 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNajim Dehak
Speaker Sincerity Detection based on Covariance Feature Vectors and Ensemble Methods
Apr 26, 2019

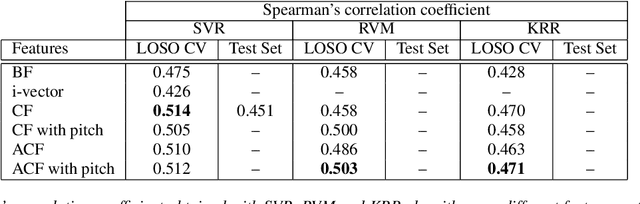
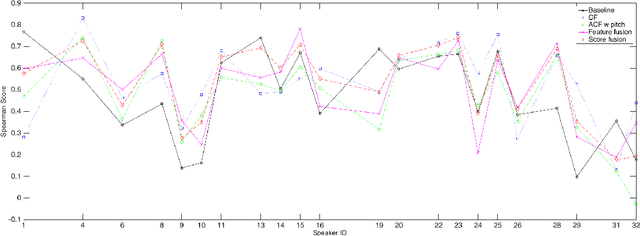
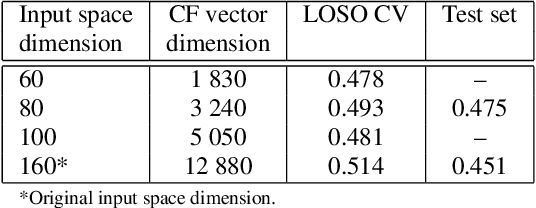
Automatic measuring of speaker sincerity degree is a novel research problem in computational paralinguistics. This paper proposes covariance-based feature vectors to model speech and ensembles of support vector regressors to estimate the degree of sincerity of a speaker. The elements of each covariance vector are pairwise statistics between the short-term feature components. These features are used alone as well as in combination with the ComParE acoustic feature set. The experimental results on the development set of the Sincerity Speech Corpus using a cross-validation procedure have shown an 8.1% relative improvement in the Spearman's correlation coefficient over the baseline system.
ASSERT: Anti-Spoofing with Squeeze-Excitation and Residual neTworks
Apr 01, 2019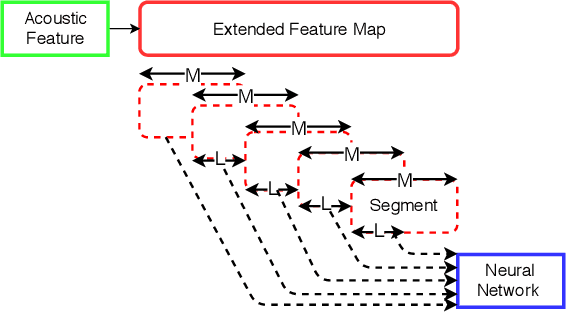
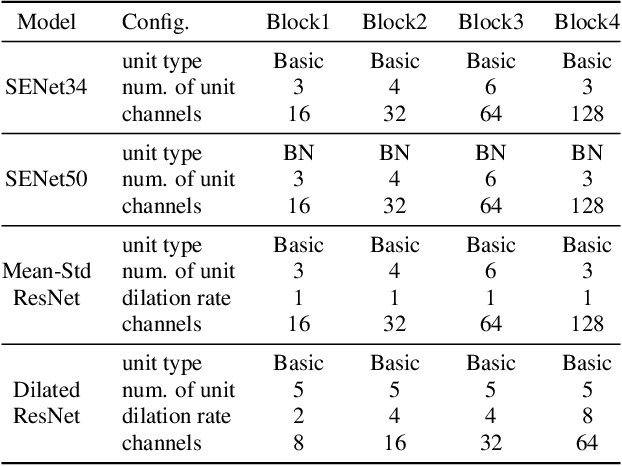
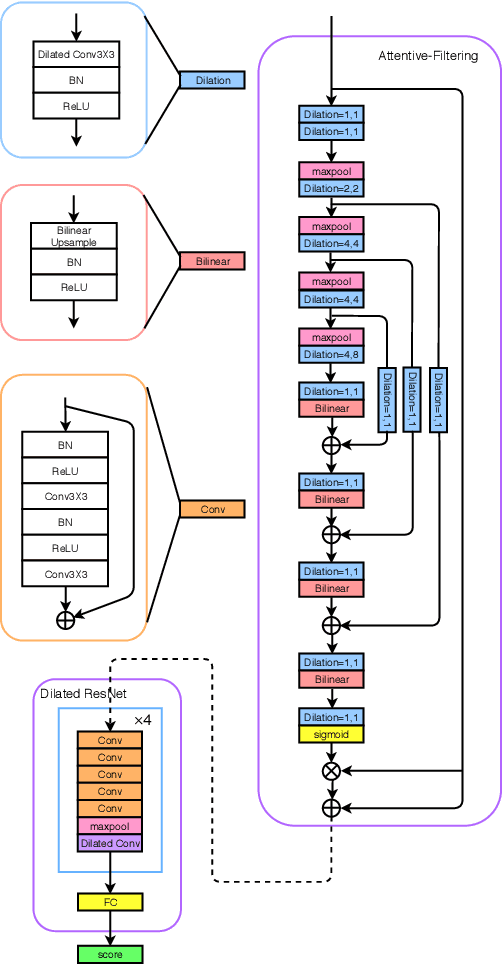
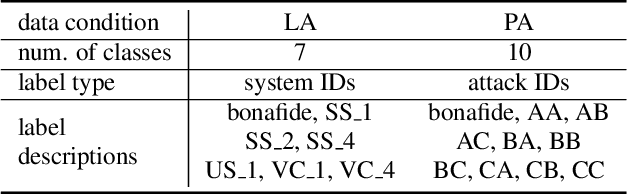
We present JHU's system submission to the ASVspoof 2019 Challenge: Anti-Spoofing with Squeeze-Excitation and Residual neTworks (ASSERT). Anti-spoofing has gathered more and more attention since the inauguration of the ASVspoof Challenges, and ASVspoof 2019 dedicates to address attacks from all three major types: text-to-speech, voice conversion, and replay. Built upon previous research work on Deep Neural Network (DNN), ASSERT is a pipeline for DNN-based approach to anti-spoofing. ASSERT has four components: feature engineering, DNN models, network optimization and system combination, where the DNN models are variants of squeeze-excitation and residual networks. We conducted an ablation study of the effectiveness of each component on the ASVspoof 2019 corpus, and experimental results showed that ASSERT obtained more than 93% and 17% relative improvements over the baseline systems in the two sub-challenges in ASVspooof 2019, ranking ASSERT one of the top performing systems. Code and pretrained models will be made publicly available.
Low Resource Multi-modal Data Augmentation for End-to-end ASR
Dec 10, 2018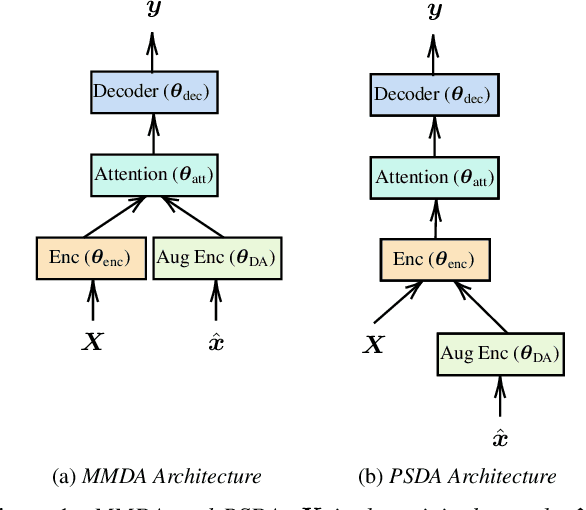
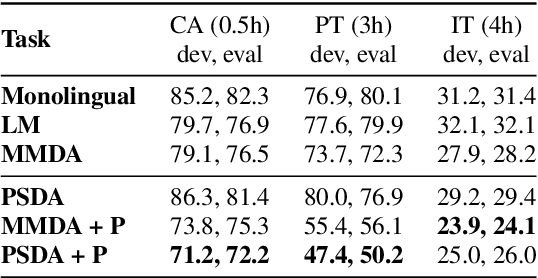

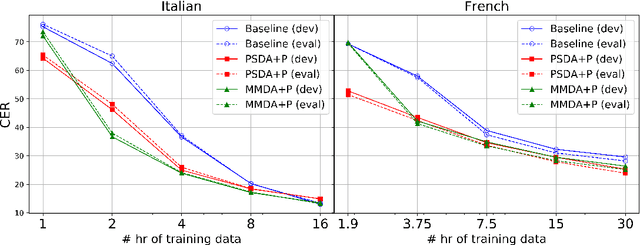
We explore training attention-based encoder-decoder ASR for low-resource languages and present techniques that result in a 50% relative improvement in character error rate compared to a standard baseline. The performance of encoder-decoder ASR systems depends on having sufficient target-side text to train the attention and decoder networks. The lack of such data in low-resource contexts results in severely degraded performance. In this paper we present a data augmentation scheme tailored for low-resource ASR in diverse languages. Across 3 test languages, our approach resulted in a 20% average relative improvement over a baseline text-based augmentation technique. We further compare the performance of our monolingual text-based data augmentation to speech-based data augmentation from nearby languages and find that this gives a further 20-30% relative reduction in character error rate.
Attentive Filtering Networks for Audio Replay Attack Detection
Oct 31, 2018
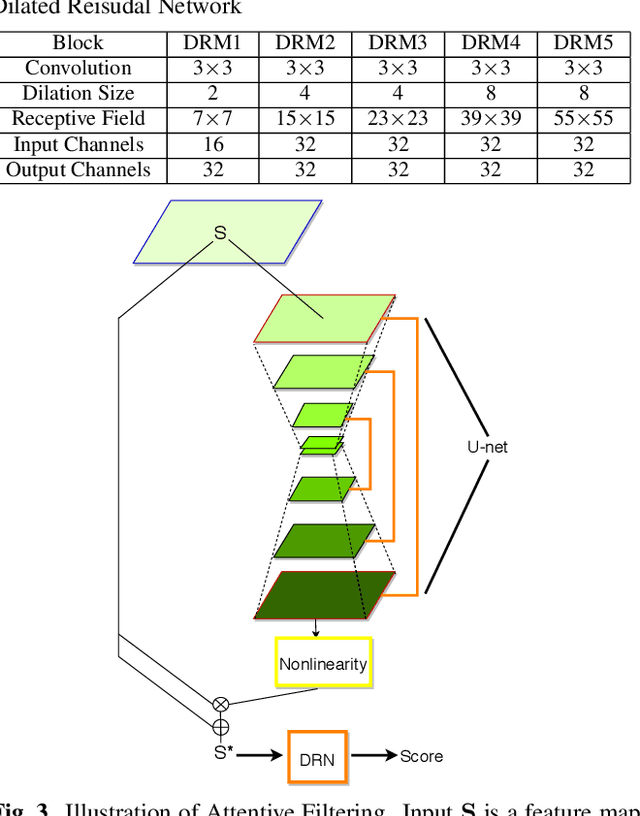
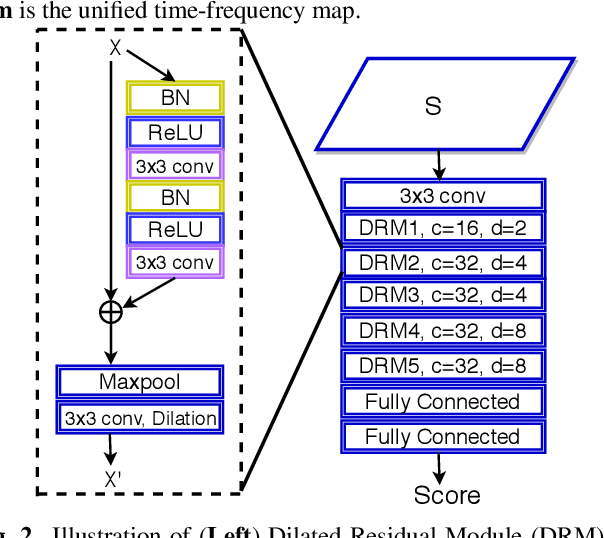
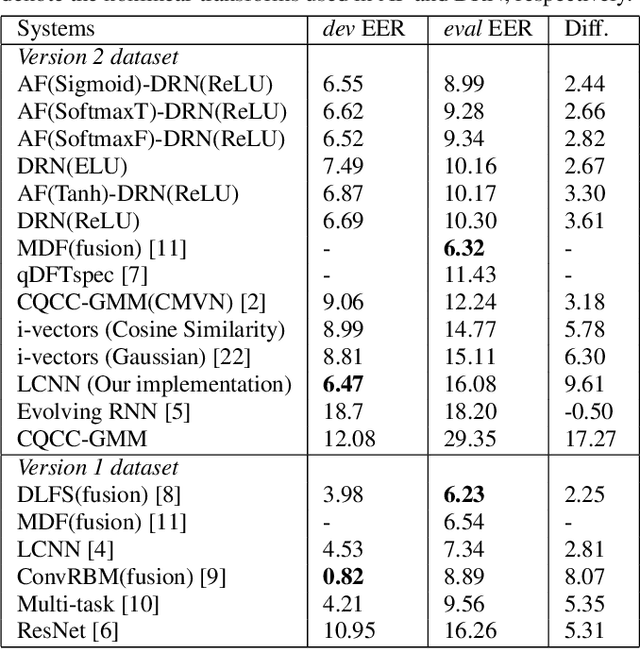
An attacker may use a variety of techniques to fool an automatic speaker verification system into accepting them as a genuine user. Anti-spoofing methods meanwhile aim to make the system robust against such attacks. The ASVspoof 2017 Challenge focused specifically on replay attacks, with the intention of measuring the limits of replay attack detection as well as developing countermeasures against them. In this work, we propose our replay attacks detection system - Attentive Filtering Network, which is composed of an attention-based filtering mechanism that enhances feature representations in both the frequency and time domains, and a ResNet-based classifier. We show that the network enables us to visualize the automatically acquired feature representations that are helpful for spoofing detection. Attentive Filtering Network attains an evaluation EER of 8.99$\%$ on the ASVspoof 2017 Version 2.0 dataset. With system fusion, our best system further obtains a 30$\%$ relative improvement over the ASVspoof 2017 enhanced baseline system.
Low-Resource Contextual Topic Identification on Speech
Sep 28, 2018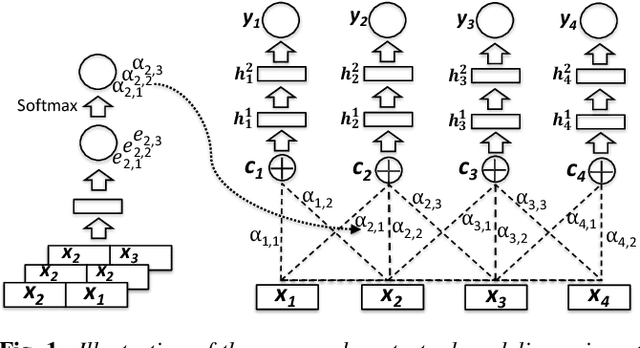

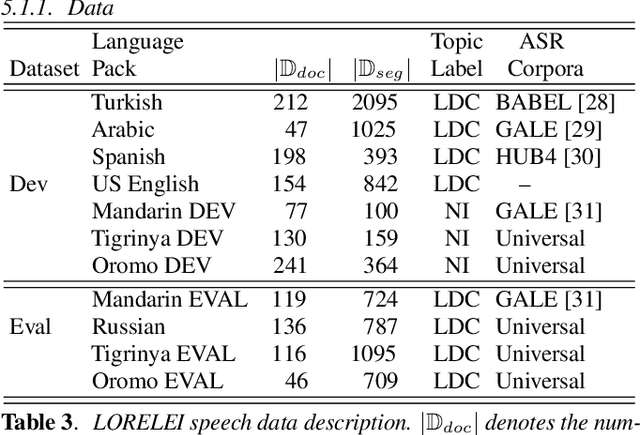
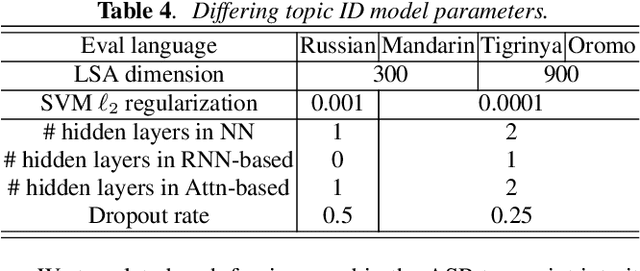
In topic identification (topic ID) on real-world unstructured audio, an audio instance of variable topic shifts is first broken into sequential segments, and each segment is independently classified. We first present a general purpose method for topic ID on spoken segments in low-resource languages, using a cascade of universal acoustic modeling, translation lexicons to English, and English-language topic classification. Next, instead of classifying each segment independently, we demonstrate that exploring the contextual dependencies across sequential segments can provide large improvements. In particular, we propose an attention-based contextual model which is able to leverage the contexts in a selective manner. We test both our contextual and non-contextual models on four LORELEI languages, and on all but one our attention-based contextual model significantly outperforms the context-independent models.
Punctuation Prediction Model for Conversational Speech
Jul 02, 2018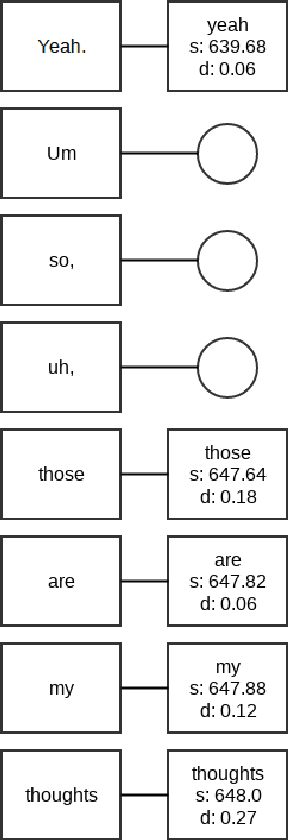
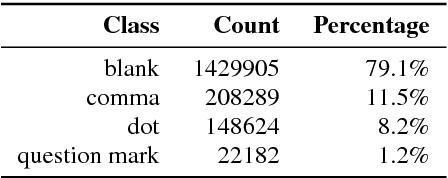
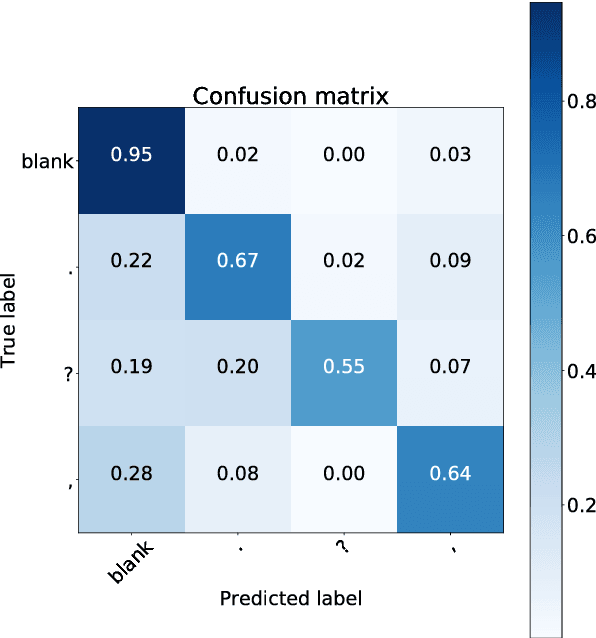
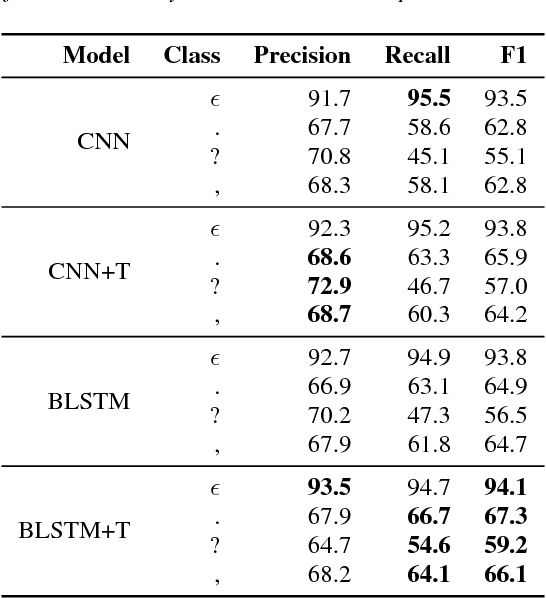
An ASR system usually does not predict any punctuation or capitalization. Lack of punctuation causes problems in result presentation and confuses both the human reader andoff-the-shelf natural language processing algorithms. To overcome these limitations, we train two variants of Deep Neural Network (DNN) sequence labelling models - a Bidirectional Long Short-Term Memory (BLSTM) and a Convolutional Neural Network (CNN), to predict the punctuation. The models are trained on the Fisher corpus which includes punctuation annotation. In our experiments, we combine time-aligned and punctuated Fisher corpus transcripts using a sequence alignment algorithm. The neural networks are trained on Common Web Crawl GloVe embedding of the words in Fisher transcripts aligned with conversation side indicators and word time infomation. The CNNs yield a better precision and BLSTMs tend to have better recall. While BLSTMs make fewer mistakes overall, the punctuation predicted by the CNN is more accurate - especially in the case of question marks. Our results constitute significant evidence that the distribution of words in time, as well as pre-trained embeddings, can be useful in the punctuation prediction task.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018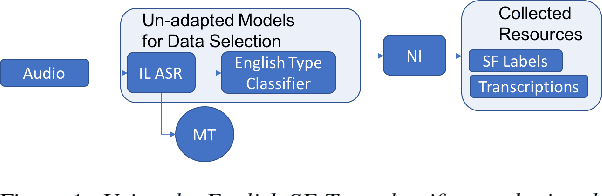
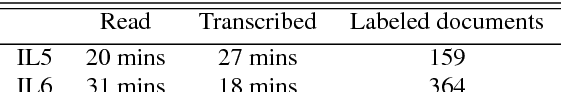
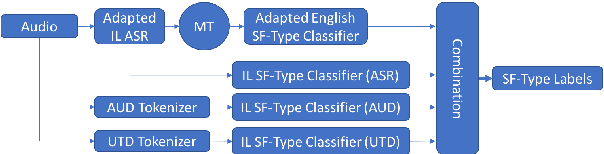
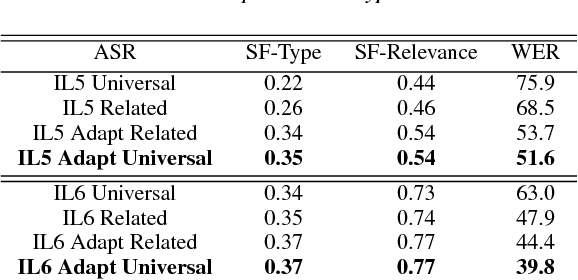
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
An Empirical Evaluation of Zero Resource Acoustic Unit Discovery
Feb 05, 2017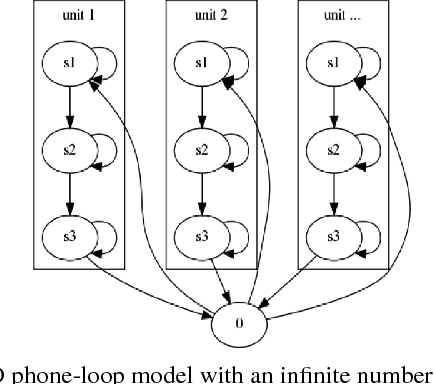
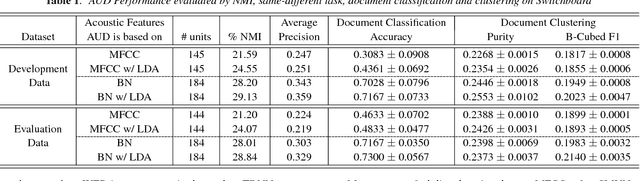
Acoustic unit discovery (AUD) is a process of automatically identifying a categorical acoustic unit inventory from speech and producing corresponding acoustic unit tokenizations. AUD provides an important avenue for unsupervised acoustic model training in a zero resource setting where expert-provided linguistic knowledge and transcribed speech are unavailable. Therefore, to further facilitate zero-resource AUD process, in this paper, we demonstrate acoustic feature representations can be significantly improved by (i) performing linear discriminant analysis (LDA) in an unsupervised self-trained fashion, and (ii) leveraging resources of other languages through building a multilingual bottleneck (BN) feature extractor to give effective cross-lingual generalization. Moreover, we perform comprehensive evaluations of AUD efficacy on multiple downstream speech applications, and their correlated performance suggests that AUD evaluations are feasible using different alternative language resources when only a subset of these evaluation resources can be available in typical zero resource applications.
Automatic Dialect Detection in Arabic Broadcast Speech
Aug 11, 2016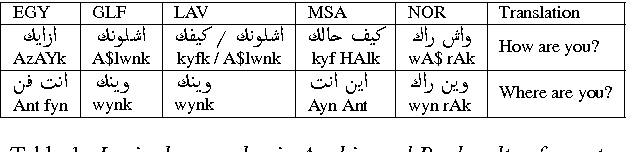
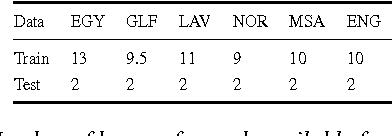

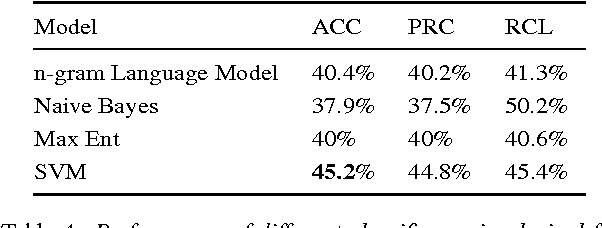
We investigate different approaches for dialect identification in Arabic broadcast speech, using phonetic, lexical features obtained from a speech recognition system, and acoustic features using the i-vector framework. We studied both generative and discriminate classifiers, and we combined these features using a multi-class Support Vector Machine (SVM). We validated our results on an Arabic/English language identification task, with an accuracy of 100%. We used these features in a binary classifier to discriminate between Modern Standard Arabic (MSA) and Dialectal Arabic, with an accuracy of 100%. We further report results using the proposed method to discriminate between the five most widely used dialects of Arabic: namely Egyptian, Gulf, Levantine, North African, and MSA, with an accuracy of 52%. We discuss dialect identification errors in the context of dialect code-switching between Dialectal Arabic and MSA, and compare the error pattern between manually labeled data, and the output from our classifier. We also release the train and test data as standard corpus for dialect identification.
A Unified Deep Neural Network for Speaker and Language Recognition
Apr 03, 2015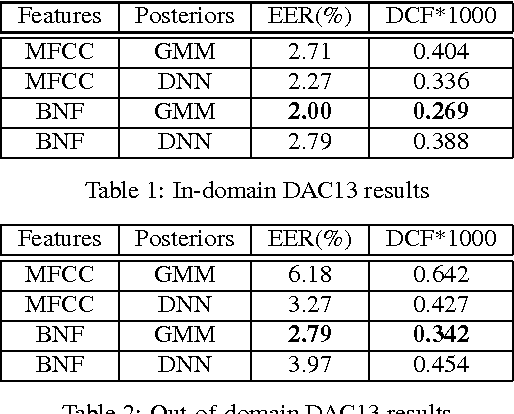
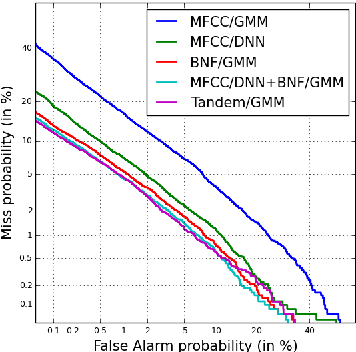
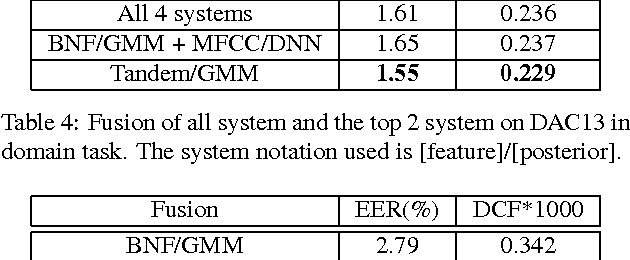
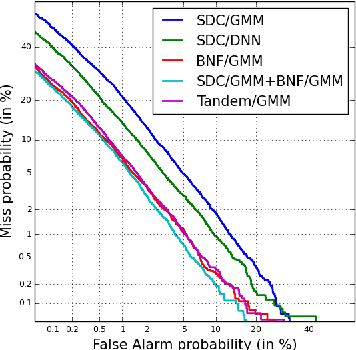
Learned feature representations and sub-phoneme posteriors from Deep Neural Networks (DNNs) have been used separately to produce significant performance gains for speaker and language recognition tasks. In this work we show how these gains are possible using a single DNN for both speaker and language recognition. The unified DNN approach is shown to yield substantial performance improvements on the the 2013 Domain Adaptation Challenge speaker recognition task (55% reduction in EER for the out-of-domain condition) and on the NIST 2011 Language Recognition Evaluation (48% reduction in EER for the 30s test condition).