 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulReaD: Knowledge-Graph-guided Software Vulnerability Reasoning and Detection
Feb 11, 2026Software vulnerability detection (SVD) is a critical challenge in modern systems. Large language models (LLMs) offer natural-language explanations alongside predictions, but most work focuses on binary evaluation, and explanations often lack semantic consistency with Common Weakness Enumeration (CWE) categories. We propose VulReaD, a knowledge-graph-guided approach for vulnerability reasoning and detection that moves beyond binary classification toward CWE-level reasoning. VulReaD leverages a security knowledge graph (KG) as a semantic backbone and uses a strong teacher LLM to generate CWE-consistent contrastive reasoning supervision, enabling student model training without manual annotations. Students are fine-tuned with Odds Ratio Preference Optimization (ORPO) to encourage taxonomy-aligned reasoning while suppressing unsupported explanations. Across three real-world datasets, VulReaD improves binary F1 by 8-10% and multi-class classification by 30% Macro-F1 and 18% Micro-F1 compared to state-of-the-art baselines. Results show that LLMs outperform deep learning baselines in binary detection and that KG-guided reasoning enhances CWE coverage and interpretability.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
Fast, high-fidelity Lyman $α$ forests with convolutional neural networks
Jun 23, 2021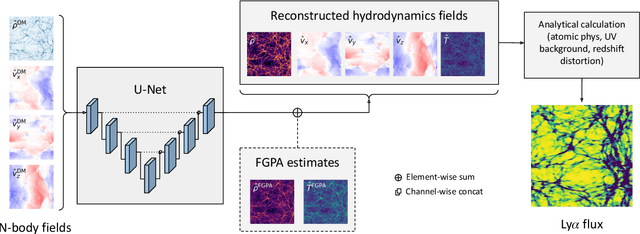
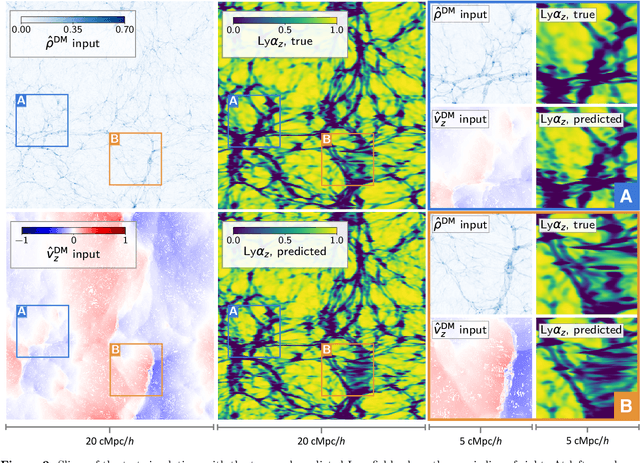
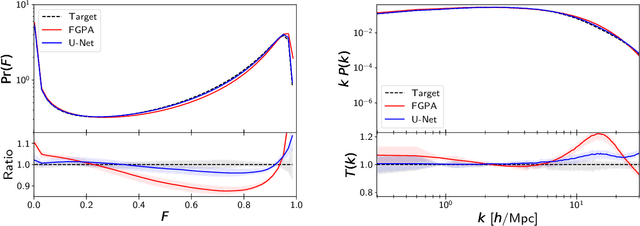
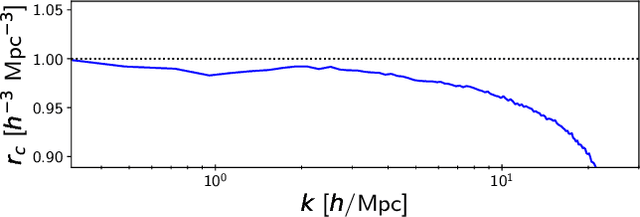
Full-physics cosmological simulations are powerful tools for studying the formation and evolution of structure in the universe but require extreme computational resources. Here, we train a convolutional neural network to use a cheaper N-body-only simulation to reconstruct the baryon hydrodynamic variables (density, temperature, and velocity) on scales relevant to the Lyman-$\alpha$ (Ly$\alpha$) forest, using data from Nyx simulations. We show that our method enables rapid estimation of these fields at a resolution of $\sim$20kpc, and captures the statistics of the Ly$\alpha$ forest with much greater accuracy than existing approximations. Because our model is fully-convolutional, we can train on smaller simulation boxes and deploy on much larger ones, enabling substantial computational savings. Furthermore, as our method produces an approximation for the hydrodynamic fields instead of Ly$\alpha$ flux directly, it is not limited to a particular choice of ionizing background or mean transmitted flux.
Towards physically consistent data-driven weather forecasting: Integrating data assimilation with equivariance-preserving deep spatial transformers
Mar 16, 2021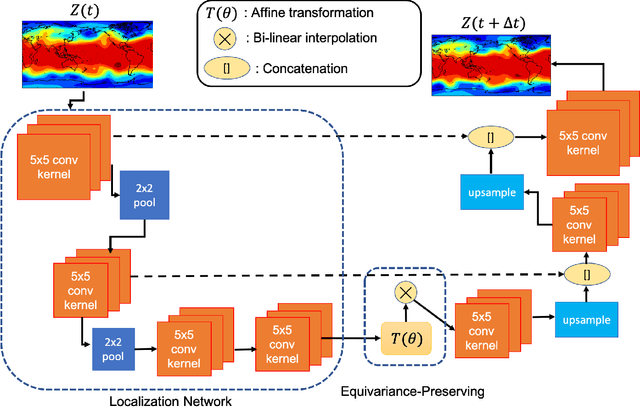
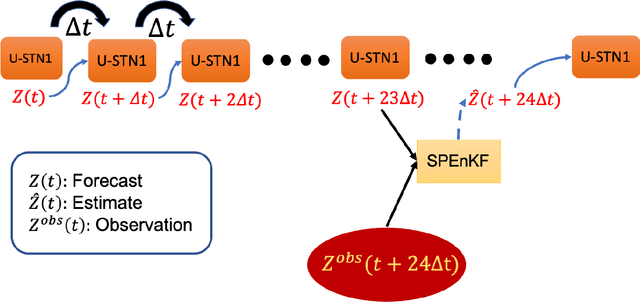
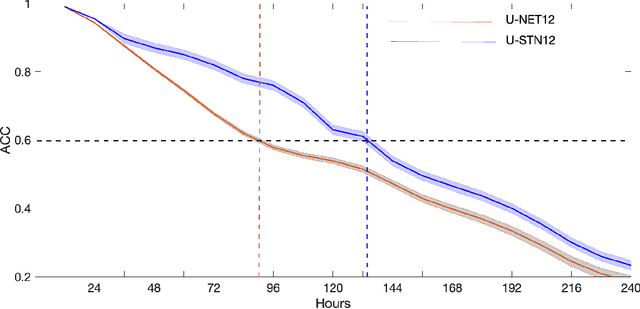
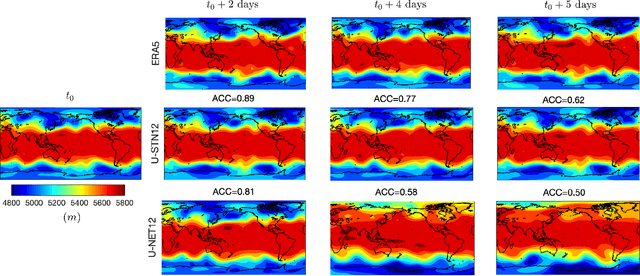
There is growing interest in data-driven weather prediction (DDWP), for example using convolutional neural networks such as U-NETs that are trained on data from models or reanalysis. Here, we propose 3 components to integrate with commonly used DDWP models in order to improve their physical consistency and forecast accuracy. These components are 1) a deep spatial transformer added to the latent space of the U-NETs to preserve a property called equivariance, which is related to correctly capturing rotations and scalings of features in spatio-temporal data, 2) a data-assimilation (DA) algorithm to ingest noisy observations and improve the initial conditions for next forecasts, and 3) a multi-time-step algorithm, which combines forecasts from DDWP models with different time steps through DA, improving the accuracy of forecasts at short intervals. To show the benefit/feasibility of each component, we use geopotential height at 500~hPa (Z500) from ERA5 reanalysis and examine the short-term forecast accuracy of specific setups of the DDWP framework. Results show that the equivariance-preserving networks (U-STNs) clearly outperform the U-NETs, for example improving the forecast skill by $45\%$. Using a sigma-point ensemble Kalman (SPEnKF) algorithm for DA and U-STN as the forward model, we show that stable, accurate DA cycles are achieved even with high observation noise. The DDWP+DA framework substantially benefits from large ($O(1000)$) ensembles that are inexpensively generated with the data-driven forward model in each DA cycle. The multi-time-step DDWP+DA framework also shows promises, e.g., it reduces the average error by factors of 2-3.
Estimating Galactic Distances From Images Using Self-supervised Representation Learning
Jan 12, 2021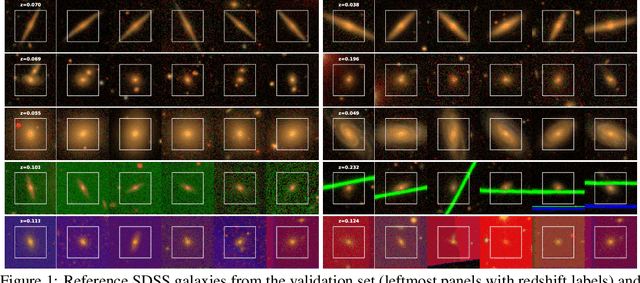
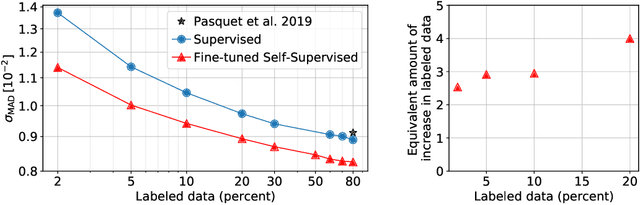
We use a contrastive self-supervised learning framework to estimate distances to galaxies from their photometric images. We incorporate data augmentations from computer vision as well as an application-specific augmentation accounting for galactic dust. We find that the resulting visual representations of galaxy images are semantically useful and allow for fast similarity searches, and can be successfully fine-tuned for the task of redshift estimation. We show that (1) pretraining on a large corpus of unlabeled data followed by fine-tuning on some labels can attain the accuracy of a fully-supervised model which requires 2-4x more labeled data, and (2) that by fine-tuning our self-supervised representations using all available data labels in the Main Galaxy Sample of the Sloan Digital Sky Survey (SDSS), we outperform the state-of-the-art supervised learning method.
Self-Supervised Representation Learning for Astronomical Images
Dec 24, 2020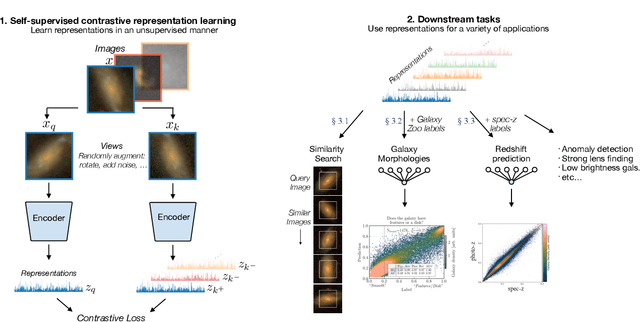

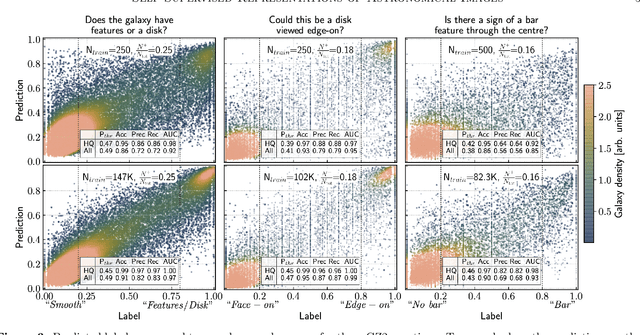
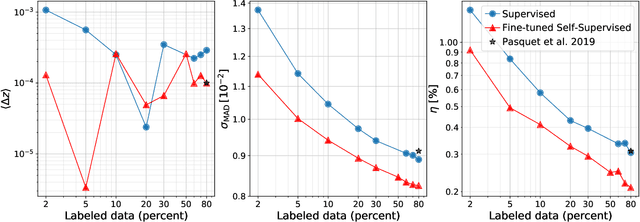
Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS) to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state-of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.
Using Machine Learning to Augment Coarse-Grid Computational Fluid Dynamics Simulations
Oct 03, 2020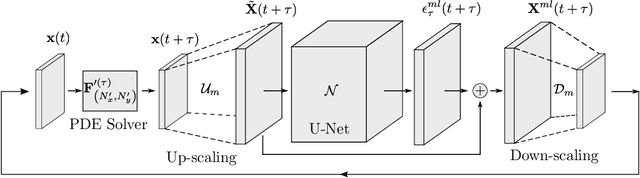
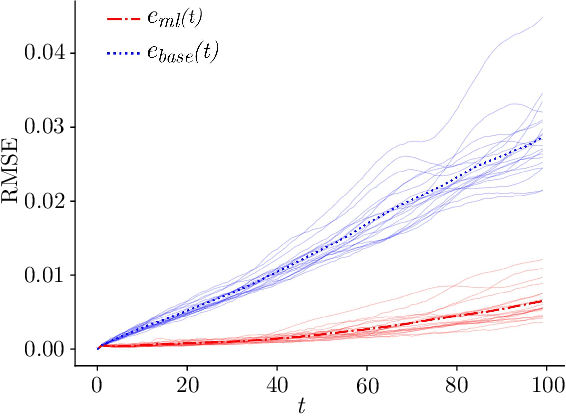
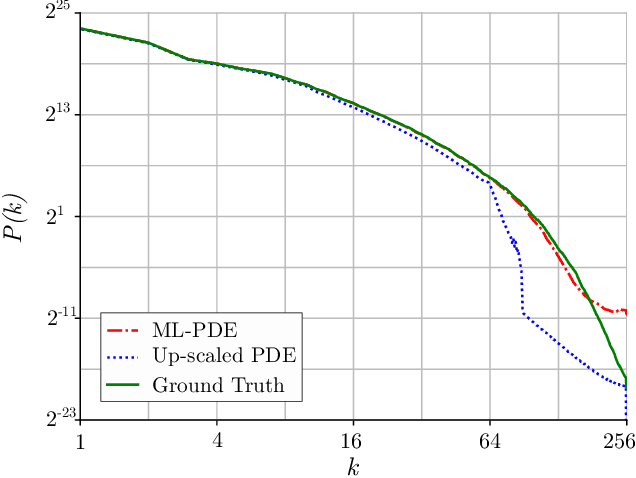
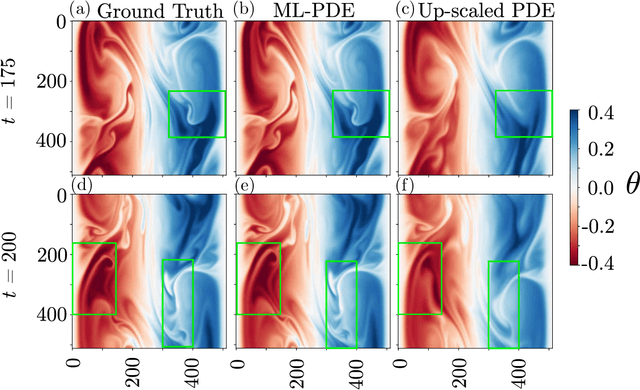
Simulation of turbulent flows at high Reynolds number is a computationally challenging task relevant to a large number of engineering and scientific applications in diverse fields such as climate science, aerodynamics, and combustion. Turbulent flows are typically modeled by the Navier-Stokes equations. Direct Numerical Simulation (DNS) of the Navier-Stokes equations with sufficient numerical resolution to capture all the relevant scales of the turbulent motions can be prohibitively expensive. Simulation at lower-resolution on a coarse-grid introduces significant errors. We introduce a machine learning (ML) technique based on a deep neural network architecture that corrects the numerical errors induced by a coarse-grid simulation of turbulent flows at high-Reynolds numbers, while simultaneously recovering an estimate of the high-resolution fields. Our proposed simulation strategy is a hybrid ML-PDE solver that is capable of obtaining a meaningful high-resolution solution trajectory while solving the system PDE at a lower resolution. The approach has the potential to dramatically reduce the expense of turbulent flow simulations. As a proof-of-concept, we demonstrate our ML-PDE strategy on a two-dimensional turbulent (Rayleigh Number $Ra=10^9$) Rayleigh-B\'enard Convection (RBC) problem.
MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
May 01, 2020
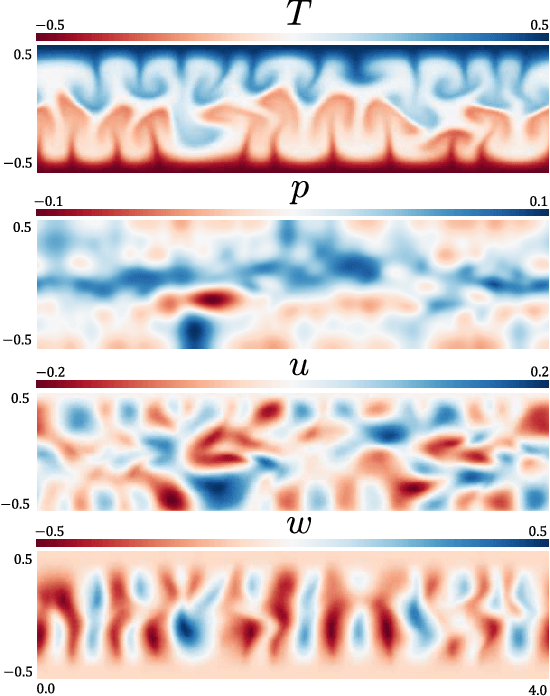

We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder. We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh-Benard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
Towards Physics-informed Deep Learning for Turbulent Flow Prediction
Dec 21, 2019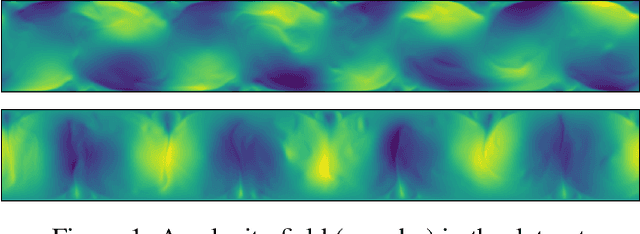
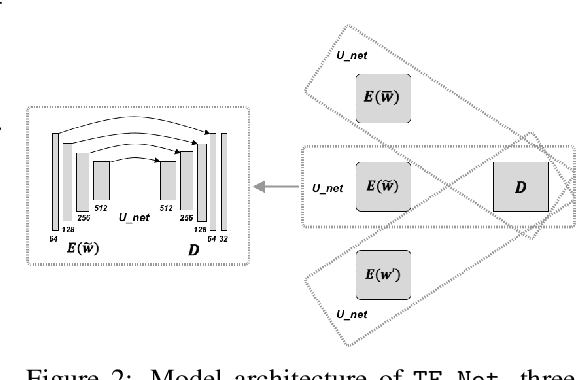
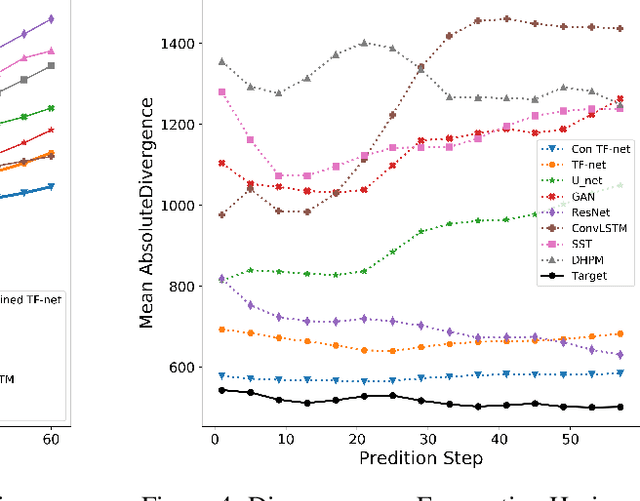
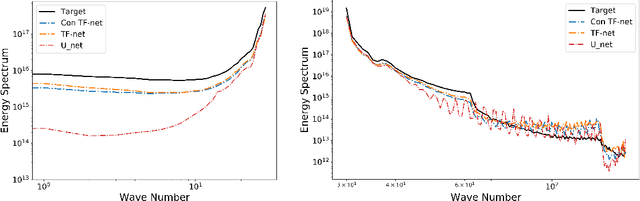
While deep learning has shown tremendous success in a wide range of domains, it remains a grand challenge to incorporate physical principles in a systematic manner to the design, training, and inference of such models. In this paper, we aim to predict turbulent flow by learning its highly nonlinear dynamics from spatiotemporal velocity fields of large-scale fluid flow simulations of relevance to turbulence modeling and climate modeling. We adopt a hybrid approach by marrying two well-established turbulent flow simulation techniques with deep learning. Specifically, we introduce trainable spectral filters in a coupled model of Reynolds-averaged Navier-Stokes (RANS) and Large Eddy Simulation (LES), followed by a specialized U-net for prediction. Our approach, which we call turbulent-Flow Net (TF-Net), is grounded in a principled physics model, yet offers the flexibility of learned representations. We compare our model, TF-Net, with state-of-the-art baselines and observe significant reductions in error for predictions 60 frames ahead. Most importantly, our method predicts physical fields that obey desirable physical characteristics, such as conservation of mass, whilst faithfully emulating the turbulent kinetic energy field and spectrum, which are critical for accurate prediction of turbulent flows.
Creating Virtual Universes Using Generative Adversarial Networks
Aug 17, 2018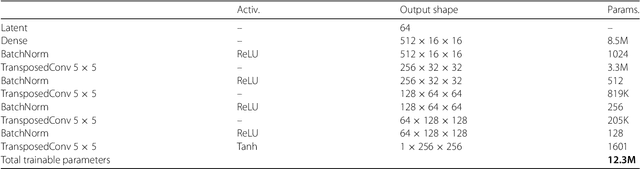
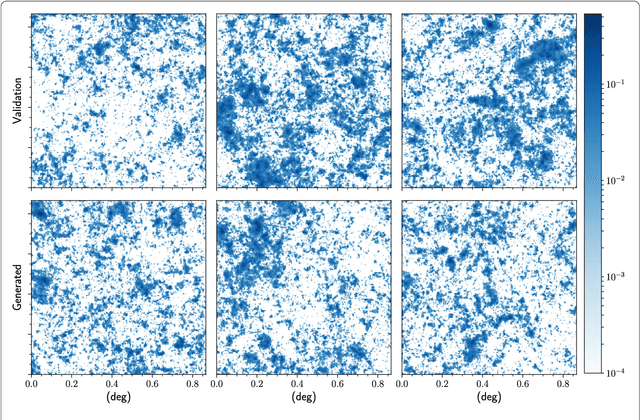

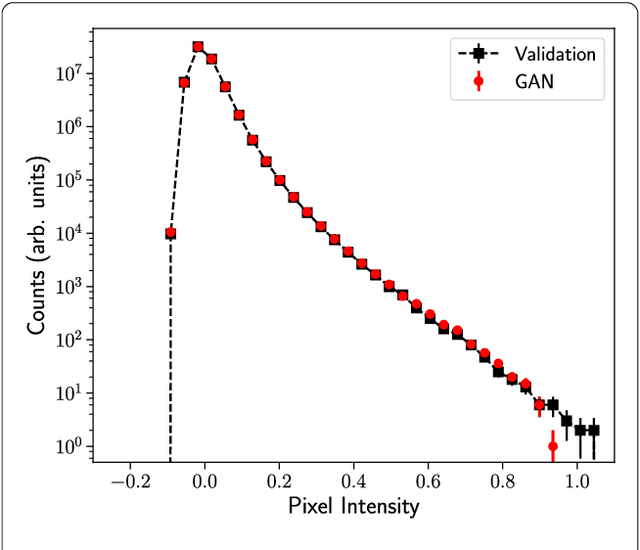
Inferring model parameters from experimental data is a grand challenge in many sciences, including cosmology. This often relies critically on high fidelity numerical simulations, which are prohibitively computationally expensive. The application of deep learning techniques to generative modeling is renewing interest in using high dimensional density estimators as computationally inexpensive emulators of fully-fledged simulations. These generative models have the potential to make a dramatic shift in the field of scientific simulations, but for that shift to happen we need to study the performance of such generators in the precision regime needed for science applications. To this end, in this letter we apply Generative Adversarial Networks to the problem of generating cosmological weak lensing convergence maps. We show that our generator network produces maps that are described by, with high statistical confidence, the same summary statistics as the fully simulated maps.