 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Aware Generative Latent Data Augmentation for Learning in Low-Resource Domains
Feb 02, 2026Despite strong performance in data-rich regimes, deep learning often underperforms in the data-scarce settings common in practice. While foundation models (FMs) trained on massive datasets demonstrate strong generalization by extracting general-purpose features, they can still suffer from scarce labeled data during downstream fine-tuning. To address this, we propose GeLDA, a semantics-aware generative latent data augmentation framework that leverages conditional diffusion models to synthesize samples in an FM-induced latent space. Because this space is low-dimensional and concentrates task-relevant information compared to the input space, GeLDA enables efficient, high-quality data generation. GeLDA conditions generation on auxiliary feature vectors that capture semantic relationships among classes or subdomains, facilitating data augmentation in low-resource domains. We validate GeLDA in two large-scale recognition tasks: (a) in zero-shot language-specific speech emotion recognition, GeLDA improves the Whisper-large baseline's unweighted average recall by 6.13%; and (b) in long-tailed image classification, it achieves 74.7% tail-class accuracy on ImageNet-LT, setting a new state-of-the-art result.
Latent Filling: Latent Space Data Augmentation for Zero-shot Speech Synthesis
Oct 05, 2023Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd-sourcing or augmenting existing speech data. However, the use of low-quality data has led to a decline in the overall system performance. To avoid such degradation, instead of directly augmenting the input data, we propose a latent filling (LF) method that adopts simple but effective latent space data augmentation in the speaker embedding space of the ZS-TTS system. By incorporating a consistency loss, LF can be seamlessly integrated into existing ZS-TTS systems without the need for additional training stages. Experimental results show that LF significantly improves speaker similarity while preserving speech quality.
An Empirical Study on L2 Accents of Cross-lingual Text-to-Speech Systems via Vowel Space
Nov 06, 2022With the recent developments in cross-lingual Text-to-Speech (TTS) systems, L2 (second-language, or foreign) accent problems arise. Moreover, running a subjective evaluation for such cross-lingual TTS systems is troublesome. The vowel space analysis, which is often utilized to explore various aspects of language including L2 accents, is a great alternative analysis tool. In this study, we apply the vowel space analysis method to explore L2 accents of cross-lingual TTS systems. Through the vowel space analysis, we observe the three followings: a) a parallel architecture (Glow-TTS) is less L2-accented than an auto-regressive one (Tacotron); b) L2 accents are more dominant in non-shared vowels in a language pair; and c) L2 accents of cross-lingual TTS systems share some phenomena with those of human L2 learners. Our findings imply that it is necessary for TTS systems to handle each language pair differently, depending on their linguistic characteristics such as non-shared vowels. They also hint that we can further incorporate linguistics knowledge in developing cross-lingual TTS systems.
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Jun 28, 2022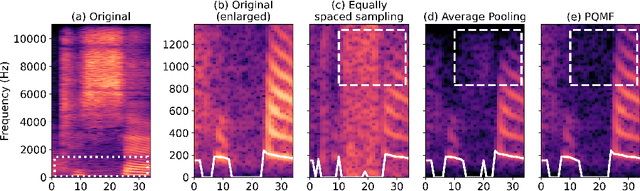
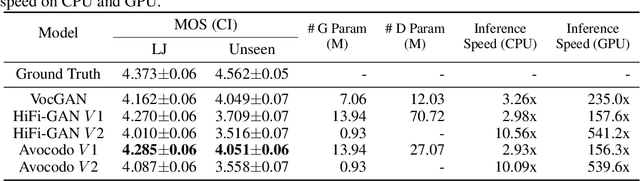
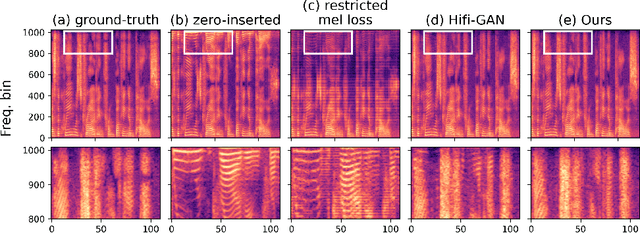
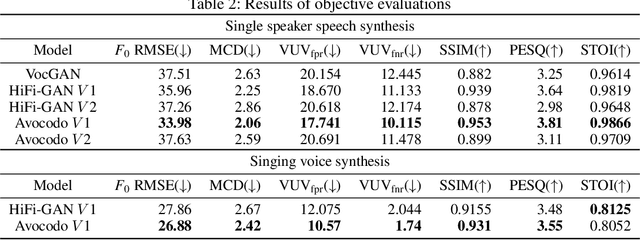
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.
Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
Apr 08, 2022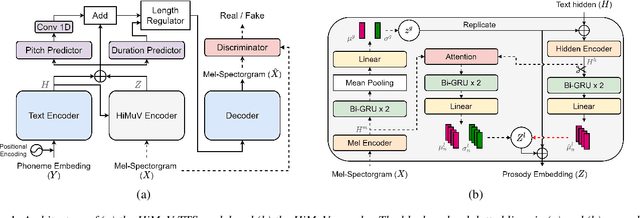
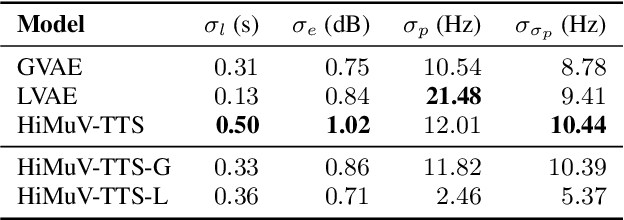
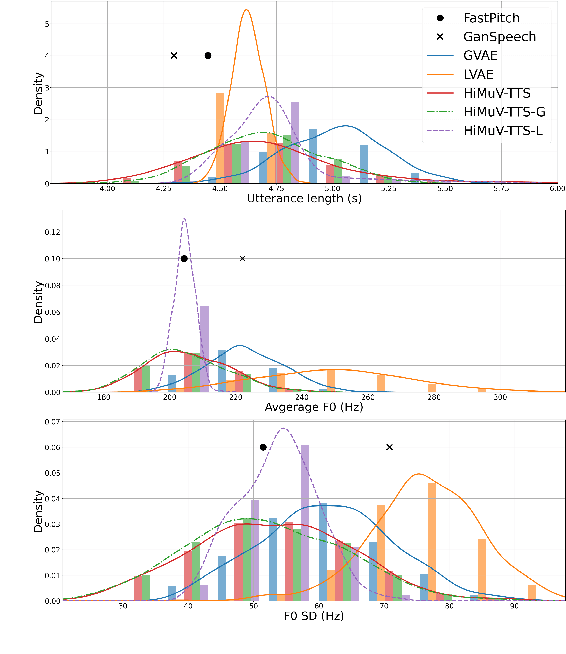
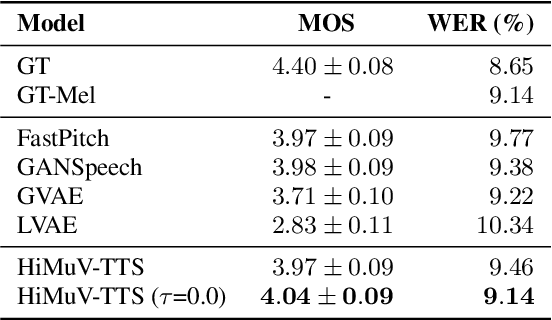
This paper proposes a hierarchical and multi-scale variational autoencoder-based non-autoregressive text-to-speech model (HiMuV-TTS) to generate natural speech with diverse speaking styles. Recent advances in non-autoregressive TTS (NAR-TTS) models have significantly improved the inference speed and robustness of synthesized speech. However, the diversity of speaking styles and naturalness are needed to be improved. To solve this problem, we propose the HiMuV-TTS model that first determines the global-scale prosody and then determines the local-scale prosody via conditioning on the global-scale prosody and the learned text representation. In addition, we improve the quality of speech by adopting the adversarial training technique. Experimental results verify that the proposed HiMuV-TTS model can generate more diverse and natural speech as compared to TTS models with single-scale variational autoencoders, and can represent different prosody information in each scale.
GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
Jun 29, 2021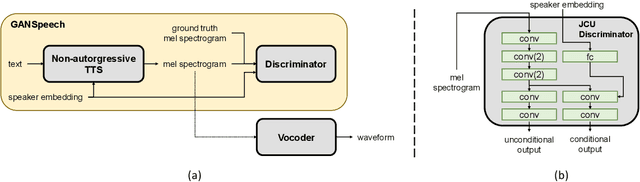


Recent advances in neural multi-speaker text-to-speech (TTS) models have enabled the generation of reasonably good speech quality with a single model and made it possible to synthesize the speech of a speaker with limited training data. Fine-tuning to the target speaker data with the multi-speaker model can achieve better quality, however, there still exists a gap compared to the real speech sample and the model depends on the speaker. In this work, we propose GANSpeech, which is a high-fidelity multi-speaker TTS model that adopts the adversarial training method to a non-autoregressive multi-speaker TTS model. In addition, we propose simple but efficient automatic scaling methods for feature matching loss used in adversarial training. In the subjective listening tests, GANSpeech significantly outperformed the baseline multi-speaker FastSpeech and FastSpeech2 models, and showed a better MOS score than the speaker-specific fine-tuned FastSpeech2.
Hierarchical Context-Aware Transformers for Non-Autoregressive Text to Speech
Jun 29, 2021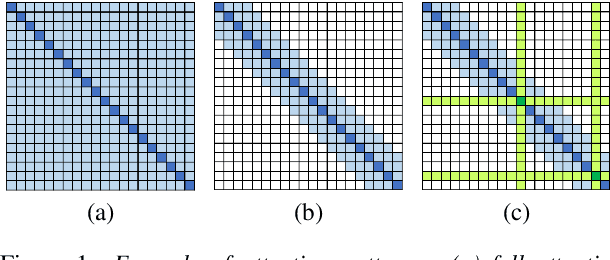
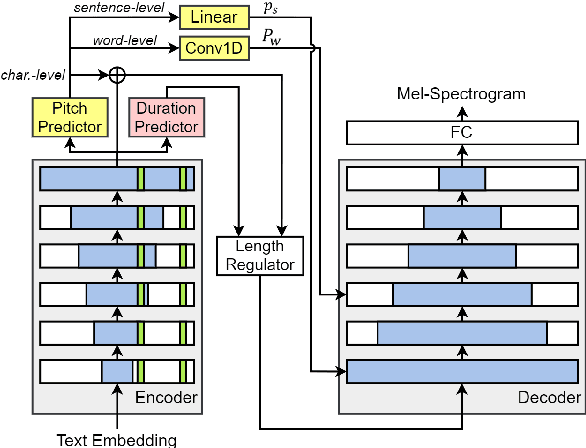
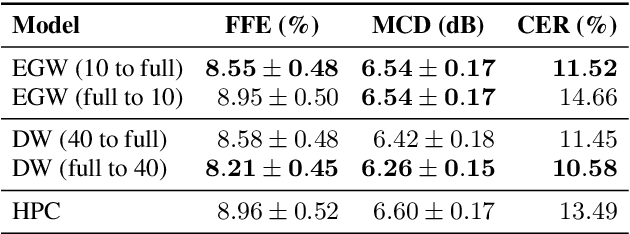
In this paper, we propose methods for improving the modeling performance of a Transformer-based non-autoregressive text-to-speech (TNA-TTS) model. Although the text encoder and audio decoder handle different types and lengths of data (i.e., text and audio), the TNA-TTS models are not designed considering these variations. Therefore, to improve the modeling performance of the TNA-TTS model we propose a hierarchical Transformer structure-based text encoder and audio decoder that are designed to accommodate the characteristics of each module. For the text encoder, we constrain each self-attention layer so the encoder focuses on a text sequence from the local to the global scope. Conversely, the audio decoder constrains its self-attention layers to focus in the reverse direction, i.e., from global to local scope. Additionally, we further improve the pitch modeling accuracy of the audio decoder by providing sentence and word-level pitch as conditions. Various objective and subjective evaluations verified that the proposed method outperformed the baseline TNA-TTS.
FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
Jun 29, 2021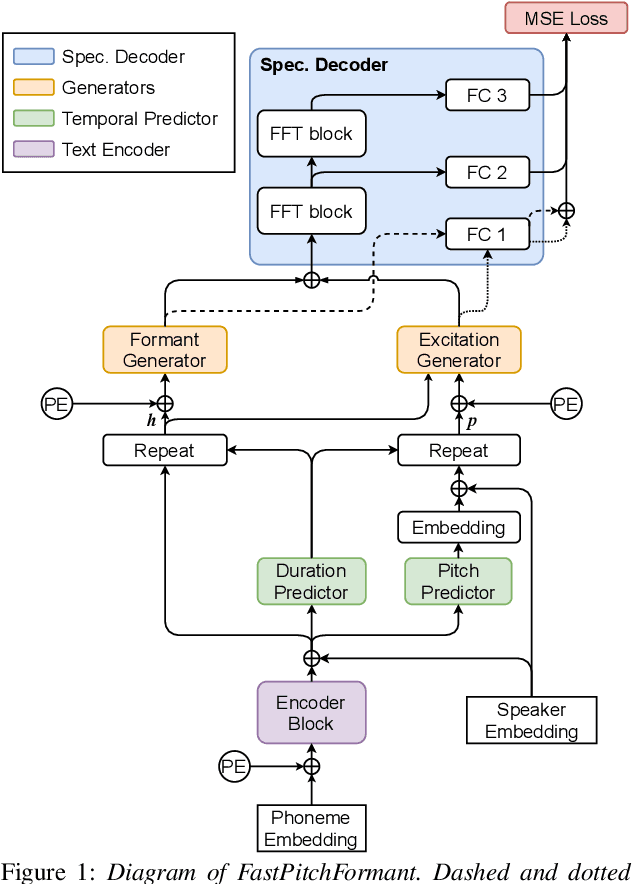
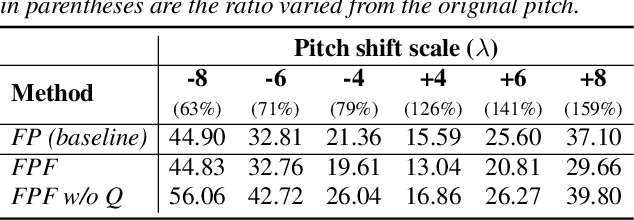
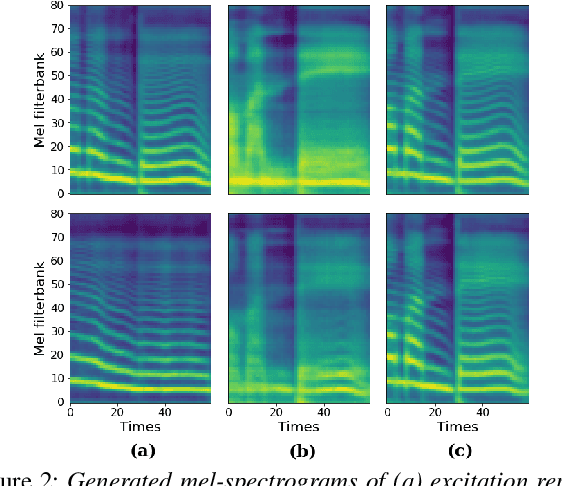
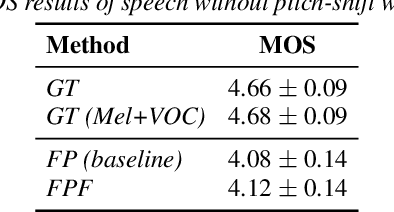
Methods for modeling and controlling prosody with acoustic features have been proposed for neural text-to-speech (TTS) models. Prosodic speech can be generated by conditioning acoustic features. However, synthesized speech with a large pitch-shift scale suffers from audio quality degradation, and speaker characteristics deformation. To address this problem, we propose a feed-forward Transformer based TTS model that is designed based on the source-filter theory. This model, called FastPitchFormant, has a unique structure that handles text and acoustic features in parallel. With modeling each feature separately, the tendency that the model learns the relationship between two features can be mitigated.
A Neural Text-to-Speech Model Utilizing Broadcast Data Mixed with Background Music
Mar 04, 2021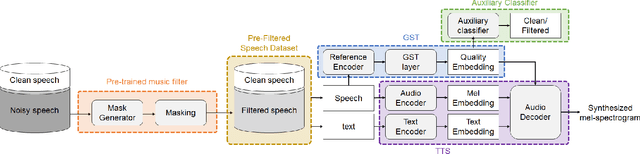
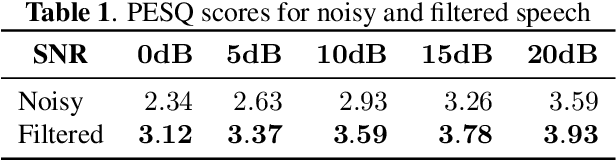
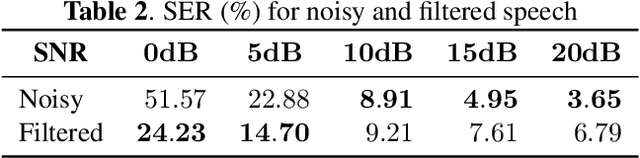
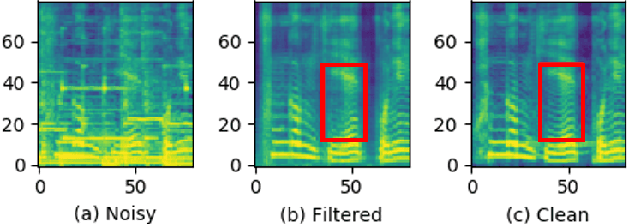
Recently, it has become easier to obtain speech data from various media such as the internet or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult. The proportion of clean speech is insufficient and the remainder includes background music. Even with the global style token (GST). Therefore, we propose the following method to successfully train an end-to-end TTS model with limited broadcast data. First, the background music is removed from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality classifier is trained with the filtered speech and a small amount of clean speech. In particular, the quality classifier makes the embedding vector of the GST layer focus on representing the speech quality (filtered or clean) of the input speech. The experimental results verified that the proposed method synthesized much more high-quality speech than conventional methods.