 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Programming Encoding for Subword Segmentation in Neural Machine Translation
May 03, 2020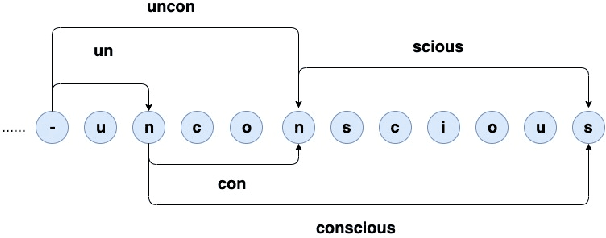
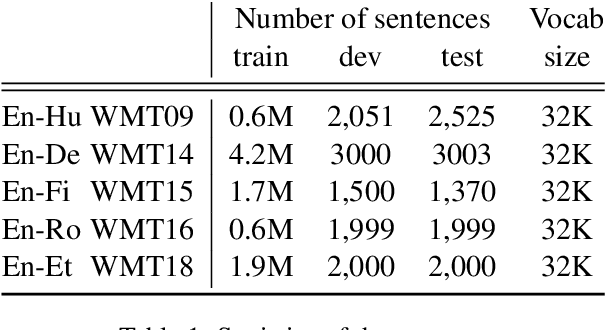
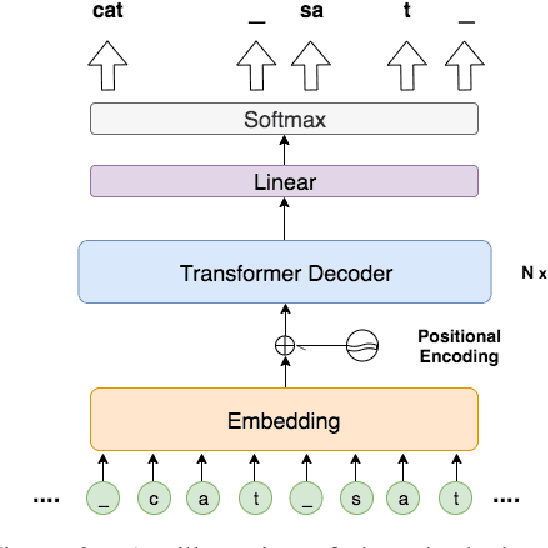
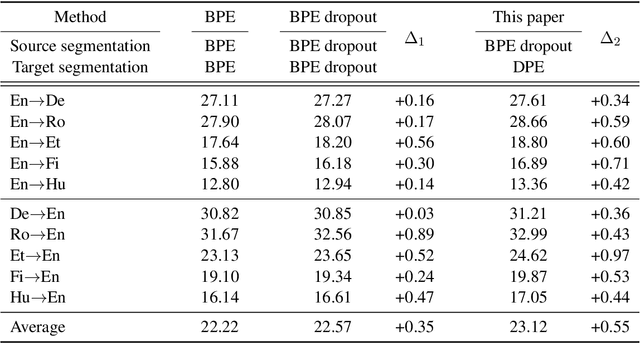
This paper introduces Dynamic Programming Encoding (DPE), a new segmentation algorithm for tokenizing sentences into subword units. We view the subword segmentation of output sentences as a latent variable that should be marginalized out for learning and inference. A mixed character-subword transformer is proposed, which enables exact log marginal likelihood estimation and exact MAP inference to find target segmentations with maximum posterior probability. DPE uses a lightweight mixed character-subword transformer as a means of pre-processing parallel data to segment output sentences using dynamic programming. Empirical results on machine translation suggest that DPE is effective for segmenting output sentences and can be combined with BPE dropout for stochastic segmentation of source sentences. DPE achieves an average improvement of 0.9 BLEU over BPE (Sennrich et al., 2016) and an average improvement of 0.55 BLEU over BPE dropout (Provilkov et al., 2019) on several WMT datasets including English <=> (German, Romanian, Estonian, Finnish, Hungarian).
Non-Autoregressive Machine Translation with Latent Alignments
Apr 22, 2020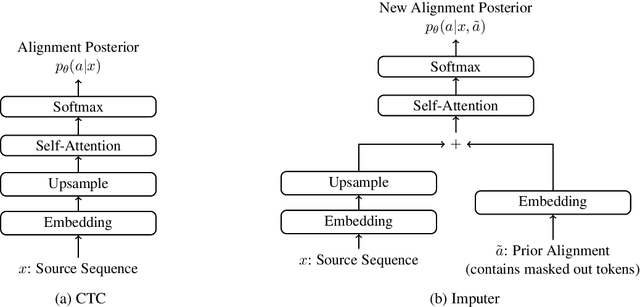
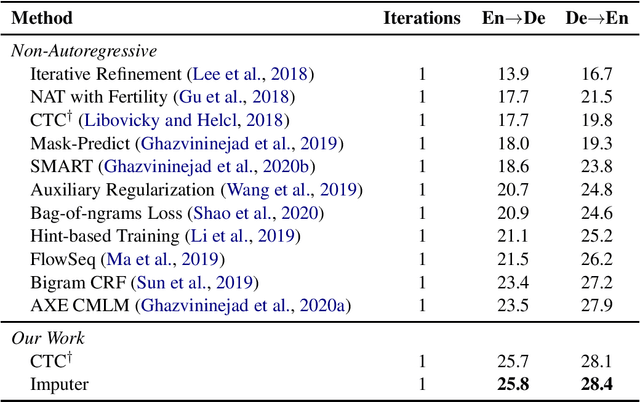


This paper investigates two latent alignment models for non-autoregressive machine translation, namely CTC and Imputer. CTC generates outputs in a single step, makes strong conditional independence assumptions about output variables, and marginalizes out latent alignments using dynamic programming. Imputer generates outputs in a constant number of steps, and approximately marginalizes out possible generation orders and latent alignments for training. These models are simpler than existing non-autoregressive methods, since they do not require output length prediction as a pre-process. In addition, our architecture is simpler than typical encoder-decoder architectures, since input-output cross attention is not used. On the competitive WMT'14 En$\rightarrow$De task, our CTC model achieves 25.7 BLEU with a single generation step, while Imputer achieves 27.5 BLEU with 2 generation steps, and 28.0 BLEU with 4 generation steps. This compares favourably to the baseline autoregressive Transformer with 27.8 BLEU.
Exemplar VAEs for Exemplar based Generation and Data Augmentation
Apr 09, 2020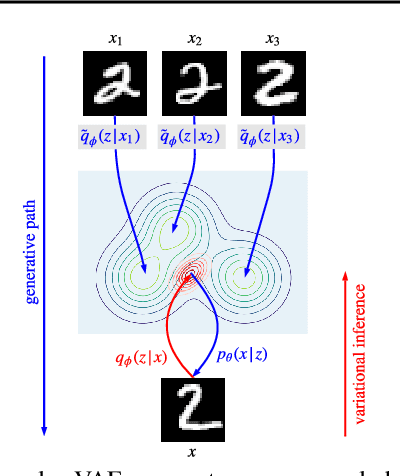

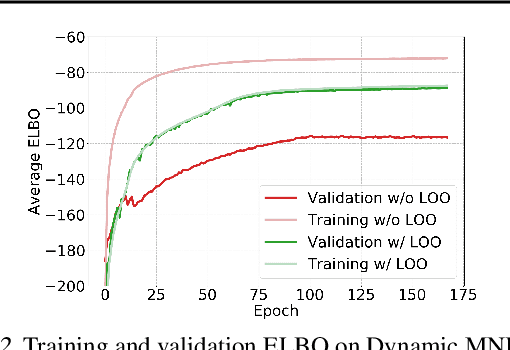
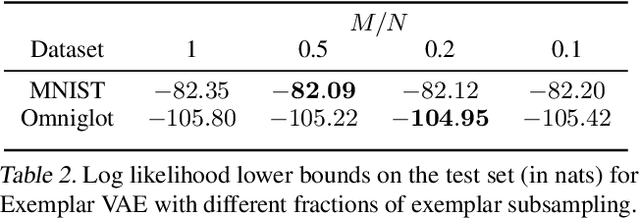
This paper presents a framework for exemplar based generative modeling, featuring Exemplar VAEs. To generate a sample from the Exemplar VAE, one first draws a random exemplar from a training dataset, and then stochastically transforms that exemplar into a latent code, which is then used to generate a new observation. We show that the Exemplar VAE can be interpreted as a VAE with a mixture of Gaussians prior in the latent space, with Gaussian means defined by the latent encoding of the exemplars. To enable optimization and avoid overfitting, Exemplar VAE's parameters are learned using leave-one-out and exemplar subsampling, where, for the generation of each data point, we build a prior based on a random subset of the remaining data points. To accelerate learning, which requires finding the exemplars that exert the greatest influence on the generation of each data point, we use approximate nearest neighbor search in the latent space, yielding a lower bound on the log marginal likelihood. Experiments demonstrate the effectiveness of Exemplar VAEs in density estimation, representation learning, and generative data augmentation for supervised learning.
NiLBS: Neural Inverse Linear Blend Skinning
Apr 06, 2020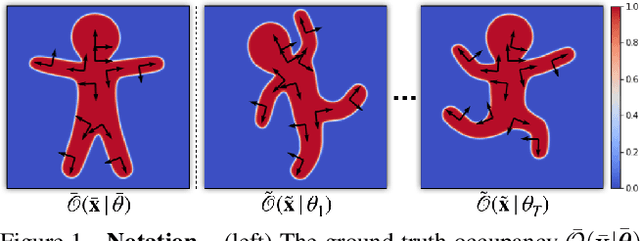
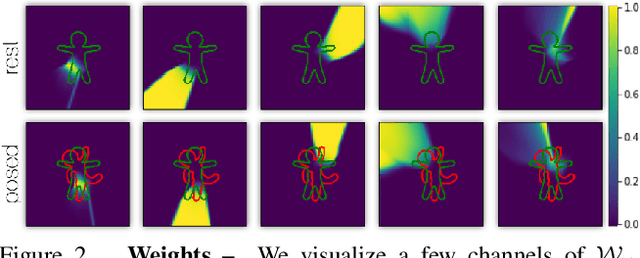
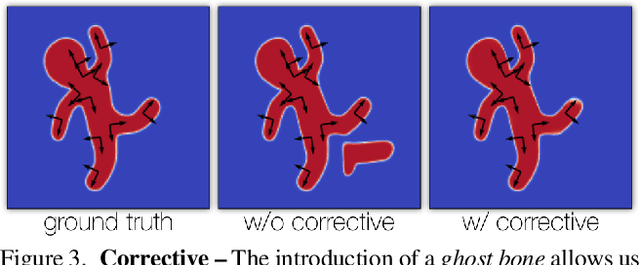
In this technical report, we investigate efficient representations of articulated objects (e.g. human bodies), which is an important problem in computer vision and graphics. To deform articulated geometry, existing approaches represent objects as meshes and deform them using "skinning" techniques. The skinning operation allows a wide range of deformations to be achieved with a small number of control parameters. This paper introduces a method to invert the deformations undergone via traditional skinning techniques via a neural network parameterized by pose. The ability to invert these deformations allows values (e.g., distance function, signed distance function, occupancy) to be pre-computed at rest pose, and then efficiently queried when the character is deformed. We leave empirical evaluation of our approach to future work.
SUMO: Unbiased Estimation of Log Marginal Probability for Latent Variable Models
Apr 01, 2020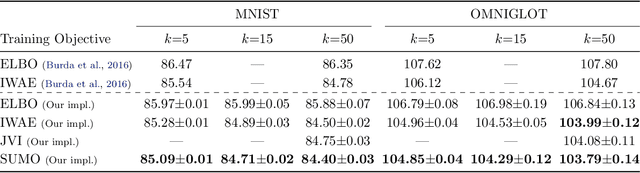

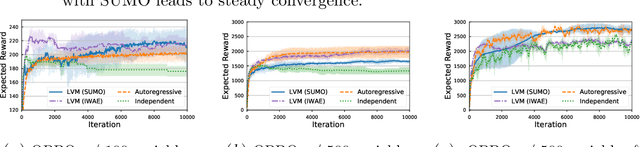
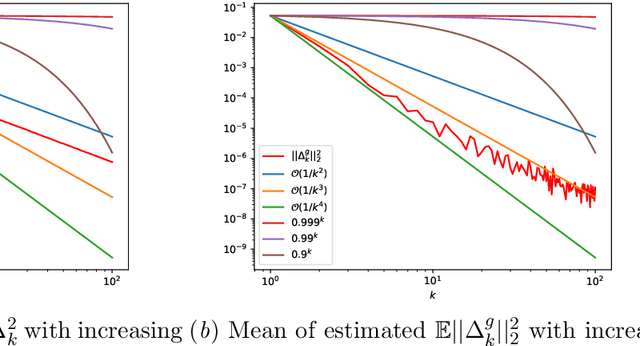
Standard variational lower bounds used to train latent variable models produce biased estimates of most quantities of interest. We introduce an unbiased estimator of the log marginal likelihood and its gradients for latent variable models based on randomized truncation of infinite series. If parameterized by an encoder-decoder architecture, the parameters of the encoder can be optimized to minimize its variance of this estimator. We show that models trained using our estimator give better test-set likelihoods than a standard importance-sampling based approach for the same average computational cost. This estimator also allows use of latent variable models for tasks where unbiased estimators, rather than marginal likelihood lower bounds, are preferred, such as minimizing reverse KL divergences and estimating score functions.
Imputer: Sequence Modelling via Imputation and Dynamic Programming
Feb 20, 2020
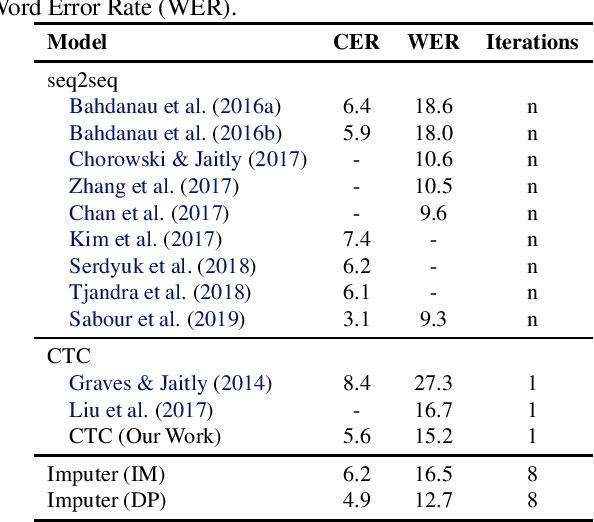
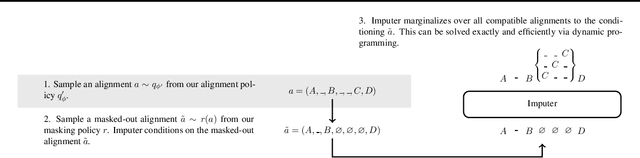
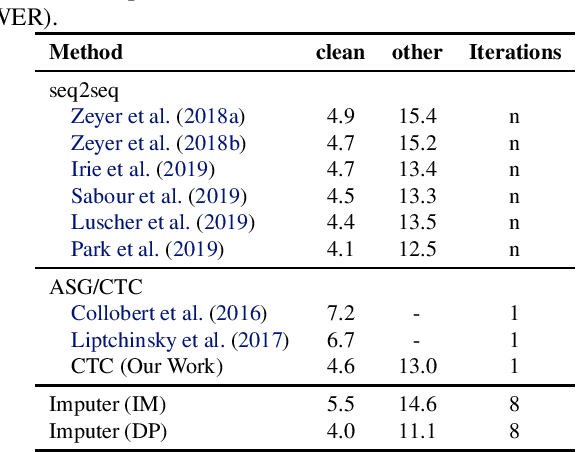
This paper presents the Imputer, a neural sequence model that generates output sequences iteratively via imputations. The Imputer is an iterative generative model, requiring only a constant number of generation steps independent of the number of input or output tokens. The Imputer can be trained to approximately marginalize over all possible alignments between the input and output sequences, and all possible generation orders. We present a tractable dynamic programming training algorithm, which yields a lower bound on the log marginal likelihood. When applied to end-to-end speech recognition, the Imputer outperforms prior non-autoregressive models and achieves competitive results to autoregressive models. On LibriSpeech test-other, the Imputer achieves 11.1 WER, outperforming CTC at 13.0 WER and seq2seq at 12.5 WER.
A Simple Framework for Contrastive Learning of Visual Representations
Feb 13, 2020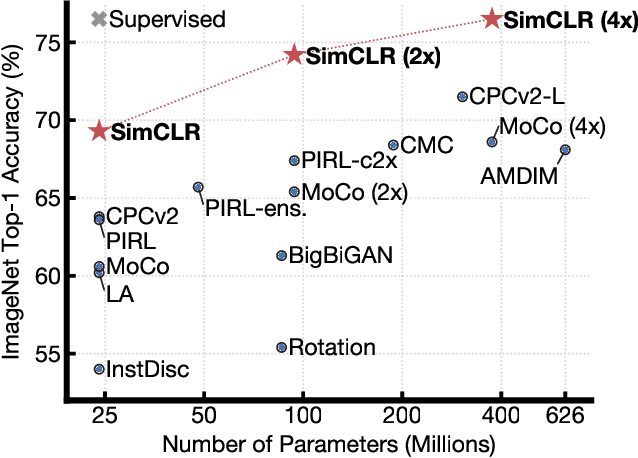

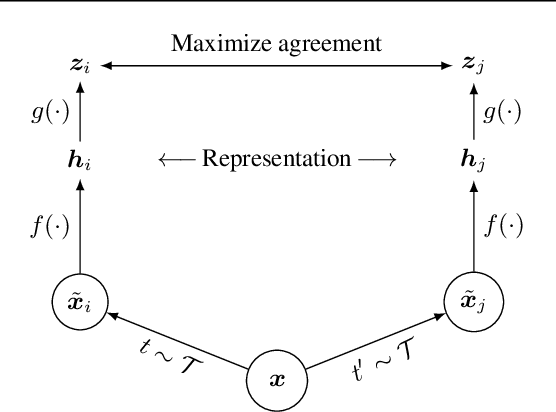

This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
Dec 11, 2019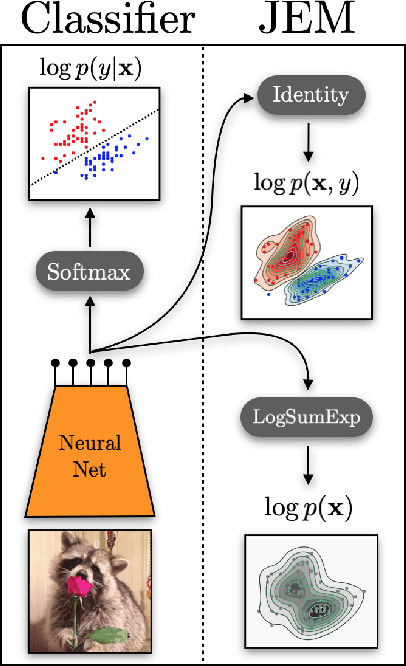
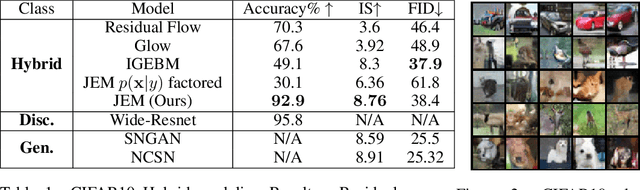
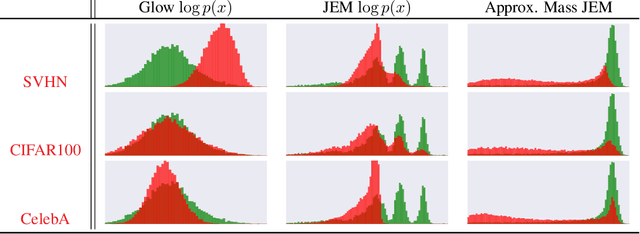

We propose to reinterpret a standard discriminative classifier of p(y|x) as an energy based model for the joint distribution p(x,y). In this setting, the standard class probabilities can be easily computed as well as unnormalized values of p(x) and p(x|y). Within this framework, standard discriminative architectures may beused and the model can also be trained on unlabeled data. We demonstrate that energy based training of the joint distribution improves calibration, robustness, andout-of-distribution detection while also enabling our models to generate samplesrivaling the quality of recent GAN approaches. We improve upon recently proposed techniques for scaling up the training of energy based models and presentan approach which adds little overhead compared to standard classification training. Our approach is the first to achieve performance rivaling the state-of-the-artin both generative and discriminative learning within one hybrid model.
NASA: Neural Articulated Shape Approximation
Dec 06, 2019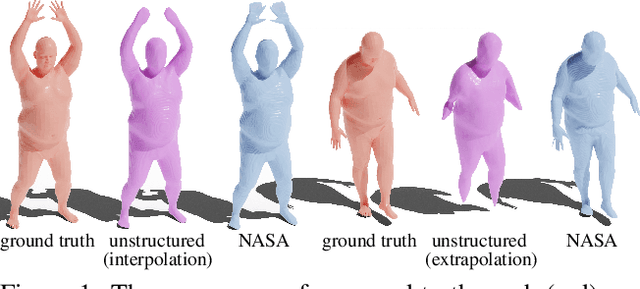


Efficient representation of articulated objects such as human bodies is an important problem in computer vision and graphics. To efficiently simulate deformation, existing approaches represent objects as meshes and deform them using skinning techniques. This paper introduces neural articulated shape approximation (NASA), a framework that enables efficient representation of articulated deformable objects using neural indicator functions parameterized by pose. In contrast to classic approaches, NASA avoids the need to convert between different representations. For occupancy testing, NASA circumvents the complexity of meshes and mitigates the issue of water-tightness. In comparison with regular grids and octrees, our approach provides high resolution without high memory use.
Dream to Control: Learning Behaviors by Latent Imagination
Dec 03, 2019
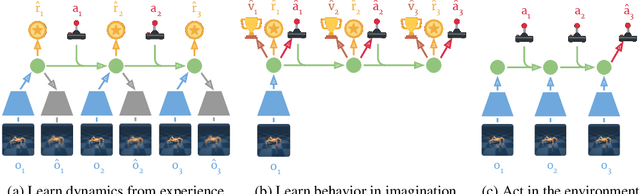
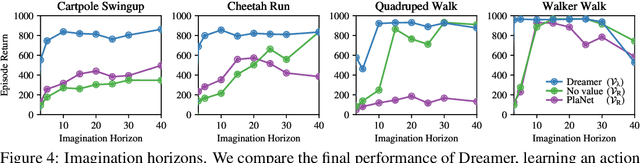

Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs is becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.