 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-Token Aligned Bayesian Prompt Learning for Vision-Language Models
Mar 16, 2023For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt learning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize prompt learning with the visual knowledge and view images and the corresponding prompts as patch and token sets under optimal transport, which pushes the prompt tokens to faithfully capture the label-specific visual concepts, instead of overfitting the training categories. Moreover, the proposed model can also be straightforwardly extended to the conditional case where the instance-conditional prompts are generated to improve the generalizability. Extensive experiments on 15 datasets show promising transferability and generalization performance of our proposed model.
Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-oriented Dialogue Systems
Feb 20, 2023When learning task-oriented dialogue (ToD) agents, reinforcement learning (RL) techniques can naturally be utilized to train dialogue strategies to achieve user-specific goals. Prior works mainly focus on adopting advanced RL techniques to train the ToD agents, while the design of the reward function is not well studied. This paper aims at answering the question of how to efficiently learn and leverage a reward function for training end-to-end (E2E) ToD agents. Specifically, we introduce two generalized objectives for reward-function learning, inspired by the classical learning-to-rank literature. Further, we utilize the learned reward function to guide the training of the E2E ToD agent. With the proposed techniques, we achieve competitive results on the E2E response-generation task on the Multiwoz 2.0 dataset. Source code and checkpoints are publicly released at https://github.com/Shentao-YANG/Fantastic_Reward_ICLR2023.
A Prototype-Oriented Clustering for Domain Shift with Source Privacy
Feb 09, 2023Unsupervised clustering under domain shift (UCDS) studies how to transfer the knowledge from abundant unlabeled data from multiple source domains to learn the representation of the unlabeled data in a target domain. In this paper, we introduce Prototype-oriented Clustering with Distillation (PCD) to not only improve the performance and applicability of existing methods for UCDS, but also address the concerns on protecting the privacy of both the data and model of the source domains. PCD first constructs a source clustering model by aligning the distributions of prototypes and data. It then distills the knowledge to the target model through cluster labels provided by the source model while simultaneously clustering the target data. Finally, it refines the target model on the target domain data without guidance from the source model. Experiments across multiple benchmarks show the effectiveness and generalizability of our source-private clustering method.
Generative-Contrastive Learning for Self-Supervised Latent Representations of 3D Shapes from Multi-Modal Euclidean Input
Jan 11, 2023


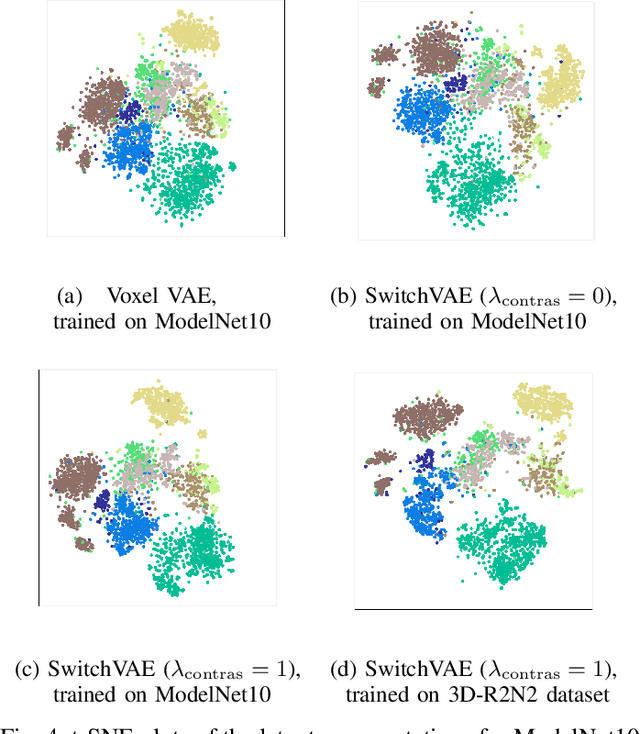
We propose a combined generative and contrastive neural architecture for learning latent representations of 3D volumetric shapes. The architecture uses two encoder branches for voxel grids and multi-view images from the same underlying shape. The main idea is to combine a contrastive loss between the resulting latent representations with an additional reconstruction loss. That helps to avoid collapsing the latent representations as a trivial solution for minimizing the contrastive loss. A novel switching scheme is used to cross-train two encoders with a shared decoder. The switching scheme also enables the stop gradient operation on a random branch. Further classification experiments show that the latent representations learned with our self-supervised method integrate more useful information from the additional input data implicitly, thus leading to better reconstruction and classification performance.
HyperMiner: Topic Taxonomy Mining with Hyperbolic Embedding
Oct 16, 2022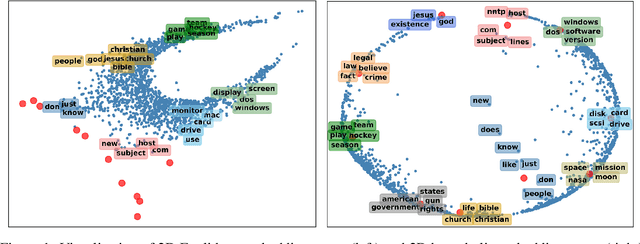
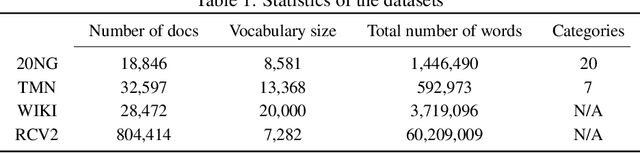
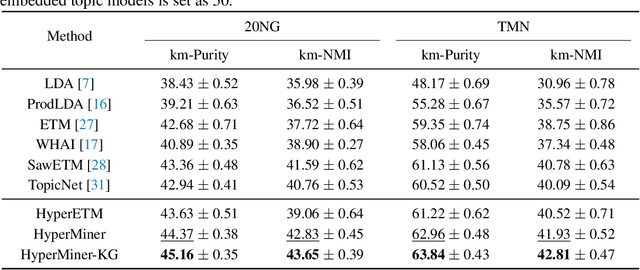
Embedded topic models are able to learn interpretable topics even with large and heavy-tailed vocabularies. However, they generally hold the Euclidean embedding space assumption, leading to a basic limitation in capturing hierarchical relations. To this end, we present a novel framework that introduces hyperbolic embeddings to represent words and topics. With the tree-likeness property of hyperbolic space, the underlying semantic hierarchy among words and topics can be better exploited to mine more interpretable topics. Furthermore, due to the superiority of hyperbolic geometry in representing hierarchical data, tree-structure knowledge can also be naturally injected to guide the learning of a topic hierarchy. Therefore, we further develop a regularization term based on the idea of contrastive learning to inject prior structural knowledge efficiently. Experiments on both topic taxonomy discovery and document representation demonstrate that the proposed framework achieves improved performance against existing embedded topic models.
A Unified Framework for Alternating Offline Model Training and Policy Learning
Oct 12, 2022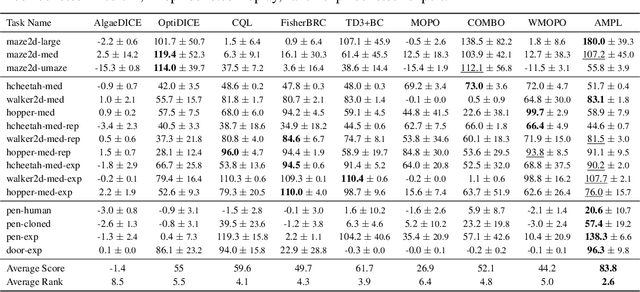
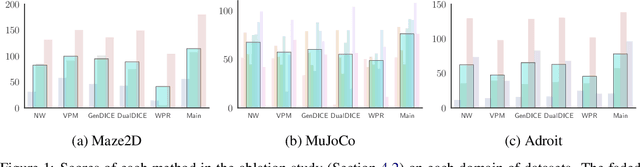
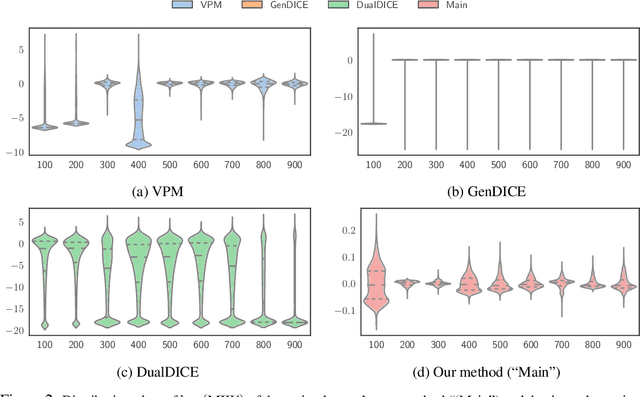
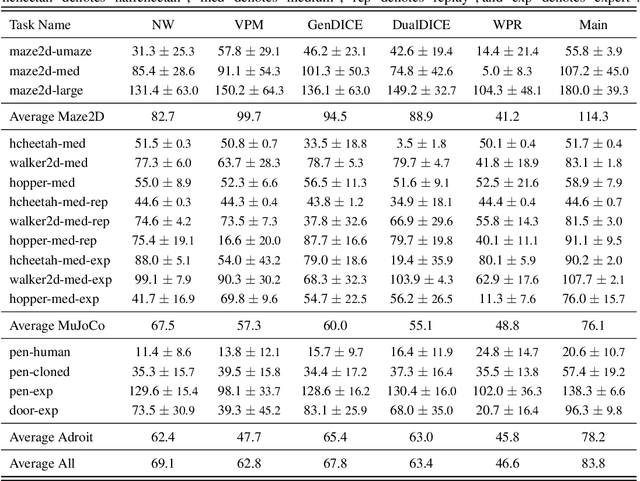
In offline model-based reinforcement learning (offline MBRL), we learn a dynamic model from historically collected data, and subsequently utilize the learned model and fixed datasets for policy learning, without further interacting with the environment. Offline MBRL algorithms can improve the efficiency and stability of policy learning over the model-free algorithms. However, in most of the existing offline MBRL algorithms, the learning objectives for the dynamic models and the policies are isolated from each other. Such an objective mismatch may lead to inferior performance of the learned agents. In this paper, we address this issue by developing an iterative offline MBRL framework, where we maximize a lower bound of the true expected return, by alternating between dynamic-model training and policy learning. With the proposed unified model-policy learning framework, we achieve competitive performance on a wide range of continuous-control offline reinforcement learning datasets. Source code is publicly released.
Adaptive Distribution Calibration for Few-Shot Learning with Hierarchical Optimal Transport
Oct 09, 2022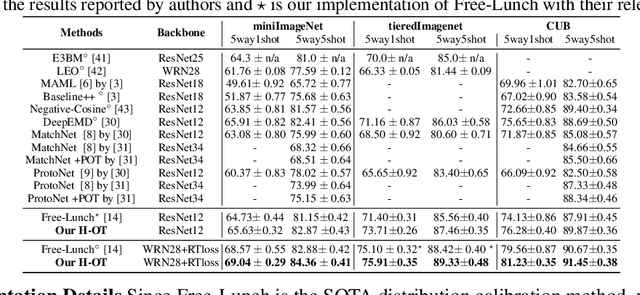
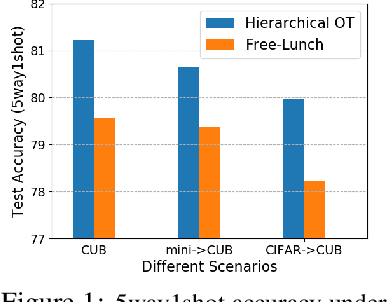
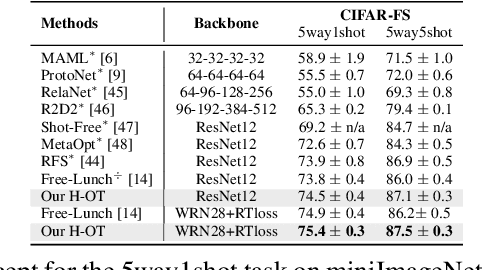

Few-shot classification aims to learn a classifier to recognize unseen classes during training, where the learned model can easily become over-fitted based on the biased distribution formed by only a few training examples. A recent solution to this problem is calibrating the distribution of these few sample classes by transferring statistics from the base classes with sufficient examples, where how to decide the transfer weights from base classes to novel classes is the key. However, principled approaches for learning the transfer weights have not been carefully studied. To this end, we propose a novel distribution calibration method by learning the adaptive weight matrix between novel samples and base classes, which is built upon a hierarchical Optimal Transport (H-OT) framework. By minimizing the high-level OT distance between novel samples and base classes, we can view the learned transport plan as the adaptive weight information for transferring the statistics of base classes. The learning of the cost function between a base class and novel class in the high-level OT leads to the introduction of the low-level OT, which considers the weights of all the data samples in the base class. Experimental results on standard benchmarks demonstrate that our proposed plug-and-play model outperforms competing approaches and owns desired cross-domain generalization ability, indicating the effectiveness of the learned adaptive weights.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022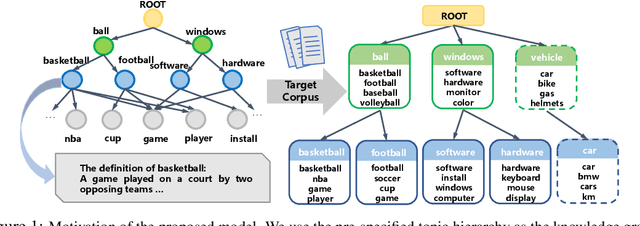
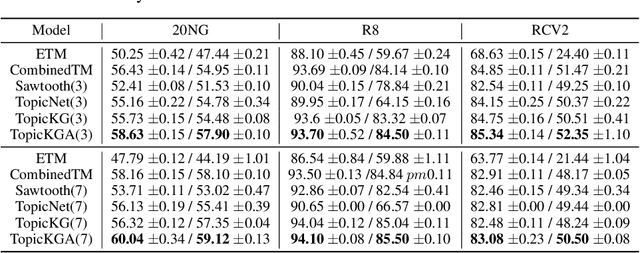
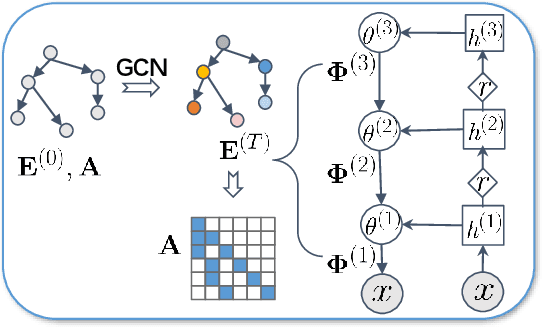

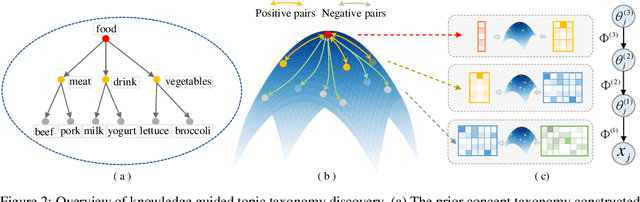
We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.
Ordinal Graph Gamma Belief Network for Social Recommender Systems
Sep 12, 2022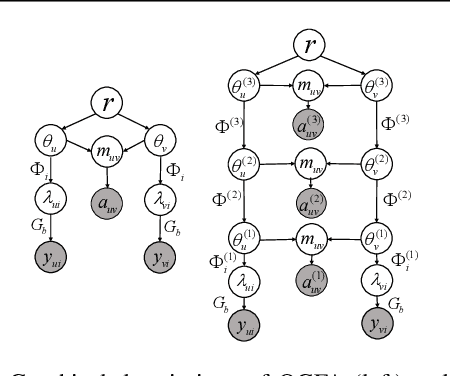
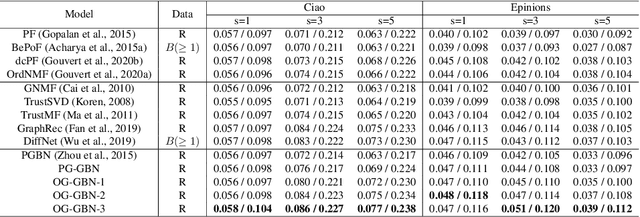
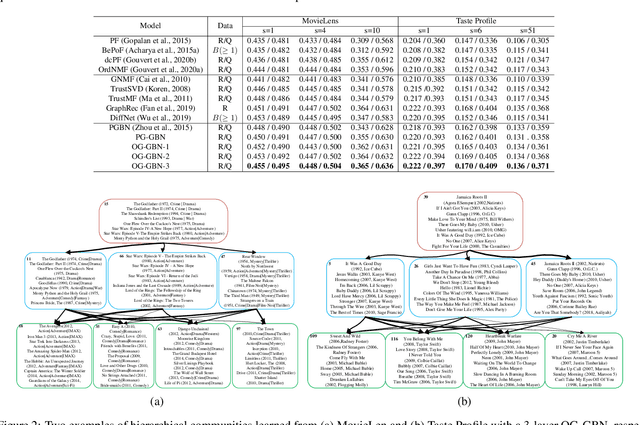
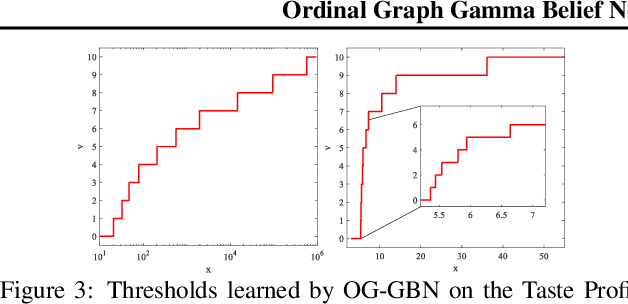
To build recommender systems that not only consider user-item interactions represented as ordinal variables, but also exploit the social network describing the relationships between the users, we develop a hierarchical Bayesian model termed ordinal graph factor analysis (OGFA), which jointly models user-item and user-user interactions. OGFA not only achieves good recommendation performance, but also extracts interpretable latent factors corresponding to representative user preferences. We further extend OGFA to ordinal graph gamma belief network, which is a multi-stochastic-layer deep probabilistic model that captures the user preferences and social communities at multiple semantic levels. For efficient inference, we develop a parallel hybrid Gibbs-EM algorithm, which exploits the sparsity of the graphs and is scalable to large datasets. Our experimental results show that the proposed models not only outperform recent baselines on recommendation datasets with explicit or implicit feedback, but also provide interpretable latent representations.
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Aug 12, 2022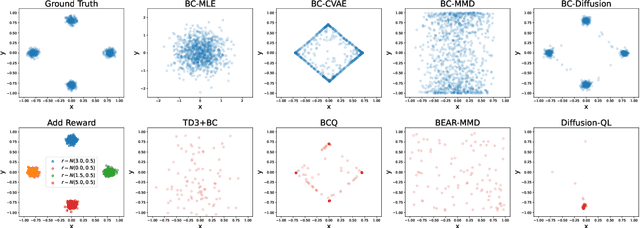
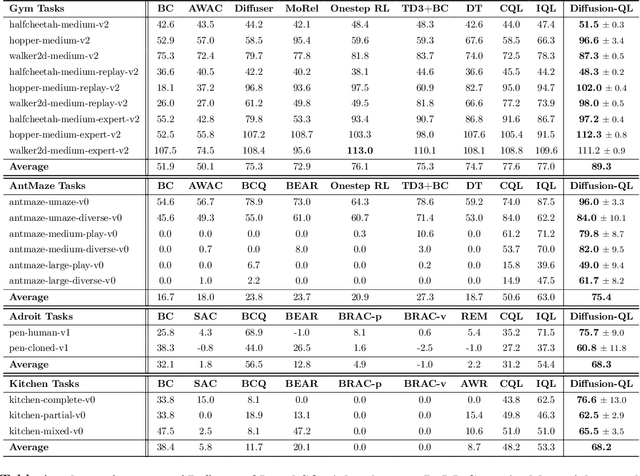
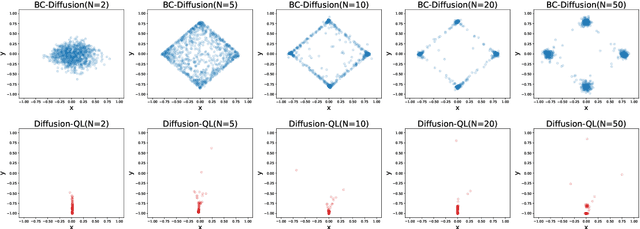
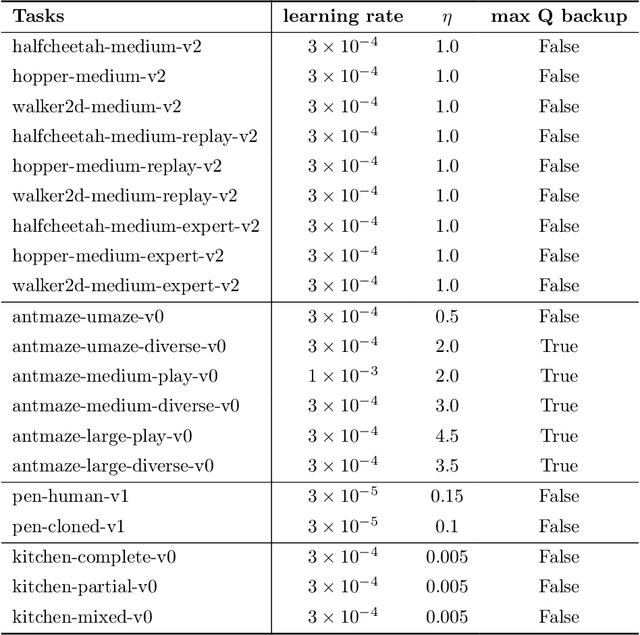
Offline reinforcement learning (RL), which aims to learn an optimal policy using a previously collected static dataset, is an important paradigm of RL. Standard RL methods often perform poorly at this task due to the function approximation errors on out-of-distribution actions. While a variety of regularization methods have been proposed to mitigate this issue, they are often constrained by policy classes with limited expressiveness and sometimes result in substantially suboptimal solutions. In this paper, we propose Diffusion-QL that utilizes a conditional diffusion model as a highly expressive policy class for behavior cloning and policy regularization. In our approach, we learn an action-value function and we add a term maximizing action-values into the training loss of a conditional diffusion model, which results in a loss that seeks optimal actions that are near the behavior policy. We show the expressiveness of the diffusion model-based policy and the coupling of the behavior cloning and policy improvement under the diffusion model both contribute to the outstanding performance of Diffusion-QL. We illustrate our method and prior work in a simple 2D bandit example with a multimodal behavior policy. We then show that our method can achieve state-of-the-art performance on the majority of the D4RL benchmark tasks for offline RL.