 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoah D. Goodman
Procedural Dilemma Generation for Evaluating Moral Reasoning in Humans and Language Models
Apr 17, 2024
As AI systems like language models are increasingly integrated into decision-making processes affecting people's lives, it's critical to ensure that these systems have sound moral reasoning. To test whether they do, we need to develop systematic evaluations. We provide a framework that uses a language model to translate causal graphs that capture key aspects of moral dilemmas into prompt templates. With this framework, we procedurally generated a large and diverse set of moral dilemmas -- the OffTheRails benchmark -- consisting of 50 scenarios and 400 unique test items. We collected moral permissibility and intention judgments from human participants for a subset of our items and compared these judgments to those from two language models (GPT-4 and Claude-2) across eight conditions. We find that moral dilemmas in which the harm is a necessary means (as compared to a side effect) resulted in lower permissibility and higher intention ratings for both participants and language models. The same pattern was observed for evitable versus inevitable harmful outcomes. However, there was no clear effect of whether the harm resulted from an agent's action versus from having omitted to act. We discuss limitations of our prompt generation pipeline and opportunities for improving scenarios to increase the strength of experimental effects.
Stream of Search (SoS): Learning to Search in Language
Apr 01, 2024Language models are rarely shown fruitful mistakes while training. They then struggle to look beyond the next token, suffering from a snowballing of errors and struggling to predict the consequence of their actions several steps ahead. In this paper, we show how language models can be taught to search by representing the process of search in language, as a flattened string -- a stream of search (SoS). We propose a unified language for search that captures an array of different symbolic search strategies. We demonstrate our approach using the simple yet difficult game of Countdown, where the goal is to combine input numbers with arithmetic operations to reach a target number. We pretrain a transformer-based language model from scratch on a dataset of streams of search generated by heuristic solvers. We find that SoS pretraining increases search accuracy by 25% over models trained to predict only the optimal search trajectory. We further finetune this model with two policy improvement methods: Advantage-Induced Policy Alignment (APA) and Self-Taught Reasoner (STaR). The finetuned SoS models solve 36% of previously unsolved problems, including problems that cannot be solved by any of the heuristic solvers. Our results indicate that language models can learn to solve problems via search, self-improve to flexibly use different search strategies, and potentially discover new ones.
STaR-GATE: Teaching Language Models to Ask Clarifying Questions
Mar 29, 2024When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Mar 18, 2024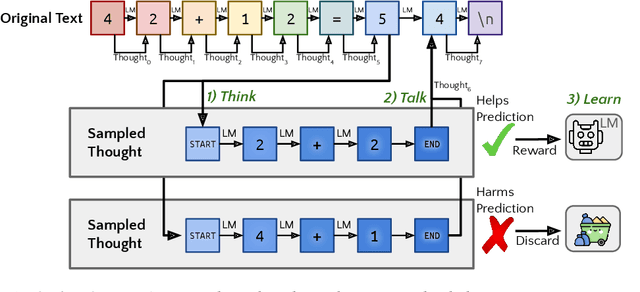
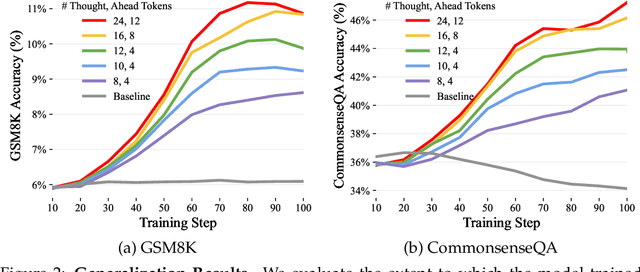

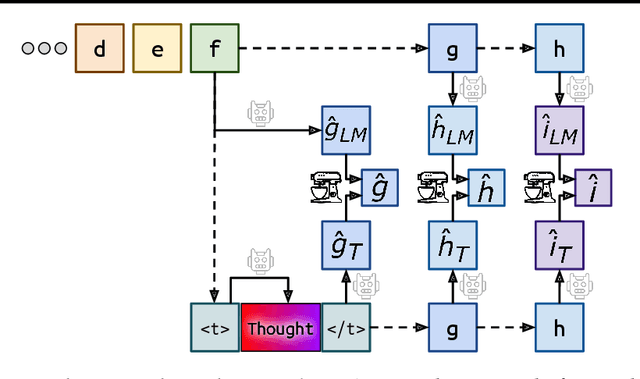
When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text. For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer. This is a highly constrained setting -- ideally, a language model could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain future text, improving their predictions. We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought's start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM's ability to directly answer difficult questions. In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%$\rightarrow$10.9%) and CommonsenseQA (36.3%$\rightarrow$47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way.
pyvene: A Library for Understanding and Improving PyTorch Models via Interventions
Mar 12, 2024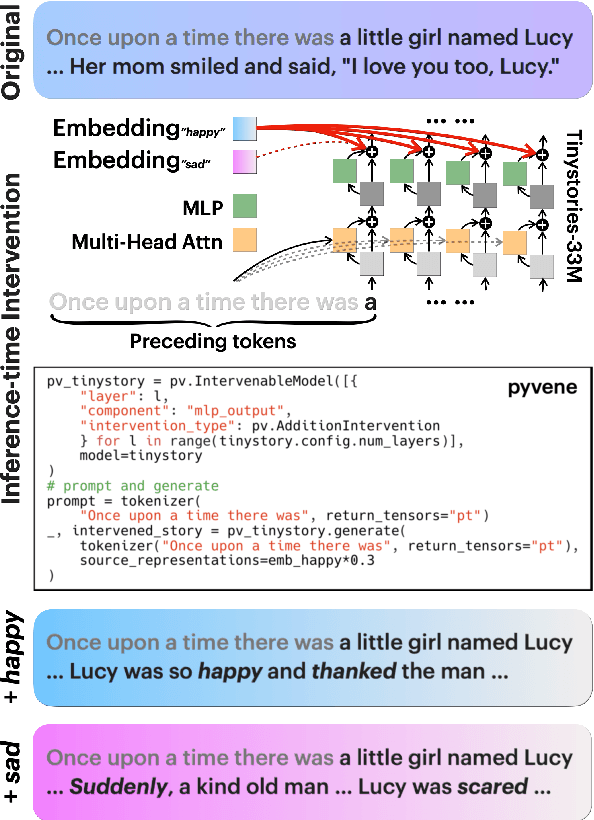
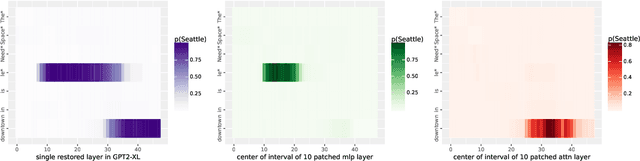
Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce $\textbf{pyvene}$, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. $\textbf{pyvene}$ supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how $\textbf{pyvene}$ provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at https://github.com/stanfordnlp/pyvene.
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Mar 05, 2024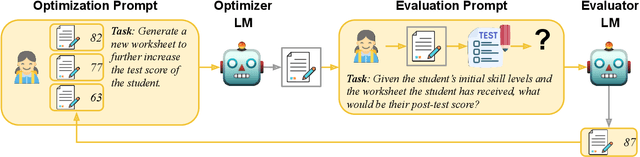


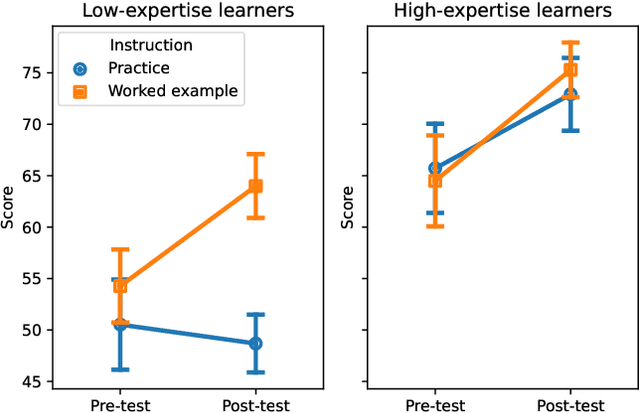
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
Automated Statistical Model Discovery with Language Models
Feb 27, 2024Statistical model discovery involves a challenging search over a vast space of models subject to domain-specific modeling constraints. Efficiently searching over this space requires human expertise in modeling and the problem domain. Motivated by the domain knowledge and programming capabilities of large language models (LMs), we introduce a method for language model driven automated statistical model discovery. We cast our automated procedure within the framework of Box's Loop: the LM iterates between proposing statistical models represented as probabilistic programs, acting as a modeler, and critiquing those models, acting as a domain expert. By leveraging LMs, we do not have to define a domain-specific language of models or design a handcrafted search procedure, key restrictions of previous systems. We evaluate our method in three common settings in probabilistic modeling: searching within a restricted space of models, searching over an open-ended space, and improving classic models under natural language constraints (e.g., this model should be interpretable to an ecologist). Our method matches the performance of previous systems, identifies models on par with human expert designed models, and extends classic models in interpretable ways. Our results highlight the promise of LM driven model discovery.
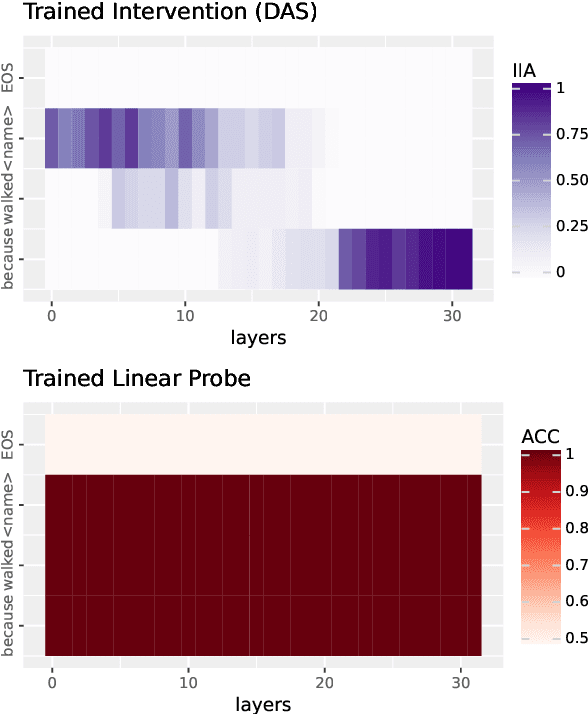
A Reply to Makelov et al. (2023)'s "Interpretability Illusion" Arguments
Jan 23, 2024We respond to the recent paper by Makelov et al. (2023), which reviews subspace interchange intervention methods like distributed alignment search (DAS; Geiger et al. 2023) and claims that these methods potentially cause "interpretability illusions". We first review Makelov et al. (2023)'s technical notion of what an "interpretability illusion" is, and then we show that even intuitive and desirable explanations can qualify as illusions in this sense. As a result, their method of discovering "illusions" can reject explanations they consider "non-illusory". We then argue that the illusions Makelov et al. (2023) see in practice are artifacts of their training and evaluation paradigms. We close by emphasizing that, though we disagree with their core characterization, Makelov et al. (2023)'s examples and discussion have undoubtedly pushed the field of interpretability forward.
Social Contract AI: Aligning AI Assistants with Implicit Group Norms
Oct 26, 2023We explore the idea of aligning an AI assistant by inverting a model of users' (unknown) preferences from observed interactions. To validate our proposal, we run proof-of-concept simulations in the economic ultimatum game, formalizing user preferences as policies that guide the actions of simulated players. We find that the AI assistant accurately aligns its behavior to match standard policies from the economic literature (e.g., selfish, altruistic). However, the assistant's learned policies lack robustness and exhibit limited generalization in an out-of-distribution setting when confronted with a currency (e.g., grams of medicine) that was not included in the assistant's training distribution. Additionally, we find that when there is inconsistency in the relationship between language use and an unknown policy (e.g., an altruistic policy combined with rude language), the assistant's learning of the policy is slowed. Overall, our preliminary results suggest that developing simulation frameworks in which AI assistants need to infer preferences from diverse users can provide a valuable approach for studying practical alignment questions.