 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Architecture Search: A Broad Version
Jan 18, 2020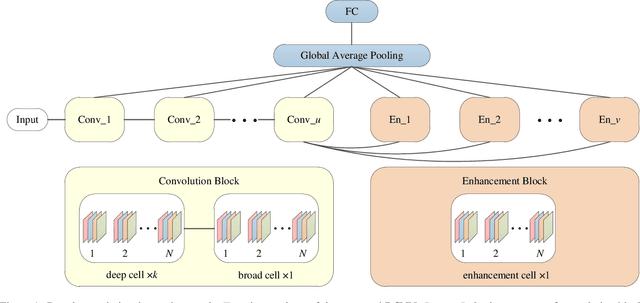
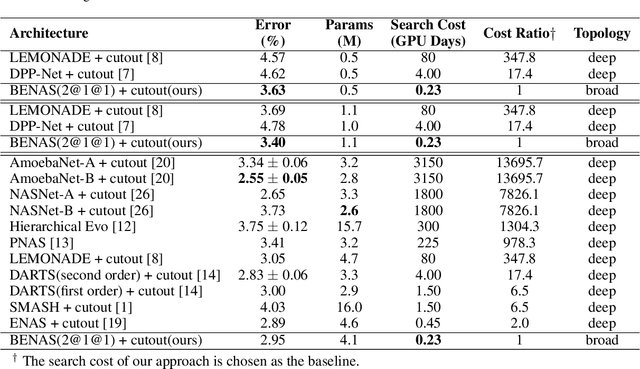
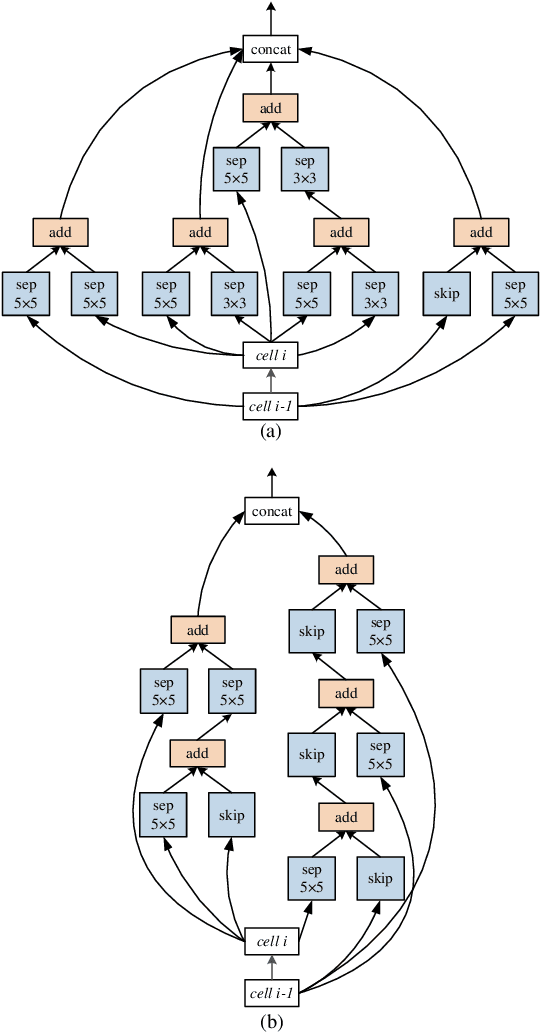
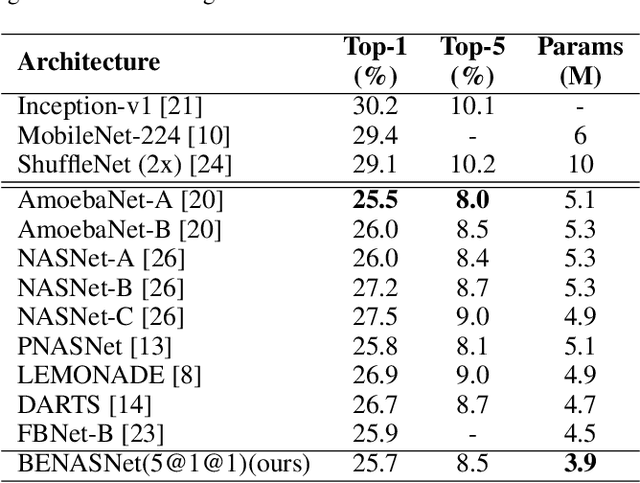
Efficient Neural Architecture Search (ENAS) achieves novel efficiency for learning architecture with high-performance via parameter sharing, but suffers from an issue of slow propagation speed of search model with deep topology. In this paper, we propose a Broad version for ENAS (BENAS) to solve the above issue, by learning broad architecture whose propagation speed is fast with reinforcement learning and parameter sharing used in ENAS, thereby achieving a higher search efficiency. In particular, we elaborately design Broad Convolutional Neural Network (BCNN), the search paradigm of BENAS with fast propagation speed, which can obtain a satisfactory performance with broad topology, i.e. fast forward and backward propagation speed. The proposed BCNN extracts multi-scale features and enhancement representations, and feeds them into global average pooling layer to yield more reasonable and comprehensive representations so that the achieved performance of BCNN with shallow topology can be promised. In order to verify the effectiveness of BENAS, several experiments are performed and experimental results show that 1) BENAS delivers 0.23 day which is 2x less expensive than ENAS, 2) the architecture learned by BENAS based small-size BCNNs with 0.5 and 1.1 millions parameters obtain state-of-the-art performance, 3.63% and 3.40% test error on CIFAR-10, 3) the learned architecture based BCNN achieves 25.3\% top-1 error on ImageNet just using 3.9 millions parameters.
A Survey of Deep Reinforcement Learning in Video Games
Dec 26, 2019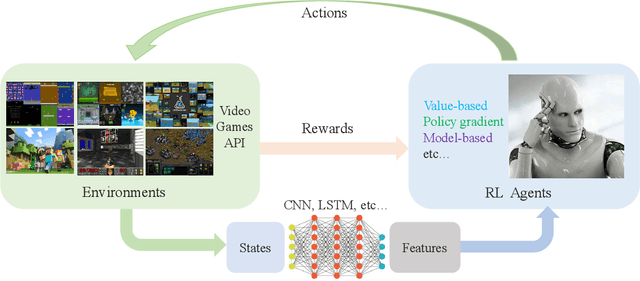
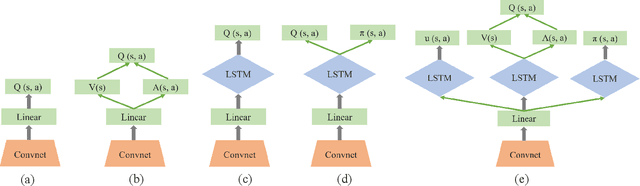
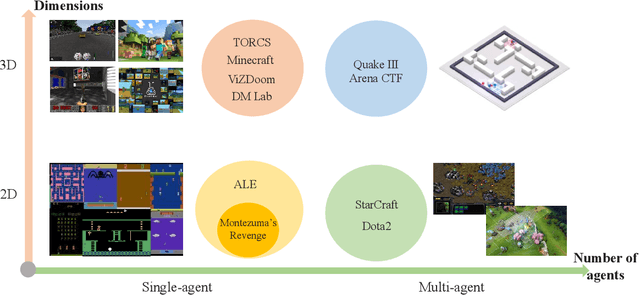
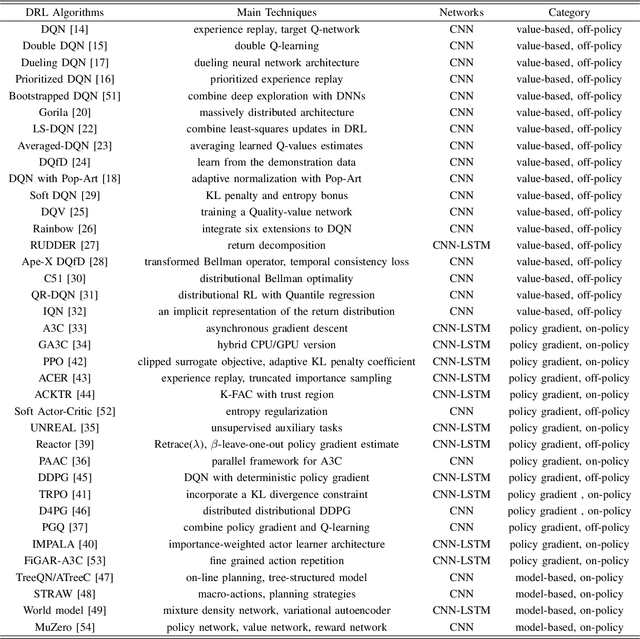
Deep reinforcement learning (DRL) has made great achievements since proposed. Generally, DRL agents receive high-dimensional inputs at each step, and make actions according to deep-neural-network-based policies. This learning mechanism updates the policy to maximize the return with an end-to-end method. In this paper, we survey the progress of DRL methods, including value-based, policy gradient, and model-based algorithms, and compare their main techniques and properties. Besides, DRL plays an important role in game artificial intelligence (AI). We also take a review of the achievements of DRL in various video games, including classical Arcade games, first-person perspective games and multi-agent real-time strategy games, from 2D to 3D, and from single-agent to multi-agent. A large number of video game AIs with DRL have achieved super-human performance, while there are still some challenges in this domain. Therefore, we also discuss some key points when applying DRL methods to this field, including exploration-exploitation, sample efficiency, generalization and transfer, multi-agent learning, imperfect information, and delayed spare rewards, as well as some research directions.
Non-rigid 3D shape retrieval based on multi-view metric learning
Mar 20, 2019
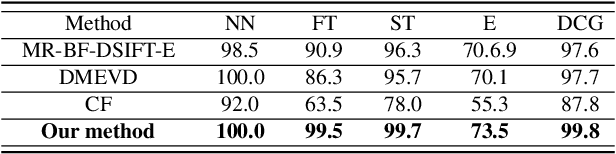
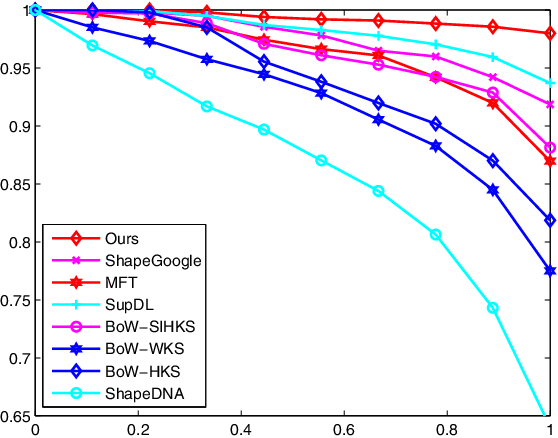
This study presents a novel multi-view metric learning algorithm, which aims to improve 3D non-rigid shape retrieval. With the development of non-rigid 3D shape analysis, there exist many shape descriptors. The intrinsic descriptors can be explored to construct various intrinsic representations for non-rigid 3D shape retrieval task. The different intrinsic representations (features) focus on different geometric properties to describe the same 3D shape, which makes the representations are related. Therefore, it is possible and necessary to learn multiple metrics for different representations jointly. We propose an effective multi-view metric learning algorithm by extending the Marginal Fisher Analysis (MFA) into the multi-view domain, and exploring Hilbert-Schmidt Independence Criteria (HSCI) as a diversity term to jointly learning the new metrics. The different classes can be separated by MFA in our method. Meanwhile, HSCI is exploited to make the multiple representations to be consensus. The learned metrics can reduce the redundancy between the multiple representations, and improve the accuracy of the retrieval results. Experiments are performed on SHREC'10 benchmarks, and the results show that the proposed method outperforms the state-of-the-art non-rigid 3D shape retrieval methods.
Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classifier for Anomaly Detection
Mar 18, 2019
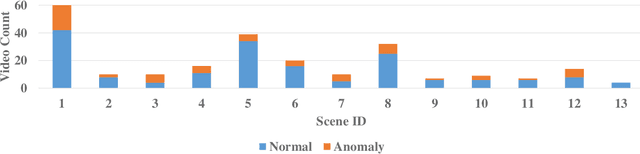

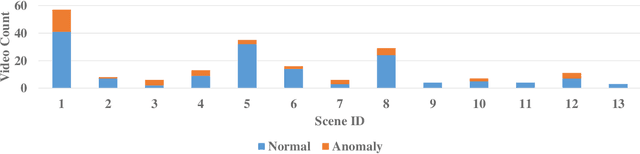
Video anomaly detection under weak labels is formulated as a typical multiple-instance learning problem in previous works. In this paper, we provide a new perspective, i.e., a supervised learning task under noisy labels. In such a viewpoint, as long as cleaning away label noise, we can directly apply fully supervised action classifiers to weakly supervised anomaly detection, and take maximum advantage of these well-developed classifiers. For this purpose, we devise a graph convolutional network to correct noisy labels. Based upon feature similarity and temporal consistency, our network propagates supervisory signals from high-confidence snippets to low-confidence ones. In this manner, the network is capable of providing cleaned supervision for action classifiers. During the test phase, we only need to obtain snippet-wise predictions from the action classifier without any extra post-processing. Extensive experiments on 3 datasets at different scales with 2 types of action classifiers demonstrate the efficacy of our method. Remarkably, we obtain the frame-level AUC score of 82.12% on UCF-Crime.
BLP - Boundary Likelihood Pinpointing Networks for Accurate Temporal Action Localization
Nov 12, 2018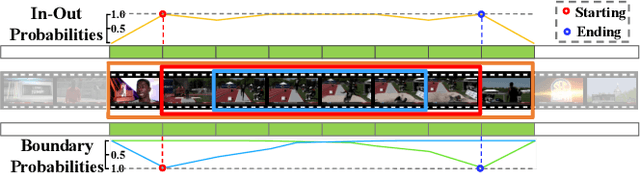

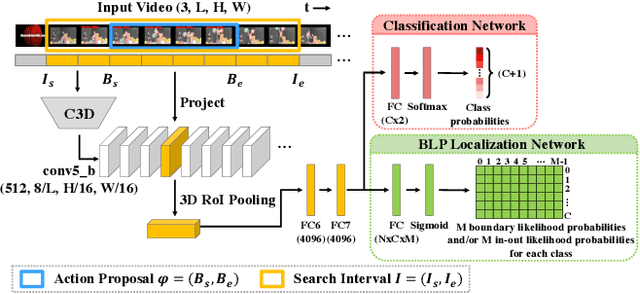

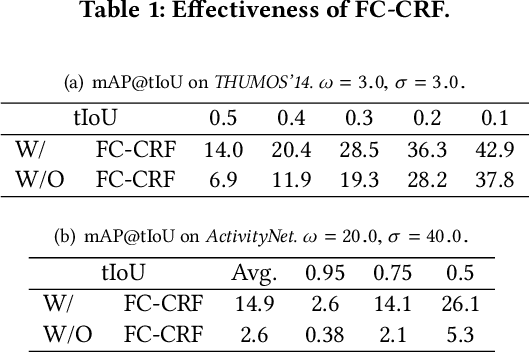
Despite tremendous progress achieved in temporal action detection, state-of-the-art methods still suffer from the sharp performance deterioration when localizing the starting and ending temporal action boundaries. Although most methods apply boundary regression paradigm to tackle this problem, we argue that the direct regression lacks detailed enough information to yield accurate temporal boundaries. In this paper, we propose a novel Boundary Likelihood Pinpointing (BLP) network to alleviate this deficiency of boundary regression and improve the localization accuracy. Given a loosely localized search interval that contains an action instance, BLP casts the problem of localizing temporal boundaries as that of assigning probabilities on each equally divided unit of this interval. These generated probabilities provide useful information regarding the boundary location of the action inside this search interval. Based on these probabilities, we introduce a boundary pinpointing paradigm to pinpoint the accurate boundaries under a simple probabilistic framework. Compared with other C3D feature based detectors, extensive experiments demonstrate that BLP significantly improve the localization performance of recent state-of-the-art detectors, and achieve competitive detection mAP on both THUMOS' 14 and ActivityNet datasets, particularly when the evaluation tIoU is high.
MRI Cross-Modality NeuroImage-to-NeuroImage Translation
Sep 11, 2018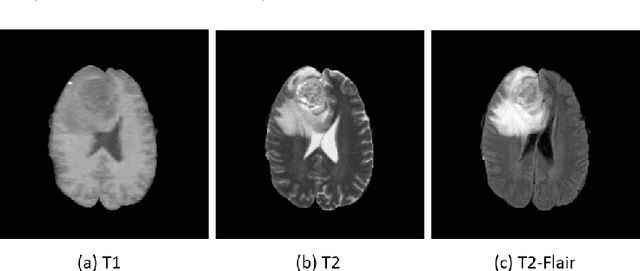
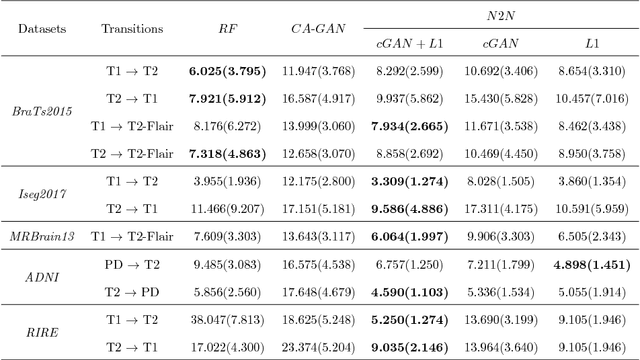

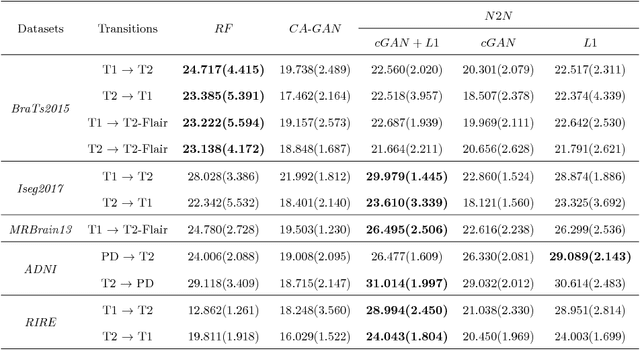
We present a cross-modality generation framework that learns to generate translated modalities from given modalities in MR images without real acquisition. Our proposed method performs NeuroImage-to-NeuroImage translation (abbreviated as N2N) by means of a deep learning model that leverages conditional generative adversarial networks (cGANs). Our framework jointly exploits the low-level features (pixel-wise information) and high-level representations (e.g. brain tumors, brain structure like gray matter, etc.) between cross modalities which are important for resolving the challenging complexity in brain structures. Our framework can serve as an auxiliary method in clinical diagnosis and has great application potential. Based on our proposed framework, we first propose a method for cross-modality registration by fusing the deformation fields to adopt the cross-modality information from translated modalities. Second, we propose an approach for MRI segmentation, translated multichannel segmentation (TMS), where given modalities, along with translated modalities, are segmented by fully convolutional networks (FCN) in a multichannel manner. Both of these two methods successfully adopt the cross-modality information to improve the performance without adding any extra data. Experiments demonstrate that our proposed framework advances the state-of-the-art on five brain MRI datasets. We also observe encouraging results in cross-modality registration and segmentation on some widely adopted brain datasets. Overall, our work can serve as an auxiliary method in clinical diagnosis and be applied to various tasks in medical fields. Keywords: image-to-image, cross-modality, registration, segmentation, brain MRI
Step-by-step Erasion, One-by-one Collection: A Weakly Supervised Temporal Action Detector
Jul 18, 2018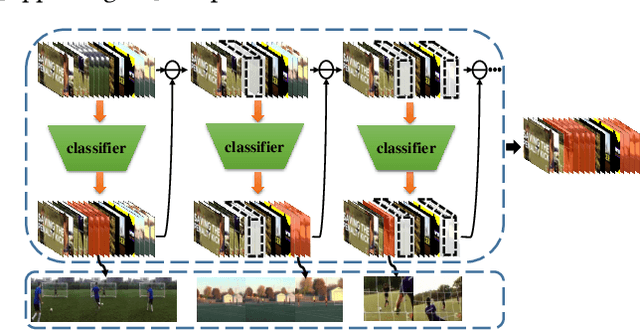
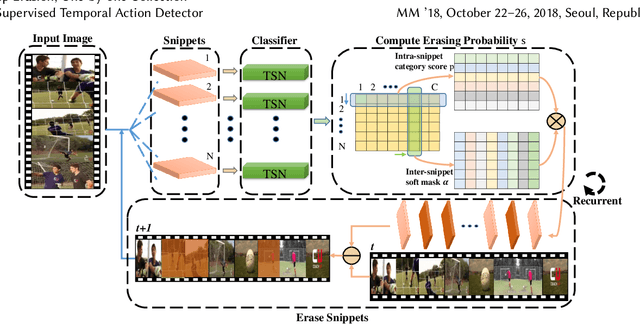
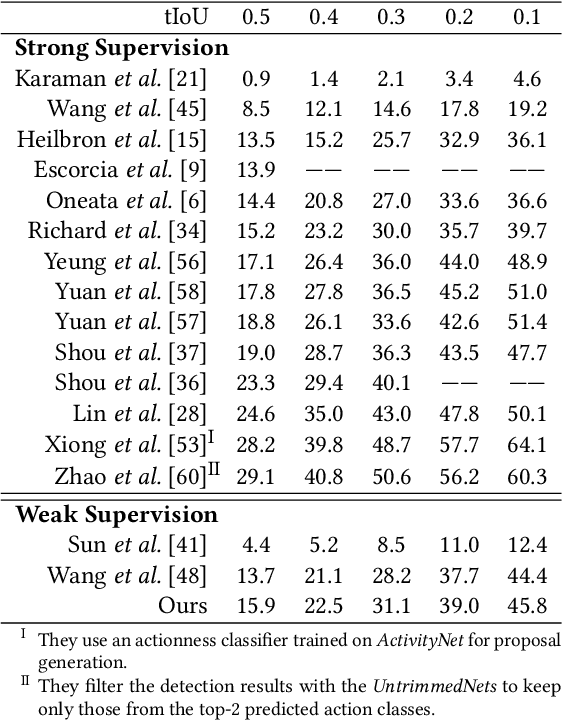
Weakly supervised temporal action detection is a Herculean task in understanding untrimmed videos, since no supervisory signal except the video-level category label is available on training data. Under the supervision of category labels, weakly supervised detectors are usually built upon classifiers. However, there is an inherent contradiction between classifier and detector; i.e., a classifier in pursuit of high classification performance prefers top-level discriminative video clips that are extremely fragmentary, whereas a detector is obliged to discover the whole action instance without missing any relevant snippet. To reconcile this contradiction, we train a detector by driving a series of classifiers to find new actionness clips progressively, via step-by-step erasion from a complete video. During the test phase, all we need to do is to collect detection results from the one-by-one trained classifiers at various erasing steps. To assist in the collection process, a fully connected conditional random field is established to refine the temporal localization outputs. We evaluate our approach on two prevailing datasets, THUMOS'14 and ActivityNet. The experiments show that our detector advances state-of-the-art weakly supervised temporal action detection results, and even compares with quite a few strongly supervised methods.
A Self-Adaptive Proposal Model for Temporal Action Detection based on Reinforcement Learning
Jun 22, 2017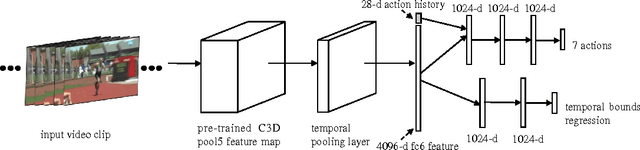
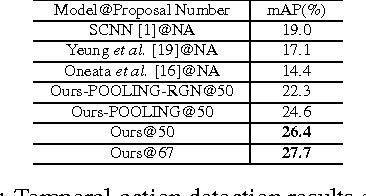

Existing action detection algorithms usually generate action proposals through an extensive search over the video at multiple temporal scales, which brings about huge computational overhead and deviates from the human perception procedure. We argue that the process of detecting actions should be naturally one of observation and refinement: observe the current window and refine the span of attended window to cover true action regions. In this paper, we propose an active action proposal model that learns to find actions through continuously adjusting the temporal bounds in a self-adaptive way. The whole process can be deemed as an agent, which is firstly placed at a position in the video at random, adopts a sequence of transformations on the current attended region to discover actions according to a learned policy. We utilize reinforcement learning, especially the Deep Q-learning algorithm to learn the agent's decision policy. In addition, we use temporal pooling operation to extract more effective feature representation for the long temporal window, and design a regression network to adjust the position offsets between predicted results and the ground truth. Experiment results on THUMOS 2014 validate the effectiveness of the proposed approach, which can achieve competitive performance with current action detection algorithms via much fewer proposals.
Searching Action Proposals via Spatial Actionness Estimation and Temporal Path Inference and Tracking
Aug 23, 2016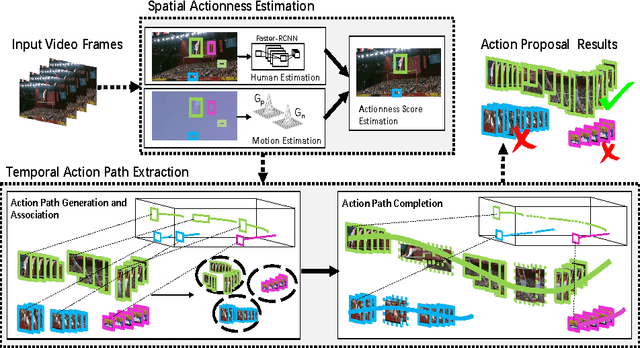
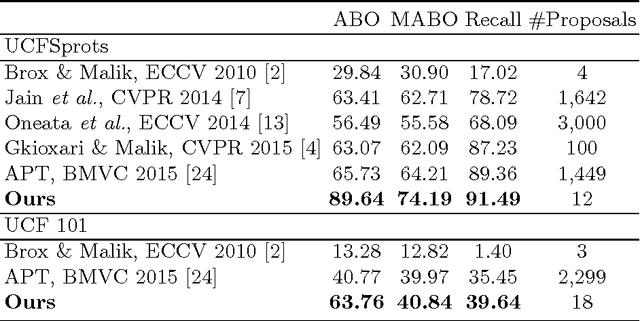

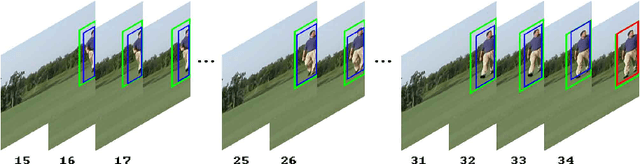
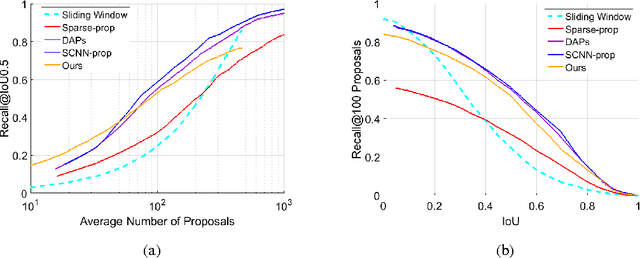
In this paper, we address the problem of searching action proposals in unconstrained video clips. Our approach starts from actionness estimation on frame-level bounding boxes, and then aggregates the bounding boxes belonging to the same actor across frames via linking, associating, tracking to generate spatial-temporal continuous action paths. To achieve the target, a novel actionness estimation method is firstly proposed by utilizing both human appearance and motion cues. Then, the association of the action paths is formulated as a maximum set coverage problem with the results of actionness estimation as a priori. To further promote the performance, we design an improved optimization objective for the problem and provide a greedy search algorithm to solve it. Finally, a tracking-by-detection scheme is designed to further refine the searched action paths. Extensive experiments on two challenging datasets, UCF-Sports and UCF-101, show that the proposed approach advances state-of-the-art proposal generation performance in terms of both accuracy and proposal quantity.