 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Decision Tree with Noisy Outcomes
Dec 23, 2023



In pool-based active learning, the learner is given an unlabeled data set and aims to efficiently learn the unknown hypothesis by querying the labels of the data points. This can be formulated as the classical Optimal Decision Tree (ODT) problem: Given a set of tests, a set of hypotheses, and an outcome for each pair of test and hypothesis, our objective is to find a low-cost testing procedure (i.e., decision tree) that identifies the true hypothesis. This optimization problem has been extensively studied under the assumption that each test generates a deterministic outcome. However, in numerous applications, for example, clinical trials, the outcomes may be uncertain, which renders the ideas from the deterministic setting invalid. In this work, we study a fundamental variant of the ODT problem in which some test outcomes are noisy, even in the more general case where the noise is persistent, i.e., repeating a test gives the same noisy output. Our approximation algorithms provide guarantees that are nearly best possible and hold for the general case of a large number of noisy outcomes per test or per hypothesis where the performance degrades continuously with this number. We numerically evaluated our algorithms for identifying toxic chemicals and learning linear classifiers, and observed that our algorithms have costs very close to the information-theoretic minimum.
Short-lived High-volume Multi-A/B Testing
Dec 23, 2023Modern platforms leverage randomized experiments to make informed decisions from a given set of items (``treatments''). As a particularly challenging scenario, these items may (i) arrive in high volume, with thousands of new items being released per hour, and (ii) have short lifetime, say, due to the item's transient nature or underlying non-stationarity that impels the platform to perceive the same item as distinct copies over time. Thus motivated, we study a Bayesian multiple-play bandit problem that encapsulates the key features of the multivariate testing (or ``multi-A/B testing'') problem with a high volume of short-lived arms. In each round, a set of $k$ arms arrive, each available for $w$ rounds. Without knowing the mean reward for each arm, the learner selects a multiset of $n$ arms and immediately observes their realized rewards. We aim to minimize the loss due to not knowing the mean rewards, averaged over instances generated from a given prior distribution. We show that when $k = O(n^\rho)$ for some constant $\rho>0$, our proposed policy has $\tilde O(n^{-\min \{\rho, \frac 12 (1+\frac 1w)^{-1}\}})$ loss on a sufficiently large class of prior distributions. We complement this result by showing that every policy suffers $\Omega (n^{-\min \{\rho, \frac 12\}})$ loss on the same class of distributions. We further validate the effectiveness of our policy through a large-scale field experiment on {\em Glance}, a content-card-serving platform that faces exactly the above challenge. A simple variant of our policy outperforms the platform's current recommender by 4.32\% in total duration and 7.48\% in total number of click-throughs.
Markdown Pricing Under an Unknown Parametric Demand Model
Dec 23, 2023Consider a single-product revenue-maximization problem where the seller monotonically decreases the price in $n$ rounds with an unknown demand model coming from a given family. Without monotonicity, the minimax regret is $\tilde O(n^{2/3})$ for the Lipschitz demand family and $\tilde O(n^{1/2})$ for a general class of parametric demand models. With monotonicity, the minimax regret is $\tilde O(n^{3/4})$ if the revenue function is Lipschitz and unimodal. However, the minimax regret for parametric families remained open. In this work, we provide a complete settlement for this fundamental problem. We introduce the crossing number to measure the complexity of a family of demand functions. In particular, the family of degree-$k$ polynomials has a crossing number $k$. Based on conservatism under uncertainty, we present (i) a policy with an optimal $\Theta(\log^2 n)$ regret for families with crossing number $k=0$, and (ii) another policy with an optimal $\tilde \Theta(n^{k/(k+1)})$ regret when $k\ge 1$. These bounds are asymptotically higher than the $\tilde O(\log n)$ and $\tilde \Theta(\sqrt n)$ minimax regret for the same families without the monotonicity constraint.
Informed Steiner Trees: Sampling and Pruning for Multi-Goal Path Finding in High Dimensions
May 09, 2022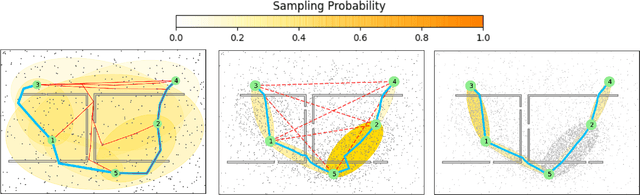
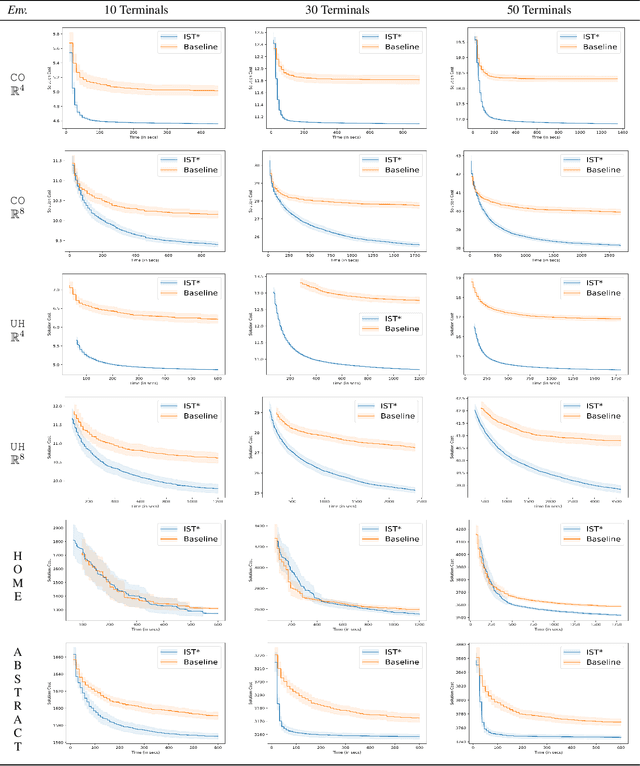
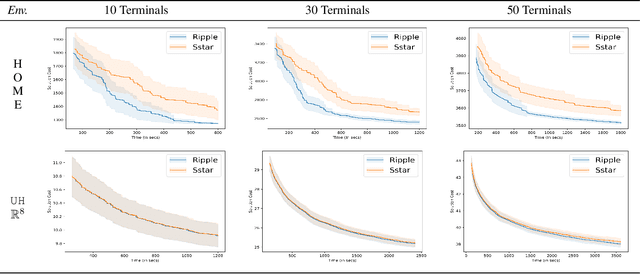
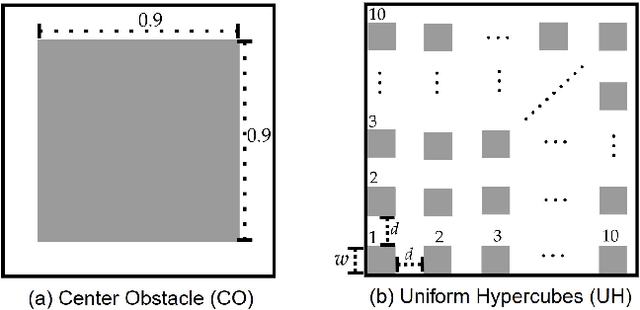
We interleave sampling based motion planning methods with pruning ideas from minimum spanning tree algorithms to develop a new approach for solving a Multi-Goal Path Finding (MGPF) problem in high dimensional spaces. The approach alternates between sampling points from selected regions in the search space and de-emphasizing regions that may not lead to good solutions for MGPF. Our approach provides an asymptotic, 2-approximation guarantee for MGPF. We also present extensive numerical results to illustrate the advantages of our proposed approach over uniform sampling in terms of the quality of the solutions found and computation speed.
Learnable and Instance-Robust Predictions for Online Matching, Flows and Load Balancing
Nov 23, 2020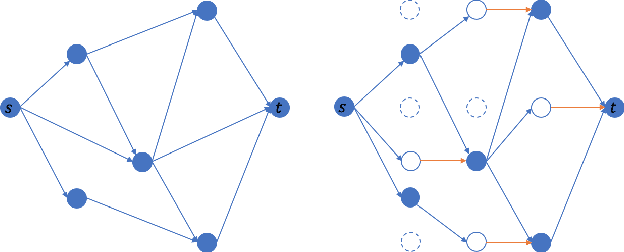
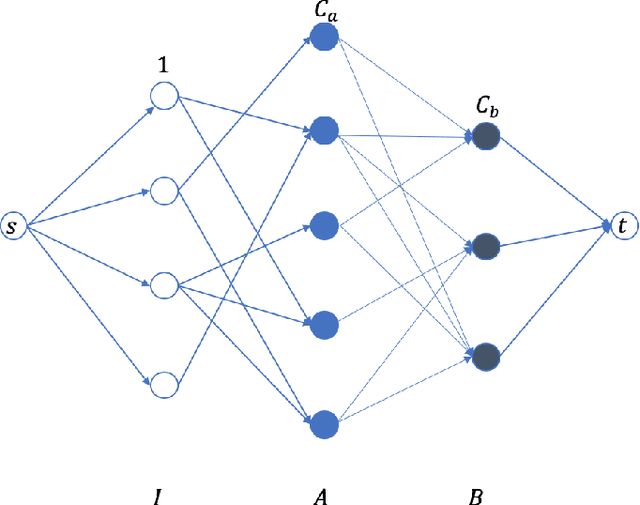
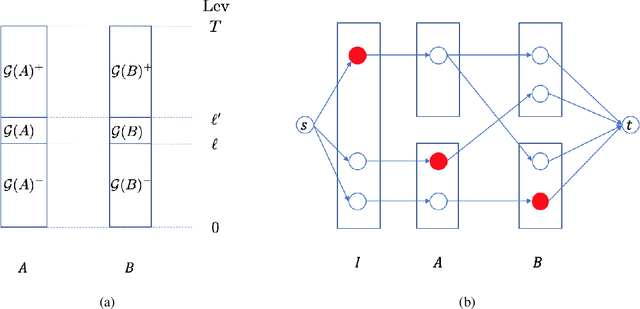
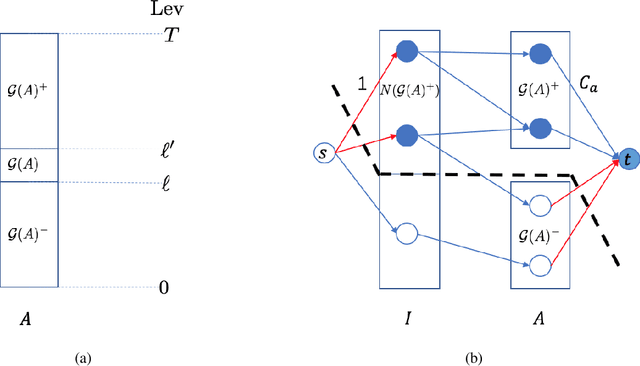
This paper proposes a new model for augmenting algorithms with useful predictions that go beyond worst-case bounds on the algorithm performance. By refining existing models, our model ensures predictions are formally learnable and instance robust. Learnability guarantees that predictions can be efficiently constructed from past data. Instance robustness formally ensures a prediction is robust to modest changes in the problem input. Further, the robustness model ensures two different predictions can be objectively compared, addressing a shortcoming in prior models. This paper establishes the existence of predictions which satisfy these properties. The paper considers online algorithms with predictions for a network flow allocation problem and the restricted assignment makespan minimization problem. For both problems, three key properties are established: existence of useful predictions that give near optimal solutions, robustness of these predictions to errors that smoothly degrade as the underlying problem instance changes, and we prove high quality predictions can be learned from a small sample of prior instances.
Stretching the Effectiveness of MLE from Accuracy to Bias for Pairwise Comparisons
Jun 10, 2019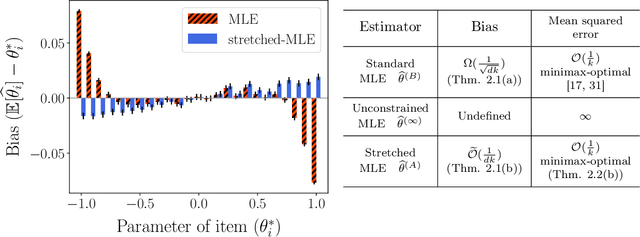
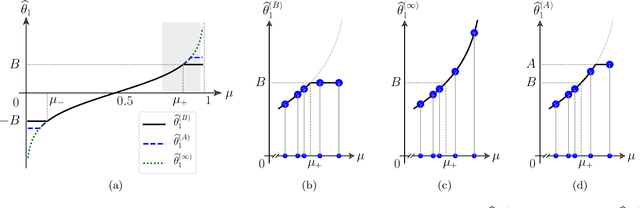
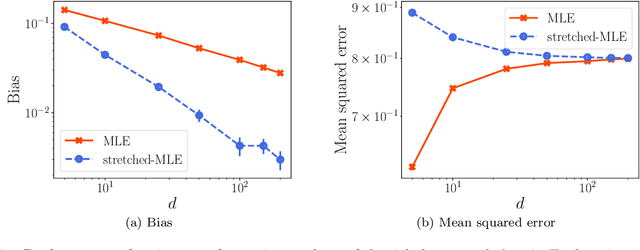
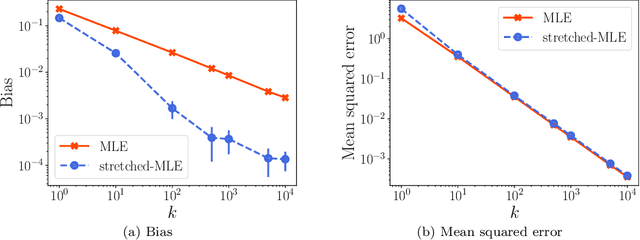
A number of applications (e.g., AI bot tournaments, sports, peer grading, crowdsourcing) use pairwise comparison data and the Bradley-Terry-Luce (BTL) model to evaluate a given collection of items (e.g., bots, teams, students, search results). Past work has shown that under the BTL model, the widely-used maximum-likelihood estimator (MLE) is minimax-optimal in estimating the item parameters, in terms of the mean squared error. However, another important desideratum for designing estimators is fairness. In this work, we consider fairness modeled by the notion of bias in statistics. We show that the MLE incurs a suboptimal rate in terms of bias. We then propose a simple modification to the MLE, which "stretches" the bounding box of the maximum-likelihood optimizer by a small constant factor from the underlying ground truth domain. We show that this simple modification leads to an improved rate in bias, while maintaining minimax-optimality in the mean squared error. In this manner, our proposed class of estimators provably improves fairness represented by bias without loss in accuracy.
Geometry of Online Packing Linear Programs
Apr 26, 2012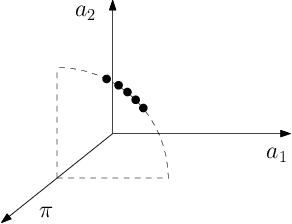
We consider packing LP's with $m$ rows where all constraint coefficients are normalized to be in the unit interval. The n columns arrive in random order and the goal is to set the corresponding decision variables irrevocably when they arrive so as to obtain a feasible solution maximizing the expected reward. Previous (1 - \epsilon)-competitive algorithms require the right-hand side of the LP to be Omega((m/\epsilon^2) log (n/\epsilon)), a bound that worsens with the number of columns and rows. However, the dependence on the number of columns is not required in the single-row case and known lower bounds for the general case are also independent of n. Our goal is to understand whether the dependence on n is required in the multi-row case, making it fundamentally harder than the single-row version. We refute this by exhibiting an algorithm which is (1 - \epsilon)-competitive as long as the right-hand sides are Omega((m^2/\epsilon^2) log (m/\epsilon)). Our techniques refine previous PAC-learning based approaches which interpret the online decisions as linear classifications of the columns based on sampled dual prices. The key ingredient of our improvement comes from a non-standard covering argument together with the realization that only when the columns of the LP belong to few 1-d subspaces we can obtain small such covers; bounding the size of the cover constructed also relies on the geometry of linear classifiers. General packing LP's are handled by perturbing the input columns, which can be seen as making the learning problem more robust.