 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Driven Zero-Shot MRI Reconstruction with Non-local Image Priors
Jun 13, 2026Zero-Shot Self-Supervised Learning (ZS-SSL) has emerged as a promising paradigm for accelerated Magnetic Resonance Imaging (MRI) reconstruction, eliminating the reliance on fully-sampled external datasets. However, learning solely from a single under-sampled scan suffers from supervision scarcity and optimization instability, often leading to overfitting or artifacts. To address these challenges, we propose a robust physics-driven ZS-SSL framework that synergizes physical consistency with image-domain non-local priors. Our method introduces three core innovations: (1) a Coil Sensitivity Map (CSM)-Guided Dynamic Repository, which stabilizes the training trajectory by filtering physically inconsistent artifacts based on coil sensitivity constraints; (2) a SPIRiT-based regularization, which enforces k-space self-consistency via a learned correlation kernel and stochastic masking; (3) a Non-Local Self-Similarity (NSS) Pixel Bank, which leverages the high-fidelity reference established by the former modules to explicitly mine non-local anatomical similarities, thereby augmenting supervision in the image domain. Extensive experiments on the FastMRI dataset demonstrate that our approach achieves state-of-the-art performance, particularly under high acceleration factors, effectively bridging the gap between zero-shot learning and supervised methods. The code is available at https://github.com/Zolento/NS-SSL.
AffordanceGrasp-R1:Leveraging Reasoning-Based Affordance Segmentation with Reinforcement Learning for Robotic Grasping
Feb 03, 2026We introduce AffordanceGrasp-R1, a reasoning-driven affordance segmentation framework for robotic grasping that combines a chain-of-thought (CoT) cold-start strategy with reinforcement learning to enhance deduction and spatial grounding. In addition, we redesign the grasping pipeline to be more context-aware by generating grasp candidates from the global scene point cloud and subsequently filtering them using instruction-conditioned affordance masks. Extensive experiments demonstrate that AffordanceGrasp-R1 consistently outperforms state-of-the-art (SOTA) methods on benchmark datasets, and real-world robotic grasping evaluations further validate its robustness and generalization under complex language-conditioned manipulation scenarios.
From Prompt to Graph: Comparing LLM-Based Information Extraction Strategies in Domain-Specific Ontology Development
Jan 31, 2026Ontologies are essential for structuring domain knowledge, improving accessibility, sharing, and reuse. However, traditional ontology construction relies on manual annotation and conventional natural language processing (NLP) techniques, making the process labour-intensive and costly, especially in specialised fields like casting manufacturing. The rise of Large Language Models (LLMs) offers new possibilities for automating knowledge extraction. This study investigates three LLM-based approaches, including pre-trained LLM-driven method, in-context learning (ICL) method and fine-tuning method to extract terms and relations from domain-specific texts using limited data. We compare their performances and use the best-performing method to build a casting ontology that validated by domian expert.
API: Empowering Generalizable Real-World Image Dehazing via Adaptive Patch Importance Learning
Jan 05, 2026Real-world image dehazing is a fundamental yet challenging task in low-level vision. Existing learning-based methods often suffer from significant performance degradation when applied to complex real-world hazy scenes, primarily due to limited training data and the intrinsic complexity of haze density distributions.To address these challenges, we introduce a novel Adaptive Patch Importance-aware (API) framework for generalizable real-world image dehazing. Specifically, our framework consists of an Automatic Haze Generation (AHG) module and a Density-aware Haze Removal (DHR) module. AHG provides a hybrid data augmentation strategy by generating realistic and diverse hazy images as additional high-quality training data. DHR considers hazy regions with varying haze density distributions for generalizable real-world image dehazing in an adaptive patch importance-aware manner. To alleviate the ambiguity of the dehazed image details, we further introduce a new Multi-Negative Contrastive Dehazing (MNCD) loss, which fully utilizes information from multiple negative samples across both spatial and frequency domains. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across multiple real-world benchmarks, delivering strong results in both quantitative metrics and qualitative visual quality, and exhibiting robust generalization across diverse haze distributions.
Nighttime Hazy Image Enhancement via Progressively and Mutually Reinforcing Night-Haze Priors
Jan 05, 2026Enhancing the visibility of nighttime hazy images is challenging due to the complex degradation distributions. Existing methods mainly address a single type of degradation (e.g., haze or low-light) at a time, ignoring the interplay of different degradation types and resulting in limited visibility improvement. We observe that the domain knowledge shared between low-light and haze priors can be reinforced mutually for better visibility. Based on this key insight, in this paper, we propose a novel framework that enhances visibility in nighttime hazy images by reinforcing the intrinsic consistency between haze and low-light priors mutually and progressively. In particular, our model utilizes image-, patch-, and pixel-level experts that operate across visual and frequency domains to recover global scene structure, regional patterns, and fine-grained details progressively. A frequency-aware router is further introduced to adaptively guide the contribution of each expert, ensuring robust image restoration. Extensive experiments demonstrate the superior performance of our model on nighttime dehazing benchmarks both quantitatively and qualitatively. Moreover, we showcase the generalizability of our model in daytime dehazing and low-light enhancement tasks.
TriLoRA: Integrating SVD for Advanced Style Personalization in Text-to-Image Generation
May 18, 2024



As deep learning technology continues to advance, image generation models, especially models like Stable Diffusion, are finding increasingly widespread application in visual arts creation. However, these models often face challenges such as overfitting, lack of stability in generated results, and difficulties in accurately capturing the features desired by creators during the fine-tuning process. In response to these challenges, we propose an innovative method that integrates Singular Value Decomposition (SVD) into the Low-Rank Adaptation (LoRA) parameter update strategy, aimed at enhancing the fine-tuning efficiency and output quality of image generation models. By incorporating SVD within the LoRA framework, our method not only effectively reduces the risk of overfitting but also enhances the stability of model outputs, and captures subtle, creator-desired feature adjustments more accurately. We evaluated our method on multiple datasets, and the results show that, compared to traditional fine-tuning methods, our approach significantly improves the model's generalization ability and creative flexibility while maintaining the quality of generation. Moreover, this method maintains LoRA's excellent performance under resource-constrained conditions, allowing for significant improvements in image generation quality without sacrificing the original efficiency and resource advantages.
RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth Estimation
Jul 26, 2022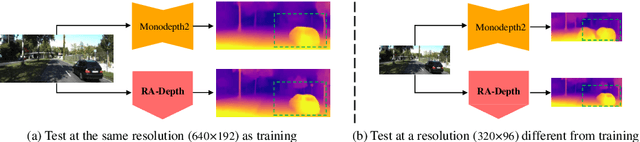
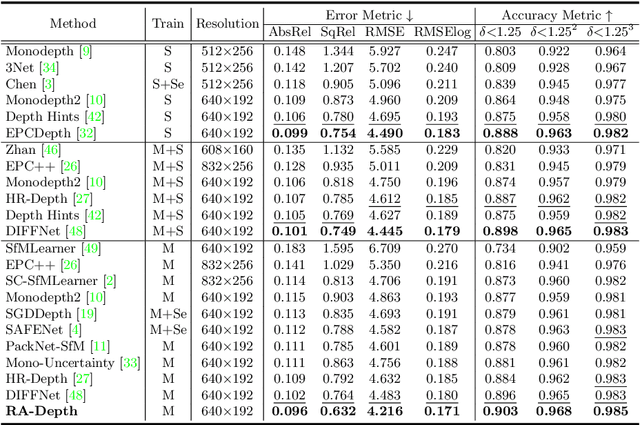
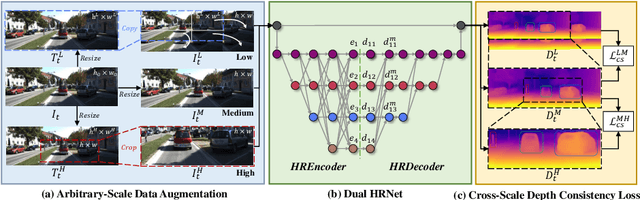
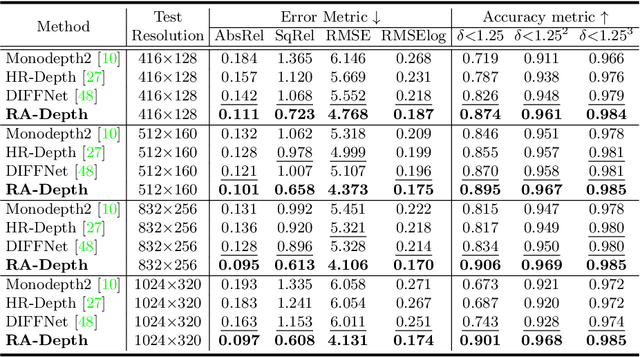
Existing self-supervised monocular depth estimation methods can get rid of expensive annotations and achieve promising results. However, these methods suffer from severe performance degradation when directly adopting a model trained on a fixed resolution to evaluate at other different resolutions. In this paper, we propose a resolution adaptive self-supervised monocular depth estimation method (RA-Depth) by learning the scale invariance of the scene depth. Specifically, we propose a simple yet efficient data augmentation method to generate images with arbitrary scales for the same scene. Then, we develop a dual high-resolution network that uses the multi-path encoder and decoder with dense interactions to aggregate multi-scale features for accurate depth inference. Finally, to explicitly learn the scale invariance of the scene depth, we formulate a cross-scale depth consistency loss on depth predictions with different scales. Extensive experiments on the KITTI, Make3D and NYU-V2 datasets demonstrate that RA-Depth not only achieves state-of-the-art performance, but also exhibits a good ability of resolution adaptation.