 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Call Stochastic Extragradient Methods for Structured Non-monotone Variational Inequalities: Improved Analysis under Weaker Conditions
Feb 27, 2023



Single-call stochastic extragradient methods, like stochastic past extragradient (SPEG) and stochastic optimistic gradient (SOG), have gained a lot of interest in recent years and are one of the most efficient algorithms for solving large-scale min-max optimization and variational inequalities problems (VIP) appearing in various machine learning tasks. However, despite their undoubted popularity, current convergence analyses of SPEG and SOG require a bounded variance assumption. In addition, several important questions regarding the convergence properties of these methods are still open, including mini-batching, efficient step-size selection, and convergence guarantees under different sampling strategies. In this work, we address these questions and provide convergence guarantees for two large classes of structured non-monotone VIPs: (i) quasi-strongly monotone problems (a generalization of strongly monotone problems) and (ii) weak Minty variational inequalities (a generalization of monotone and Minty VIPs). We introduce the expected residual condition, explain its benefits, and show how it can be used to obtain a strictly weaker bound than previously used growth conditions, expected co-coercivity, or bounded variance assumptions. Equipped with this condition, we provide theoretical guarantees for the convergence of single-call extragradient methods for different step-size selections, including constant, decreasing, and step-size-switching rules. Furthermore, our convergence analysis holds under the arbitrary sampling paradigm, which includes importance sampling and various mini-batching strategies as special cases.
A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games
Jun 12, 2022
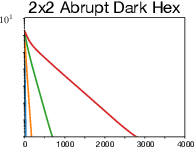
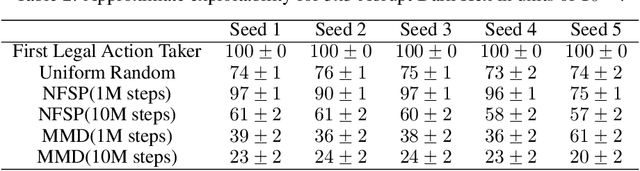

Algorithms designed for single-agent reinforcement learning (RL) generally fail to converge to equilibria in two-player zero-sum (2p0s) games. Conversely, game-theoretic algorithms for approximating Nash and quantal response equilibria (QREs) in 2p0s games are not typically competitive for RL and can be difficult to scale. As a result, algorithms for these two cases are generally developed and evaluated separately. In this work, we show that a single algorithm -- a simple extension to mirror descent with proximal regularization that we call magnetic mirror descent (MMD) -- can produce strong results in both settings, despite their fundamental differences. From a theoretical standpoint, we prove that MMD converges linearly to QREs in extensive-form games -- this is the first time linear convergence has been proven for a first order solver. Moreover, applied as a tabular Nash equilibrium solver via self-play, we show empirically that MMD produces results competitive with CFR in both normal-form and extensive-form games with full feedback (this is the first time that a standard RL algorithm has done so) and also that MMD empirically converges in black-box feedback settings. Furthermore, for single-agent deep RL, on a small collection of Atari and Mujoco games, we show that MMD can produce results competitive with those of PPO. Lastly, for multi-agent deep RL, we show MMD can outperform NFSP in 3x3 Abrupt Dark Hex.
Stochastic Gradient Descent-Ascent: Unified Theory and New Efficient Methods
Feb 15, 2022



Stochastic Gradient Descent-Ascent (SGDA) is one of the most prominent algorithms for solving min-max optimization and variational inequalities problems (VIP) appearing in various machine learning tasks. The success of the method led to several advanced extensions of the classical SGDA, including variants with arbitrary sampling, variance reduction, coordinate randomization, and distributed variants with compression, which were extensively studied in the literature, especially during the last few years. In this paper, we propose a unified convergence analysis that covers a large variety of stochastic gradient descent-ascent methods, which so far have required different intuitions, have different applications and have been developed separately in various communities. A key to our unified framework is a parametric assumption on the stochastic estimates. Via our general theoretical framework, we either recover the sharpest known rates for the known special cases or tighten them. Moreover, to illustrate the flexibility of our approach we develop several new variants of SGDA such as a new variance-reduced method (L-SVRGDA), new distributed methods with compression (QSGDA, DIANA-SGDA, VR-DIANA-SGDA), and a new method with coordinate randomization (SEGA-SGDA). Although variants of the new methods are known for solving minimization problems, they were never considered or analyzed for solving min-max problems and VIPs. We also demonstrate the most important properties of the new methods through extensive numerical experiments.
Stochastic Extragradient: General Analysis and Improved Rates
Nov 16, 2021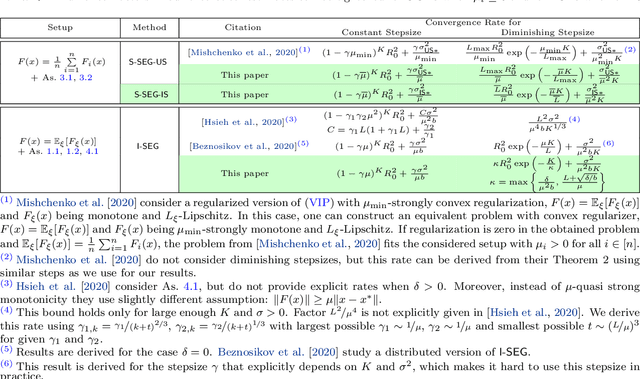
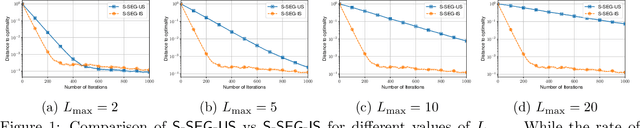
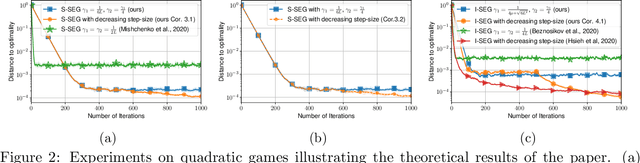

The Stochastic Extragradient (SEG) method is one of the most popular algorithms for solving min-max optimization and variational inequalities problems (VIP) appearing in various machine learning tasks. However, several important questions regarding the convergence properties of SEG are still open, including the sampling of stochastic gradients, mini-batching, convergence guarantees for the monotone finite-sum variational inequalities with possibly non-monotone terms, and others. To address these questions, in this paper, we develop a novel theoretical framework that allows us to analyze several variants of SEG in a unified manner. Besides standard setups, like Same-Sample SEG under Lipschitzness and monotonicity or Independent-Samples SEG under uniformly bounded variance, our approach allows us to analyze variants of SEG that were never explicitly considered in the literature before. Notably, we analyze SEG with arbitrary sampling which includes importance sampling and various mini-batching strategies as special cases. Our rates for the new variants of SEG outperform the current state-of-the-art convergence guarantees and rely on less restrictive assumptions.
Stochastic Mirror Descent: Convergence Analysis and Adaptive Variants via the Mirror Stochastic Polyak Stepsize
Nov 01, 2021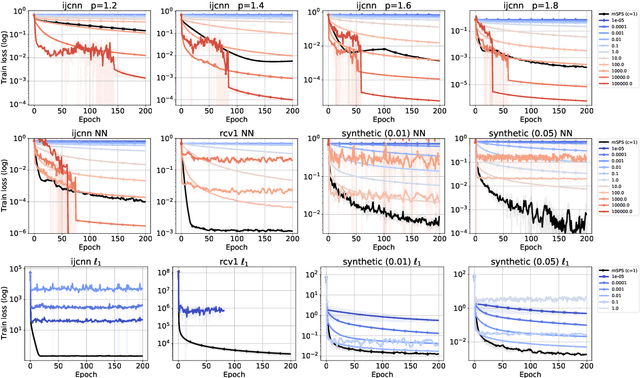
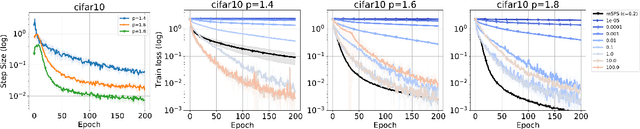


We investigate the convergence of stochastic mirror descent (SMD) in relatively smooth and smooth convex optimization. In relatively smooth convex optimization we provide new convergence guarantees for SMD with a constant stepsize. For smooth convex optimization we propose a new adaptive stepsize scheme -- the mirror stochastic Polyak stepsize (mSPS). Notably, our convergence results in both settings do not make bounded gradient assumptions or bounded variance assumptions, and we show convergence to a neighborhood that vanishes under interpolation. mSPS generalizes the recently proposed stochastic Polyak stepsize (SPS) (Loizou et al., 2021) to mirror descent and remains both practical and efficient for modern machine learning applications while inheriting the benefits of mirror descent. We complement our results with experiments across various supervised learning tasks and different instances of SMD, demonstrating the effectiveness of mSPS.
Extragradient Method: $O(1/K)$ Last-Iterate Convergence for Monotone Variational Inequalities and Connections With Cocoercivity
Oct 08, 2021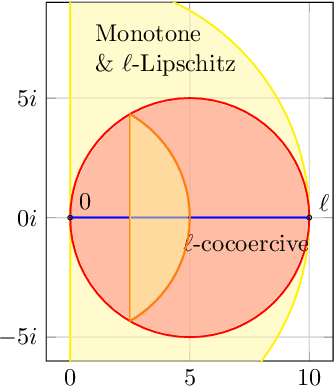
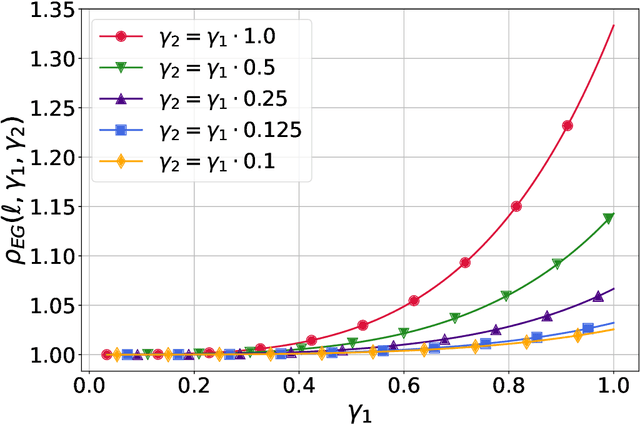
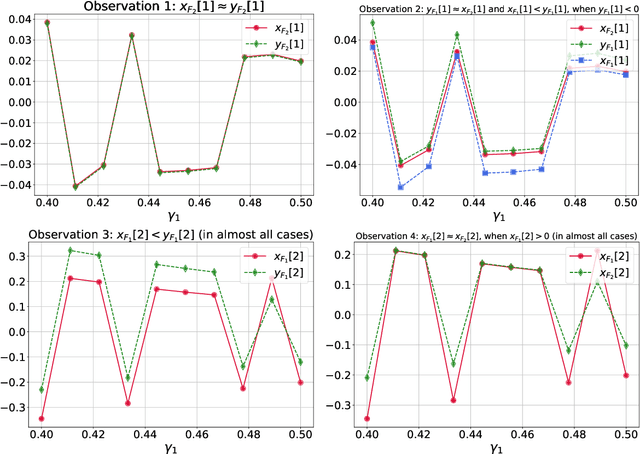
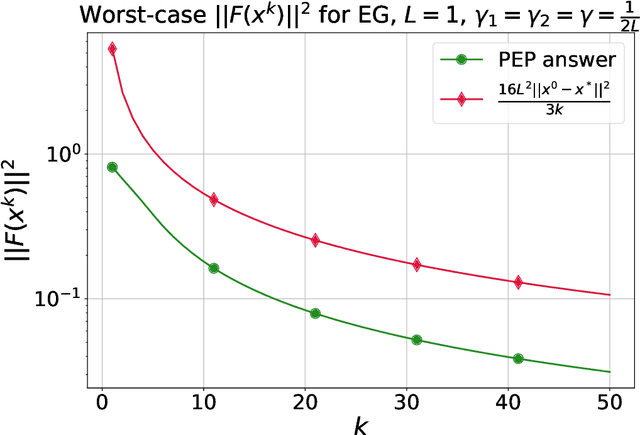
Extragradient method (EG) Korpelevich [1976] is one of the most popular methods for solving saddle point and variational inequalities problems (VIP). Despite its long history and significant attention in the optimization community, there remain important open questions about convergence of EG. In this paper, we resolve one of such questions and derive the first last-iterate $O(1/K)$ convergence rate for EG for monotone and Lipschitz VIP without any additional assumptions on the operator. The rate is given in terms of reducing the squared norm of the operator. Moreover, we establish several results on the (non-)cocoercivity of the update operators of EG, Optimistic Gradient Method, and Hamiltonian Gradient Method, when the original operator is monotone and Lipschitz.
Stochastic Gradient Descent-Ascent and Consensus Optimization for Smooth Games: Convergence Analysis under Expected Co-coercivity
Jun 30, 2021
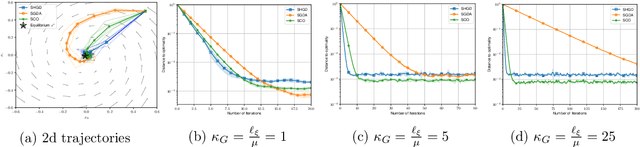
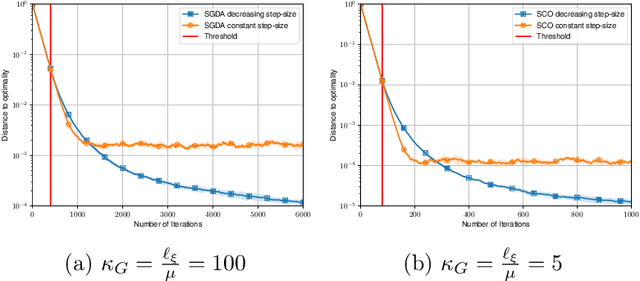
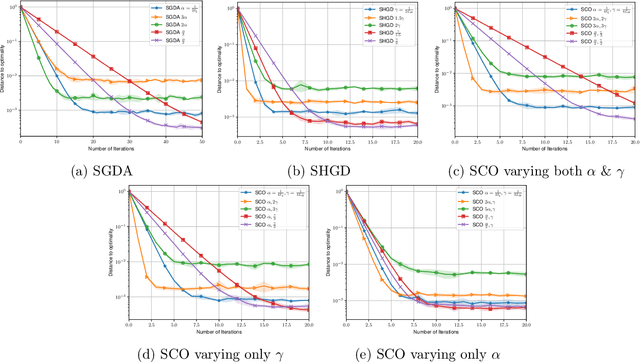
Two of the most prominent algorithms for solving unconstrained smooth games are the classical stochastic gradient descent-ascent (SGDA) and the recently introduced stochastic consensus optimization (SCO) (Mescheder et al., 2017). SGDA is known to converge to a stationary point for specific classes of games, but current convergence analyses require a bounded variance assumption. SCO is used successfully for solving large-scale adversarial problems, but its convergence guarantees are limited to its deterministic variant. In this work, we introduce the expected co-coercivity condition, explain its benefits, and provide the first last-iterate convergence guarantees of SGDA and SCO under this condition for solving a class of stochastic variational inequality problems that are potentially non-monotone. We prove linear convergence of both methods to a neighborhood of the solution when they use constant step-size, and we propose insightful stepsize-switching rules to guarantee convergence to the exact solution. In addition, our convergence guarantees hold under the arbitrary sampling paradigm, and as such, we give insights into the complexity of minibatching.
On the Convergence of Stochastic Extragradient for Bilinear Games with Restarted Iteration Averaging
Jun 30, 2021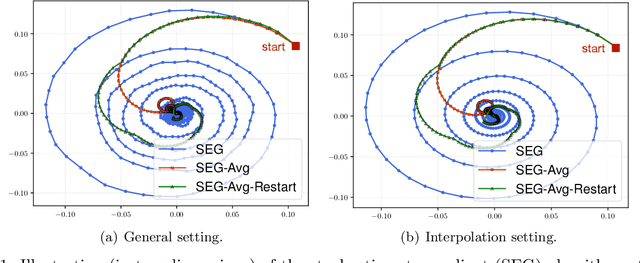
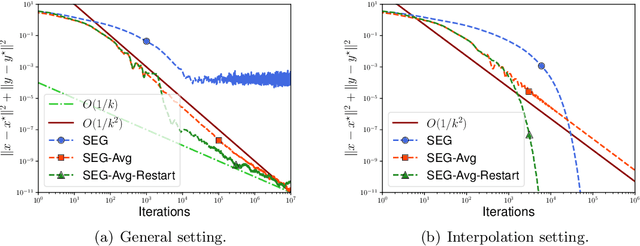
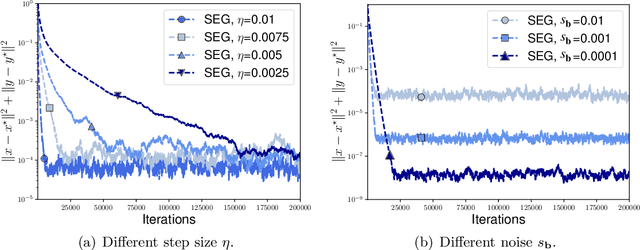
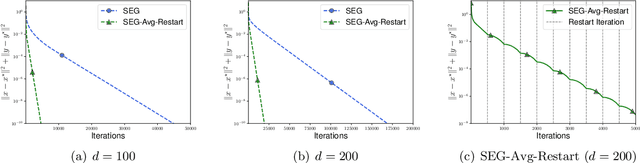
We study the stochastic bilinear minimax optimization problem, presenting an analysis of the Stochastic ExtraGradient (SEG) method with constant step size, and presenting variations of the method that yield favorable convergence. We first note that the last iterate of the basic SEG method only contracts to a fixed neighborhood of the Nash equilibrium, independent of the step size. This contrasts sharply with the standard setting of minimization where standard stochastic algorithms converge to a neighborhood that vanishes in proportion to the square-root (constant) step size. Under the same setting, however, we prove that when augmented with iteration averaging, SEG provably converges to the Nash equilibrium, and such a rate is provably accelerated by incorporating a scheduled restarting procedure. In the interpolation setting, we achieve an optimal convergence rate up to tight constants. We present numerical experiments that validate our theoretical findings and demonstrate the effectiveness of the SEG method when equipped with iteration averaging and restarting.
AI-SARAH: Adaptive and Implicit Stochastic Recursive Gradient Methods
Feb 19, 2021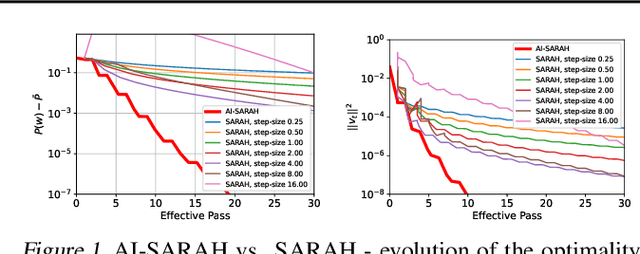
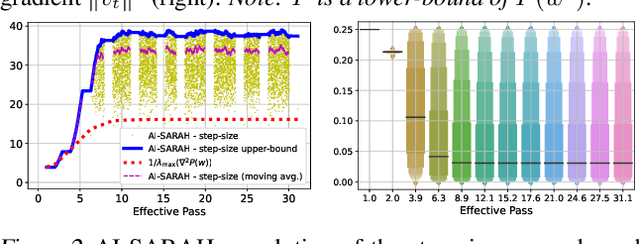
We present an adaptive stochastic variance reduced method with an implicit approach for adaptivity. As a variant of SARAH, our method employs the stochastic recursive gradient yet adjusts step-size based on local geometry. We provide convergence guarantees for finite-sum minimization problems and show a faster convergence than SARAH can be achieved if local geometry permits. Furthermore, we propose a practical, fully adaptive variant, which does not require any knowledge of local geometry and any effort of tuning the hyper-parameters. This algorithm implicitly computes step-size and efficiently estimates local Lipschitz smoothness of stochastic functions. The numerical experiments demonstrate the algorithm's strong performance compared to its classical counterparts and other state-of-the-art first-order methods.
Stochastic Hamiltonian Gradient Methods for Smooth Games
Jul 08, 2020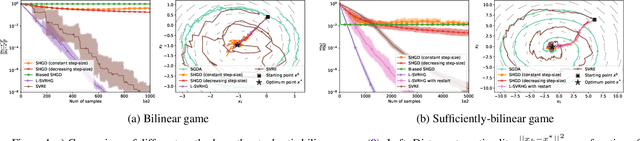

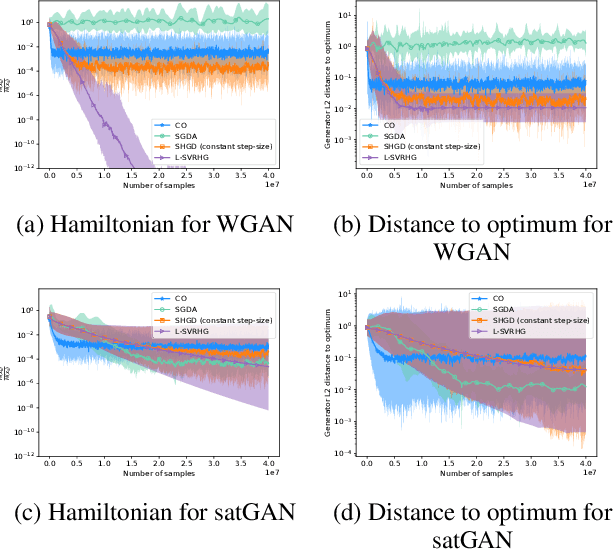

The success of adversarial formulations in machine learning has brought renewed motivation for smooth games. In this work, we focus on the class of stochastic Hamiltonian methods and provide the first convergence guarantees for certain classes of stochastic smooth games. We propose a novel unbiased estimator for the stochastic Hamiltonian gradient descent (SHGD) and highlight its benefits. Using tools from the optimization literature we show that SHGD converges linearly to the neighbourhood of a stationary point. To guarantee convergence to the exact solution, we analyze SHGD with a decreasing step-size and we also present the first stochastic variance reduced Hamiltonian method. Our results provide the first global non-asymptotic last-iterate convergence guarantees for the class of stochastic unconstrained bilinear games and for the more general class of stochastic games that satisfy a "sufficiently bilinear" condition, notably including some non-convex non-concave problems. We supplement our analysis with experiments on stochastic bilinear and sufficiently bilinear games, where our theory is shown to be tight, and on simple adversarial machine learning formulations.