 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNan Zhao
Robust Federated Learning with Noisy Communication
Nov 01, 2019
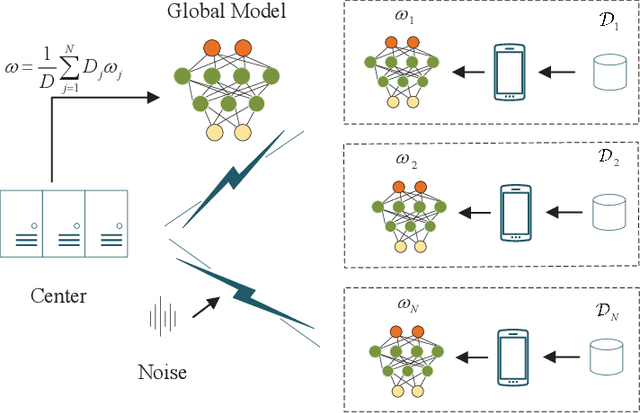
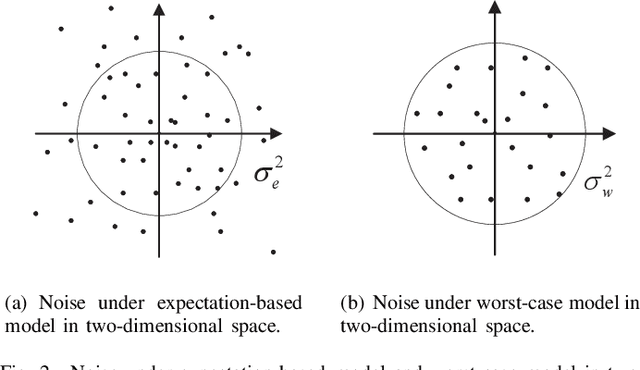
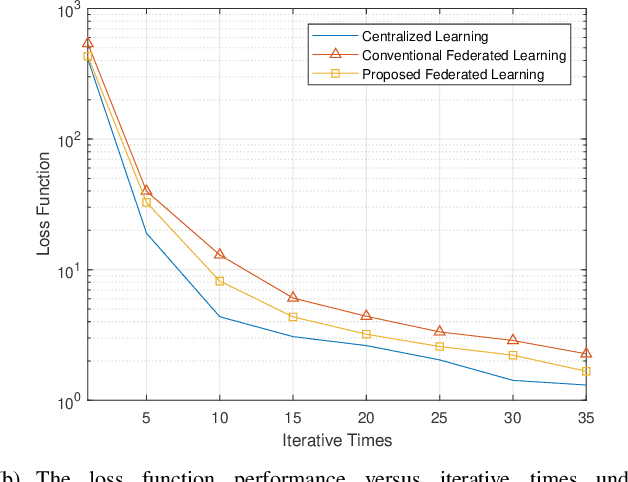
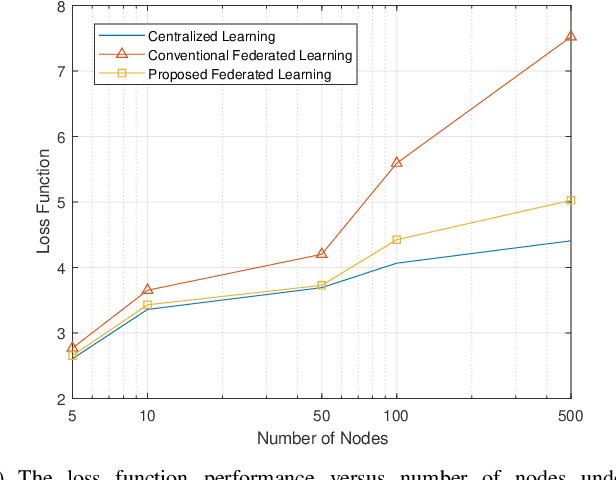
Federated learning is a communication-efficient training process that alternates between local training at the edge devices and averaging the updated local model at the central server. Nevertheless, it is impractical to achieve a perfect acquisition of the local models in wireless communication due to noise, which also brings serious effects on federated learning. To tackle this challenge, we propose a robust design for federated learning to alleviate the effects of noise in this paper. Considering noise in the two aforementioned steps, we first formulate the training problem as a parallel optimization for each node under the expectation-based model and the worst-case model. Due to the non-convexity of the problem, a regularization for the loss function approximation method is proposed to make it tractable. Regarding the worst-case model, we develop a feasible training scheme which utilizes the sampling-based successive convex approximation algorithm to tackle the unavailable maxima or minima noise condition and the non-convex issue of the objective function. Furthermore, the convergence rates of both new designs are analyzed from a theoretical point of view. Finally, the improvement of prediction accuracy and the reduction of loss function are demonstrated via simulations for the proposed designs.
Sky pixel detection in outdoor imagery using an adaptive algorithm and machine learning
Oct 08, 2019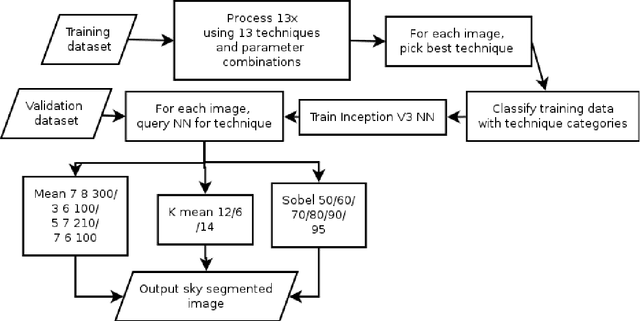



Computer vision techniques allow automated detection of sky pixels in outdoor imagery. Multiple applications exist for this information across a large number of research areas. In urban climate, sky detection is an important first step in gathering information about urban morphology and sky view factors. However, capturing accurate results remains challenging and becomes even more complex using imagery captured under a variety of lighting and weather conditions. To address this problem, we present a new sky pixel detection system demonstrated to produce accurate results using a wide range of outdoor imagery types. Images are processed using a selection of mean-shift segmentation, K-means clustering, and Sobel filters to mark sky pixels in the scene. The algorithm for a specific image is chosen by a convolutional neural network, trained with 25,000 images from the Skyfinder data set, reaching 82% accuracy with the top three classes. This selection step allows the sky marking to follow an adaptive process and to use different techniques and parameters to best suit a particular image. An evaluation of fourteen different techniques and parameter sets shows that no single technique can perform with high accuracy across varied Skyfinder and Google Street View data sets. However, by using our adaptive process, large increases in accuracy are observed. The resulting system is shown to perform better than other published techniques.
RGB-T Object Tracking:Benchmark and Baseline
May 23, 2018
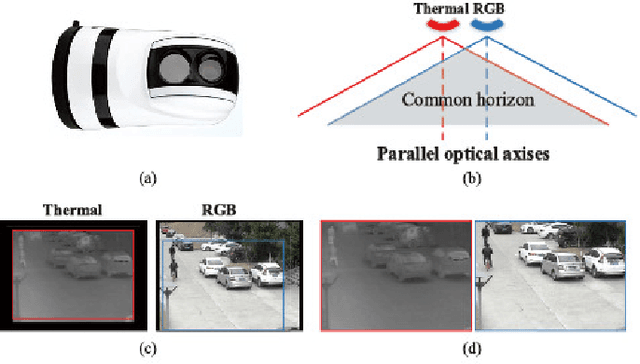
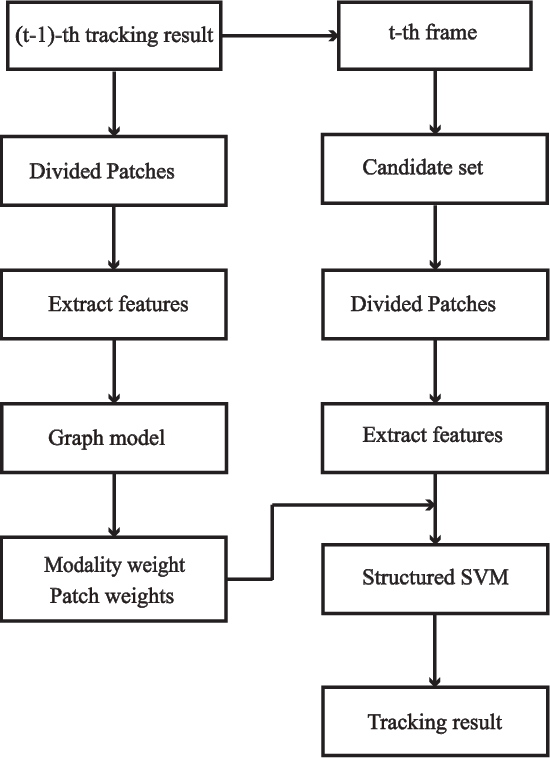

RGB-Thermal (RGB-T) object tracking receives more and more attention due to the strongly complementary benefits of thermal information to visible data. However, RGB-T research is limited by lacking a comprehensive evaluation platform. In this paper, we propose a large-scale video benchmark dataset for RGB-T tracking.It has three major advantages over existing ones: 1) Its size is sufficiently large for large-scale performance evaluation (total frame number: 234K, maximum frame per sequence: 8K). 2) The alignment between RGB-T sequence pairs is highly accurate, which does not need pre- or post-processing. 3) The occlusion levels are annotated for occlusion-sensitive performance analysis of different tracking algorithms.Moreover, we propose a novel graph-based approach to learn a robust object representation for RGB-T tracking. In particular, the tracked object is represented with a graph with image patches as nodes. This graph including graph structure, node weights and edge weights is dynamically learned in a unified ADMM (alternating direction method of multipliers)-based optimization framework, in which the modality weights are also incorporated for adaptive fusion of multiple source data.Extensive experiments on the large-scale dataset are executed to demonstrate the effectiveness of the proposed tracker against other state-of-the-art tracking methods. We also provide new insights and potential research directions to the field of RGB-T object tracking.
Recognition of Emotions using Kinects
Aug 04, 2015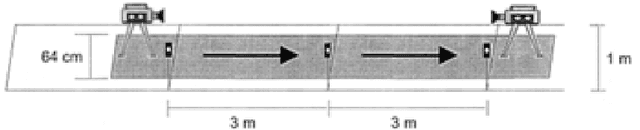

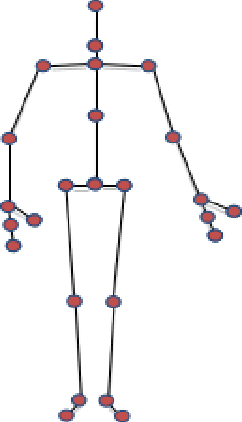

Psychological studies indicate that emotional states are expressed in the way people walk and the human gait is investigated in terms of its ability to reveal a person's emotional state. And Microsoft Kinect is a rapidly developing, inexpensive, portable and no-marker motion capture system. This paper gives a new referable method to do emotion recognition, by using Microsoft Kinect to do gait pattern analysis, which has not been reported. $59$ subjects are recruited in this study and their gait patterns are record by two Kinect cameras. Significant joints selecting, Coordinate system transforming, Slider window gauss filter, Differential operation, and Data segmentation are used in data preprocessing. Feature extracting is based on Fourier transformation. By using the NaiveBayes, RandomForests, libSVM and SMO classification, the recognition rate of natural and unnatural emotions can reach above 70%.It is concluded that using the Kinect system can be a new method in recognition of emotions.