 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Dynamic Consistent Submodular Maximization
Jun 03, 2026Consistency is an important property in dynamic submodular maximization and entails maintaining a near-optimal solution at all times, making only a small number of adjustments to the solution in each step. Prior work has explored this question for the insertion-only case, where the algorithm faces a stream of $n$ insertions, and has established lower and upper bounds for the cardinality-constrained version of the problem. We consider this question in the fully dynamic setting, where the stream of operations may contain both insertions and deletions. We develop a general framework for designing algorithms for this setting, and instantiate it to obtain the first constant-factor approximations with sublinear consistency. For cardinality constraints, we propose a $\frac 12 - O(\varepsilon)$ approximation that is $O\left(\frac{1}{\varepsilon^2}\right)$ consistent. For rank-$k$ matroid constraints, we construct a $\frac 14 - O(\varepsilon)$ approximation to the dynamic optimum that is $O\left(\frac{\log k}{\varepsilon^2}\right)$ consistent.
Retriever Portfolios: A Principled Approach to Adaptive RAG
May 29, 2026Retrieval-augmented generation (RAG) systems typically rely on a single retriever and a single set of hyperparameters, despite facing highly heterogeneous queries that range from simple factoid questions to complex multi-hop reasoning. We propose a method that automatically selects a small, diverse subset of retrievers (a portfolio) from a large pool of candidates, to cover different regions of the target query distribution. We formalize this setting via an expected best-of-$k$ objective over the query distribution and show that it admits an efficient portfolio construction algorithm with near-optimal guarantees. Across multiple QA benchmarks, our learned portfolios and router pipeline consistently outperform single-retriever and naive multi-retriever baselines on both retrieval metrics and answer quality. In addition, compared to inference-time hyperparameter tuning approaches, fixed portfolios enable parallel retrieval and LLM calls, achieving comparable (and sometimes better) accuracy with substantially lower latency and token cost.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
Clustering with Label Consistency
Dec 22, 2025Designing efficient, effective, and consistent metric clustering algorithms is a significant challenge attracting growing attention. Traditional approaches focus on the stability of cluster centers; unfortunately, this neglects the real-world need for stable point labels, i.e., stable assignments of points to named sets (clusters). In this paper, we address this gap by initiating the study of label-consistent metric clustering. We first introduce a new notion of consistency, measuring the label distance between two consecutive solutions. Then, armed with this new definition, we design new consistent approximation algorithms for the classical $k$-center and $k$-median problems.
The Cost of Consistency: Submodular Maximization with Constant Recourse
Dec 03, 2024



In this work, we study online submodular maximization, and how the requirement of maintaining a stable solution impacts the approximation. In particular, we seek bounds on the best-possible approximation ratio that is attainable when the algorithm is allowed to make at most a constant number of updates per step. We show a tight information-theoretic bound of $\tfrac{2}{3}$ for general monotone submodular functions, and an improved (also tight) bound of $\tfrac{3}{4}$ for coverage functions. Since both these bounds are attained by non poly-time algorithms, we also give a poly-time randomized algorithm that achieves a $0.51$-approximation. Combined with an information-theoretic hardness of $\tfrac{1}{2}$ for deterministic algorithms from prior work, our work thus shows a separation between deterministic and randomized algorithms, both information theoretically and for poly-time algorithms.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
An Analysis of $D^α$ seeding for $k$-means
Oct 20, 2023One of the most popular clustering algorithms is the celebrated $D^\alpha$ seeding algorithm (also know as $k$-means++ when $\alpha=2$) by Arthur and Vassilvitskii (2007), who showed that it guarantees in expectation an $O(2^{2\alpha}\cdot \log k)$-approximate solution to the ($k$,$\alpha$)-means cost (where euclidean distances are raised to the power $\alpha$) for any $\alpha\ge 1$. More recently, Balcan, Dick, and White (2018) observed experimentally that using $D^\alpha$ seeding with $\alpha>2$ can lead to a better solution with respect to the standard $k$-means objective (i.e. the $(k,2)$-means cost). In this paper, we provide a rigorous understanding of this phenomenon. For any $\alpha>2$, we show that $D^\alpha$ seeding guarantees in expectation an approximation factor of $$ O_\alpha \left((g_\alpha)^{2/\alpha}\cdot \left(\frac{\sigma_{\mathrm{max}}}{\sigma_{\mathrm{min}}}\right)^{2-4/\alpha}\cdot (\min\{\ell,\log k\})^{2/\alpha}\right)$$ with respect to the standard $k$-means cost of any underlying clustering; where $g_\alpha$ is a parameter capturing the concentration of the points in each cluster, $\sigma_{\mathrm{max}}$ and $\sigma_{\mathrm{min}}$ are the maximum and minimum standard deviation of the clusters around their means, and $\ell$ is the number of distinct mixing weights in the underlying clustering (after rounding them to the nearest power of $2$). We complement these results by some lower bounds showing that the dependency on $g_\alpha$ and $\sigma_{\mathrm{max}}/\sigma_{\mathrm{min}}$ is tight. Finally, we provide an experimental confirmation of the effects of the aforementioned parameters when using $D^\alpha$ seeding. Further, we corroborate the observation that $\alpha>2$ can indeed improve the $k$-means cost compared to $D^2$ seeding, and that this advantage remains even if we run Lloyd's algorithm after the seeding.
Nearly-Tight and Oblivious Algorithms for Explainable Clustering
Jun 30, 2021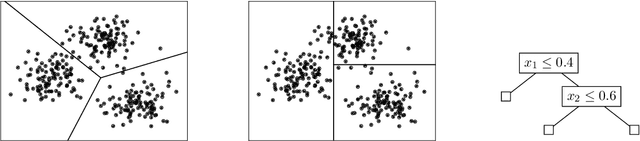

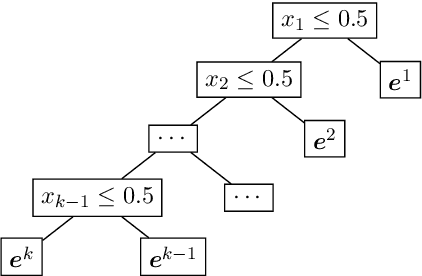
We study the problem of explainable clustering in the setting first formalized by Moshkovitz, Dasgupta, Rashtchian, and Frost (ICML 2020). A $k$-clustering is said to be explainable if it is given by a decision tree where each internal node splits data points with a threshold cut in a single dimension (feature), and each of the $k$ leaves corresponds to a cluster. We give an algorithm that outputs an explainable clustering that loses at most a factor of $O(\log^2 k)$ compared to an optimal (not necessarily explainable) clustering for the $k$-medians objective, and a factor of $O(k \log^2 k)$ for the $k$-means objective. This improves over the previous best upper bounds of $O(k)$ and $O(k^2)$, respectively, and nearly matches the previous $\Omega(\log k)$ lower bound for $k$-medians and our new $\Omega(k)$ lower bound for $k$-means. The algorithm is remarkably simple. In particular, given an initial not necessarily explainable clustering in $\mathbb{R}^d$, it is oblivious to the data points and runs in time $O(dk \log^2 k)$, independent of the number of data points $n$. Our upper and lower bounds also generalize to objectives given by higher $\ell_p$-norms.
Fast and Accurate $k$-means++ via Rejection Sampling
Dec 22, 2020



$k$-means++ \cite{arthur2007k} is a widely used clustering algorithm that is easy to implement, has nice theoretical guarantees and strong empirical performance. Despite its wide adoption, $k$-means++ sometimes suffers from being slow on large data-sets so a natural question has been to obtain more efficient algorithms with similar guarantees. In this paper, we present a near linear time algorithm for $k$-means++ seeding. Interestingly our algorithm obtains the same theoretical guarantees as $k$-means++ and significantly improves earlier results on fast $k$-means++ seeding. Moreover, we show empirically that our algorithm is significantly faster than $k$-means++ and obtains solutions of equivalent quality.
The Primal-Dual method for Learning Augmented Algorithms
Oct 22, 2020


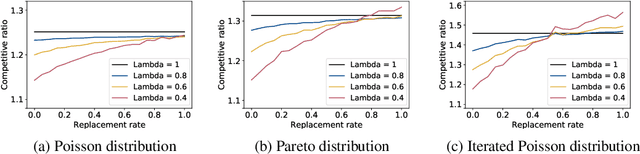
The extension of classical online algorithms when provided with predictions is a new and active research area. In this paper, we extend the primal-dual method for online algorithms in order to incorporate predictions that advise the online algorithm about the next action to take. We use this framework to obtain novel algorithms for a variety of online covering problems. We compare our algorithms to the cost of the true and predicted offline optimal solutions and show that these algorithms outperform any online algorithm when the prediction is accurate while maintaining good guarantees when the prediction is misleading.