 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023



Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
Towards Dialogue Systems with Agency in Human-AI Collaboration Tasks
May 22, 2023



Agency, the capacity to proactively shape events, is crucial to how humans interact and collaborate with other humans. In this paper, we investigate Agency as a potentially desirable function of dialogue agents, and how it can be measured and controlled. We build upon the social-cognitive theory of Bandura (2001) to develop a framework of features through which Agency is expressed in dialogue -- indicating what you intend to do (Intentionality), motivating your intentions (Motivation), having self-belief in intentions (Self-Efficacy), and being able to self-adjust (Self-Regulation). We collect and release a new dataset of 83 human-human collaborative interior design conversations containing 908 conversational snippets annotated for Agency features. Using this dataset, we explore methods for measuring and controlling Agency in dialogue systems. Automatic and human evaluation show that although a baseline GPT-3 model can express Intentionality, models that explicitly manifest features associated with high Motivation, Self-Efficacy, and Self-Regulation are better perceived as being highly agentive. This work has implications for the development of dialogue systems with varying degrees of Agency in collaborative tasks.
Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling
May 17, 2023



We introduce Reprompting, an iterative sampling algorithm that searches for the Chain-of-Thought (CoT) recipes for a given task without human intervention. Through Gibbs sampling, we infer CoT recipes that work consistently well for a set of training samples. Our method iteratively samples new recipes using previously sampled solutions as parent prompts to solve other training problems. On five Big-Bench Hard tasks that require multi-step reasoning, Reprompting achieves consistently better performance than the zero-shot, few-shot, and human-written CoT baselines. Reprompting can also facilitate transfer of knowledge from a stronger model to a weaker model leading to substantially improved performance of the weaker model. Overall, Reprompting brings up to +17 point improvements over the previous state-of-the-art method that uses human-written CoT prompts.
GPT is becoming a Turing machine: Here are some ways to program it
Mar 25, 2023


We demonstrate that, through appropriate prompting, GPT-3 family of models can be triggered to perform iterative behaviours necessary to execute (rather than just write or recall) programs that involve loops, including several popular algorithms found in computer science curricula or software developer interviews. We trigger execution and description of Iterations by Regimenting Self-Attention (IRSA) in one (or a combination) of three ways: 1) Using strong repetitive structure in an example of an execution path of a target program for one particular input, 2) Prompting with fragments of execution paths, and 3) Explicitly forbidding (skipping) self-attention to parts of the generated text. On a dynamic program execution, IRSA leads to larger accuracy gains than replacing the model with the much more powerful GPT-4. IRSA has promising applications in education, as the prompts and responses resemble student assignments in data structures and algorithms classes. Our findings hold implications for evaluating LLMs, which typically target the in-context learning: We show that prompts that may not even cover one full task example can trigger algorithmic behaviour, allowing solving problems previously thought of as hard for LLMs, such as logical puzzles. Consequently, prompt design plays an even more critical role in LLM performance than previously recognized.
ThinkSum: Probabilistic reasoning over sets using large language models
Oct 04, 2022
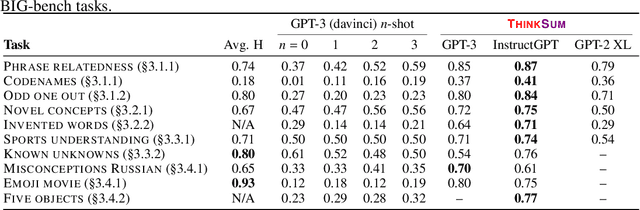
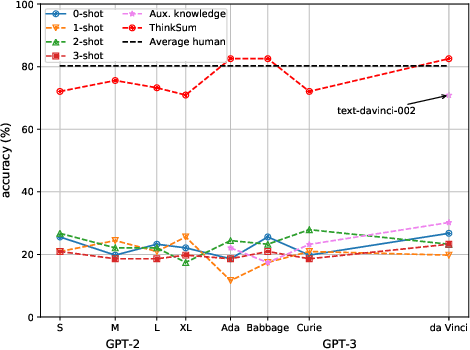
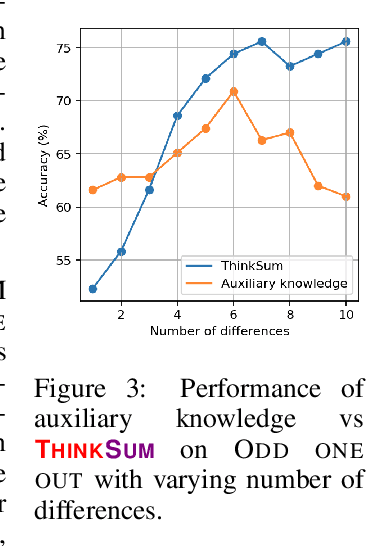
Large language models (LLMs) have a substantial capacity for high-level analogical reasoning: reproducing patterns in linear text that occur in their training data (zero-shot evaluation) or in the provided context (few-shot in-context learning). However, recent studies show that even the largest LLMs fail in scenarios that require reasoning over multiple objects or facts or making sequences of logical deductions. We propose a two-stage probabilistic inference paradigm, ThinkSum, that reasons over sets of objects or facts in a structured manner. In the first stage (Think -- 'fast' retrieval of associations), a LLM is queried in parallel over a set of phrases extracted from the prompt or an auxiliary model call. In the second stage (Sum -- 'slow' probabilistic inference or reasoning), the results of these queries are aggregated to make the final prediction. We demonstrate the advantages of ThinkSum on the BIG-bench suite of evaluation tasks, achieving improvements over the state of the art using GPT-family models on ten difficult tasks, often with far smaller model variants. We compare and contrast ThinkSum with other proposed modifications to direct prompting of LLMs, such as variants of chain-of-thought prompting. We argue that because the probabilistic inference in ThinkSum is performed outside of calls to the LLM, ThinkSum is less sensitive to prompt design, yields more interpretable predictions, and can be flexibly combined with latent variable models to extract structured knowledge from LLMs.
Diffusion models as plug-and-play priors
Jun 17, 2022
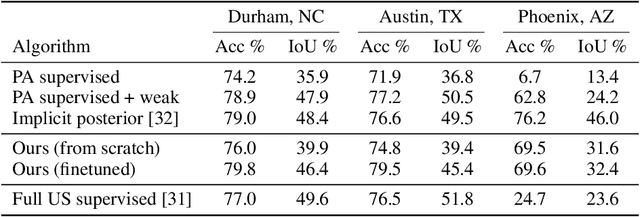

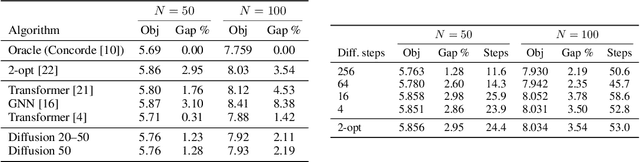
We consider the problem of inferring high-dimensional data $\mathbf{x}$ in a model that consists of a prior $p(\mathbf{x})$ and an auxiliary constraint $c(\mathbf{x},\mathbf{y})$. In this paper, the prior is an independently trained denoising diffusion generative model. The auxiliary constraint is expected to have a differentiable form, but can come from diverse sources. The possibility of such inference turns diffusion models into plug-and-play modules, thereby allowing a range of potential applications in adapting models to new domains and tasks, such as conditional generation or image segmentation. The structure of diffusion models allows us to perform approximate inference by iterating differentiation through the fixed denoising network enriched with different amounts of noise at each step. Considering many noised versions of $\mathbf{x}$ in evaluation of its fitness is a novel search mechanism that may lead to new algorithms for solving combinatorial optimization problems.
Resolving label uncertainty with implicit posterior models
Feb 28, 2022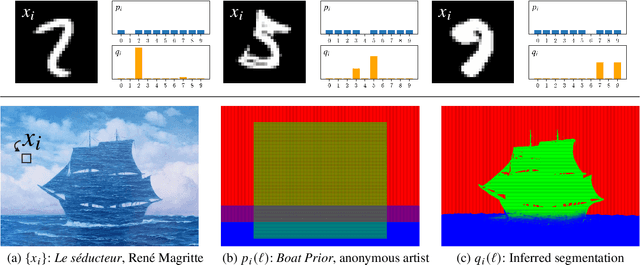
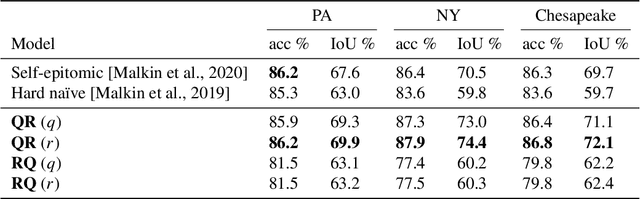
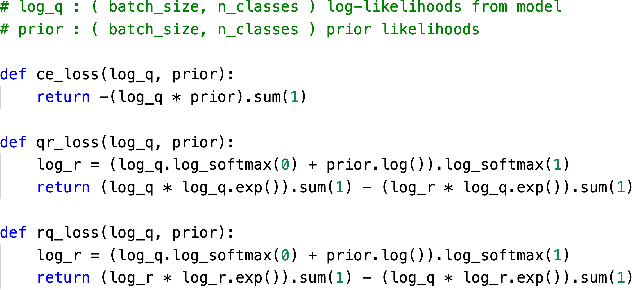
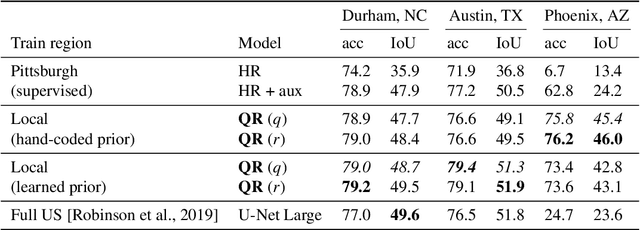
We propose a method for jointly inferring labels across a collection of data samples, where each sample consists of an observation and a prior belief about the label. By implicitly assuming the existence of a generative model for which a differentiable predictor is the posterior, we derive a training objective that allows learning under weak beliefs. This formulation unifies various machine learning settings; the weak beliefs can come in the form of noisy or incomplete labels, likelihoods given by a different prediction mechanism on auxiliary input, or common-sense priors reflecting knowledge about the structure of the problem at hand. We demonstrate the proposed algorithms on diverse problems: classification with negative training examples, learning from rankings, weakly and self-supervised aerial imagery segmentation, co-segmentation of video frames, and coarsely supervised text classification.
Boosting coherence of language models
Oct 15, 2021
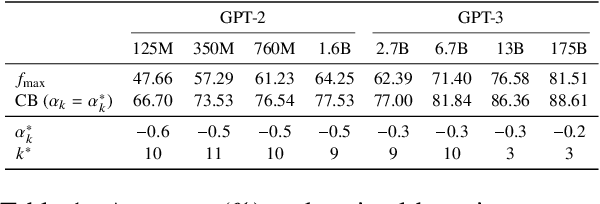
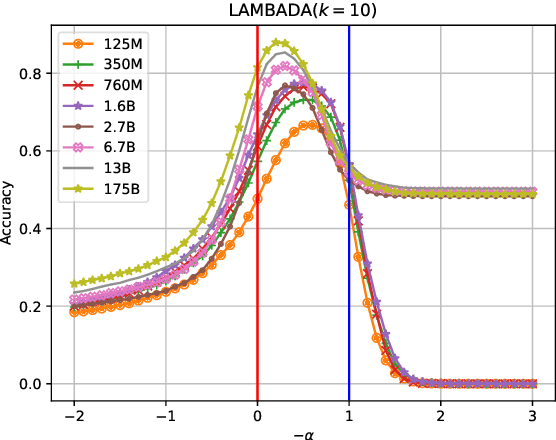
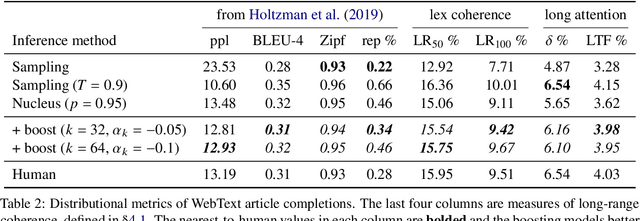
Naturality of long-term information structure -- coherence -- remains a challenge in language generation. Large language models have insufficiently learned such structure, as their long-form generations differ from natural text in measures of coherence. To alleviate this divergence, we propose coherence boosting, an inference procedure that increases the effect of distant context on next-token prediction. We show the benefits of coherence boosting with pretrained models by distributional analyses of generated ordinary text and dialog responses. We also find that coherence boosting with state-of-the-art models for various zero-shot NLP tasks yields performance gains with no additional training.
Studying word order through iterative shuffling
Sep 10, 2021
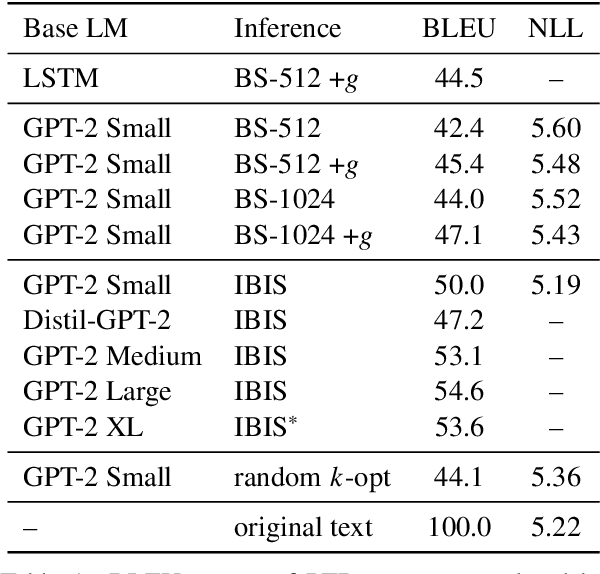


As neural language models approach human performance on NLP benchmark tasks, their advances are widely seen as evidence of an increasingly complex understanding of syntax. This view rests upon a hypothesis that has not yet been empirically tested: that word order encodes meaning essential to performing these tasks. We refute this hypothesis in many cases: in the GLUE suite and in various genres of English text, the words in a sentence or phrase can rarely be permuted to form a phrase carrying substantially different information. Our surprising result relies on inference by iterative shuffling (IBIS), a novel, efficient procedure that finds the ordering of a bag of words having the highest likelihood under a fixed language model. IBIS can use any black-box model without additional training and is superior to existing word ordering algorithms. Coalescing our findings, we discuss how shuffling inference procedures such as IBIS can benefit language modeling and constrained generation.
Multi-Label Learning from Single Positive Labels
Jun 17, 2021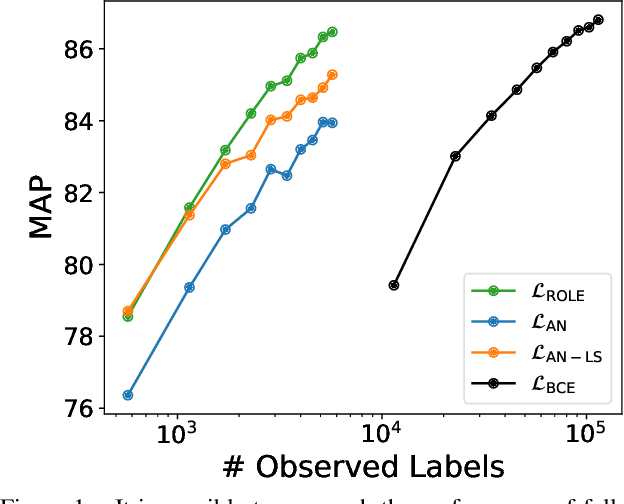
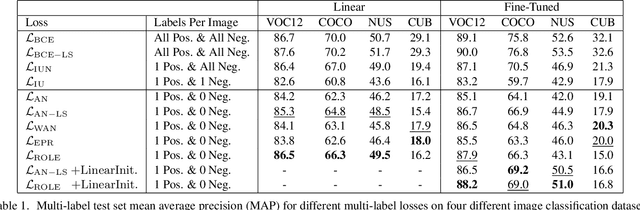
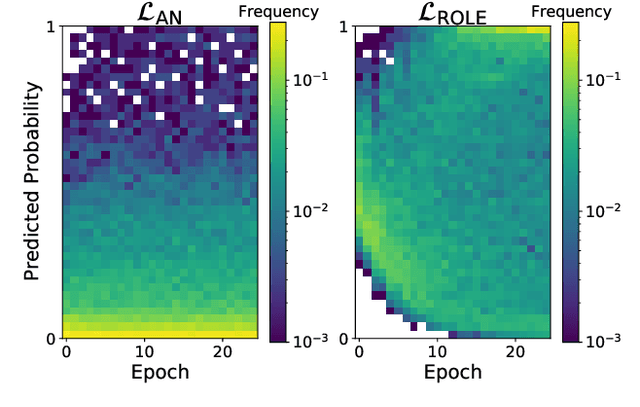
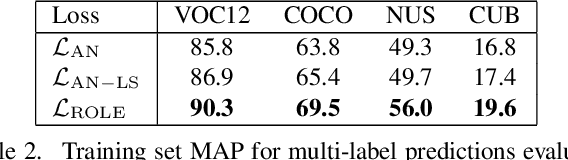
Predicting all applicable labels for a given image is known as multi-label classification. Compared to the standard multi-class case (where each image has only one label), it is considerably more challenging to annotate training data for multi-label classification. When the number of potential labels is large, human annotators find it difficult to mention all applicable labels for each training image. Furthermore, in some settings detection is intrinsically difficult e.g. finding small object instances in high resolution images. As a result, multi-label training data is often plagued by false negatives. We consider the hardest version of this problem, where annotators provide only one relevant label for each image. As a result, training sets will have only one positive label per image and no confirmed negatives. We explore this special case of learning from missing labels across four different multi-label image classification datasets for both linear classifiers and end-to-end fine-tuned deep networks. We extend existing multi-label losses to this setting and propose novel variants that constrain the number of expected positive labels during training. Surprisingly, we show that in some cases it is possible to approach the performance of fully labeled classifiers despite training with significantly fewer confirmed labels.