 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speaker Diarization: Current Databases, Approaches and Challenges
Sep 09, 2024Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.
Direct Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023



Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
Class Token and Knowledge Distillation for Multi-head Self-Attention Speaker Verification Systems
Nov 06, 2021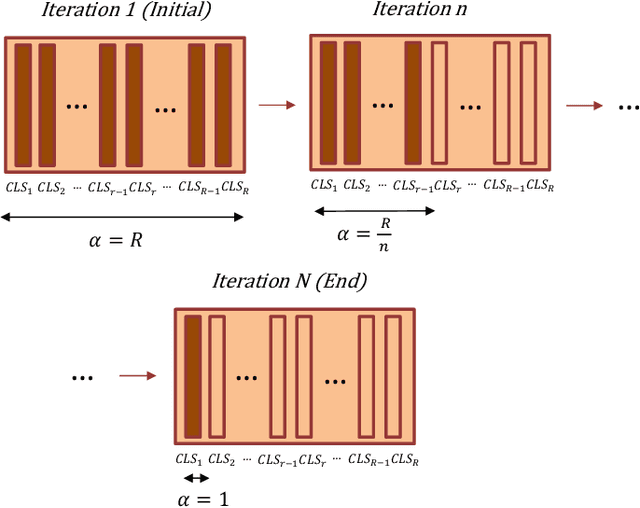
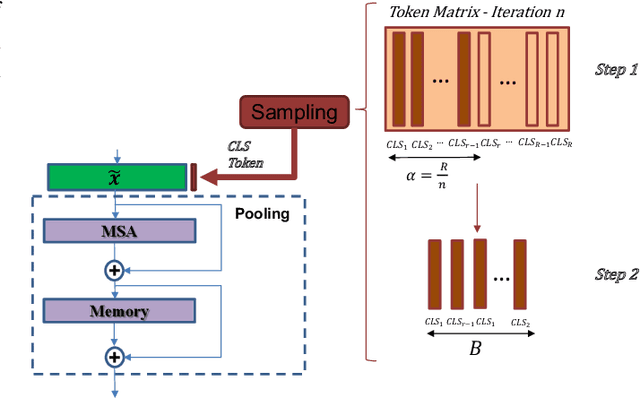
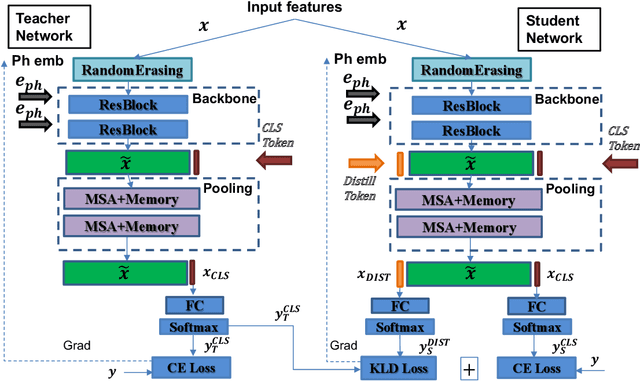
This paper explores three novel approaches to improve the performance of speaker verification (SV) systems based on deep neural networks (DNN) using Multi-head Self-Attention (MSA) mechanisms and memory layers. Firstly, we propose the use of a learnable vector called Class token to replace the average global pooling mechanism to extract the embeddings. Unlike global average pooling, our proposal takes into account the temporal structure of the input what is relevant for the text-dependent SV task. The class token is concatenated to the input before the first MSA layer, and its state at the output is used to predict the classes. To gain additional robustness, we introduce two approaches. First, we have developed a Bayesian estimation of the class token. Second, we have added a distilled representation token for training a teacher-student pair of networks using the Knowledge Distillation (KD) philosophy, which is combined with the class token. This distillation token is trained to mimic the predictions from the teacher network, while the class token replicates the true label. All the strategies have been tested on the RSR2015-Part II and DeepMine-Part 1 databases for text-dependent SV, providing competitive results compared to the same architecture using the average pooling mechanism to extract average embeddings.
Generalizing AUC Optimization to Multiclass Classification for Audio Segmentation With Limited Training Data
Oct 27, 2021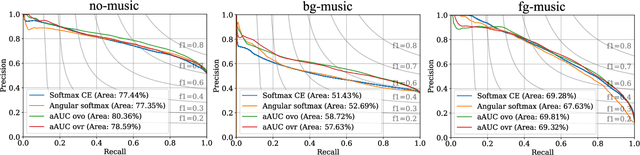
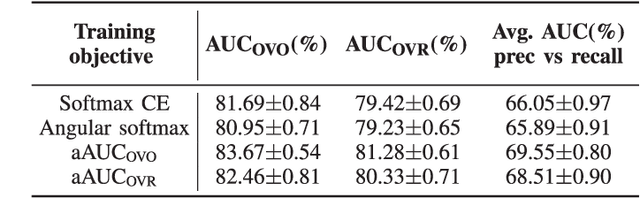

Area under the ROC curve (AUC) optimisation techniques developed for neural networks have recently demonstrated their capabilities in different audio and speech related tasks. However, due to its intrinsic nature, AUC optimisation has focused only on binary tasks so far. In this paper, we introduce an extension to the AUC optimisation framework so that it can be easily applied to an arbitrary number of classes, aiming to overcome the issues derived from training data limitations in deep learning solutions. Building upon the multiclass definitions of the AUC metric found in the literature, we define two new training objectives using a one-versus-one and a one-versus-rest approach. In order to demonstrate its potential, we apply them in an audio segmentation task with limited training data that aims to differentiate 3 classes: foreground music, background music and no music. Experimental results show that our proposal can improve the performance of audio segmentation systems significantly compared to traditional training criteria such as cross entropy.
Optimization of the Area Under the ROC Curve using Neural Network Supervectors for Text-Dependent Speaker Verification
Jan 31, 2019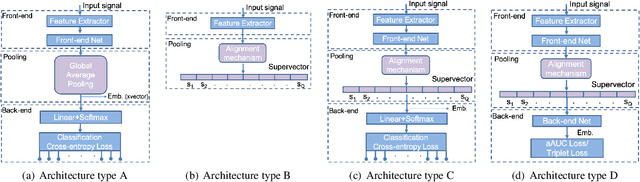
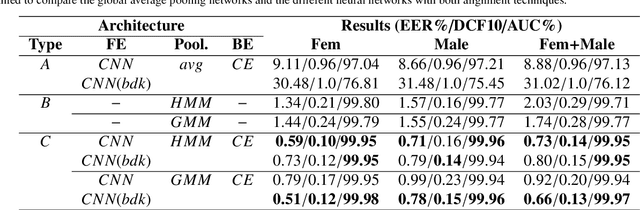

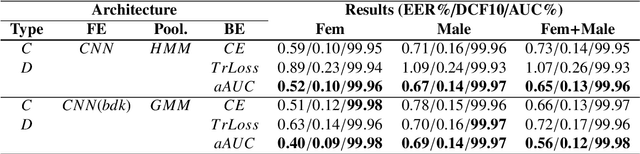
This paper explores two techniques to improve the performance of text-dependent speaker verification systems based on deep neural networks. Firstly, we propose a general alignment mechanism to keep the temporal structure of each phrase and obtain a supervector with the speaker and phrase information, since both are relevant for a text-dependent verification. As we show, it is possible to use different alignment techniques to replace the average pooling providing significant gains in performance. Moreover, we present a novel back-end approach to train a neural network for detection tasks by optimizing the Area Under the Curve (AUC) as an alternative to the usual triplet loss function, so the system is end-to-end, with a cost function closed to our desired measure of performance. As we can see in the experimental section, this approach improves the system performance, since our triplet AUC neural network learns how to discriminate between pairs of examples from the same identity and pairs of different identities. The different alignment techniques to produce supervectors in addition to the new back-end approach were tested on the RSR2015-Part I database for text-dependent speaker verification, providing competitive results compared to similar size networks using the average pooling to extract supervectors and using a simple back-end or triplet loss training.
Differentiable Supervector Extraction for Encoding Speaker and Phrase Information in Text Dependent Speaker Verification
Dec 22, 2018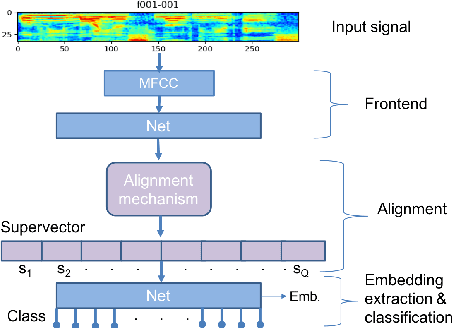
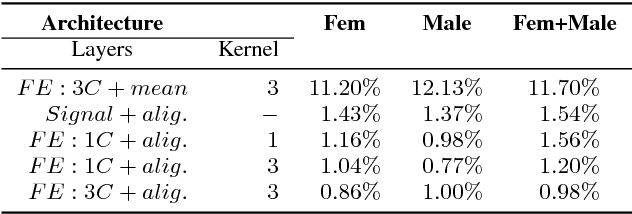
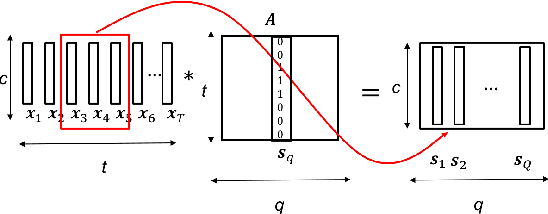
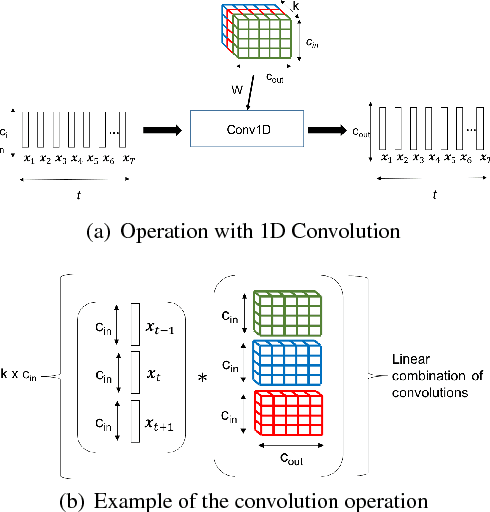
In this paper, we propose a new differentiable neural network alignment mechanism for text-dependent speaker verification which uses alignment models to produce a supervector representation of an utterance. Unlike previous works with similar approaches, we do not extract the embedding of an utterance from the mean reduction of the temporal dimension. Our system replaces the mean by a phrase alignment model to keep the temporal structure of each phrase which is relevant in this application since the phonetic information is part of the identity in the verification task. Moreover, we can apply a convolutional neural network as front-end, and thanks to the alignment process being differentiable, we can train the whole network to produce a supervector for each utterance which will be discriminative with respect to the speaker and the phrase simultaneously. As we show, this choice has the advantage that the supervector encodes the phrase and speaker information providing good performance in text-dependent speaker verification tasks. In this work, the process of verification is performed using a basic similarity metric, due to simplicity, compared to other more elaborate models that are commonly used. The new model using alignment to produce supervectors was tested on the RSR2015-Part I database for text-dependent speaker verification, providing competitive results compared to similar size networks using the mean to extract embeddings.