 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020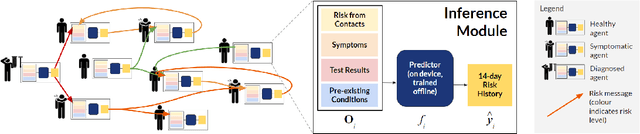
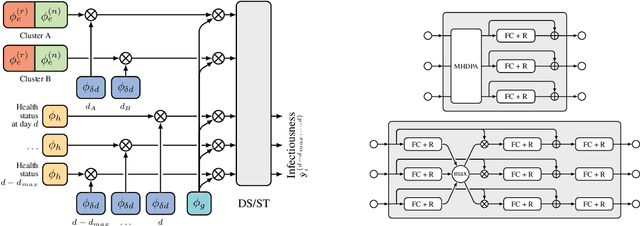
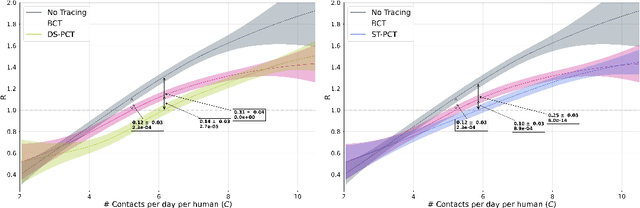
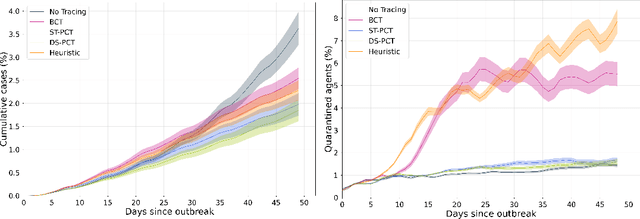
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
Function Contrastive Learning of Transferable Representations
Oct 14, 2020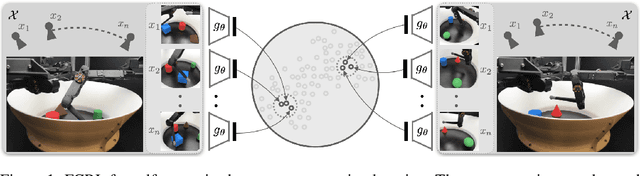
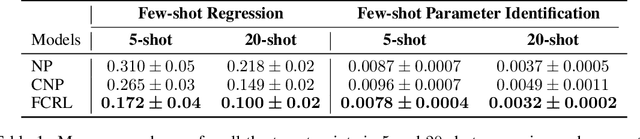
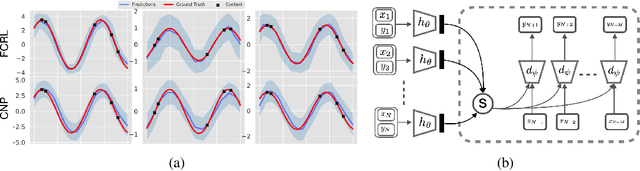
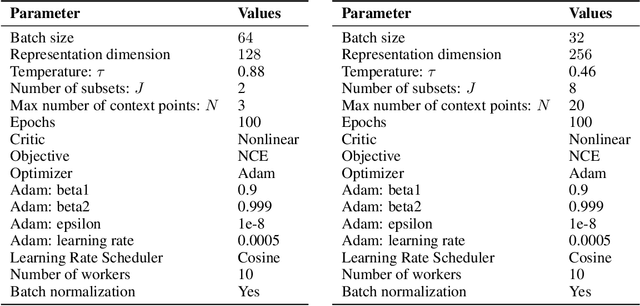
Few-shot-learning seeks to find models that are capable of fast-adaptation to novel tasks. Unlike typical few-shot learning algorithms, we propose a contrastive learning method which is not trained to solve a set of tasks, but rather attempts to find a good representation of the underlying data-generating processes (\emph{functions}). This allows for finding representations which are useful for an entire series of tasks sharing the same function. In particular, our training scheme is driven by the self-supervision signal indicating whether two sets of samples stem from the same underlying function. Our experiments on a number of synthetic and real-world datasets show that the representations we obtain can outperform strong baselines in terms of downstream performance and noise robustness, even when these baselines are trained in an end-to-end manner.
S2RMs: Spatially Structured Recurrent Modules
Jul 13, 2020



Capturing the structure of a data-generating process by means of appropriate inductive biases can help in learning models that generalize well and are robust to changes in the input distribution. While methods that harness spatial and temporal structures find broad application, recent work has demonstrated the potential of models that leverage sparse and modular structure using an ensemble of sparingly interacting modules. In this work, we take a step towards dynamic models that are capable of simultaneously exploiting both modular and spatiotemporal structures. We accomplish this by abstracting the modeled dynamical system as a collection of autonomous but sparsely interacting sub-systems. The sub-systems interact according to a topology that is learned, but also informed by the spatial structure of the underlying real-world system. This results in a class of models that are well suited for modeling the dynamics of systems that only offer local views into their state, along with corresponding spatial locations of those views. On the tasks of video prediction from cropped frames and multi-agent world modeling from partial observations in the challenging Starcraft2 domain, we find our models to be more robust to the number of available views and better capable of generalization to novel tasks without additional training, even when compared against strong baselines that perform equally well or better on the training distribution.
COVI White Paper
May 18, 2020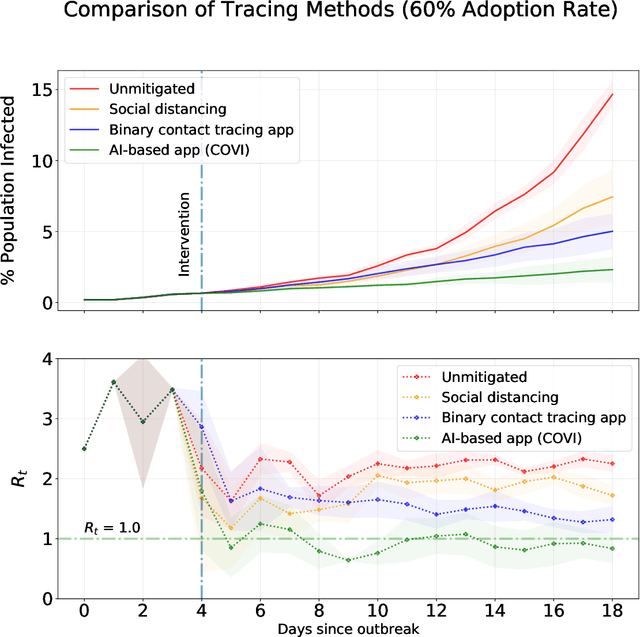
The SARS-CoV-2 (Covid-19) pandemic has caused significant strain on public health institutions around the world. Contact tracing is an essential tool to change the course of the Covid-19 pandemic. Manual contact tracing of Covid-19 cases has significant challenges that limit the ability of public health authorities to minimize community infections. Personalized peer-to-peer contact tracing through the use of mobile apps has the potential to shift the paradigm. Some countries have deployed centralized tracking systems, but more privacy-protecting decentralized systems offer much of the same benefit without concentrating data in the hands of a state authority or for-profit corporations. Machine learning methods can circumvent some of the limitations of standard digital tracing by incorporating many clues and their uncertainty into a more graded and precise estimation of infection risk. The estimated risk can provide early risk awareness, personalized recommendations and relevant information to the user. Finally, non-identifying risk data can inform epidemiological models trained jointly with the machine learning predictor. These models can provide statistical evidence for the importance of factors involved in disease transmission. They can also be used to monitor, evaluate and optimize health policy and (de)confinement scenarios according to medical and economic productivity indicators. However, such a strategy based on mobile apps and machine learning should proactively mitigate potential ethical and privacy risks, which could have substantial impacts on society (not only impacts on health but also impacts such as stigmatization and abuse of personal data). Here, we present an overview of the rationale, design, ethical considerations and privacy strategy of `COVI,' a Covid-19 public peer-to-peer contact tracing and risk awareness mobile application developed in Canada.
Learning the Arrow of Time
Jul 02, 2019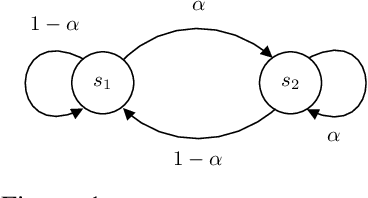
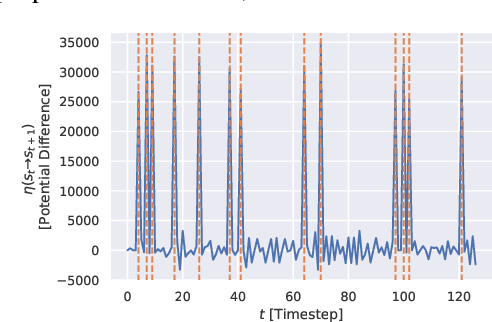
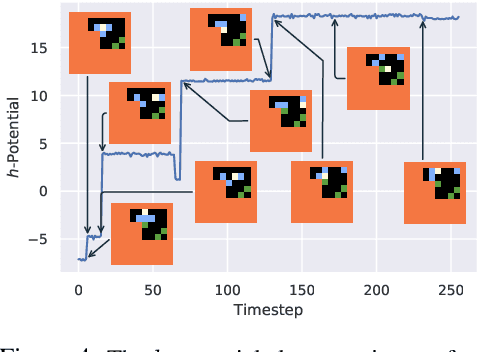
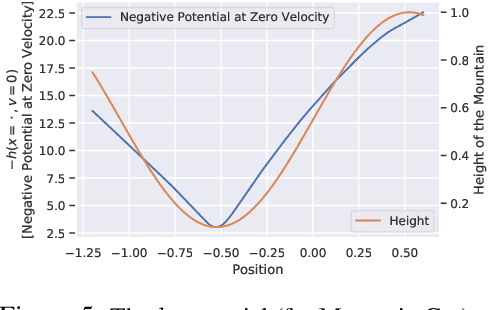
We humans seem to have an innate understanding of the asymmetric progression of time, which we use to efficiently and safely perceive and manipulate our environment. Drawing inspiration from that, we address the problem of learning an arrow of time in a Markov (Decision) Process. We illustrate how a learned arrow of time can capture meaningful information about the environment, which in turn can be used to measure reachability, detect side-effects and to obtain an intrinsic reward signal. We show empirical results on a selection of discrete and continuous environments, and demonstrate for a class of stochastic processes that the learned arrow of time agrees reasonably well with a known notion of an arrow of time given by the celebrated Jordan-Kinderlehrer-Otto result.
The Mutex Watershed and its Objective: Efficient, Parameter-Free Image Partitioning
Apr 25, 2019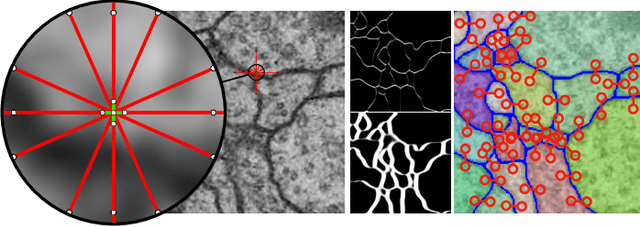
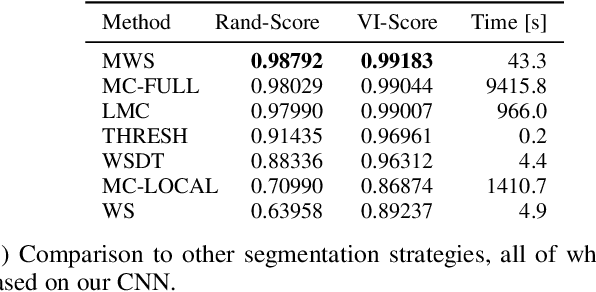
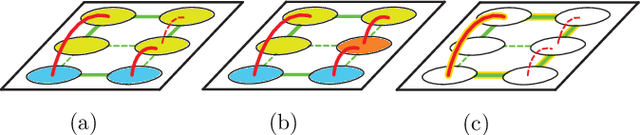
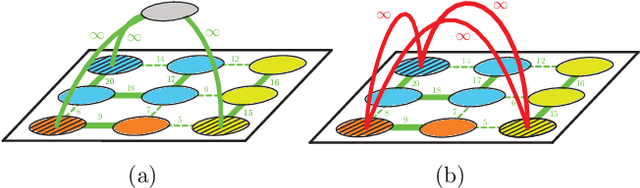
Image partitioning, or segmentation without semantics, is the task of decomposing an image into distinct segments, or equivalently to detect closed contours. Most prior work either requires seeds, one per segment; or a threshold; or formulates the task as multicut / correlation clustering, an NP-hard problem. Here, we propose a greedy algorithm for signed graph partitioning, the "Mutex Watershed". Unlike seeded watershed, the algorithm can accommodate not only attractive but also repulsive cues, allowing it to find a previously unspecified number of segments without the need for explicit seeds or a tunable threshold. We also prove that this simple algorithm solves to global optimality an objective function that is intimately related to the multicut / correlation clustering integer linear programming formulation. The algorithm is deterministic, very simple to implement, and has empirically linearithmic complexity. When presented with short-range attractive and long-range repulsive cues from a deep neural network, the Mutex Watershed gives the best results currently known for the competitive ISBI 2012 EM segmentation benchmark.
A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms
Feb 04, 2019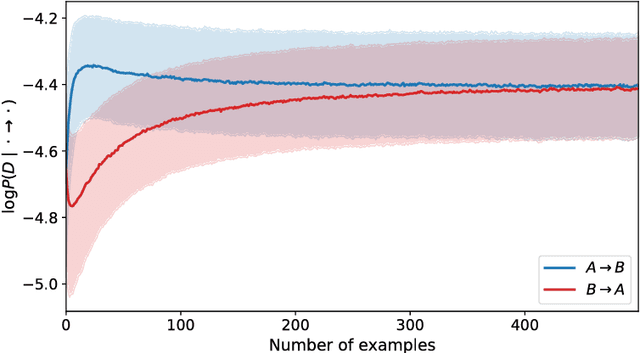
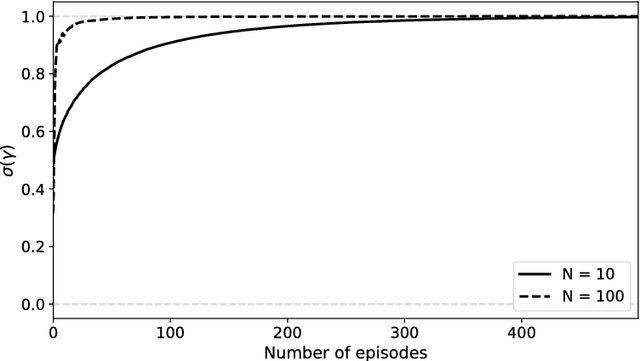
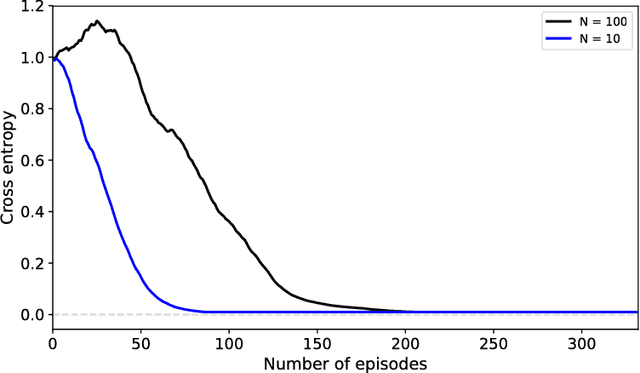

We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.
On the Spectral Bias of Neural Networks
Oct 17, 2018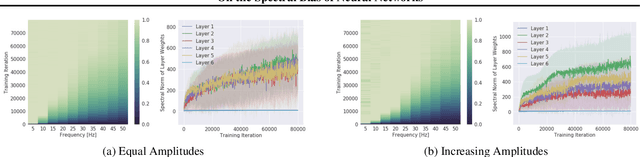
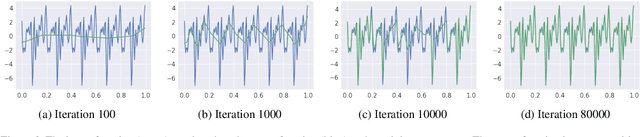
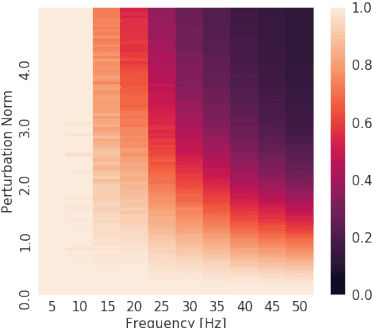
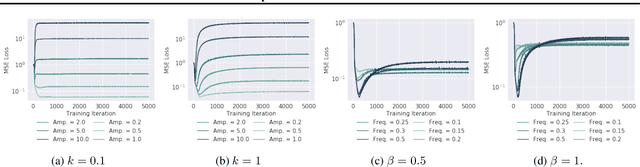
Neural networks are known to be a class of highly expressive functions able to fit even random input-output mappings with $100\%$ accuracy. In this work, we present properties of neural networks that complement this aspect of expressivity. By using tools from Fourier analysis, we show that deep ReLU networks are biased towards low frequency functions, meaning that they cannot have local fluctuations without affecting their global behavior. Intuitively, this property is in line with the observation that over-parameterized networks find simple patterns that generalize across data samples. We also investigate how the shape of the data manifold affects expressivity by showing evidence that learning high frequencies gets \emph{easier} with increasing manifold complexity, and present a theoretical understanding of this behavior. Finally, we study the robustness of the frequency components with respect to parameter perturbation, to develop the intuition that the parameters must be finely tuned to express high frequency functions.