 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventHands: Real-Time Neural 3D Hand Reconstruction from an Event Stream
Dec 14, 2020
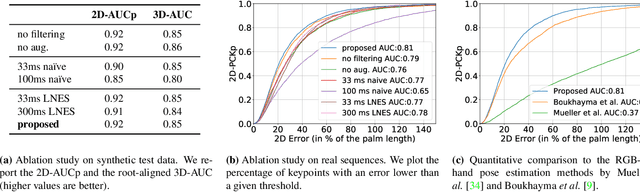


3D hand pose estimation from monocular videos is a long-standing and challenging problem, which is now seeing a strong upturn. In this work, we address it for the first time using a single event camera, i.e., an asynchronous vision sensor reacting on brightness changes. Our EventHands approach has characteristics previously not demonstrated with a single RGB or depth camera such as high temporal resolution at low data throughputs and real-time performance at 1000 Hz. Due to the different data modality of event cameras compared to classical cameras, existing methods cannot be directly applied to and re-trained for event streams. We thus design a new neural approach which accepts a new event stream representation suitable for learning, which is trained on newly-generated synthetic event streams and can generalise to real data. Experiments show that EventHands outperforms recent monocular methods using a colour (or depth) camera in terms of accuracy and its ability to capture hand motions of unprecedented speed. Our method, the event stream simulator and the dataset will be made publicly available.
i3DMM: Deep Implicit 3D Morphable Model of Human Heads
Nov 28, 2020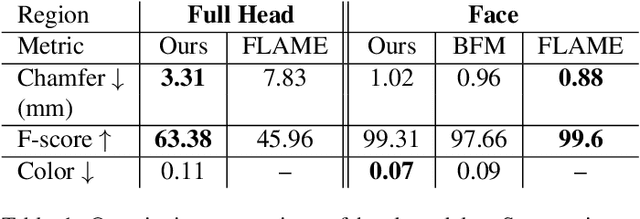


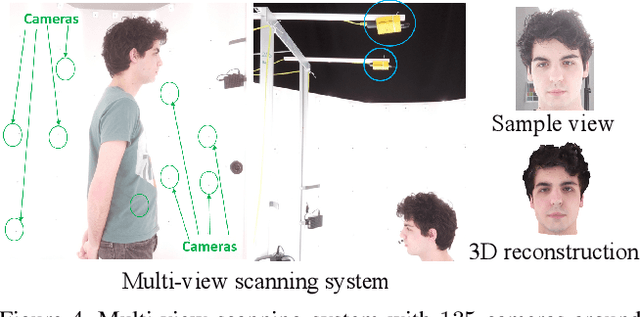
We present the first deep implicit 3D morphable model (i3DMM) of full heads. Unlike earlier morphable face models it not only captures identity-specific geometry, texture, and expressions of the frontal face, but also models the entire head, including hair. We collect a new dataset consisting of 64 people with different expressions and hairstyles to train i3DMM. Our approach has the following favorable properties: (i) It is the first full head morphable model that includes hair. (ii) In contrast to mesh-based models it can be trained on merely rigidly aligned scans, without requiring difficult non-rigid registration. (iii) We design a novel architecture to decouple the shape model into an implicit reference shape and a deformation of this reference shape. With that, dense correspondences between shapes can be learned implicitly. (iv) This architecture allows us to semantically disentangle the geometry and color components, as color is learned in the reference space. Geometry is further disentangled as identity, expressions, and hairstyle, while color is disentangled as identity and hairstyle components. We show the merits of i3DMM using ablation studies, comparisons to state-of-the-art models, and applications such as semantic head editing and texture transfer. We will make our model publicly available.
Learning Complete 3D Morphable Face Models from Images and Videos
Oct 04, 2020

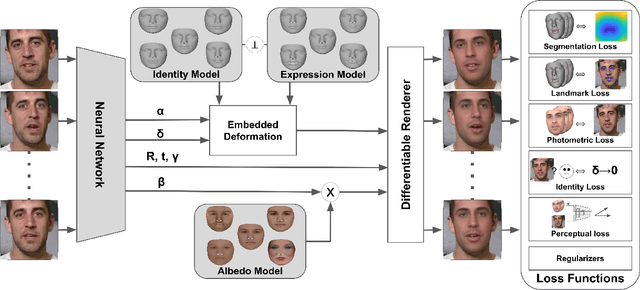

Most 3D face reconstruction methods rely on 3D morphable models, which disentangle the space of facial deformations into identity geometry, expressions and skin reflectance. These models are typically learned from a limited number of 3D scans and thus do not generalize well across different identities and expressions. We present the first approach to learn complete 3D models of face identity geometry, albedo and expression just from images and videos. The virtually endless collection of such data, in combination with our self-supervised learning-based approach allows for learning face models that generalize beyond the span of existing approaches. Our network design and loss functions ensure a disentangled parameterization of not only identity and albedo, but also, for the first time, an expression basis. Our method also allows for in-the-wild monocular reconstruction at test time. We show that our learned models better generalize and lead to higher quality image-based reconstructions than existing approaches.
PIE: Portrait Image Embedding for Semantic Control
Sep 20, 2020

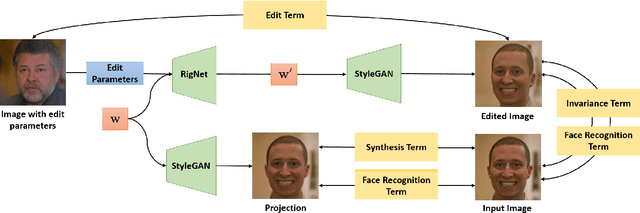

Editing of portrait images is a very popular and important research topic with a large variety of applications. For ease of use, control should be provided via a semantically meaningful parameterization that is akin to computer animation controls. The vast majority of existing techniques do not provide such intuitive and fine-grained control, or only enable coarse editing of a single isolated control parameter. Very recently, high-quality semantically controlled editing has been demonstrated, however only on synthetically created StyleGAN images. We present the first approach for embedding real portrait images in the latent space of StyleGAN, which allows for intuitive editing of the head pose, facial expression, and scene illumination in the image. Semantic editing in parameter space is achieved based on StyleRig, a pretrained neural network that maps the control space of a 3D morphable face model to the latent space of the GAN. We design a novel hierarchical non-linear optimization problem to obtain the embedding. An identity preservation energy term allows spatially coherent edits while maintaining facial integrity. Our approach runs at interactive frame rates and thus allows the user to explore the space of possible edits. We evaluate our approach on a wide set of portrait photos, compare it to the current state of the art, and validate the effectiveness of its components in an ablation study.
User-assisted Video Reflection Removal
Sep 07, 2020


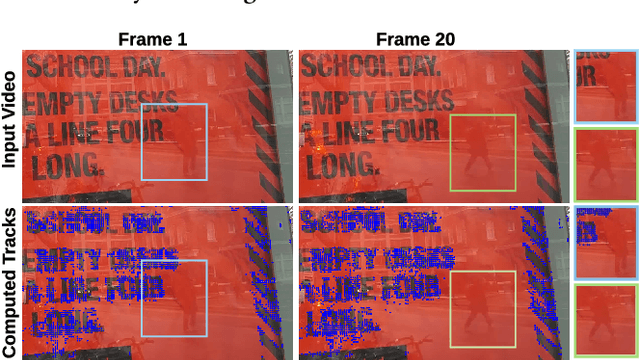
Reflections in videos are obstructions that often occur when videos are taken behind reflective surfaces like glass. These reflections reduce the quality of such videos, lead to information loss and degrade the accuracy of many computer vision algorithms. A video containing reflections is a combination of background and reflection layers. Thus, reflection removal is equivalent to decomposing the video into two layers. This, however, is a challenging and ill-posed problem as there is an infinite number of valid decompositions. To address this problem, we propose a user-assisted method for video reflection removal. We rely on both spatial and temporal information and utilize sparse user hints to help improve separation. The key idea of the proposed method is to use motion cues to separate the background layer from the reflection layer with minimal user assistance. We show that user-assistance significantly improves the layer separation results. We implement and evaluate the proposed method through quantitative and qualitative results on real and synthetic videos. Our experiments show that the proposed method successfully removes reflection from video sequences, does not introduce visual distortions, and significantly outperforms the state-of-the-art reflection removal methods in the literature.
Monocular Reconstruction of Neural Face Reflectance Fields
Aug 24, 2020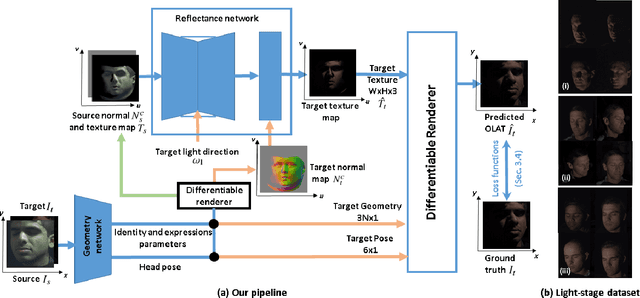
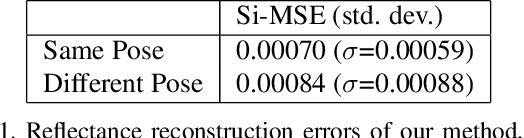


The reflectance field of a face describes the reflectance properties responsible for complex lighting effects including diffuse, specular, inter-reflection and self shadowing. Most existing methods for estimating the face reflectance from a monocular image assume faces to be diffuse with very few approaches adding a specular component. This still leaves out important perceptual aspects of reflectance as higher-order global illumination effects and self-shadowing are not modeled. We present a new neural representation for face reflectance where we can estimate all components of the reflectance responsible for the final appearance from a single monocular image. Instead of modeling each component of the reflectance separately using parametric models, our neural representation allows us to generate a basis set of faces in a geometric deformation-invariant space, parameterized by the input light direction, viewpoint and face geometry. We learn to reconstruct this reflectance field of a face just from a monocular image, which can be used to render the face from any viewpoint in any light condition. Our method is trained on a light-stage training dataset, which captures 300 people illuminated with 150 light conditions from 8 viewpoints. We show that our method outperforms existing monocular reflectance reconstruction methods, in terms of photorealism due to better capturing of physical premitives, such as sub-surface scattering, specularities, self-shadows and other higher-order effects.
VideoForensicsHQ: Detecting High-quality Manipulated Face Videos
May 20, 2020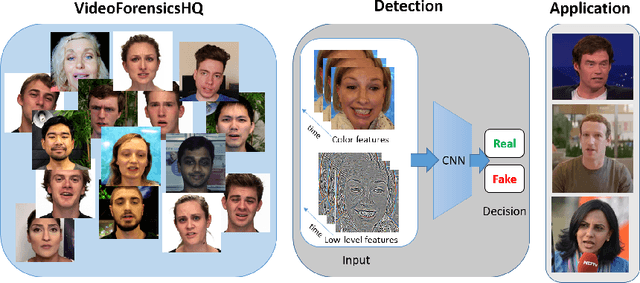

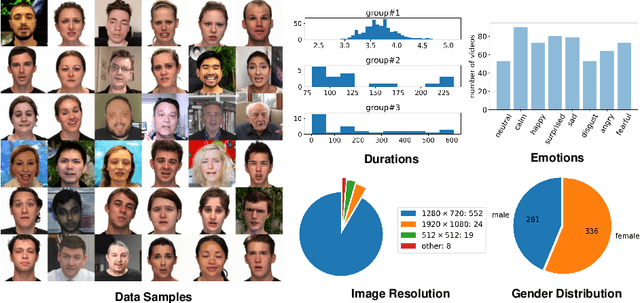
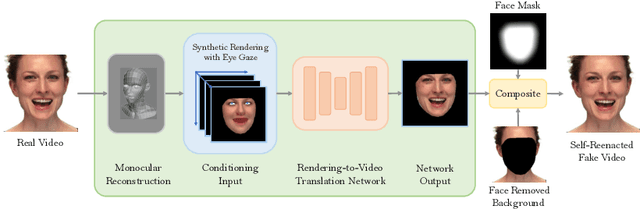
New approaches to synthesize and manipulate face videos at very high quality have paved the way for new applications in computer animation, virtual and augmented reality, or face video analysis. However, there are concerns that they may be used in a malicious way, e.g. to manipulate videos of public figures, politicians or reporters, to spread false information. The research community therefore developed techniques for automated detection of modified imagery, and assembled benchmark datasets showing manipulatons by state-of-the-art techniques. In this paper, we contribute to this initiative in two ways: First, we present a new audio-visual benchmark dataset. It shows some of the highest quality visual manipulations available today. Human observers find them significantly harder to identify as forged than videos from other benchmarks. Furthermore we propose new family of deep-learning-based fake detectors, demonstrating that existing detectors are not well-suited for detecting fakes of a quality as high as presented in our dataset. Our detectors examine spatial and temporal features. This allows them to outperform existing approaches both in terms of high detection accuracy and generalization to unseen fake generation methods and unseen identities.
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
Mar 31, 2020
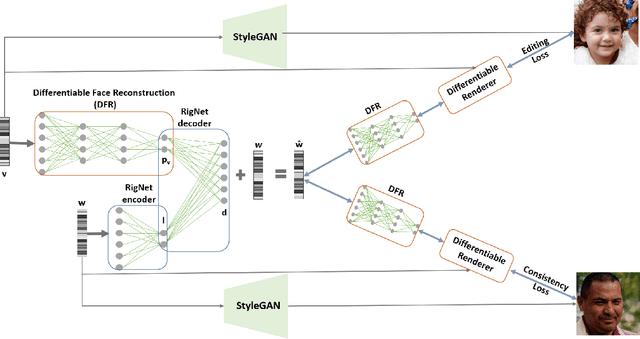
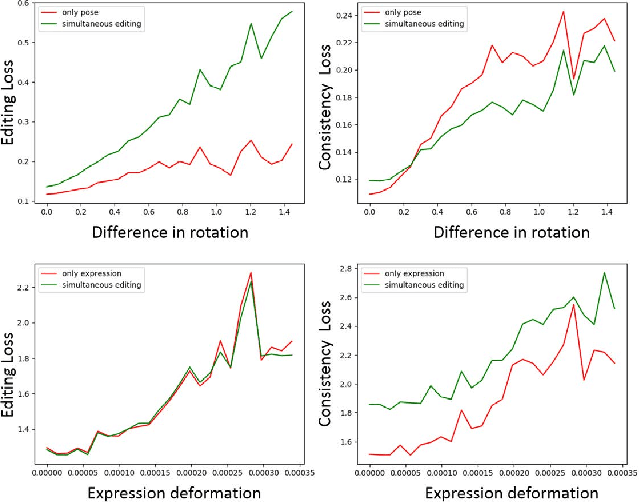

StyleGAN generates photorealistic portrait images of faces with eyes, teeth, hair and context (neck, shoulders, background), but lacks a rig-like control over semantic face parameters that are interpretable in 3D, such as face pose, expressions, and scene illumination. Three-dimensional morphable face models (3DMMs) on the other hand offer control over the semantic parameters, but lack photorealism when rendered and only model the face interior, not other parts of a portrait image (hair, mouth interior, background). We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. A new rigging network, RigNet is trained between the 3DMM's semantic parameters and StyleGAN's input. The network is trained in a self-supervised manner, without the need for manual annotations. At test time, our method generates portrait images with the photorealism of StyleGAN and provides explicit control over the 3D semantic parameters of the face.
Neural Voice Puppetry: Audio-driven Facial Reenactment
Dec 11, 2019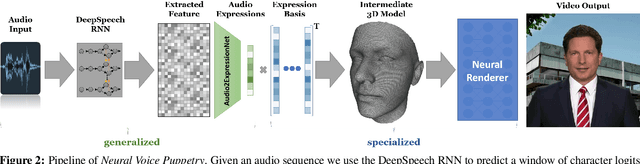
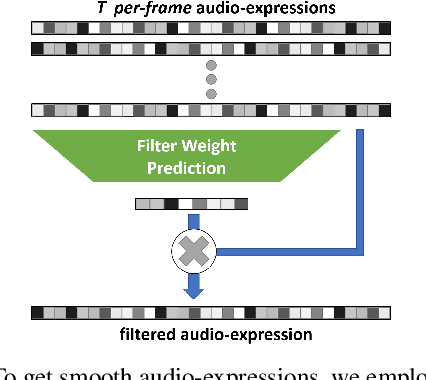

We present Neural Voice Puppetry, a novel approach for audio-driven facial video synthesis. Given an audio sequence of a source person or digital assistant, we generate a photo-realistic output video of a target person that is in sync with the audio of the source input. This audio-driven facial reenactment is driven by a deep neural network that employs a latent 3D face model space. Through the underlying 3D representation, the model inherently learns temporal stability while we leverage neural rendering to generate photo-realistic output frames. Our approach generalizes across different people, allowing us to synthesize videos of a target actor with the voice of any unknown source actor or even synthetic voices that can be generated utilizing standard text-to-speech approaches. Neural Voice Puppetry has a variety of use-cases, including audio-driven video avatars, video dubbing, and text-driven video synthesis of a talking head. We demonstrate the capabilities of our method in a series of audio- and text-based puppetry examples. Our method is not only more general than existing works since we are generic to the input person, but we also show superior visual and lip sync quality compared to photo-realistic audio- and video-driven reenactment techniques.
Neural Style-Preserving Visual Dubbing
Sep 06, 2019
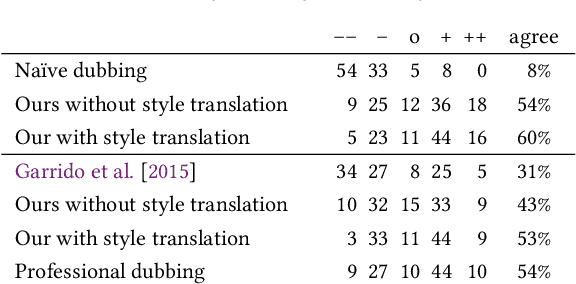
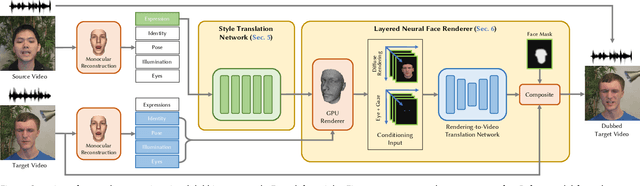
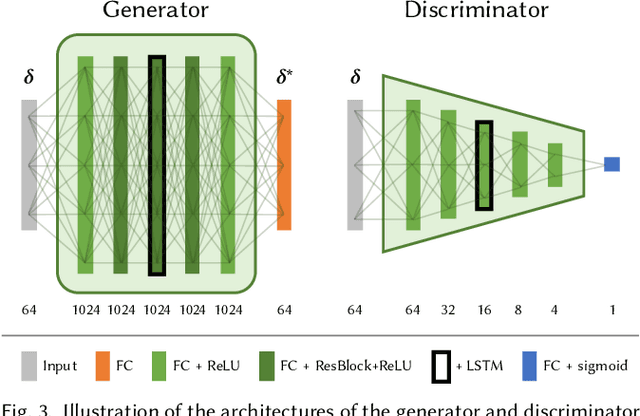
Dubbing is a technique for translating video content from one language to another. However, state-of-the-art visual dubbing techniques directly copy facial expressions from source to target actors without considering identity-specific idiosyncrasies such as a unique type of smile. We present a style-preserving visual dubbing approach from single video inputs, which maintains the signature style of target actors when modifying facial expressions, including mouth motions, to match foreign languages. At the heart of our approach is the concept of motion style, in particular for facial expressions, i.e., the person-specific expression change that is yet another essential factor beyond visual accuracy in face editing applications. Our method is based on a recurrent generative adversarial network that captures the spatiotemporal co-activation of facial expressions, and enables generating and modifying the facial expressions of the target actor while preserving their style. We train our model with unsynchronized source and target videos in an unsupervised manner using cycle-consistency and mouth expression losses, and synthesize photorealistic video frames using a layered neural face renderer. Our approach generates temporally coherent results, and handles dynamic backgrounds. Our results show that our dubbing approach maintains the idiosyncratic style of the target actor better than previous approaches, even for widely differing source and target actors.