 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Trained Proposal Networks for the Open World
Aug 23, 2022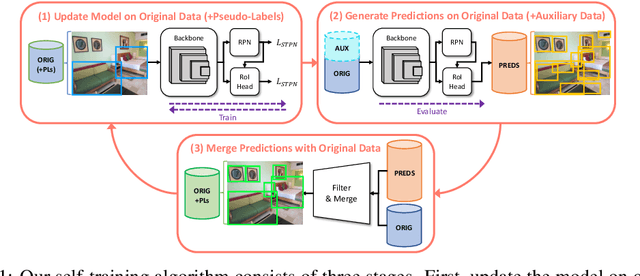
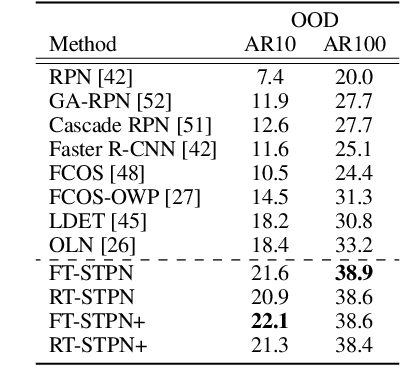
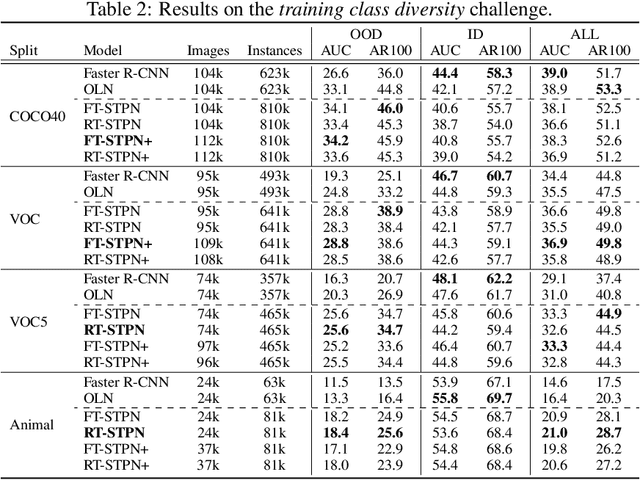
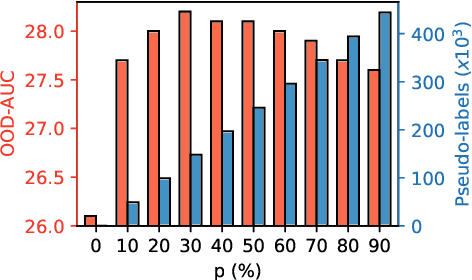
Deep learning-based object proposal methods have enabled significant advances in many computer vision pipelines. However, current state-of-the-art proposal networks use a closed-world assumption, meaning they are only trained to detect instances of the training classes while treating every other region as background. This style of solution fails to provide high recall on out-of-distribution objects, rendering it inadequate for use in realistic open-world applications where novel object categories of interest may be observed. To better detect all objects, we propose a classification-free Self-Trained Proposal Network (STPN) that leverages a novel self-training optimization strategy combined with dynamically weighted loss functions that account for challenges such as class imbalance and pseudo-label uncertainty. Not only is our model designed to excel in existing optimistic open-world benchmarks, but also in challenging operating environments where there is significant label bias. To showcase this, we devise two challenges to test the generalization of proposal models when the training data contains (1) less diversity within the labeled classes, and (2) fewer labeled instances. Our results show that STPN achieves state-of-the-art novel object generalization on all tasks.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
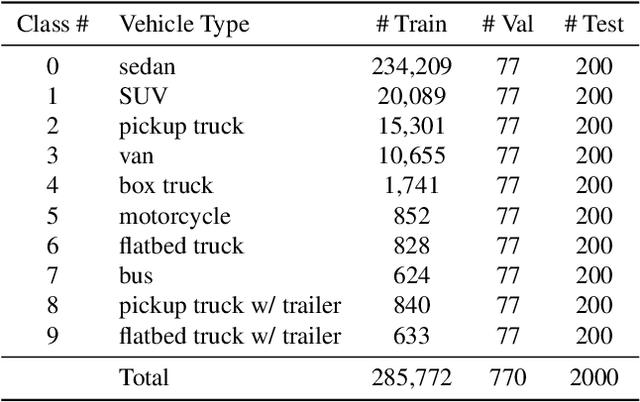
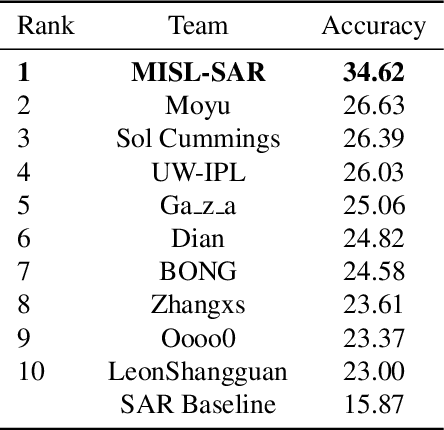
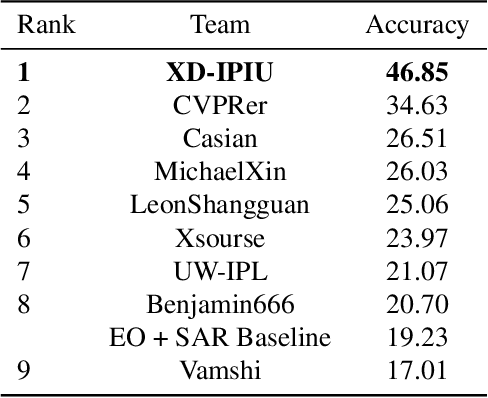
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
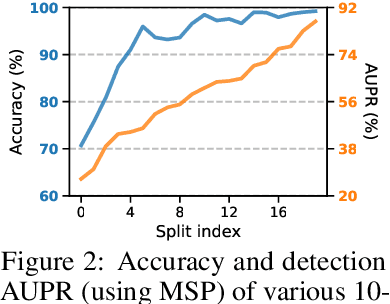
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
Fine-grained Out-of-Distribution Detection with Mixup Outlier Exposure
Jun 07, 2021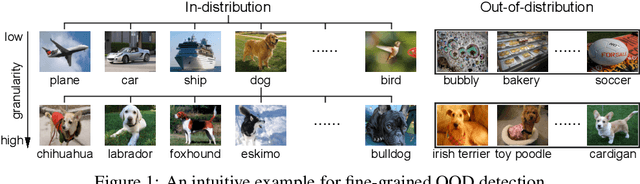
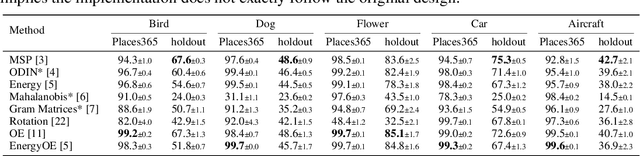

Enabling out-of-distribution (OOD) detection for DNNs is critical for their safe and reliable operation in the "open world". Unfortunately, current works in both methodology and evaluation focus on rather contrived detection problems, and only consider a coarse level of granularity w.r.t.: 1) the in-distribution (ID) classes, and 2) the OOD data's "closeness" to the ID data. We posit that such settings may be poor approximations of many real-world tasks that are naturally fine-grained (e.g., bird species classification), and thus the reported detection abilities may be over-estimates. Differently, in this work we make granularity a top priority and focus on fine-grained OOD detection. We start by carefully constructing five novel fine-grained test environments in which existing methods are shown to have difficulties. We then propose a new DNN training algorithm, Mixup Outlier Exposure (MixupOE), which leverages an outlier distribution and principles from vicinal risk minimization. Finally, we perform extensive experiments and analyses in our custom test environments and demonstrate that MixupOE can consistently improve fine-grained detection performance, establishing a strong baseline in these more realistic and challenging OOD detection settings.
Can Targeted Adversarial Examples Transfer When the Source and Target Models Have No Label Space Overlap?
Mar 17, 2021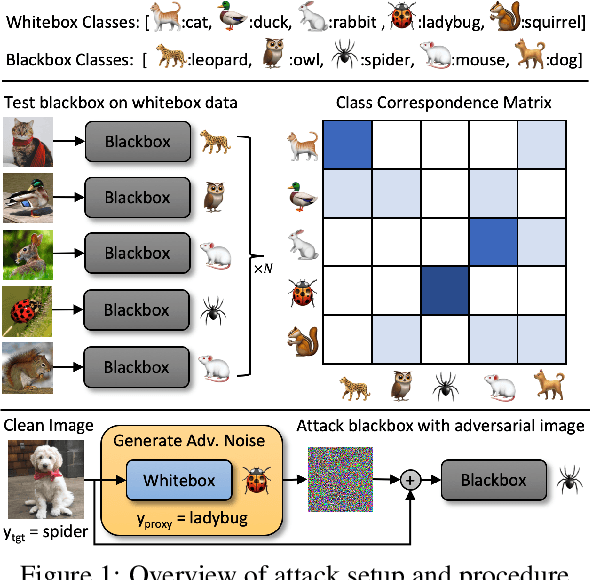
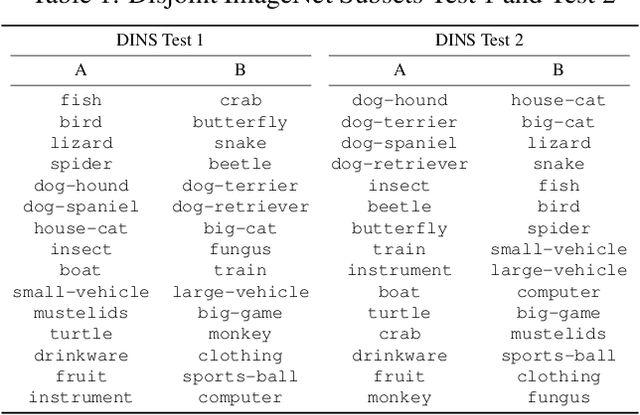
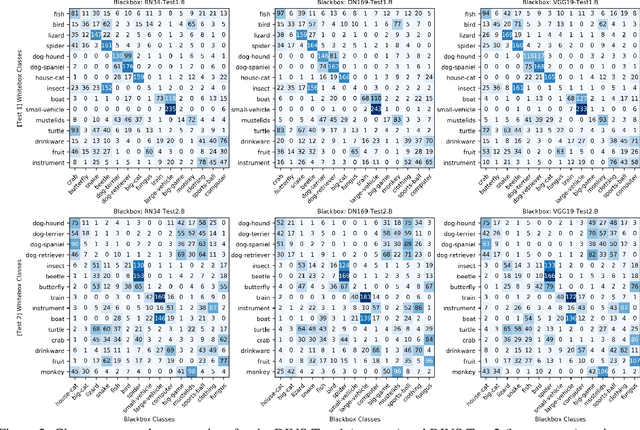
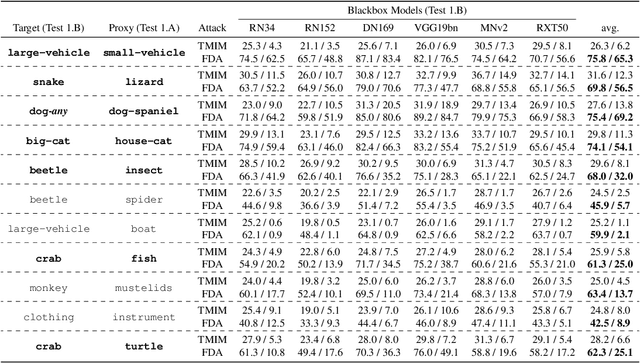
We design blackbox transfer-based targeted adversarial attacks for an environment where the attacker's source model and the target blackbox model may have disjoint label spaces and training datasets. This scenario significantly differs from the "standard" blackbox setting, and warrants a unique approach to the attacking process. Our methodology begins with the construction of a class correspondence matrix between the whitebox and blackbox label sets. During the online phase of the attack, we then leverage representations of highly related proxy classes from the whitebox distribution to fool the blackbox model into predicting the desired target class. Our attacks are evaluated in three complex and challenging test environments where the source and target models have varying degrees of conceptual overlap amongst their unique categories. Ultimately, we find that it is indeed possible to construct targeted transfer-based adversarial attacks between models that have non-overlapping label spaces! We also analyze the sensitivity of attack success to properties of the clean data. Finally, we show that our transfer attacks serve as powerful adversarial priors when integrated with query-based methods, markedly boosting query efficiency and adversarial success.
The Untapped Potential of Off-the-Shelf Convolutional Neural Networks
Mar 17, 2021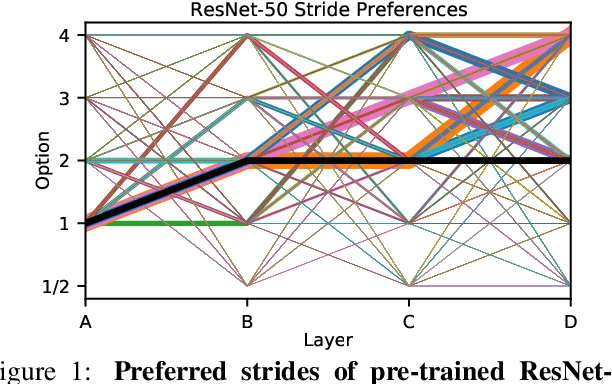
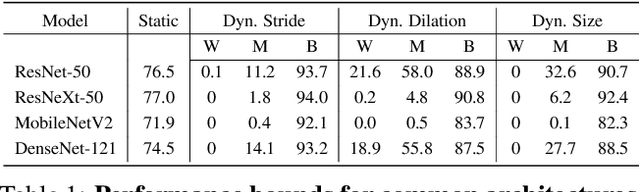
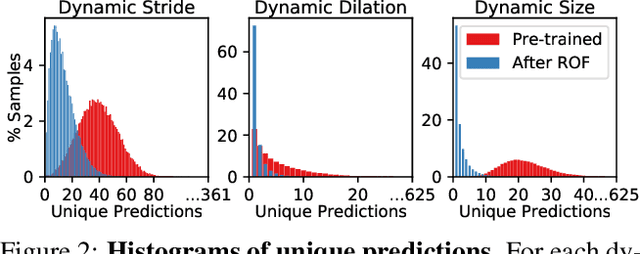
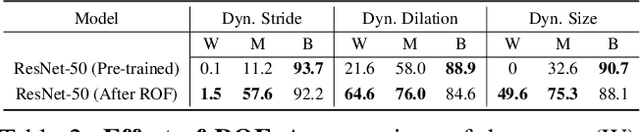
Over recent years, a myriad of novel convolutional network architectures have been developed to advance state-of-the-art performance on challenging recognition tasks. As computational resources improve, a great deal of effort has been placed in efficiently scaling up existing designs and generating new architectures with Neural Architecture Search (NAS) algorithms. While network topology has proven to be a critical factor for model performance, we show that significant gains are being left on the table by keeping topology static at inference-time. Due to challenges such as scale variation, we should not expect static models configured to perform well across a training dataset to be optimally configured to handle all test data. In this work, we seek to expose the exciting potential of inference-time-dynamic models. By allowing just four layers to dynamically change configuration at inference-time, we show that existing off-the-shelf models like ResNet-50 are capable of over 95% accuracy on ImageNet. This level of performance currently exceeds that of models with over 20x more parameters and significantly more complex training procedures.
DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles
Oct 18, 2020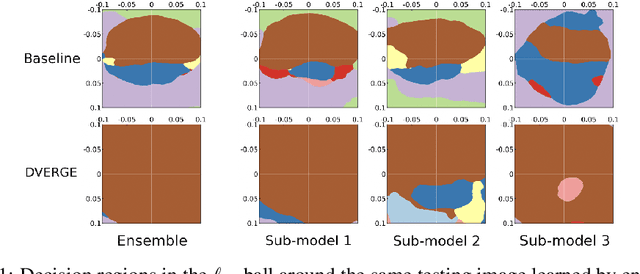

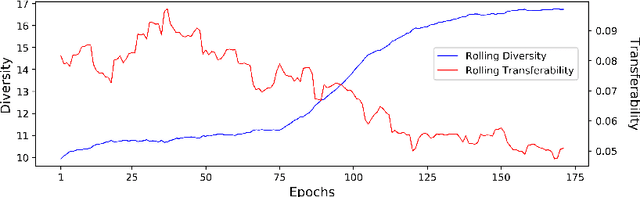

Recent research finds CNN models for image classification demonstrate overlapped adversarial vulnerabilities: adversarial attacks can mislead CNN models with small perturbations, which can effectively transfer between different models trained on the same dataset. Adversarial training, as a general robustness improvement technique, eliminates the vulnerability in a single model by forcing it to learn robust features. The process is hard, often requires models with large capacity, and suffers from significant loss on clean data accuracy. Alternatively, ensemble methods are proposed to induce sub-models with diverse outputs against a transfer adversarial example, making the ensemble robust against transfer attacks even if each sub-model is individually non-robust. Only small clean accuracy drop is observed in the process. However, previous ensemble training methods are not efficacious in inducing such diversity and thus ineffective on reaching robust ensemble. We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack. The novel diversity metric and training procedure enables DVERGE to achieve higher robustness against transfer attacks comparing to previous ensemble methods, and enables the improved robustness when more sub-models are added to the ensemble. The code of this work is available at https://github.com/zjysteven/DVERGE
Perturbing Across the Feature Hierarchy to Improve Standard and Strict Blackbox Attack Transferability
Apr 29, 2020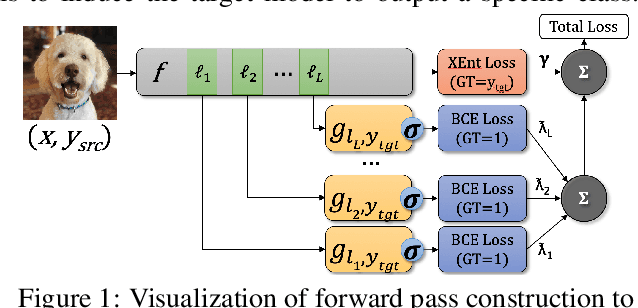
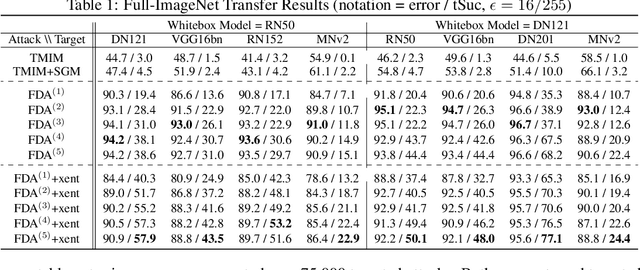
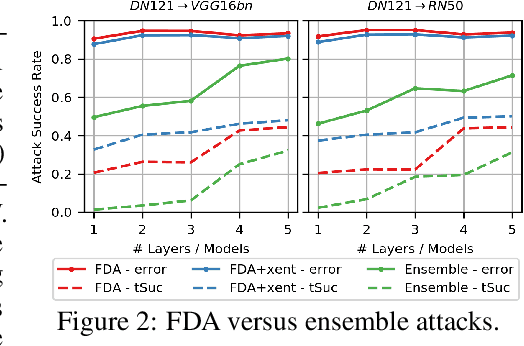
We consider the blackbox transfer-based targeted adversarial attack threat model in the realm of deep neural network (DNN) image classifiers. Rather than focusing on crossing decision boundaries at the output layer of the source model, our method perturbs representations throughout the extracted feature hierarchy to resemble other classes. We design a flexible attack framework that allows for multi-layer perturbations and demonstrates state-of-the-art targeted transfer performance between ImageNet DNNs. We also show the superiority of our feature space methods under a relaxation of the common assumption that the source and target models are trained on the same dataset and label space, in some instances achieving a $10\times$ increase in targeted success rate relative to other blackbox transfer methods. Finally, we analyze why the proposed methods outperform existing attack strategies and show an extension of the method in the case when limited queries to the blackbox model are allowed.
Transferable Perturbations of Deep Feature Distributions
Apr 27, 2020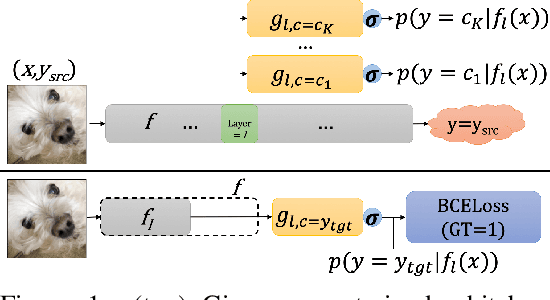
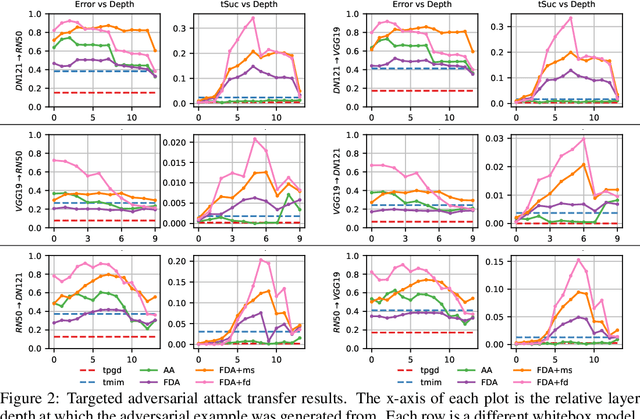
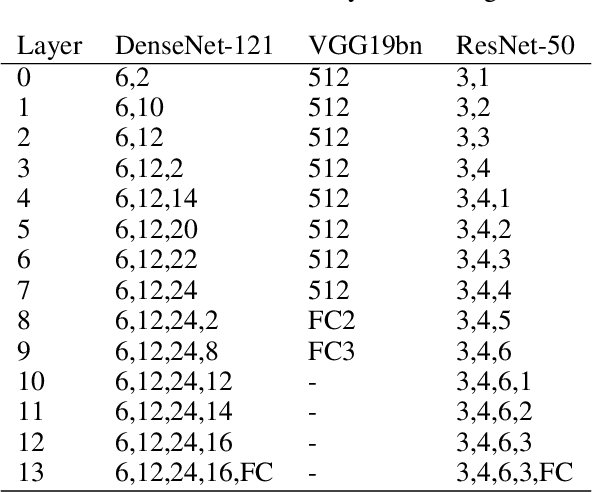
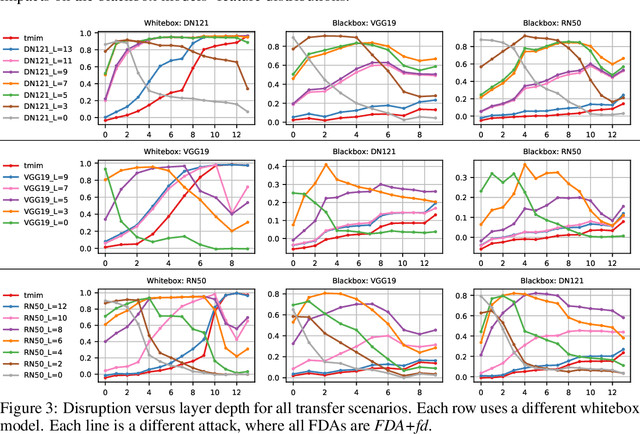
Almost all current adversarial attacks of CNN classifiers rely on information derived from the output layer of the network. This work presents a new adversarial attack based on the modeling and exploitation of class-wise and layer-wise deep feature distributions. We achieve state-of-the-art targeted blackbox transfer-based attack results for undefended ImageNet models. Further, we place a priority on explainability and interpretability of the attacking process. Our methodology affords an analysis of how adversarial attacks change the intermediate feature distributions of CNNs, as well as a measure of layer-wise and class-wise feature distributional separability/entanglement. We also conceptualize a transition from task/data-specific to model-specific features within a CNN architecture that directly impacts the transferability of adversarial examples.
Adversarial Attacks for Optical Flow-Based Action Recognition Classifiers
Nov 28, 2018
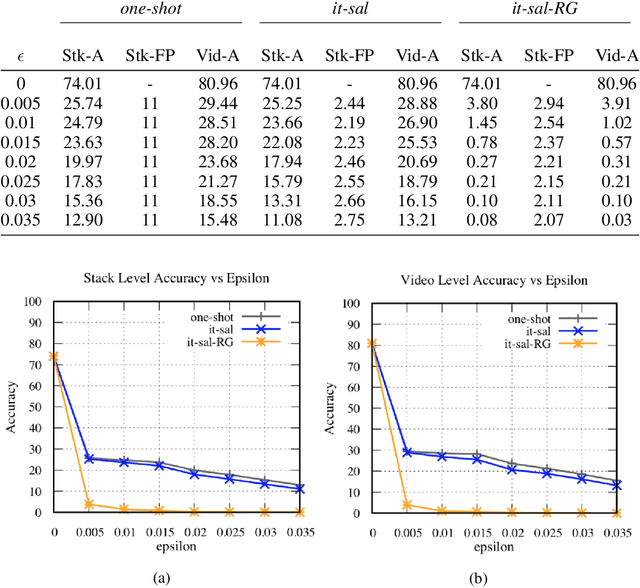
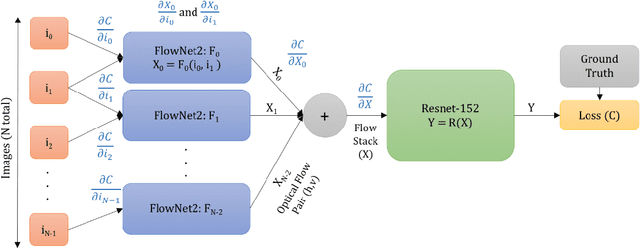
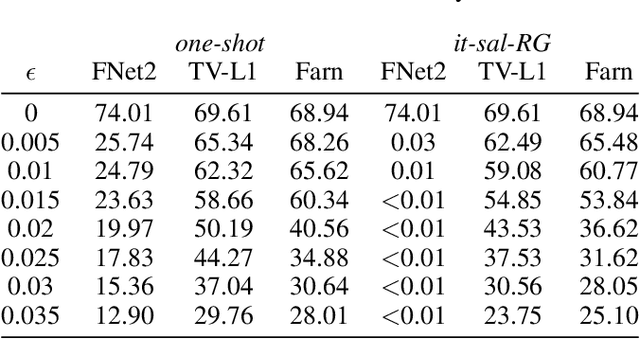
The success of deep learning research has catapulted deep models into production systems that our society is becoming increasingly dependent on, especially in the image and video domains. However, recent work has shown that these largely uninterpretable models exhibit glaring security vulnerabilities in the presence of an adversary. In this work, we develop a powerful untargeted adversarial attack for action recognition systems in both white-box and black-box settings. Action recognition models differ from image-classification models in that their inputs contain a temporal dimension, which we explicitly target in the attack. Drawing inspiration from image classifier attacks, we create new attacks which achieve state-of-the-art success rates on a two-stream classifier trained on the UCF-101 dataset. We find that our attacks can significantly degrade a model's performance with sparsely and imperceptibly perturbed examples. We also demonstrate the transferability of our attacks to black-box action recognition systems.