 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Evaluations That are Biased by Evaluations
Dec 01, 2020It is common to evaluate a set of items by soliciting people to rate them. For example, universities ask students to rate the teaching quality of their instructors, and conference organizers ask authors of submissions to evaluate the quality of the reviews. However, in these applications, students often give a higher rating to a course if they receive higher grades in a course, and authors often give a higher rating to the reviews if their papers are accepted to the conference. In this work, we call these external factors the "outcome" experienced by people, and consider the problem of mitigating these outcome-induced biases in the given ratings when some information about the outcome is available. We formulate the information about the outcome as a known partial ordering on the bias. We propose a debiasing method by solving a regularized optimization problem under this ordering constraint, and also provide a carefully designed cross-validation method that adaptively chooses the appropriate amount of regularization. We provide theoretical guarantees on the performance of our algorithm, as well as experimental evaluations.
A Large Scale Randomized Controlled Trial on Herding in Peer-Review Discussions
Nov 30, 2020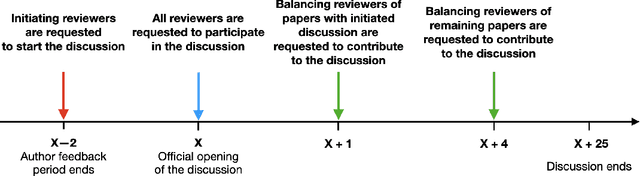

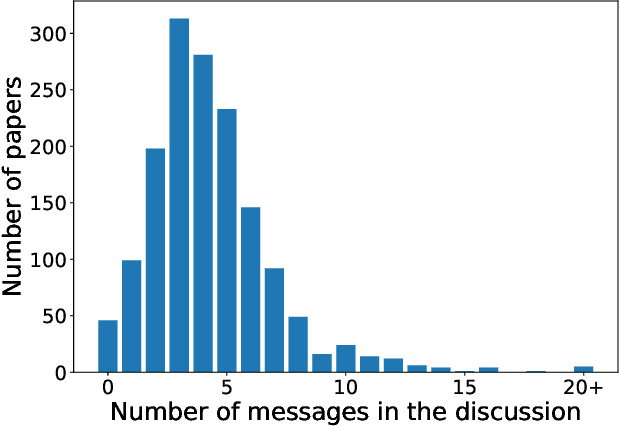

Peer review is the backbone of academia and humans constitute a cornerstone of this process, being responsible for reviewing papers and making the final acceptance/rejection decisions. Given that human decision making is known to be susceptible to various cognitive biases, it is important to understand which (if any) biases are present in the peer-review process and design the pipeline such that the impact of these biases is minimized. In this work, we focus on the dynamics of between-reviewers discussions and investigate the presence of herding behaviour therein. In that, we aim to understand whether reviewers and more senior decision makers get disproportionately influenced by the first argument presented in the discussion when (in case of reviewers) they form an independent opinion about the paper before discussing it with others. Specifically, in conjunction with the review process of ICML 2020 -- a large, top tier machine learning conference -- we design and execute a randomized controlled trial with the goal of testing for the conditional causal effect of the discussion initiator's opinion on the outcome of a paper.
A Novice-Reviewer Experiment to Address Scarcity of Qualified Reviewers in Large Conferences
Nov 30, 2020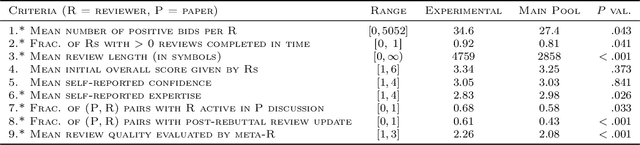
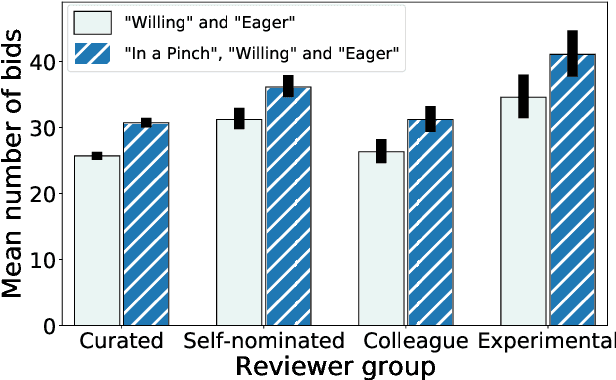
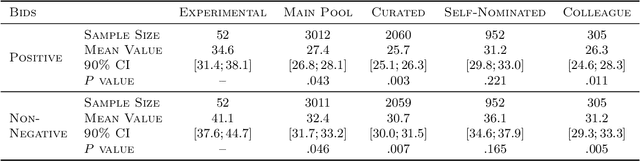
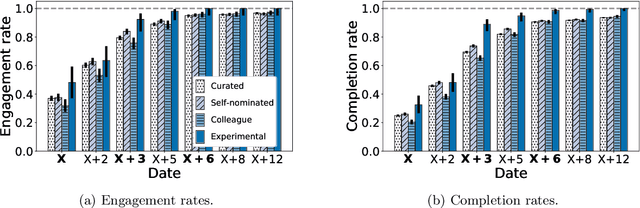
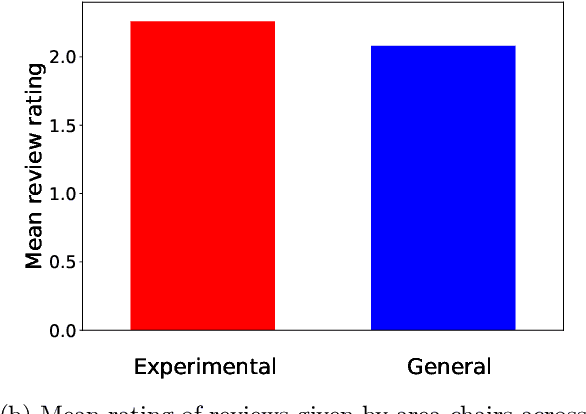
Conference peer review constitutes a human-computation process whose importance cannot be overstated: not only it identifies the best submissions for acceptance, but, ultimately, it impacts the future of the whole research area by promoting some ideas and restraining others. A surge in the number of submissions received by leading AI conferences has challenged the sustainability of the review process by increasing the burden on the pool of qualified reviewers which is growing at a much slower rate. In this work, we consider the problem of reviewer recruiting with a focus on the scarcity of qualified reviewers in large conferences. Specifically, we design a procedure for (i) recruiting reviewers from the population not typically covered by major conferences and (ii) guiding them through the reviewing pipeline. In conjunction with ICML 2020 -- a large, top-tier machine learning conference -- we recruit a small set of reviewers through our procedure and compare their performance with the general population of ICML reviewers. Our experiment reveals that a combination of the recruiting and guiding mechanisms allows for a principled enhancement of the reviewer pool and results in reviews of superior quality compared to the conventional pool of reviews as evaluated by senior members of the program committee (meta-reviewers).
Prior and Prejudice: The Novice Reviewers' Bias against Resubmissions in Conference Peer Review
Nov 30, 2020

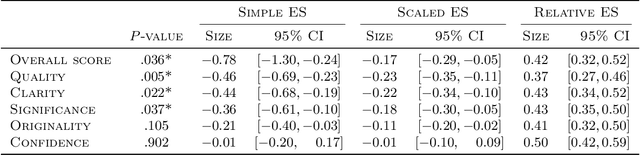
Modern machine learning and computer science conferences are experiencing a surge in the number of submissions that challenges the quality of peer review as the number of competent reviewers is growing at a much slower rate. To curb this trend and reduce the burden on reviewers, several conferences have started encouraging or even requiring authors to declare the previous submission history of their papers. Such initiatives have been met with skepticism among authors, who raise the concern about a potential bias in reviewers' recommendations induced by this information. In this work, we investigate whether reviewers exhibit a bias caused by the knowledge that the submission under review was previously rejected at a similar venue, focusing on a population of novice reviewers who constitute a large fraction of the reviewer pool in leading machine learning and computer science conferences. We design and conduct a randomized controlled trial closely replicating the relevant components of the peer-review pipeline with $133$ reviewers (master's, junior PhD students, and recent graduates of top US universities) writing reviews for $19$ papers. The analysis reveals that reviewers indeed become negatively biased when they receive a signal about paper being a resubmission, giving almost 1 point lower overall score on a 10-point Likert item ($\Delta = -0.78, \ 95\% \ \text{CI} = [-1.30, -0.24]$) than reviewers who do not receive such a signal. Looking at specific criteria scores (originality, quality, clarity and significance), we observe that novice reviewers tend to underrate quality the most.
Uncovering Latent Biases in Text: Method and Application to Peer Review
Oct 29, 2020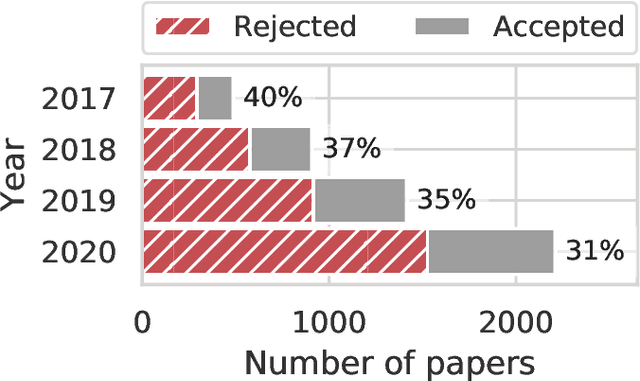
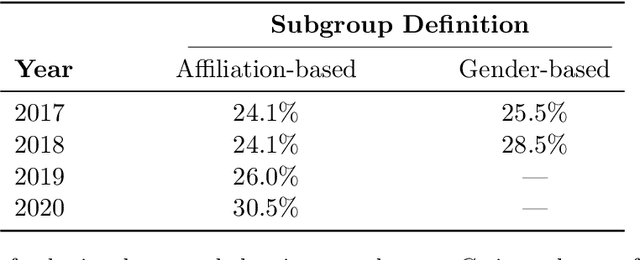
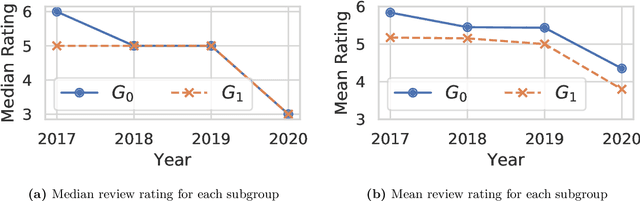
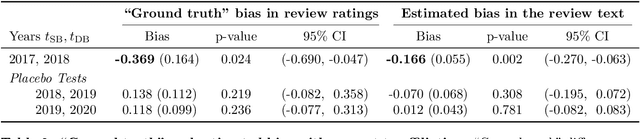
Quantifying systematic disparities in numerical quantities such as employment rates and wages between population subgroups provides compelling evidence for the existence of societal biases. However, biases in the text written for members of different subgroups (such as in recommendation letters for male and non-male candidates), though widely reported anecdotally, remain challenging to quantify. In this work, we introduce a novel framework to quantify bias in text caused by the visibility of subgroup membership indicators. We develop a nonparametric estimation and inference procedure to estimate this bias. We then formalize an identification strategy to causally link the estimated bias to the visibility of subgroup membership indicators, provided observations from time periods both before and after an identity-hiding policy change. We identify an application wherein "ground truth" bias can be inferred to evaluate our framework, instead of relying on synthetic or secondary data. Specifically, we apply our framework to quantify biases in the text of peer reviews from a reputed machine learning conference before and after the conference adopted a double-blind reviewing policy. We show evidence of biases in the review ratings that serves as "ground truth", and show that our proposed framework accurately detects these biases from the review text without having access to the review ratings.
Catch Me if I Can: Detecting Strategic Behaviour in Peer Assessment
Oct 08, 2020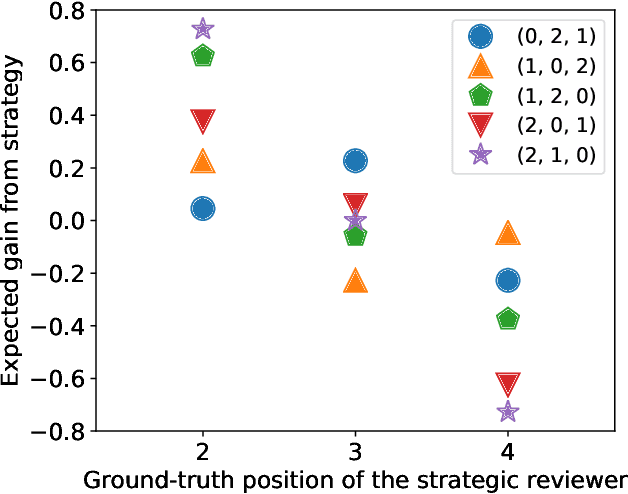
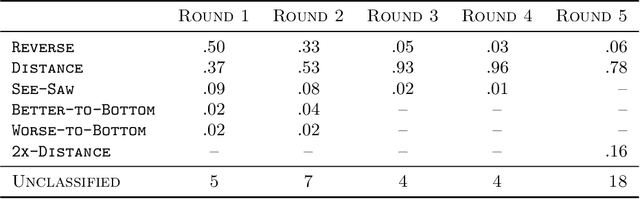
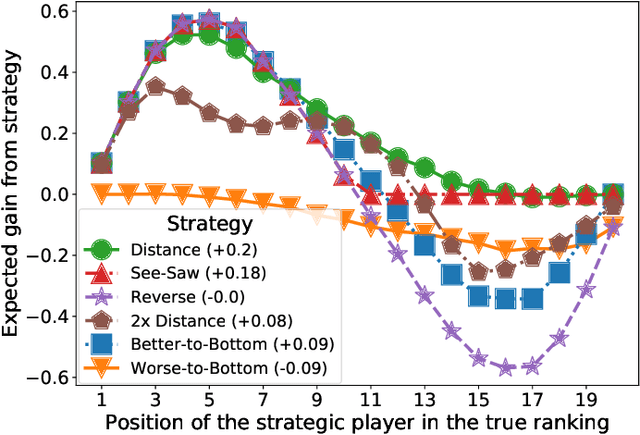

We consider the issue of strategic behaviour in various peer-assessment tasks, including peer grading of exams or homeworks and peer review in hiring or promotions. When a peer-assessment task is competitive (e.g., when students are graded on a curve), agents may be incentivized to misreport evaluations in order to improve their own final standing. Our focus is on designing methods for detection of such manipulations. Specifically, we consider a setting in which agents evaluate a subset of their peers and output rankings that are later aggregated to form a final ordering. In this paper, we investigate a statistical framework for this problem and design a principled test for detecting strategic behaviour. We prove that our test has strong false alarm guarantees and evaluate its detection ability in practical settings. For this, we design and execute an experiment that elicits strategic behaviour from subjects and release a dataset of patterns of strategic behaviour that may be of independent interest. We then use the collected data to conduct a series of real and semi-synthetic evaluations that demonstrate a strong detection power of our test.
Mitigating Manipulation in Peer Review via Randomized Reviewer Assignments
Jun 29, 2020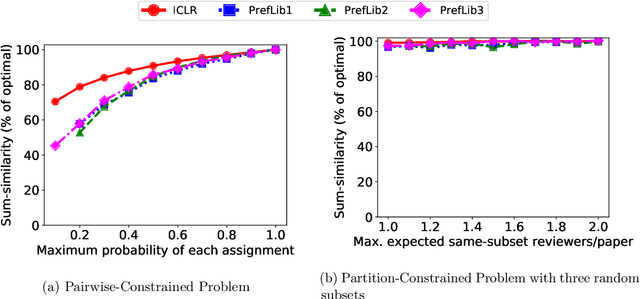
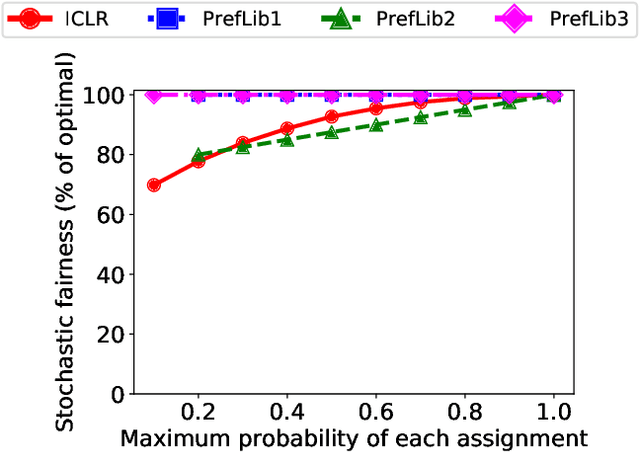
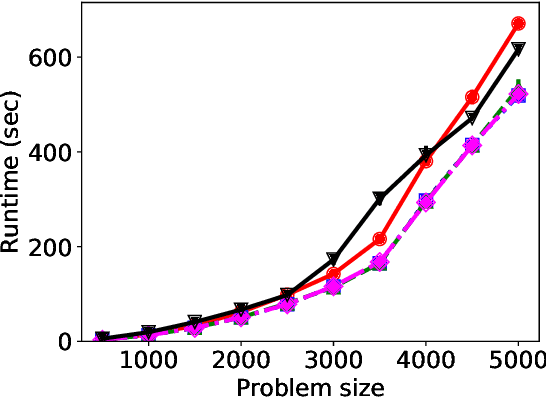
We consider three important challenges in conference peer review: (i) reviewers maliciously attempting to get assigned to certain papers to provide positive reviews, possibly as part of quid-pro-quo arrangements with the authors; (ii) "torpedo reviewing," where reviewers deliberately attempt to get assigned to certain papers that they dislike in order to reject them; (iii) reviewer de-anonymization on release of the similarities and the reviewer-assignment code. On the conceptual front, we identify connections between these three problems and present a framework that brings all these challenges under a common umbrella. We then present a (randomized) algorithm for reviewer assignment that can optimally solve the reviewer-assignment problem under any given constraints on the probability of assignment for any reviewer-paper pair. We further consider the problem of restricting the joint probability that certain suspect pairs of reviewers are assigned to certain papers, and show that this problem is NP-hard for arbitrary constraints on these joint probabilities but efficiently solvable for a practical special case. Finally, we experimentally evaluate our algorithms on datasets from past conferences, where we observe that they can limit the chance that any malicious reviewer gets assigned to their desired paper to 50% while producing assignments with over 90% of the total optimal similarity. Our algorithms still achieve this similarity while also preventing reviewers with close associations from being assigned to the same paper.
On the Privacy-Utility Tradeoff in Peer-Review Data Analysis
Jun 29, 2020
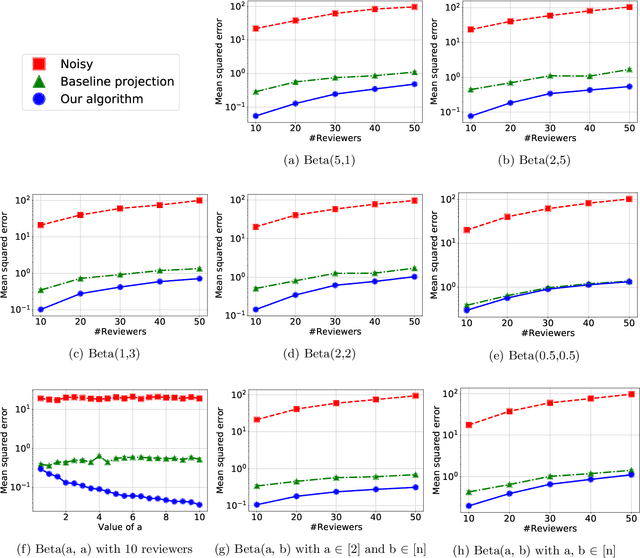
A major impediment to research on improving peer review is the unavailability of peer-review data, since any release of such data must grapple with the sensitivity of the peer review data in terms of protecting identities of reviewers from authors. We posit the need to develop techniques to release peer-review data in a privacy-preserving manner. Identifying this problem, in this paper we propose a framework for privacy-preserving release of certain conference peer-review data -- distributions of ratings, miscalibration, and subjectivity -- with an emphasis on the accuracy (or utility) of the released data. The crux of the framework lies in recognizing that a part of the data pertaining to the reviews is already available in public, and we use this information to post-process the data released by any privacy mechanism in a manner that improves the accuracy (utility) of the data while retaining the privacy guarantees. Our framework works with any privacy-preserving mechanism that operates via releasing perturbed data. We present several positive and negative theoretical results, including a polynomial-time algorithm for improving on the privacy-utility tradeoff.
A $\texttt{SUPER}^{\ast}$ Algorithm to Optimize Paper Bidding in Peer Review
Jun 27, 2020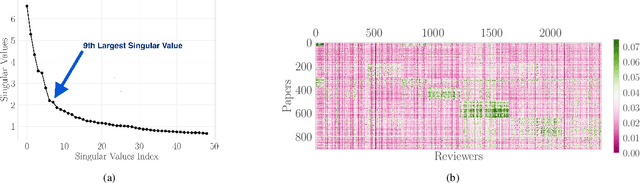
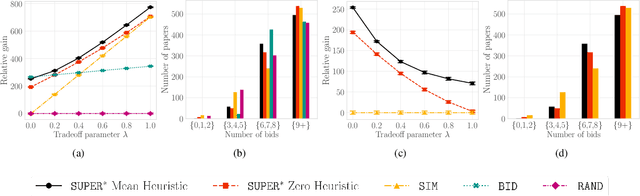
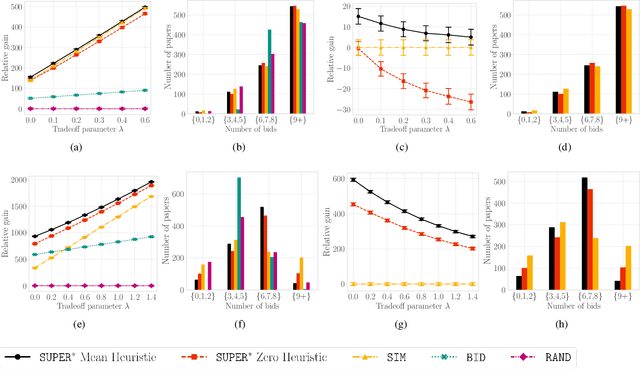
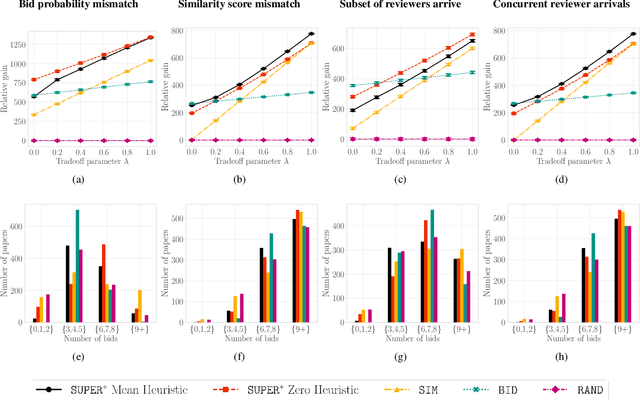
A number of applications involve sequential arrival of users, and require showing each user an ordering of items. A prime example (which forms the focus of this paper) is the bidding process in conference peer review where reviewers enter the system sequentially, each reviewer needs to be shown the list of submitted papers, and the reviewer then "bids" to review some papers. The order of the papers shown has a significant impact on the bids due to primacy effects. In deciding on the ordering of papers to show, there are two competing goals: (i) obtaining sufficiently many bids for each paper, and (ii) satisfying reviewers by showing them relevant items. In this paper, we begin by developing a framework to study this problem in a principled manner. We present an algorithm called $\texttt{SUPER}^{\ast}$, inspired by the A$^{\ast}$ algorithm, for this goal. Theoretically, we show a local optimality guarantee of our algorithm and prove that popular baselines are considerably suboptimal. Moreover, under a community model for the similarities, we prove that $\texttt{SUPER}^{\ast}$ is near-optimal whereas the popular baselines are considerably suboptimal. In experiments on real data from ICLR 2018 and synthetic data, we find that $\texttt{SUPER}^{\ast}$ considerably outperforms baselines deployed in existing systems, consistently reducing the number of papers with fewer than requisite bids by 50-75% or more, and is also robust to various real world complexities.
Two-Sample Testing on Ranked Preference Data and the Role of Modeling Assumptions
Jun 21, 2020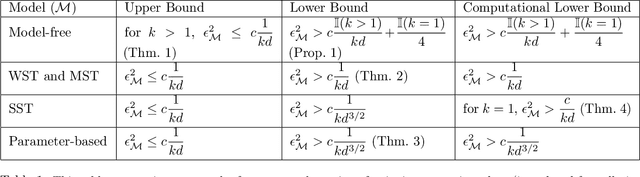
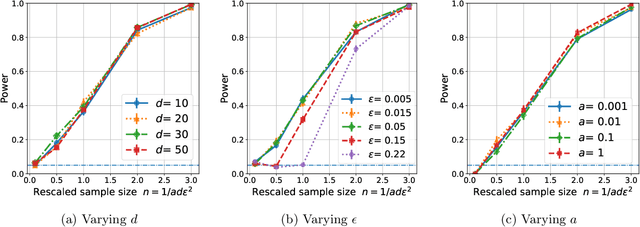
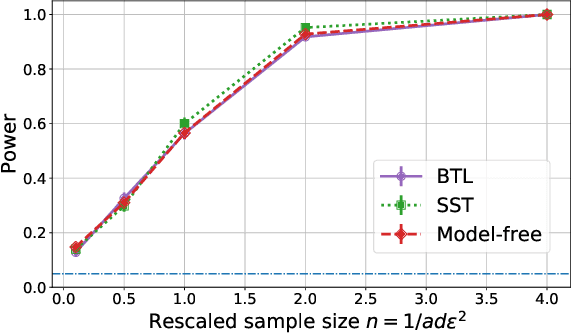

A number of applications require two-sample testing on ranked preference data. For instance, in crowdsourcing, there is a long-standing question of whether pairwise comparison data provided by people is distributed similar to ratings-converted-to-comparisons. Other examples include sports data analysis and peer grading. In this paper, we design two-sample tests for pairwise comparison data and ranking data. For our two-sample test for pairwise comparison data, we establish an upper bound on the sample complexity required to correctly distinguish between the distributions of the two sets of samples. Our test requires essentially no assumptions on the distributions. We then prove complementary lower bounds showing that our results are tight (in the minimax sense) up to constant factors. We investigate the role of modeling assumptions by proving lower bounds for a range of pairwise comparison models (WST, MST,SST, parameter-based such as BTL and Thurstone). We also provide testing algorithms and associated sample complexity bounds for the problem of two-sample testing with partial (or total) ranking data.Furthermore, we empirically evaluate our results via extensive simulations as well as two real-world datasets consisting of pairwise comparisons. By applying our two-sample test on real-world pairwise comparison data, we conclude that ratings and rankings provided by people are indeed distributed differently. On the other hand, our test recognizes no significant difference in the relative performance of European football teams across two seasons. Finally, we apply our two-sample test on a real-world partial and total ranking dataset and find a statistically significant difference in Sushi preferences across demographic divisions based on gender, age and region of residence.