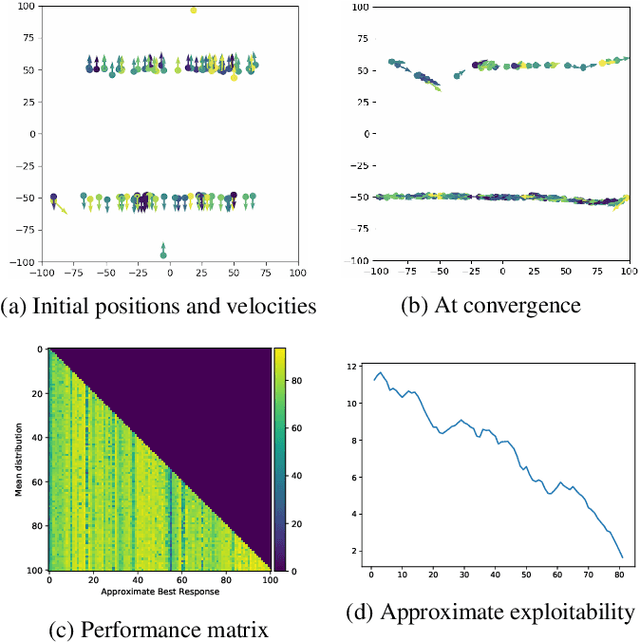
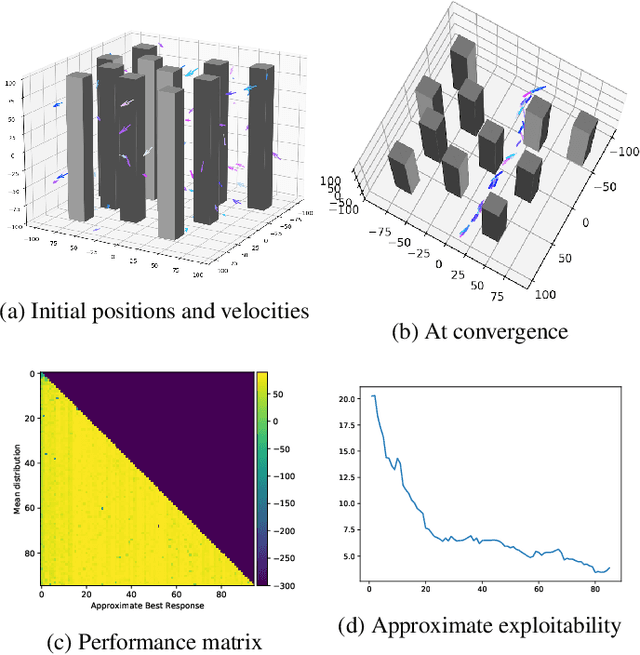
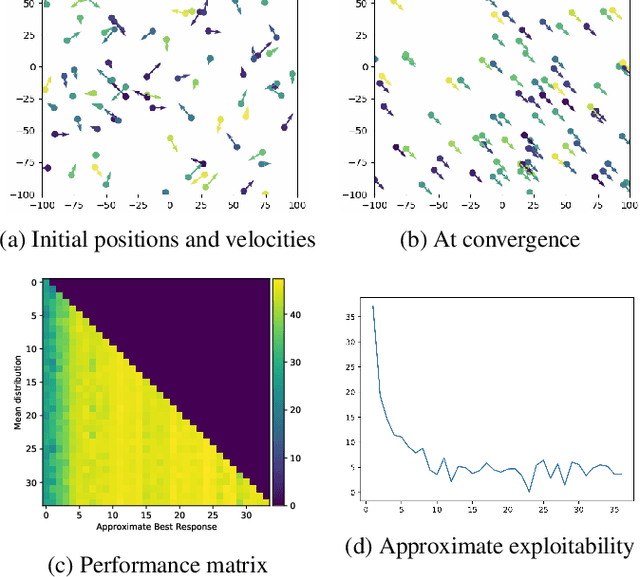
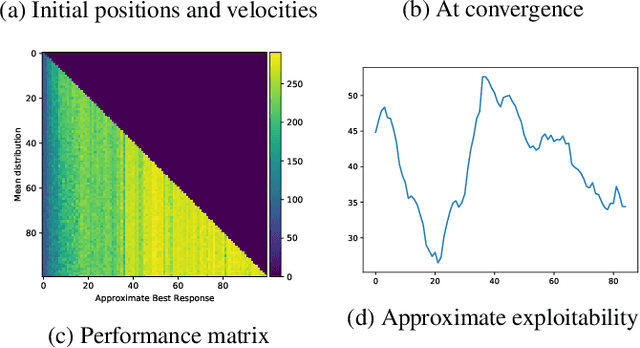
We present a method enabling a large number of agents to learn how to flock, which is a natural behavior observed in large populations of animals. This problem has drawn a lot of interest but requires many structural assumptions and is tractable only in small dimensions. We phrase this problem as a Mean Field Game (MFG), where each individual chooses its acceleration depending on the population behavior. Combining Deep Reinforcement Learning (RL) and Normalizing Flows (NF), we obtain a tractable solution requiring only very weak assumptions. Our algorithm finds a Nash Equilibrium and the agents adapt their velocity to match the neighboring flock's average one. We use Fictitious Play and alternate: (1) computing an approximate best response with Deep RL, and (2) estimating the next population distribution with NF. We show numerically that our algorithm learn multi-group or high-dimensional flocking with obstacles.
Offline Reinforcement Learning with Pseudometric Learning
Mar 02, 2021
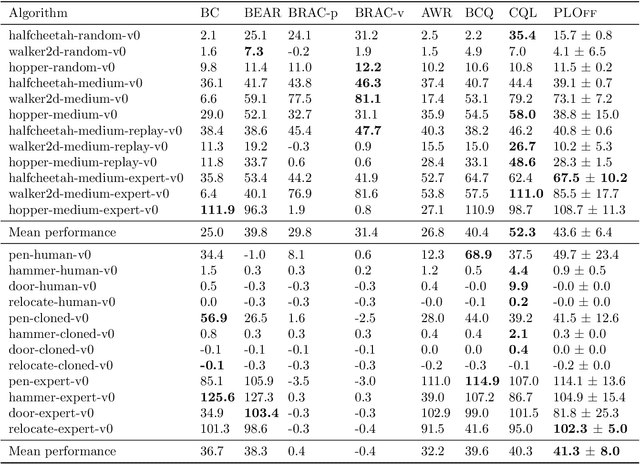

Offline Reinforcement Learning methods seek to learn a policy from logged transitions of an environment, without any interaction. In the presence of function approximation, and under the assumption of limited coverage of the state-action space of the environment, it is necessary to enforce the policy to visit state-action pairs close to the support of logged transitions. In this work, we propose an iterative procedure to learn a pseudometric (closely related to bisimulation metrics) from logged transitions, and use it to define this notion of closeness. We show its convergence and extend it to the function approximation setting. We then use this pseudometric to define a new lookup based bonus in an actor-critic algorithm: PLOff. This bonus encourages the actor to stay close, in terms of the defined pseudometric, to the support of logged transitions. Finally, we evaluate the method on hand manipulation and locomotion tasks.
Scaling up Mean Field Games with Online Mirror Descent
Feb 28, 2021
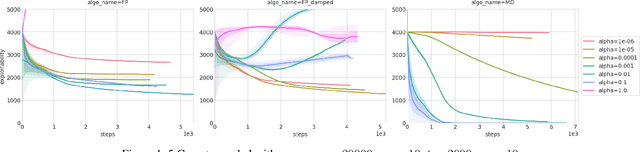

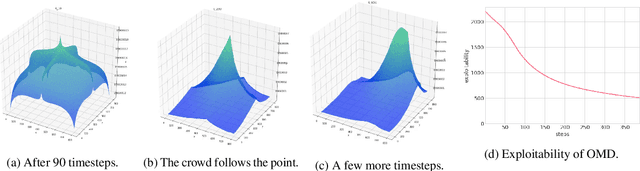
We address scaling up equilibrium computation in Mean Field Games (MFGs) using Online Mirror Descent (OMD). We show that continuous-time OMD provably converges to a Nash equilibrium under a natural and well-motivated set of monotonicity assumptions. This theoretical result nicely extends to multi-population games and to settings involving common noise. A thorough experimental investigation on various single and multi-population MFGs shows that OMD outperforms traditional algorithms such as Fictitious Play (FP). We empirically show that OMD scales up and converges significantly faster than FP by solving, for the first time to our knowledge, examples of MFGs with hundreds of billions states. This study establishes the state-of-the-art for learning in large-scale multi-agent and multi-population games.
Adversarially Guided Actor-Critic
Feb 08, 2021
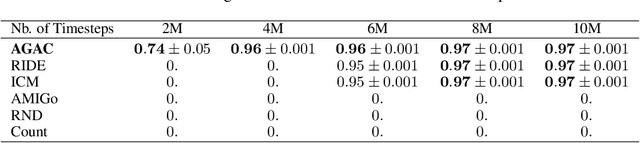
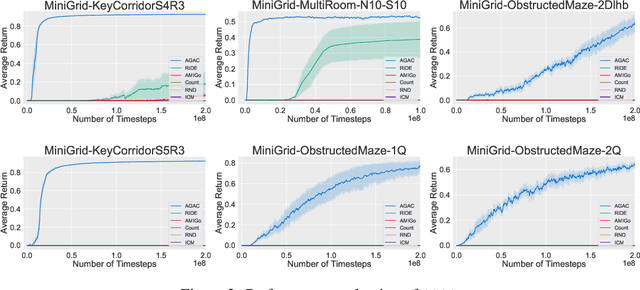

Despite definite success in deep reinforcement learning problems, actor-critic algorithms are still confronted with sample inefficiency in complex environments, particularly in tasks where efficient exploration is a bottleneck. These methods consider a policy (the actor) and a value function (the critic) whose respective losses are built using different motivations and approaches. This paper introduces a third protagonist: the adversary. While the adversary mimics the actor by minimizing the KL-divergence between their respective action distributions, the actor, in addition to learning to solve the task, tries to differentiate itself from the adversary predictions. This novel objective stimulates the actor to follow strategies that could not have been correctly predicted from previous trajectories, making its behavior innovative in tasks where the reward is extremely rare. Our experimental analysis shows that the resulting Adversarially Guided Actor-Critic (AGAC) algorithm leads to more exhaustive exploration. Notably, AGAC outperforms current state-of-the-art methods on a set of various hard-exploration and procedurally-generated tasks.
Self-Imitation Advantage Learning
Dec 22, 2020
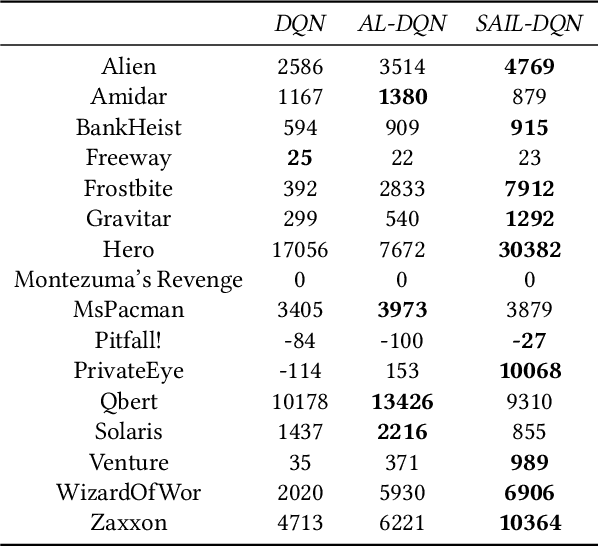
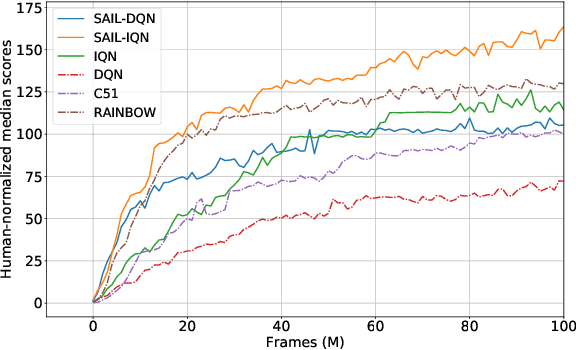
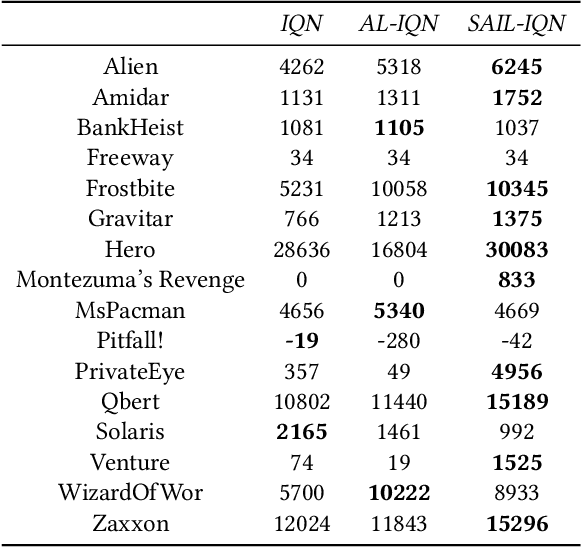
Self-imitation learning is a Reinforcement Learning (RL) method that encourages actions whose returns were higher than expected, which helps in hard exploration and sparse reward problems. It was shown to improve the performance of on-policy actor-critic methods in several discrete control tasks. Nevertheless, applying self-imitation to the mostly action-value based off-policy RL methods is not straightforward. We propose SAIL, a novel generalization of self-imitation learning for off-policy RL, based on a modification of the Bellman optimality operator that we connect to Advantage Learning. Crucially, our method mitigates the problem of stale returns by choosing the most optimistic return estimate between the observed return and the current action-value for self-imitation. We demonstrate the empirical effectiveness of SAIL on the Arcade Learning Environment, with a focus on hard exploration games.
Learning from Heterogeneous EEG Signals with Differentiable Channel Reordering
Oct 21, 2020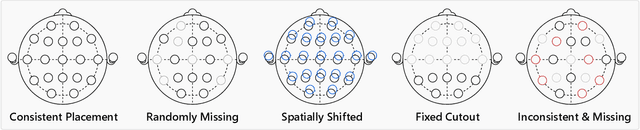
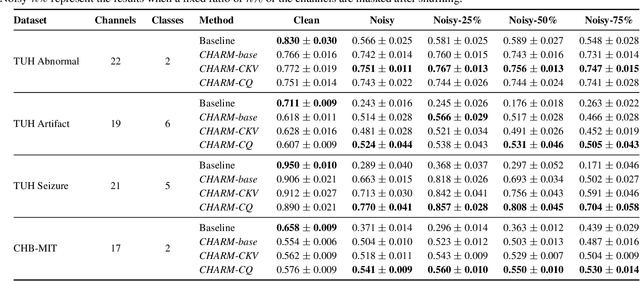
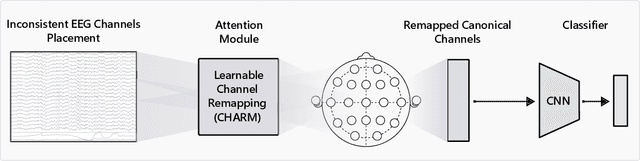
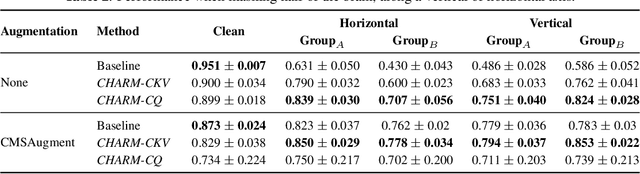
We propose CHARM, a method for training a single neural network across inconsistent input channels. Our work is motivated by Electroencephalography (EEG), where data collection protocols from different headsets result in varying channel ordering and number, which limits the feasibility of transferring trained systems across datasets. Our approach builds upon attention mechanisms to estimate a latent reordering matrix from each input signal and map input channels to a canonical order. CHARM is differentiable and can be composed further with architectures expecting a consistent channel ordering to build end-to-end trainable classifiers. We perform experiments on four EEG classification datasets and demonstrate the efficacy of CHARM via simulated shuffling and masking of input channels. Moreover, our method improves the transfer of pre-trained representations between datasets collected with different protocols.
Supervised Seeded Iterated Learning for Interactive Language Learning
Oct 06, 2020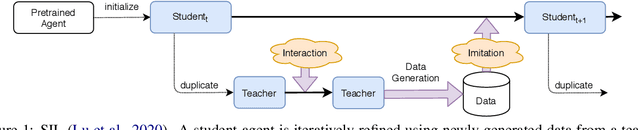
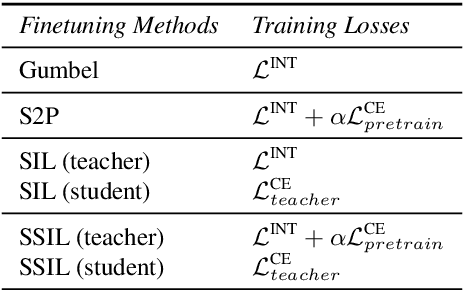
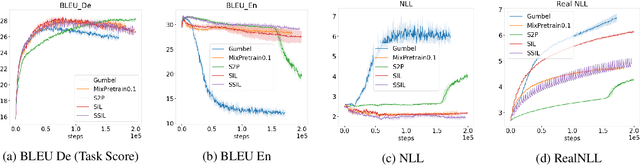
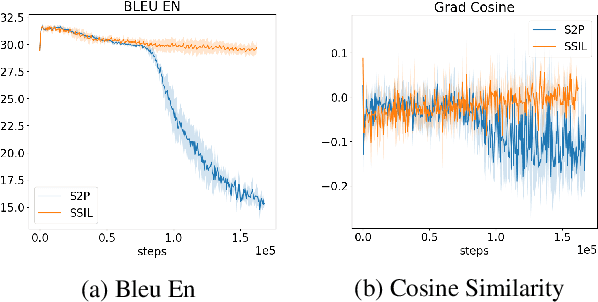
Language drift has been one of the major obstacles to train language models through interaction. When word-based conversational agents are trained towards completing a task, they tend to invent their language rather than leveraging natural language. In recent literature, two general methods partially counter this phenomenon: Supervised Selfplay (S2P) and Seeded Iterated Learning (SIL). While S2P jointly trains interactive and supervised losses to counter the drift, SIL changes the training dynamics to prevent language drift from occurring. In this paper, we first highlight their respective weaknesses, i.e., late-stage training collapses and higher negative likelihood when evaluated on human corpus. Given these observations, we introduce Supervised Seeded Iterated Learning to combine both methods to minimize their respective weaknesses. We then show the effectiveness of \algo in the language-drift translation game.
A Machine of Few Words -- Interactive Speaker Recognition with Reinforcement Learning
Aug 07, 2020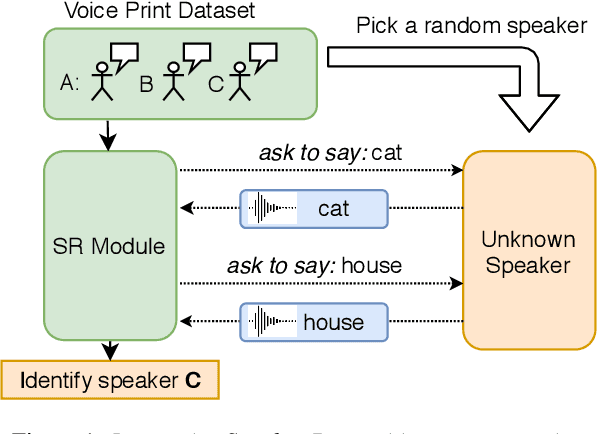
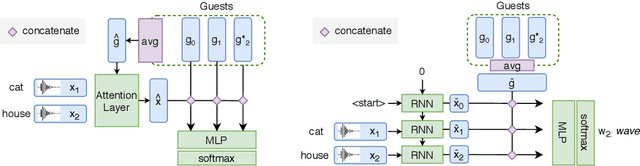
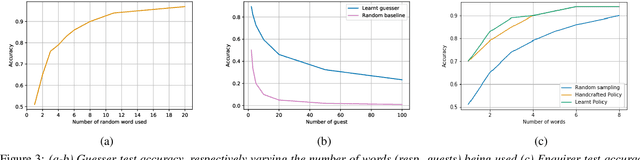
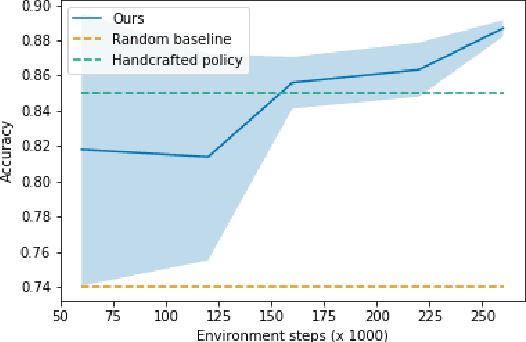
Speaker recognition is a well known and studied task in the speech processing domain. It has many applications, either for security or speaker adaptation of personal devices. In this paper, we present a new paradigm for automatic speaker recognition that we call Interactive Speaker Recognition (ISR). In this paradigm, the recognition system aims to incrementally build a representation of the speakers by requesting personalized utterances to be spoken in contrast to the standard text-dependent or text-independent schemes. To do so, we cast the speaker recognition task into a sequential decision-making problem that we solve with Reinforcement Learning. Using a standard dataset, we show that our method achieves excellent performance while using little speech signal amounts. This method could also be applied as an utterance selection mechanism for building speech synthesis systems.