 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Jan 07, 2026World models have become central to autonomous driving, where accurate scene understanding and future prediction are crucial for safe control. Recent work has explored using vision-language models (VLMs) for planning, yet existing approaches typically treat perception, prediction, and planning as separate modules. We propose UniDrive-WM, a unified VLM-based world model that jointly performs driving-scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture. UniDrive-WM's trajectory planner predicts a future trajectory, which conditions a VLM-based image generator to produce plausible future frames. These predictions provide additional supervisory signals that enhance scene understanding and iteratively refine trajectory generation. We further compare discrete and continuous output representations for future image prediction, analyzing their influence on downstream driving performance. Experiments on the challenging Bench2Drive benchmark show that UniDrive-WM produces high-fidelity future images and improves planning performance by 5.9% in L2 trajectory error and 9.2% in collision rate over the previous best method. These results demonstrate the advantages of tightly integrating VLM-driven reasoning, planning, and generative world modeling for autonomous driving. The project page is available at https://unidrive-wm.github.io/UniDrive-WM .
VectorSynth: Fine-Grained Satellite Image Synthesis with Structured Semantics
Nov 11, 2025We introduce VectorSynth, a diffusion-based framework for pixel-accurate satellite image synthesis conditioned on polygonal geographic annotations with semantic attributes. Unlike prior text- or layout-conditioned models, VectorSynth learns dense cross-modal correspondences that align imagery and semantic vector geometry, enabling fine-grained, spatially grounded edits. A vision language alignment module produces pixel-level embeddings from polygon semantics; these embeddings guide a conditional image generation framework to respect both spatial extents and semantic cues. VectorSynth supports interactive workflows that mix language prompts with geometry-aware conditioning, allowing rapid what-if simulations, spatial edits, and map-informed content generation. For training and evaluation, we assemble a collection of satellite scenes paired with pixel-registered polygon annotations spanning diverse urban scenes with both built and natural features. We observe strong improvements over prior methods in semantic fidelity and structural realism, and show that our trained vision language model demonstrates fine-grained spatial grounding. The code and data are available at https://github.com/mvrl/VectorSynth.
Beta Distribution Learning for Reliable Roadway Crash Risk Assessment
Nov 07, 2025



Roadway traffic accidents represent a global health crisis, responsible for over a million deaths annually and costing many countries up to 3% of their GDP. Traditional traffic safety studies often examine risk factors in isolation, overlooking the spatial complexity and contextual interactions inherent in the built environment. Furthermore, conventional Neural Network-based risk estimators typically generate point estimates without conveying model uncertainty, limiting their utility in critical decision-making. To address these shortcomings, we introduce a novel geospatial deep learning framework that leverages satellite imagery as a comprehensive spatial input. This approach enables the model to capture the nuanced spatial patterns and embedded environmental risk factors that contribute to fatal crash risks. Rather than producing a single deterministic output, our model estimates a full Beta probability distribution over fatal crash risk, yielding accurate and uncertainty-aware predictions--a critical feature for trustworthy AI in safety-critical applications. Our model outperforms baselines by achieving a 17-23% improvement in recall, a key metric for flagging potential dangers, while delivering superior calibration. By providing reliable and interpretable risk assessments from satellite imagery alone, our method enables safer autonomous navigation and offers a highly scalable tool for urban planners and policymakers to enhance roadway safety equitably and cost-effectively.
Global and Local Entailment Learning for Natural World Imagery
Jun 26, 2025Learning the hierarchical structure of data in vision-language models is a significant challenge. Previous works have attempted to address this challenge by employing entailment learning. However, these approaches fail to model the transitive nature of entailment explicitly, which establishes the relationship between order and semantics within a representation space. In this work, we introduce Radial Cross-Modal Embeddings (RCME), a framework that enables the explicit modeling of transitivity-enforced entailment. Our proposed framework optimizes for the partial order of concepts within vision-language models. By leveraging our framework, we develop a hierarchical vision-language foundation model capable of representing the hierarchy in the Tree of Life. Our experiments on hierarchical species classification and hierarchical retrieval tasks demonstrate the enhanced performance of our models compared to the existing state-of-the-art models. Our code and models are open-sourced at https://vishu26.github.io/RCME/index.html.
QuARI: Query Adaptive Retrieval Improvement
May 27, 2025



Massive-scale pretraining has made vision-language models increasingly popular for image-to-image and text-to-image retrieval across a broad collection of domains. However, these models do not perform well when used for challenging retrieval tasks, such as instance retrieval in very large-scale image collections. Recent work has shown that linear transformations of VLM features trained for instance retrieval can improve performance by emphasizing subspaces that relate to the domain of interest. In this paper, we explore a more extreme version of this specialization by learning to map a given query to a query-specific feature space transformation. Because this transformation is linear, it can be applied with minimal computational cost to millions of image embeddings, making it effective for large-scale retrieval or re-ranking. Results show that this method consistently outperforms state-of-the-art alternatives, including those that require many orders of magnitude more computation at query time.
ConText-CIR: Learning from Concepts in Text for Composed Image Retrieval
May 27, 2025



Composed image retrieval (CIR) is the task of retrieving a target image specified by a query image and a relative text that describes a semantic modification to the query image. Existing methods in CIR struggle to accurately represent the image and the text modification, resulting in subpar performance. To address this limitation, we introduce a CIR framework, ConText-CIR, trained with a Text Concept-Consistency loss that encourages the representations of noun phrases in the text modification to better attend to the relevant parts of the query image. To support training with this loss function, we also propose a synthetic data generation pipeline that creates training data from existing CIR datasets or unlabeled images. We show that these components together enable stronger performance on CIR tasks, setting a new state-of-the-art in composed image retrieval in both the supervised and zero-shot settings on multiple benchmark datasets, including CIRR and CIRCO. Source code, model checkpoints, and our new datasets are available at https://github.com/mvrl/ConText-CIR.
Sat2Sound: A Unified Framework for Zero-Shot Soundscape Mapping
May 19, 2025We present Sat2Sound, a multimodal representation learning framework for soundscape mapping, designed to predict the distribution of sounds at any location on Earth. Existing methods for this task rely on satellite image and paired geotagged audio samples, which often fail to capture the diversity of sound sources at a given location. To address this limitation, we enhance existing datasets by leveraging a Vision-Language Model (VLM) to generate semantically rich soundscape descriptions for locations depicted in satellite images. Our approach incorporates contrastive learning across audio, audio captions, satellite images, and satellite image captions. We hypothesize that there is a fixed set of soundscape concepts shared across modalities. To this end, we learn a shared codebook of soundscape concepts and represent each sample as a weighted average of these concepts. Sat2Sound achieves state-of-the-art performance in cross-modal retrieval between satellite image and audio on two datasets: GeoSound and SoundingEarth. Additionally, building on Sat2Sound's ability to retrieve detailed soundscape captions, we introduce a novel application: location-based soundscape synthesis, which enables immersive acoustic experiences. Our code and models will be publicly available.
PanoDreamer: Consistent Text to 360-Degree Scene Generation
Apr 07, 2025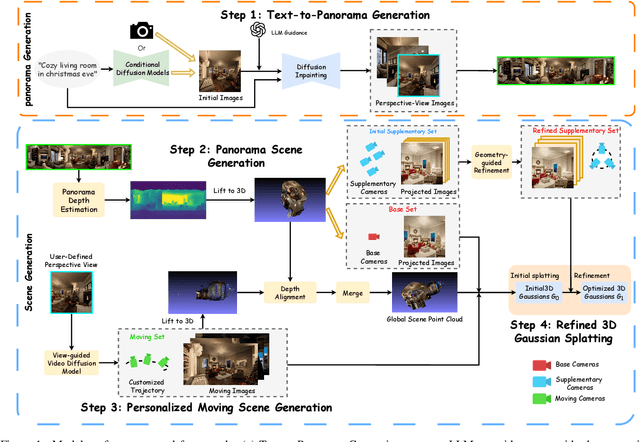

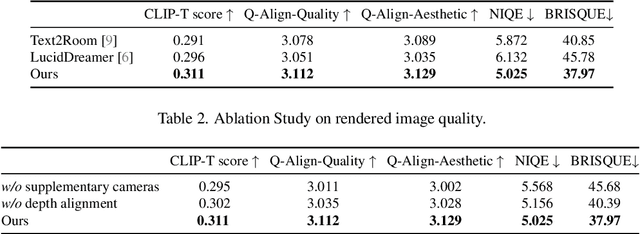

Automatically generating a complete 3D scene from a text description, a reference image, or both has significant applications in fields like virtual reality and gaming. However, current methods often generate low-quality textures and inconsistent 3D structures. This is especially true when extrapolating significantly beyond the field of view of the reference image. To address these challenges, we propose PanoDreamer, a novel framework for consistent, 3D scene generation with flexible text and image control. Our approach employs a large language model and a warp-refine pipeline, first generating an initial set of images and then compositing them into a 360-degree panorama. This panorama is then lifted into 3D to form an initial point cloud. We then use several approaches to generate additional images, from different viewpoints, that are consistent with the initial point cloud and expand/refine the initial point cloud. Given the resulting set of images, we utilize 3D Gaussian Splatting to create the final 3D scene, which can then be rendered from different viewpoints. Experiments demonstrate the effectiveness of PanoDreamer in generating high-quality, geometrically consistent 3D scenes.
DeclutterNeRF: Generative-Free 3D Scene Recovery for Occlusion Removal
Apr 07, 2025Recent novel view synthesis (NVS) techniques, including Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly advanced 3D scene reconstruction with high-quality rendering and realistic detail recovery. Effectively removing occlusions while preserving scene details can further enhance the robustness and applicability of these techniques. However, existing approaches for object and occlusion removal predominantly rely on generative priors, which, despite filling the resulting holes, introduce new artifacts and blurriness. Moreover, existing benchmark datasets for evaluating occlusion removal methods lack realistic complexity and viewpoint variations. To address these issues, we introduce DeclutterSet, a novel dataset featuring diverse scenes with pronounced occlusions distributed across foreground, midground, and background, exhibiting substantial relative motion across viewpoints. We further introduce DeclutterNeRF, an occlusion removal method free from generative priors. DeclutterNeRF introduces joint multi-view optimization of learnable camera parameters, occlusion annealing regularization, and employs an explainable stochastic structural similarity loss, ensuring high-quality, artifact-free reconstructions from incomplete images. Experiments demonstrate that DeclutterNeRF significantly outperforms state-of-the-art methods on our proposed DeclutterSet, establishing a strong baseline for future research.
GenStereo: Towards Open-World Generation of Stereo Images and Unsupervised Matching
Mar 17, 2025Stereo images are fundamental to numerous applications, including extended reality (XR) devices, autonomous driving, and robotics. Unfortunately, acquiring high-quality stereo images remains challenging due to the precise calibration requirements of dual-camera setups and the complexity of obtaining accurate, dense disparity maps. Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. Our framework eliminates the need for complex hardware setups while enabling high-quality stereo image generation, making it valuable for both real-world applications and unsupervised learning scenarios. Project page is available at https://qjizhi.github.io/genstereo