 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021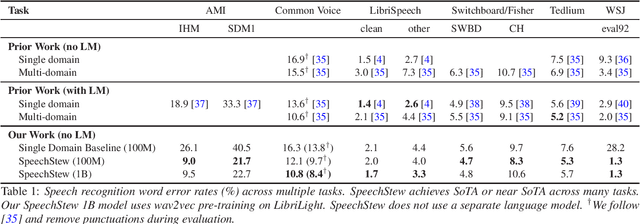
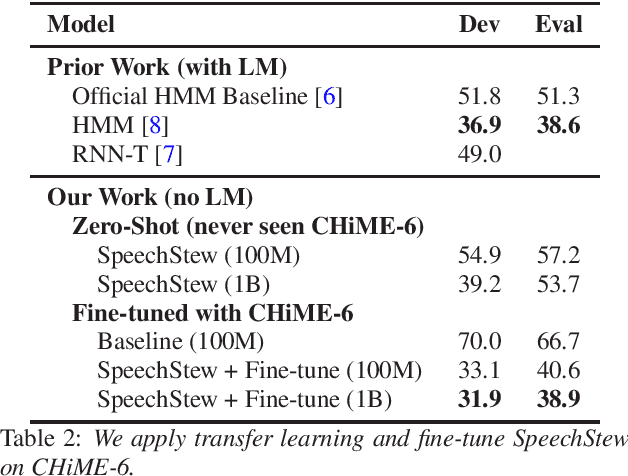
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
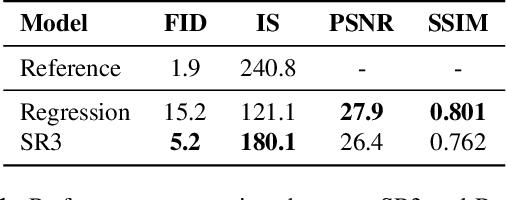
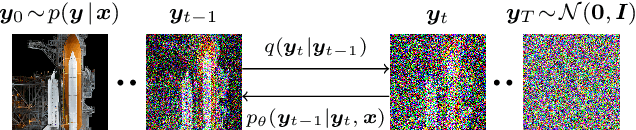

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021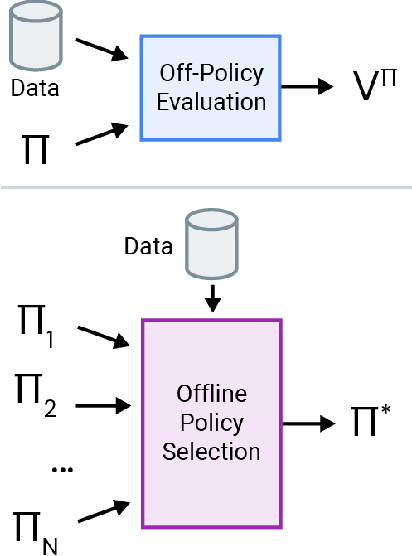
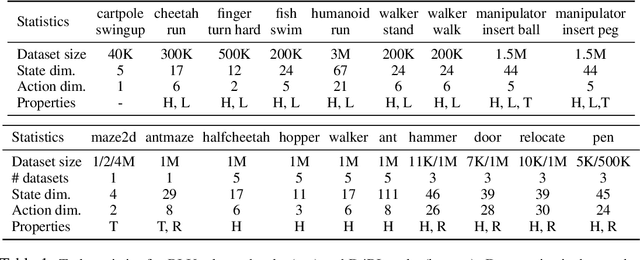
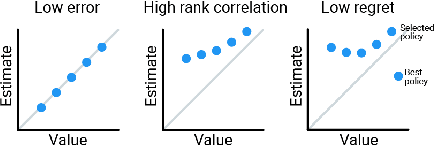
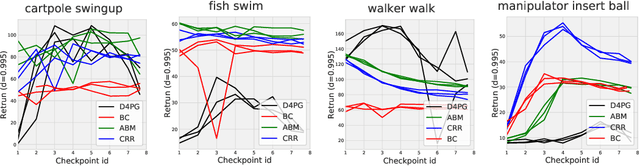
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Big Self-Supervised Models Advance Medical Image Classification
Jan 13, 2021
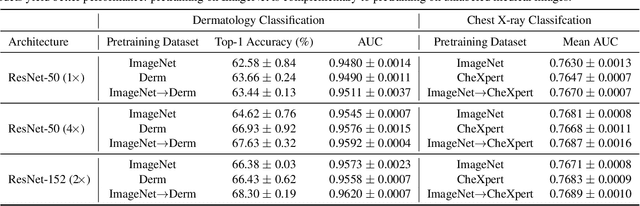
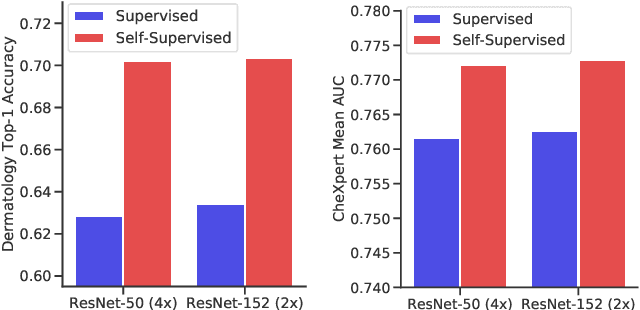
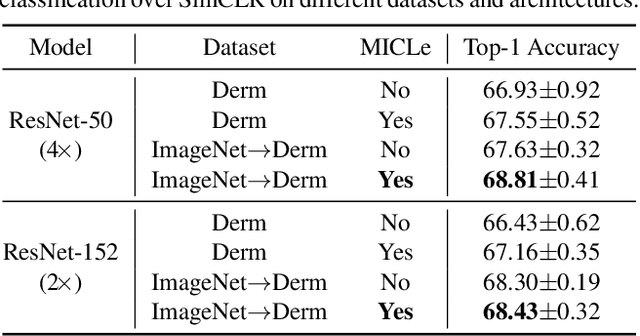
Self-supervised pretraining followed by supervised fine-tuning has seen success in image recognition, especially when labeled examples are scarce, but has received limited attention in medical image analysis. This paper studies the effectiveness of self-supervised learning as a pretraining strategy for medical image classification. We conduct experiments on two distinct tasks: dermatology skin condition classification from digital camera images and multi-label chest X-ray classification, and demonstrate that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images significantly improves the accuracy of medical image classifiers. We introduce a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case, when available, to construct more informative positive pairs for self-supervised learning. Combining our contributions, we achieve an improvement of 6.7% in top-1 accuracy and an improvement of 1.1% in mean AUC on dermatology and chest X-ray classification respectively, outperforming strong supervised baselines pretrained on ImageNet. In addition, we show that big self-supervised models are robust to distribution shift and can learn efficiently with a small number of labeled medical images.
What's in a Loss Function for Image Classification?
Oct 30, 2020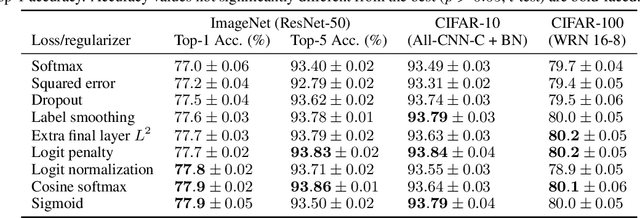
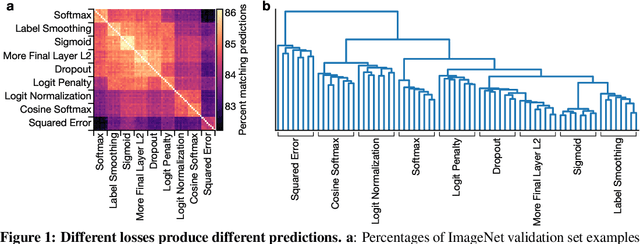
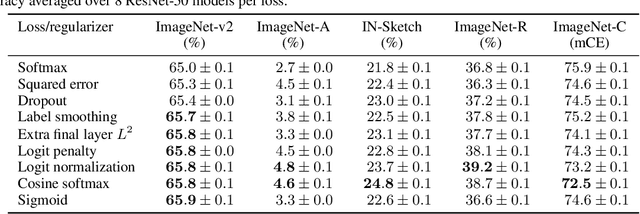
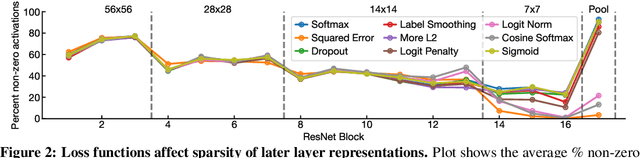
It is common to use the softmax cross-entropy loss to train neural networks on classification datasets where a single class label is assigned to each example. However, it has been shown that modifying softmax cross-entropy with label smoothing or regularizers such as dropout can lead to higher performance. This paper studies a variety of loss functions and output layer regularization strategies on image classification tasks. We observe meaningful differences in model predictions, accuracy, calibration, and out-of-distribution robustness for networks trained with different objectives. However, differences in hidden representations of networks trained with different objectives are restricted to the last few layers; representational similarity reveals no differences among network layers that are not close to the output. We show that all objectives that improve over vanilla softmax loss produce greater class separation in the penultimate layer of the network, which potentially accounts for improved performance on the original task, but results in features that transfer worse to other tasks.
No MCMC for me: Amortized sampling for fast and stable training of energy-based models
Oct 14, 2020
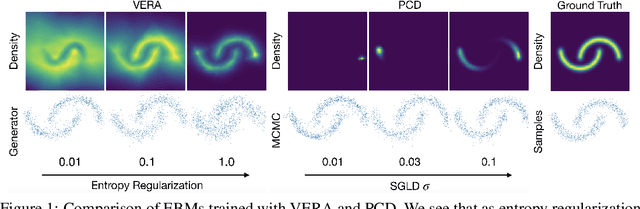


Energy-Based Models (EBMs) present a flexible and appealing way to represent uncertainty. Despite recent advances, training EBMs on high-dimensional data remains a challenging problem as the state-of-the-art approaches are costly, unstable, and require considerable tuning and domain expertise to apply successfully. In this work, we present a simple method for training EBMs at scale which uses an entropy-regularized generator to amortize the MCMC sampling typically used in EBM training. We improve upon prior MCMC-based entropy regularization methods with a fast variational approximation. We demonstrate the effectiveness of our approach by using it to train tractable likelihood models. Next, we apply our estimator to the recently proposed Joint Energy Model (JEM), where we match the original performance with faster and stable training. This allows us to extend JEM models to semi-supervised classification on tabular data from a variety of continuous domains.
Mastering Atari with Discrete World Models
Oct 05, 2020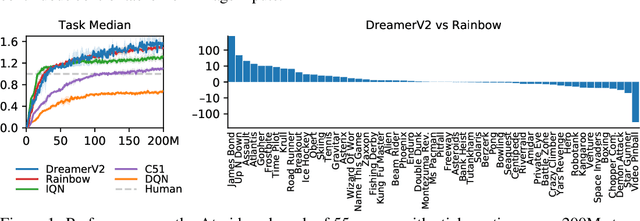
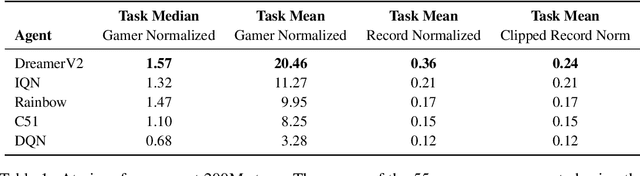
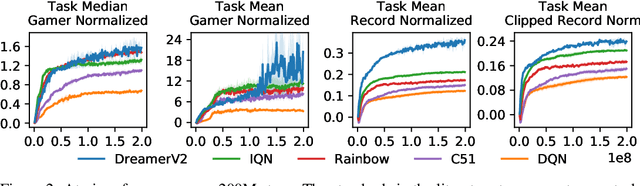

Intelligent agents need to generalize from past experience to achieve goals in complex environments. World models facilitate such generalization and allow learning behaviors from imagined outcomes to increase sample-efficiency. While learning world models from image inputs has recently become feasible for some tasks, modeling Atari games accurately enough to derive successful behaviors has remained an open challenge for many years. We introduce DreamerV2, a reinforcement learning agent that learns behaviors purely from predictions in the compact latent space of a powerful world model. The world model uses discrete representations and is trained separately from the policy. DreamerV2 constitutes the first agent that achieves human-level performance on the Atari benchmark of 55 tasks by learning behaviors inside a separately trained world model. With the same computational budget and wall-clock time, DreamerV2 reaches 200M frames and exceeds the final performance of the top single-GPU agents IQN and Rainbow.
WaveGrad: Estimating Gradients for Waveform Generation
Sep 02, 2020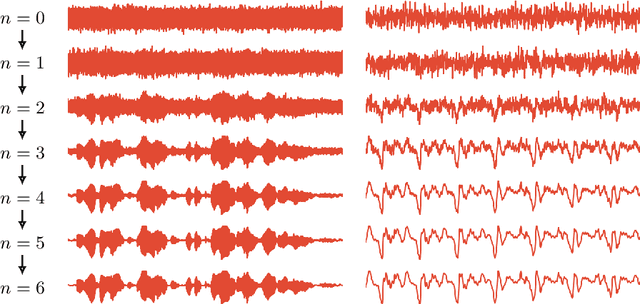
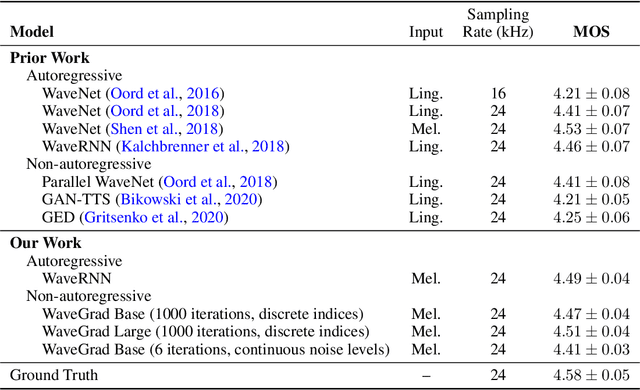
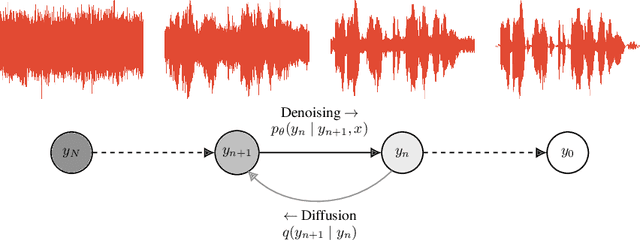

This paper introduces WaveGrad, a conditional model for waveform generation through estimating gradients of the data density. This model is built on the prior work on score matching and diffusion probabilistic models. It starts from Gaussian white noise and iteratively refines the signal via a gradient-based sampler conditioned on the mel-spectrogram. WaveGrad is non-autoregressive, and requires only a constant number of generation steps during inference. It can use as few as 6 iterations to generate high fidelity audio samples. WaveGrad is simple to train, and implicitly optimizes for the weighted variational lower-bound of the log-likelihood. Empirical experiments reveal WaveGrad to generate high fidelity audio samples matching a strong likelihood-based autoregressive baseline with less sequential operations.
RL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
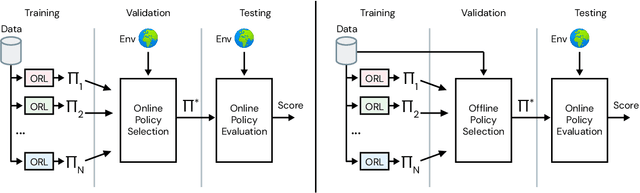
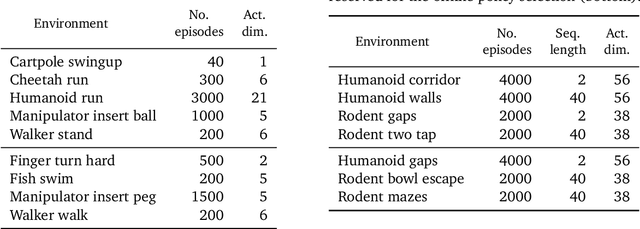
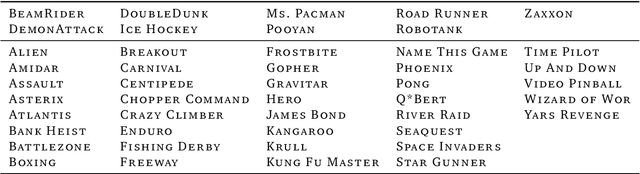
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Big Self-Supervised Models are Strong Semi-Supervised Learners
Jun 17, 2020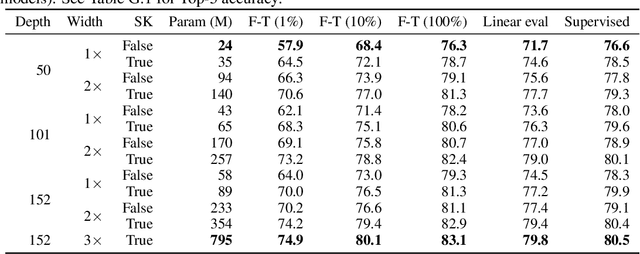
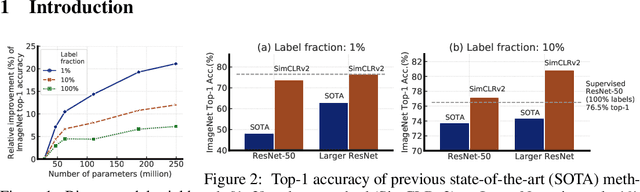
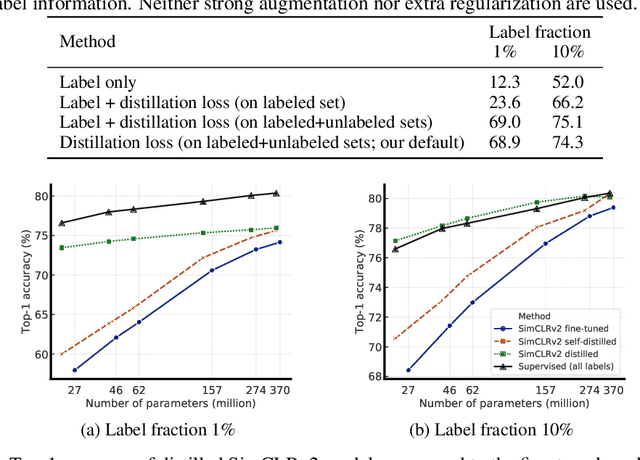
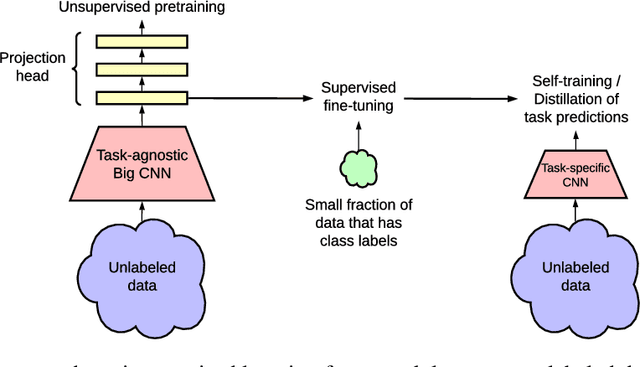
One paradigm for learning from few labeled examples while making best use of a large amount of unlabeled data is unsupervised pretraining followed by supervised fine-tuning. Although this paradigm uses unlabeled data in a task-agnostic way, in contrast to most previous approaches to semi-supervised learning for computer vision, we show that it is surprisingly effective for semi-supervised learning on ImageNet. A key ingredient of our approach is the use of a big (deep and wide) network during pretraining and fine-tuning. We find that, the fewer the labels, the more this approach (task-agnostic use of unlabeled data) benefits from a bigger network. After fine-tuning, the big network can be further improved and distilled into a much smaller one with little loss in classification accuracy by using the unlabeled examples for a second time, but in a task-specific way. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pretraining of a big ResNet model using SimCLRv2 (a modification of SimCLR), supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. This procedure achieves 73.9\% ImageNet top-1 accuracy with just 1\% of the labels ($\le$13 labeled images per class) using ResNet-50, a $10\times$ improvement in label efficiency over the previous state-of-the-art. With 10\% of labels, ResNet-50 trained with our method achieves 77.5\% top-1 accuracy, outperforming standard supervised training with all of the labels.