 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hallucination to Articulation: Language Model-Driven Losses for Ultra Low-Bitrate Neural Speech Coding
Feb 05, 2026``Phoneme Hallucinations (PH)'' commonly occur in low-bitrate DNN-based codecs. It is the generative decoder's attempt to synthesize plausible outputs from excessively compressed tokens missing some semantic information. In this work, we propose language model-driven losses (LM loss) and show they may alleviate PHs better than a semantic distillation (SD) objective in very-low-bitrate settings. The proposed LM losses build upon language models pretrained to associate speech with text. When ground-truth transcripts are unavailable, we propose to modify a popular automatic speech recognition (ASR) model, Whisper, to compare the decoded utterance against the ASR-inferred transcriptions of the input speech. Else, we propose to use the timed-text regularizer (TTR) to compare WavLM representations of the decoded utterance against BERT representations of the ground-truth transcriptions. We test and compare LM losses against an SD objective, using a reference codec whose three-stage training regimen was designed after several popular codecs. Subjective and objective evaluations conclude that LM losses may provide stronger guidance to extract semantic information from self-supervised speech representations, boosting human-perceived semantic adherence while preserving overall output quality. Demo samples, code, and checkpoints are available online.
Semantics-Aware Generative Latent Data Augmentation for Learning in Low-Resource Domains
Feb 02, 2026Despite strong performance in data-rich regimes, deep learning often underperforms in the data-scarce settings common in practice. While foundation models (FMs) trained on massive datasets demonstrate strong generalization by extracting general-purpose features, they can still suffer from scarce labeled data during downstream fine-tuning. To address this, we propose GeLDA, a semantics-aware generative latent data augmentation framework that leverages conditional diffusion models to synthesize samples in an FM-induced latent space. Because this space is low-dimensional and concentrates task-relevant information compared to the input space, GeLDA enables efficient, high-quality data generation. GeLDA conditions generation on auxiliary feature vectors that capture semantic relationships among classes or subdomains, facilitating data augmentation in low-resource domains. We validate GeLDA in two large-scale recognition tasks: (a) in zero-shot language-specific speech emotion recognition, GeLDA improves the Whisper-large baseline's unweighted average recall by 6.13%; and (b) in long-tailed image classification, it achieves 74.7% tail-class accuracy on ImageNet-LT, setting a new state-of-the-art result.
PromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
User-guided Generative Source Separation
Jul 02, 2025



Music source separation (MSS) aims to extract individual instrument sources from their mixture. While most existing methods focus on the widely adopted four-stem separation setup (vocals, bass, drums, and other instruments), this approach lacks the flexibility needed for real-world applications. To address this, we propose GuideSep, a diffusion-based MSS model capable of instrument-agnostic separation beyond the four-stem setup. GuideSep is conditioned on multiple inputs: a waveform mimicry condition, which can be easily provided by humming or playing the target melody, and mel-spectrogram domain masks, which offer additional guidance for separation. Unlike prior approaches that relied on fixed class labels or sound queries, our conditioning scheme, coupled with the generative approach, provides greater flexibility and applicability. Additionally, we design a mask-prediction baseline using the same model architecture to systematically compare predictive and generative approaches. Our objective and subjective evaluations demonstrate that GuideSep achieves high-quality separation while enabling more versatile instrument extraction, highlighting the potential of user participation in the diffusion-based generative process for MSS. Our code and demo page are available at https://yutongwen.github.io/GuideSep/
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Perceptual Audio Coding: A 40-Year Historical Perspective
Apr 22, 2025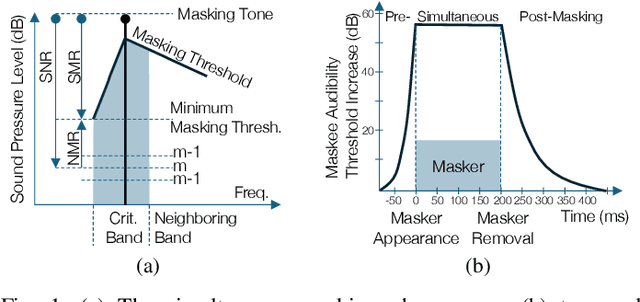
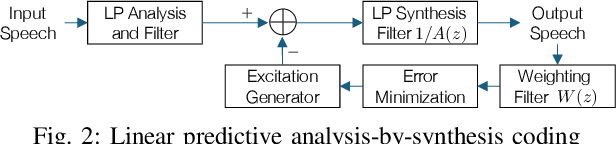
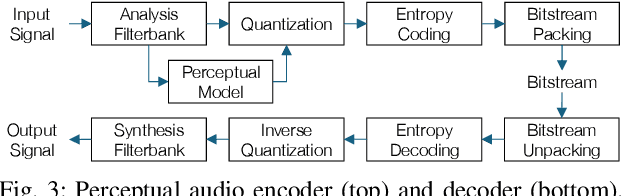
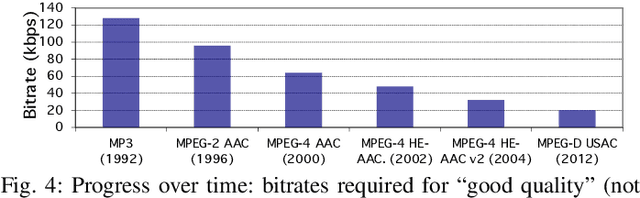
In the history of audio and acoustic signal processing, perceptual audio coding has certainly excelled as a bright success story by its ubiquitous deployment in virtually all digital media devices, such as computers, tablets, mobile phones, set-top-boxes, and digital radios. From a technology perspective, perceptual audio coding has undergone tremendous development from the first very basic perceptually driven coders (including the popular mp3 format) to today's full-blown integrated coding/rendering systems. This paper provides a historical overview of this research journey by pinpointing the pivotal development steps in the evolution of perceptual audio coding. Finally, it provides thoughts about future directions in this area.
DTA: Dual Temporal-channel-wise Attention for Spiking Neural Networks
Mar 13, 2025Spiking Neural Networks (SNNs) present a more energy-efficient alternative to Artificial Neural Networks (ANNs) by harnessing spatio-temporal dynamics and event-driven spikes. Effective utilization of temporal information is crucial for SNNs, leading to the exploration of attention mechanisms to enhance this capability. Conventional attention operations either apply identical operation or employ non-identical operations across target dimensions. We identify that these approaches provide distinct perspectives on temporal information. To leverage the strengths of both operations, we propose a novel Dual Temporal-channel-wise Attention (DTA) mechanism that integrates both identical/non-identical attention strategies. To the best of our knowledge, this is the first attempt to concentrate on both the correlation and dependency of temporal-channel using both identical and non-identical attention operations. Experimental results demonstrate that the DTA mechanism achieves state-of-the-art performance on both static datasets (CIFAR10, CIFAR100, ImageNet-1k) and dynamic dataset (CIFAR10-DVS), elevating spike representation and capturing complex temporal-channel relationship. We open-source our code: https://github.com/MnJnKIM/DTA-SNN.
A Benchmark Dataset for Collaborative SLAM in Service Environments
Nov 22, 2024



As service environments have become diverse, they have started to demand complicated tasks that are difficult for a single robot to complete. This change has led to an interest in multiple robots instead of a single robot. C-SLAM, as a fundamental technique for multiple service robots, needs to handle diverse challenges such as homogeneous scenes and dynamic objects to ensure that robots operate smoothly and perform their tasks safely. However, existing C-SLAM datasets do not include the various indoor service environments with the aforementioned challenges. To close this gap, we introduce a new multi-modal C-SLAM dataset for multiple service robots in various indoor service environments, called C-SLAM dataset in Service Environments (CSE). We use the NVIDIA Isaac Sim to generate data in various indoor service environments with the challenges that may occur in real-world service environments. By using simulation, we can provide accurate and precisely time-synchronized sensor data, such as stereo RGB, stereo depth, IMU, and ground truth (GT) poses. We configure three common indoor service environments (Hospital, Office, and Warehouse), each of which includes various dynamic objects that perform motions suitable to each environment. In addition, we drive three robots to mimic the actions of real service robots. Through these factors, we generate a more realistic C-SLAM dataset for multiple service robots. We demonstrate our dataset by evaluating diverse state-of-the-art single-robot SLAM and multi-robot SLAM methods. Our dataset is available at https://github.com/vision3d-lab/CSE_Dataset.
* 8 pages, 6 figures, Accepted to IEEE RA-L
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024



Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.
Machine Learning-based Channel Prediction in Wideband Massive MIMO Systems with Small Overhead for Online Training
Aug 22, 2024



Channel prediction compensates for outdated channel state information in multiple-input multiple-output (MIMO) systems. Machine learning (ML) techniques have recently been implemented to design channel predictors by leveraging the temporal correlation of wireless channels. However, most ML-based channel prediction techniques have only considered offline training when generating channel predictors, which can result in poor performance when encountering channel environments different from the ones they were trained on. To ensure prediction performance in varying channel conditions, we propose an online re-training framework that trains the channel predictor from scratch to effectively capture and respond to changes in the wireless environment. The training time includes data collection time and neural network training time, and should be minimized for practical channel predictors. To reduce the training time, especially data collection time, we propose a novel ML-based channel prediction technique called aggregated learning (AL) approach for wideband massive MIMO systems. In the proposed AL approach, the training data can be split and aggregated either in an array domain or frequency domain, which are the channel domains of MIMO-OFDM systems. This processing can significantly reduce the time for data collection. Our numerical results show that the AL approach even improves channel prediction performance in various scenarios with small training time overhead.