 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Sensing and Communication enabled Multiple Base Stations Cooperative Sensing Towards 6G
Oct 11, 2023Driven by the intelligent applications of sixth-generation (6G) mobile communication systems such as smart city and autonomous driving, which connect the physical and cyber space, the integrated sensing and communication (ISAC) brings a revolutionary change to the base stations (BSs) of 6G by integrating radar sensing and communication in the same hardware and wireless resource. However, with the requirements of long-range and accurate sensing in the applications of smart city and autonomous driving, the ISAC enabled single BS still has a limitation in the sensing range and accuracy. With the networked infrastructures of mobile communication systems, multi-BS cooperative sensing is a natural choice satisfying the requirement of long-range and accurate sensing. In this article, the framework of multi-BS cooperative sensing is proposed, breaking through the limitation of single-BS sensing. The enabling technologies, including unified ISAC performance metrics, ISAC signal design and optimization, interference management, cooperative sensing algorithms, are introduced in details. The performance evaluation results are provided to verify the effectiveness of multi-BS cooperative sensing schemes. With ISAC enabled multi-BS cooperative sensing (ISAC-MCS), the intelligent infrastructures connecting physical and cyber space can be established, ushering the era of 6G promoting the intelligence of everything.
* 11 pages 6 figures
You Only Look at Once for Real-time and Generic Multi-Task
Oct 10, 2023



High precision, lightweight, and real-time responsiveness are three essential requirements for implementing autonomous driving. In this study, we present an adaptive, real-time, and lightweight multi-task model designed to concurrently address object detection, drivable area segmentation, and lane line segmentation tasks. Specifically, we developed an end-to-end multi-task model with a unified and streamlined segmentation structure. We introduced a learnable parameter that adaptively concatenate features in segmentation necks, using the same loss function for all segmentation tasks. This eliminates the need for customizations and enhances the model's generalization capabilities. We also introduced a segmentation head composed only of a series of convolutional layers, which reduces the inference time. We achieved competitive results on the BDD100k dataset, particularly in visualization outcomes. The performance results show a mAP50 of 81.1% for object detection, a mIoU of 91.0% for drivable area segmentation, and an IoU of 28.8% for lane line segmentation. Additionally, we introduced real-world scenarios to evaluate our model's performance in a real scene, which significantly outperforms competitors. This demonstrates that our model not only exhibits competitive performance but is also more flexible and faster than existing multi-task models. The source codes and pre-trained models are released at https://github.com/JiayuanWang-JW/YOLOv8-multi-task
Event-Driven Imaging in Turbid Media: A Confluence of Optoelectronics and Neuromorphic Computation
Sep 13, 2023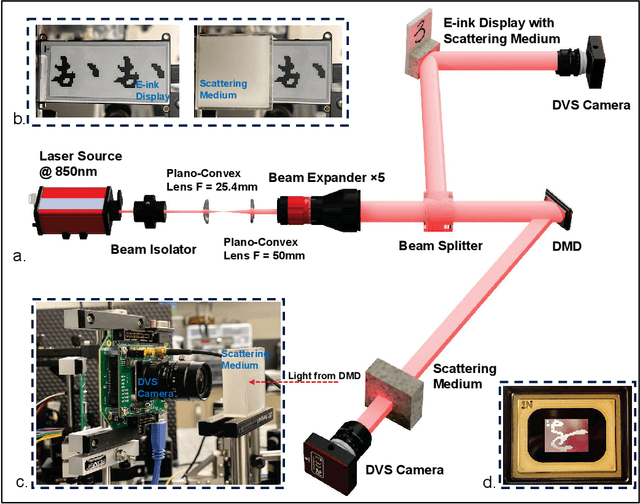
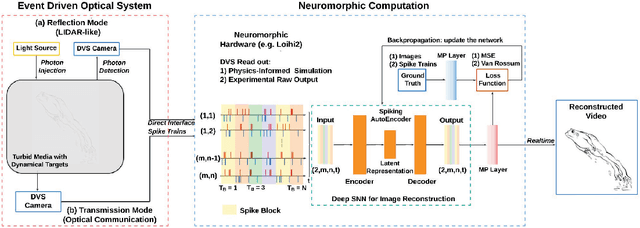
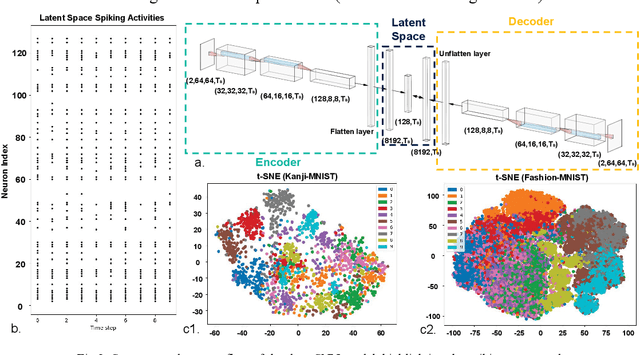

In this paper a new optical-computational method is introduced to unveil images of targets whose visibility is severely obscured by light scattering in dense, turbid media. The targets of interest are taken to be dynamic in that their optical properties are time-varying whether stationary in space or moving. The scheme, to our knowledge the first of its kind, is human vision inspired whereby diffuse photons collected from the turbid medium are first transformed to spike trains by a dynamic vision sensor as in the retina, and image reconstruction is then performed by a neuromorphic computing approach mimicking the brain. We combine benchtop experimental data in both reflection (backscattering) and transmission geometries with support from physics-based simulations to develop a neuromorphic computational model and then apply this for image reconstruction of different MNIST characters and image sets by a dedicated deep spiking neural network algorithm. Image reconstruction is achieved under conditions of turbidity where an original image is unintelligible to the human eye or a digital video camera, yet clearly and quantifiable identifiable when using the new neuromorphic computational approach.
Robust Computation Offloading and Trajectory Optimization for Multi-UAV-Assisted MEC: A Multi-Agent DRL Approach
Aug 24, 2023For multiple Unmanned-Aerial-Vehicles (UAVs) assisted Mobile Edge Computing (MEC) networks, we study the problem of combined computation and communication for user equipments deployed with multi-type tasks. Specifically, we consider that the MEC network encompasses both communication and computation uncertainties, where the partial channel state information and the inaccurate estimation of task complexity are only available. We introduce a robust design accounting for these uncertainties and minimize the total weighted energy consumption by jointly optimizing UAV trajectory, task partition, as well as the computation and communication resource allocation in the multi-UAV scenario. The formulated problem is challenging to solve with the coupled optimization variables and the high uncertainties. To overcome this issue, we reformulate a multi-agent Markov decision process and propose a multi-agent proximal policy optimization with Beta distribution framework to achieve a flexible learning policy. Numerical results demonstrate the effectiveness and robustness of the proposed algorithm for the multi-UAV-assisted MEC network, which outperforms the representative benchmarks of the deep reinforcement learning and heuristic algorithms.
* 12 pages, 10 figures
Federated Learning Robust to Byzantine Attacks: Achieving Zero Optimality Gap
Aug 21, 2023

In this paper, we propose a robust aggregation method for federated learning (FL) that can effectively tackle malicious Byzantine attacks. At each user, model parameter is firstly updated by multiple steps, which is adjustable over iterations, and then pushed to the aggregation center directly. This decreases the number of interactions between the aggregation center and users, allows each user to set training parameter in a flexible way, and reduces computation burden compared with existing works that need to combine multiple historical model parameters. At the aggregation center, geometric median is leveraged to combine the received model parameters from each user. Rigorous proof shows that zero optimality gap is achieved by our proposed method with linear convergence, as long as the fraction of Byzantine attackers is below half. Numerical results verify the effectiveness of our proposed method.
Joint Power Control and Data Size Selection for Over-the-Air Computation Aided Federated Learning
Aug 17, 2023



Federated learning (FL) has emerged as an appealing machine learning approach to deal with massive raw data generated at multiple mobile devices, {which needs to aggregate the training model parameter of every mobile device at one base station (BS) iteratively}. For parameter aggregating in FL, over-the-air computation is a spectrum-efficient solution, which allows all mobile devices to transmit their parameter-mapped signals concurrently to a BS. Due to heterogeneous channel fading and noise, there exists difference between the BS's received signal and its desired signal, measured as the mean-squared error (MSE). To minimize the MSE, we propose to jointly optimize the signal amplification factors at the BS and the mobile devices as well as the data size (the number of data samples involved in local training) at every mobile device. The formulated problem is challenging to solve due to its non-convexity. To find the optimal solution, with some simplification on cost function and variable replacement, which still preserves equivalence, we transform the changed problem to be a bi-level problem equivalently. For the lower-level problem, optimal solution is found by enumerating every candidate solution from the Karush-Kuhn-Tucker (KKT) condition. For the upper-level problem, the optimal solution is found by exploring its piecewise convexity. Numerical results show that our proposed method can greatly reduce the MSE and can help to improve the training performance of FL compared with benchmark methods.
Symbol-level Integrated Sensing and Communication enabled Multiple Base Stations Cooperative Sensing
Aug 13, 2023



With the support of integrated sensing and communication (ISAC) technology, mobile communication system will integrate the function of wireless sensing, thereby facilitating new intelligent applications such as smart city and intelligent transportation. Due to the limited sensing accuracy and sensing range of single base station (BS), multi-BS cooperative sensing can be applied to realize high-accurate, long-range and continuous sensing, exploiting the specific advantages of large-scale networked mobile communication system. This paper proposes a cooperative sensing method suitable to mobile communication systems, which applies symbol-level sensing information fusion to estimate the location and velocity of target. With the demodulation symbols obtained from the echo signals of multiple BSs, the phase features contained in the demodulation symbols are used in the fusion procedure, which realizes cooperative sensing with the synchronization level of mobile communication system. Compared with the signal-level fusion in the area of distributed aperture coherence-synthetic radars, the requirement of synchronization is much lower. When signal-to-noise ratio (SNR) is -5 dB, it is evaluated that symbol-level multi-BS cooperative sensing effectively improves the accuracy of distance and velocity estimation of target. Compared with single-BS sensing, the accuracy of distance and velocity estimation is improved by 40% and 72%, respectively. Compared with data-level multi-BS cooperative sensing based on maximum likelihood (ML) estimation, the accuracy of location and velocity estimation is improved by 12% and 63%, respectively. This work may provide a guideline for the design of multi-BS cooperative sensing system to exploit the widely deployed networked mobile communication system.
Generalized NOMP for Line Spectrum Estimation and Detection from Coarsely Quantized Samples
Jul 02, 2023



As radar systems accompanied by large numbers of antennas and scale up in bandwidth, the cost and power consumption of high-precision (e.g., 10-12 bits) analog-to-digital converter (ADC) become the limiting factor. As a remedy, line spectral estimation and detection (LSE\&D) from low resolution (e.g., 1-4 bits) quantization has been gradually drawn attention in recent years. As low resolution quantization reduces the dynamic range (DR) of the receiver, the theoretical detection probabilities for the multiple targets (especially for the weakest target) are analyzed, which reveals the effects of low resolution on weak signal detection and provides the guidelines for system design. The computation complexities of current methods solve the line spectral estimation from coarsely quantized samples are often high. In this paper, we propose a fast generalized Newtonized orthogonal matching pursuit (GNOMP) which has superior estimation accuracy and maintains a constant false alarm rate (CFAR) behaviour. Besides, such an approach are easily extended to handle the other measurement scenarios such as sign measurements from time-varying thresholds, compressive setting, multisnapshot setting, multidimensional setting and unknown noise variance. Substantial numerical simulations are conducted to demonstrate the effectiveness of GNOMP in terms of estimating accuracy, detection probability and running time. Besides, real data are also provided to demonstrate the effectiveness of the GNOMP.
Fusing Structural and Functional Connectivities using Disentangled VAE for Detecting MCI
Jun 16, 2023



Brain network analysis is a useful approach to studying human brain disorders because it can distinguish patients from healthy people by detecting abnormal connections. Due to the complementary information from multiple modal neuroimages, multimodal fusion technology has a lot of potential for improving prediction performance. However, effective fusion of multimodal medical images to achieve complementarity is still a challenging problem. In this paper, a novel hierarchical structural-functional connectivity fusing (HSCF) model is proposed to construct brain structural-functional connectivity matrices and predict abnormal brain connections based on functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI). Specifically, the prior knowledge is incorporated into the separators for disentangling each modality of information by the graph convolutional networks (GCN). And a disentangled cosine distance loss is devised to ensure the disentanglement's effectiveness. Moreover, the hierarchical representation fusion module is designed to effectively maximize the combination of relevant and effective features between modalities, which makes the generated structural-functional connectivity more robust and discriminative in the cognitive disease analysis. Results from a wide range of tests performed on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that the proposed model performs better than competing approaches in terms of classification evaluation. In general, the proposed HSCF model is a promising model for generating brain structural-functional connectivities and identifying abnormal brain connections as cognitive disease progresses.
Spectrum Sharing between High Altitude Platform Network and Terrestrial Network: Modeling and Performance Analysis
Jun 08, 2023



Achieving seamless global coverage is one of the ultimate goals of space-air-ground integrated network, as a part of which High Altitude Platform (HAP) network can provide wide-area coverage. However, deploying a large number of HAPs will lead to severe congestion of existing frequency bands. Spectrum sharing improves spectrum utilization. The coverage performance improvement and interference caused by spectrum sharing need to be investigated. To this end, this paper analyzes the performance of spectrum sharing between HAP network and terrestrial network. We firstly generalize the Poisson Point Process (PPP) to curves, surfaces and manifolds to model the distribution of terrestrial Base Stations (BSs) and HAPs. Then, the closed-form expressions for coverage probability of HAP network and terrestrial network are derived based on differential geometry and stochastic geometry. We verify the accuracy of closed-form expressions by Monte Carlo simulation. The results show that HAP network has less interference to terrestrial network. Low height and suitable deployment density can improve the coverage probability and transmission capacity of HAP network.